

对于hashmap源码的理解(1.7)
一、什么是hashmap??
hash中文为散列,而map中文为地图,二两个连到一起,就组成了hashmap,他是由数组+链表组成的。
数组因为存在下标的定义,需要连续的空间。所以它查询起来非常快,但是,他想要插入一个数据则比较麻烦。比如 现在有 1 2 3 5 这样的数组 我要在 3 和 5 之间插入一个 4 ,那么它的操作为 先复制 1 2 3 到一个“新”数组,然后把 4 插入到 3 之后, 紧接着 再把 5 复制过来,看 ,看似很简单的一个插入,它实现起来竟然是如此麻烦。
接下来要将链表的特征。上面说到数组是一个连续的空间。链表却不是这样的,他可以“见缝插针”,有一个小小的空隙,我就“呲溜”进去,根本不用一个连续的空间,所以,它正和数组的特征相反,插入快,但是,查询慢。我们首先要了解一下什么是链表。链表不需要连续的存储空间,它是通过指针来连接下面的元素的。它的没一个元素是由两部分组成的,一个为存储数据的空间,一个为存储指向下一个空间的指针。就好比图书馆里放书,某系列图书分为5季,我把它放在不连接的区域,但是每本书都夹着下一季所存放的位置,链表的原理与之相似,所以,它查询起来很费力,因为我只知道第一本书的位置,加入我要找第5本书,那么就要把前四本书都找一遍,这就和数组通过下标找差太远了。
然后,有没有查询快,插入也快的东西存在呢?hashmap就解决了这一问题。
