SparkStream整合Kafka直连方式的自动提交和手动提交偏移量
SparkStream新版本中支持与Kafka直连的方式。下图是默认自动提交偏移量的情况。executor中的task会直连kafka对应的分区,消费完数据会把偏移量写回到kafka中特殊的__consumer_offset中
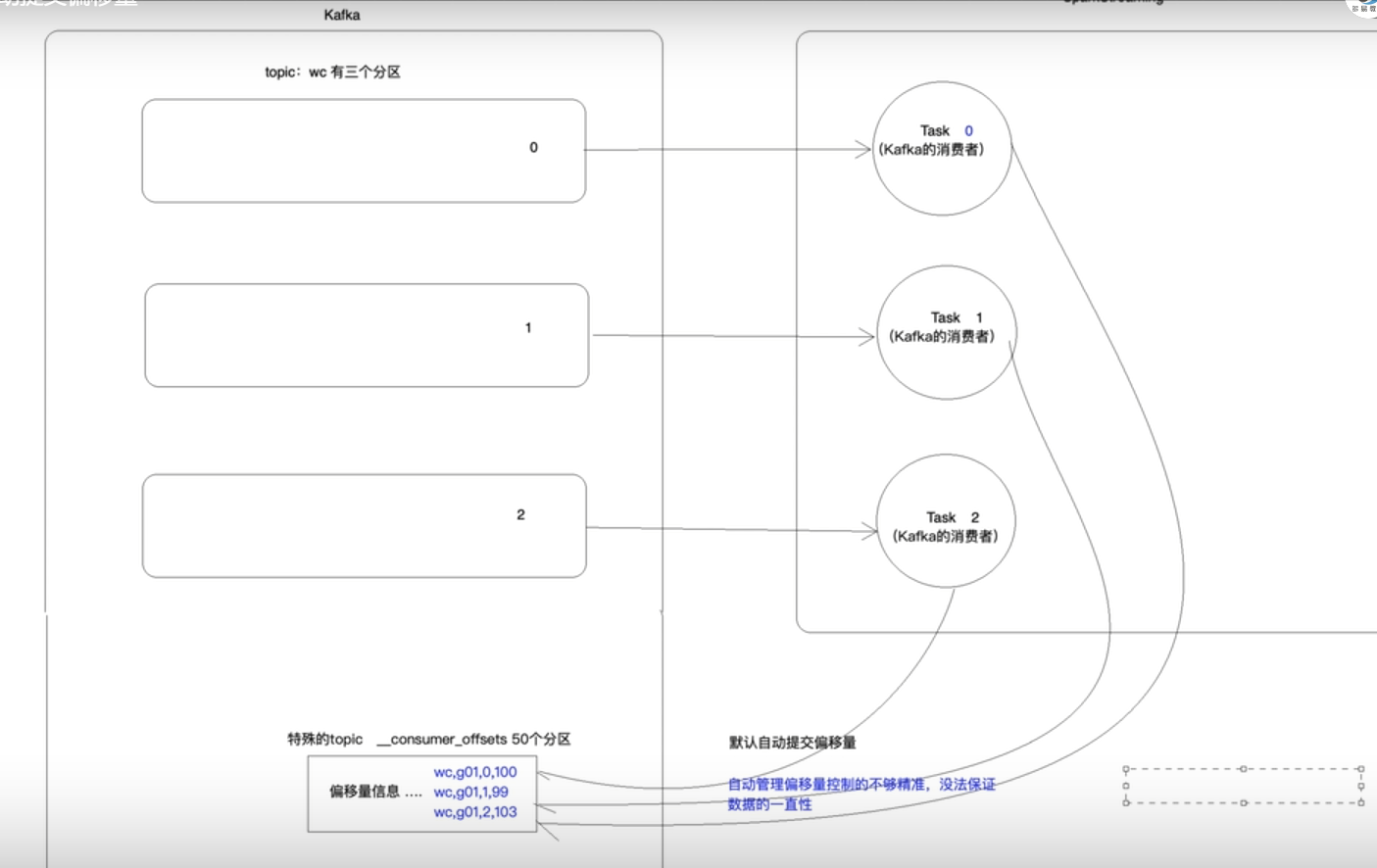
这种方式控制偏移量不够精准,无法保证数据的一致性,也就是exactly once。所以一般会关闭自动提交方式,来手动提交偏移量。
注意这里手动提交就要拿出来偏移量,因为是DSteam形式的,所以只在源头的RDD中存在,在调用
createDirectStream方法生成DStream后,因为偏移量只在RDD中存在,所以要把DStream转换成RDD。DStream转换成RDD有俩种方式,
foreachRDD和transform。这俩种方式都是运行在driver端的,不是生成task被调度到executor中的。
俩种方式的区别是foreachRDD只是方法,没有返回值,它对每一个批次的RDD进行处理,如果要在后续使用window类的DStream操作会做不到,一般用来开辟对外连接。transform方法有返回值,后续可以继续使用DStream操作。
所以综上,手动提交偏移量,是在driver端获取和更新偏移量的,executor只是执行action之后被调度过去的task算子操作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号