sum,min,max,minby,maxby
reduce,sum,min,max,minby,maxby这几个算子都是对keyedStream算子进行滚动聚合使用,把keyedStream算子转换成DataStream类算子。换句话说,想要使用这几个算子,那么势必要先去用keyby算子进行分区,把数据塞进各自对应的管道里去。
reduce算子已经在之前的一篇博客做了底层分析,这里不再赘述。下图是之后的几个算子的使用方法(注意key可以是多个元素的,这里是为了方便只写了单元素)

先来看一下sum算子
sum算子其实是reduce算子的一个弱化版本,其他几个也全是reduce的弱化版本,这里先说sum,reduce算子是你要自己去写一个Keyselecctor匿名内部类的,也就是自己去实现一个reduce具体聚合逻辑。
sum算子是用了一个默认的reduce聚合函数。接下来让我们看一下具体的底层逻辑。
sum点进去,首先看到下面俩图,new 了一个sumAggregator类,这个类是来配置你选定的sum的元素,以及聚合元素的类型的
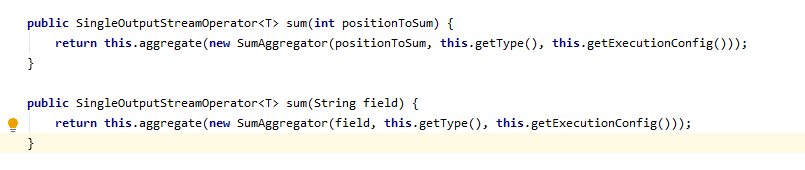
点进sumAggregator类,除开构造函数主要就是下图这个reduce函数,这个就是我们之前说到的默认的聚合函数。
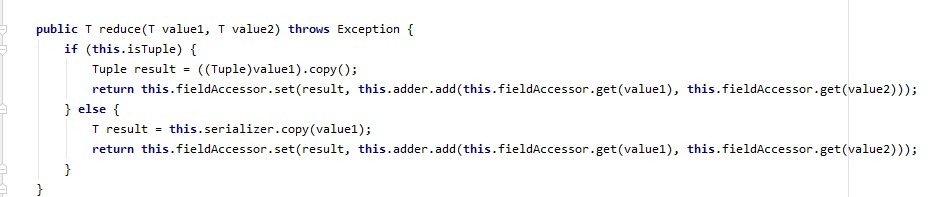
好,到这里我们debug一下,你可以看到直接像reduce一样在堆栈链里面卡在了processElement函数这里,这里就证明了之前说的 sum函数 是reduce的一个弱化版。
this.userFunction调用的reduce就是上图展示的reduce.
接下来看一下min,minby算子,max和maxby和他们是一样的原理,所以只来看一下俩个就可以。
min顾名知意,就是得到选定key的最小值。minby和min有一些区别。
来举个列子看一下,
比如现在的数据是三元组格式 ,之前使用keyby分区我们设定的Key是第一个,现在进行聚合我们设定的key是最后一个。
第一条数据(“辽宁”,“沈阳”,1000)
第二条数据(“辽宁”,“铁岭”,500)
使用min(2)之后,我们得到的是(“辽宁”,“沈阳”,500)。它只会保留分区的key和我们进行比较的key,其他的字段会延用之前状态values里,比如这里的沈阳。
使用minby(2)之后,我们得到的是(“辽宁”,“铁岭”,500),它会全部字段更新进去。可以看出min有使用局限处。
而且minby还能开启true还是false。
第三条数据(“辽宁”,“北京”,500)
现在是一个等值情况了,该保留前面的,还是后面的呢
minby(2,false) 保留后一条
minby(2,true)保留前一条
进到min源码里面,可以看到new 了comparableAggregator类,传参了比较的位置,key的类型,聚合的类型是MIN(这个聚合类型是枚举类型)

进去这个类就可以看到 reduce方法,通过byAggreagate变量,来判断进入哪个分支循环。if代码块里面的代码逻辑很容易看懂,这里就不在赘述。可以这又是一个redue函数,那么就验证了min这种又是redece的一种弱化版本

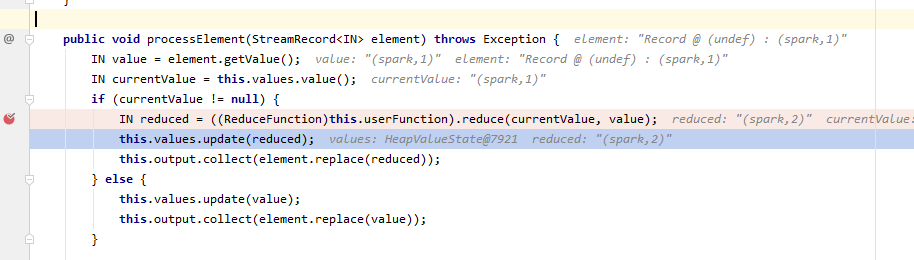
让我们来debug一下,可以又看到进到关键的processElement函数中,再次证明了上面说的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号