下面为hashmap的底层结构
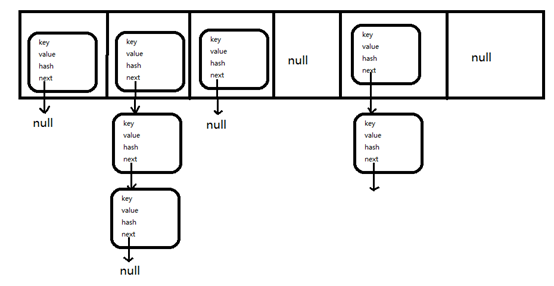
HashMap底层是由数组+链表构成的,HashMap会通过hashcode()为待插入的元素计算存储到的数组下标,根据下标,插入到数组不同的位置。在插入到数组中时,会把元素拼装成Entry对象,并构建一个链表。如果同一组数组下标已经存放了Entry,则将会插入后面。
二、hashmap源码
1.成员变量
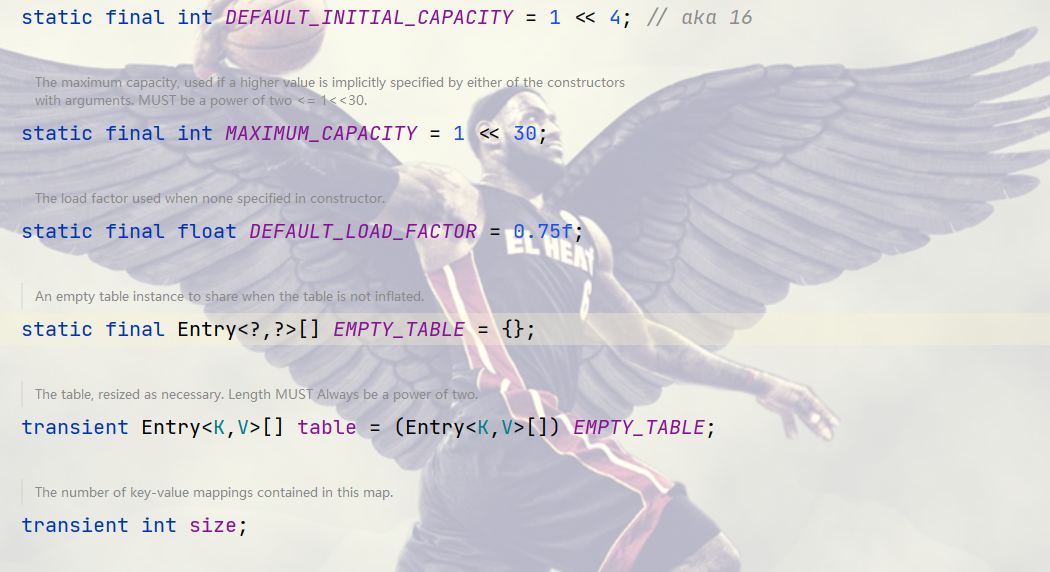
DEFAULT_INITIAL_CAPACITY:hashmap的底层容器默认初始容量,为2的4次方 16。
MAXIMUM_CAPACITY:hashmap的底层容器最大初始容量,为2的30次方 。
DEFAULT_LOAD_FACTOR:hashmap的底层容器默认负载因子,为0.75。当当前个数大于当前容量*负载因子时,这是hashmap就会进行扩充。
EMPTY_TABLE:为一个空的数组。
size:元素中存储元素的个数。
2.构造方法
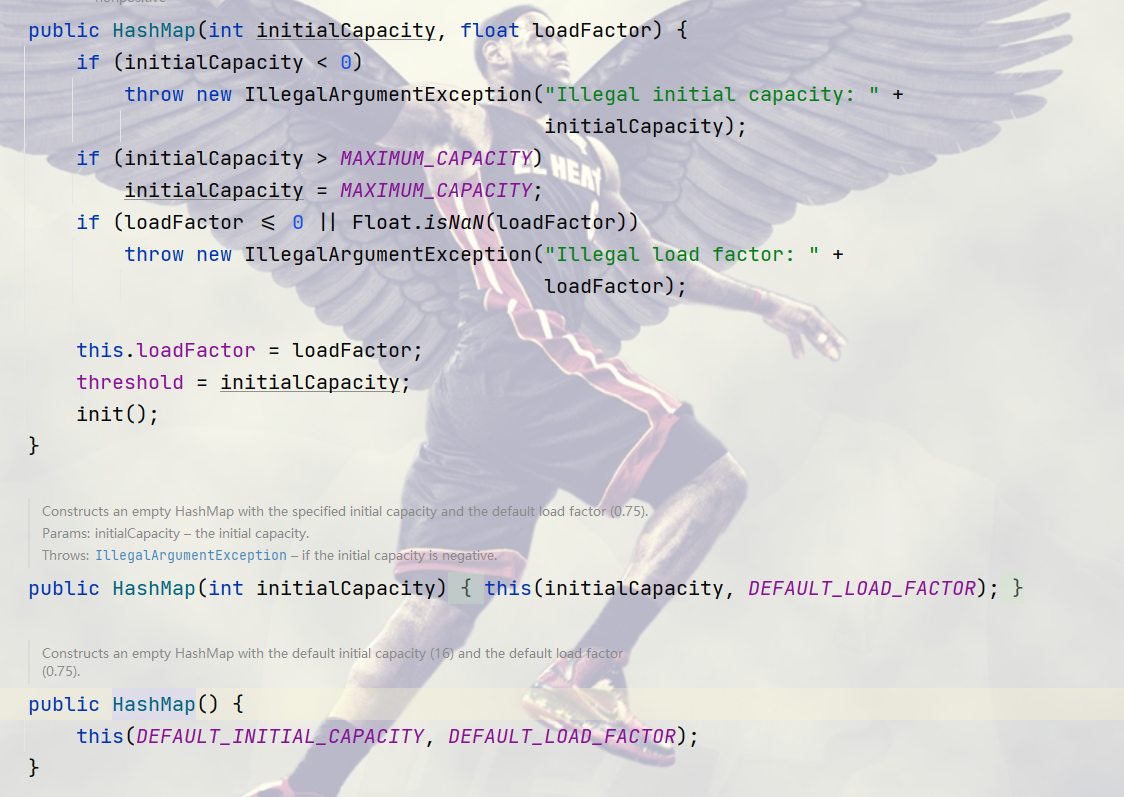
可以看到 hash共有三个构造方法,我们平常用到的是第三个无参构造方法。
第一个构造方法传入的是自定义的负载因子与容器大小
第二个构造方法要传入一个负载因子,而容器初始化大小为16。
第三个无参构造,默认容器初始化大小为16,默认负载因子0.75。
3.使用方法
当一个元素要被插入时,传入此元素的hascode值以及当前数组长度,返回hashcode对应的数组下标。
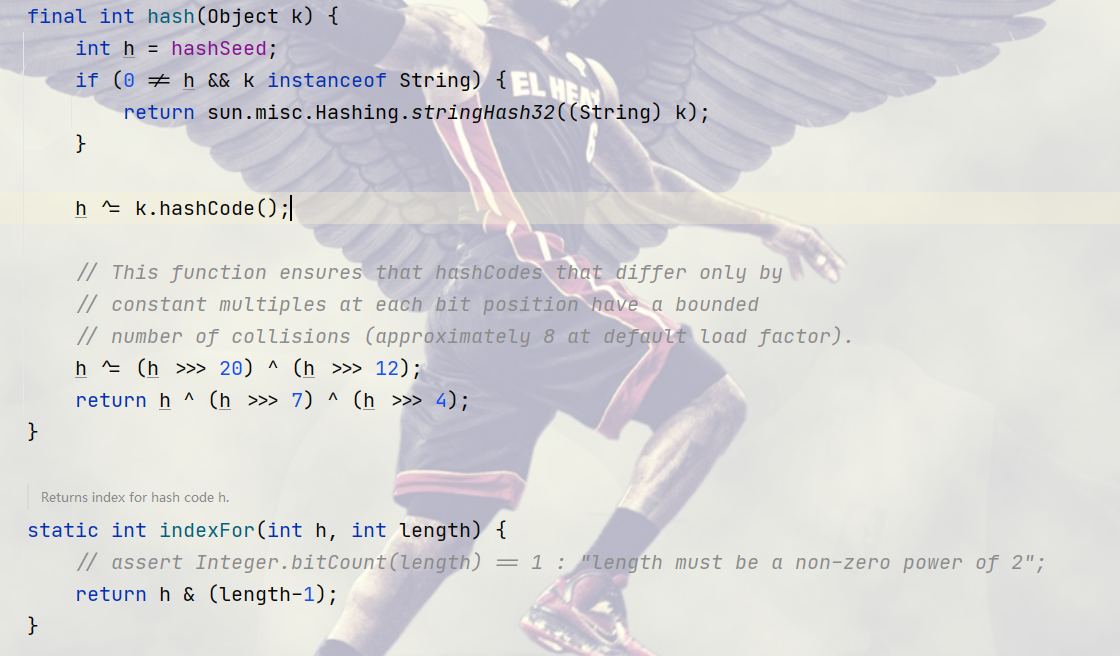
第一个hash方法就是计算元素的hash值
<< : 左移运算符,num << 1,相当于num乘以2 低位补0
>>:右移运算符,num >> 2,相当于num乘以2的2次方 高位补0
>>>:无符号右移,忽略符号位,空位都以0补齐
上面这样做的原因是让高位也参与运算,可以让hash值不容易重复。
第二个indexFor方法 是计算出索引值
&符号的用法:
比如1&1结果为1,0&0结果为0,1&0结果为0,他就是取两者都有的部分,可以这样理解,也说明了&计算出来了的结果不可能比两者大。
比如说传进来的hash值为10111(二进制),数组长度为10000,那么indeFor计算出来的结果就为10111&1111为111=7,
所以hashmap要求容量必须是2的幂,因为2的幂转换成二进制是1后面若干个0,-1后,结果为0后面若干个1.既能保证分的均匀,也能保证不越界。length-1就是防止数组越界。
还有一种可能,如果比如有两个元素,计算出来的索引值一致,那么他们就会被放在同一个索引下,以链表形式排列
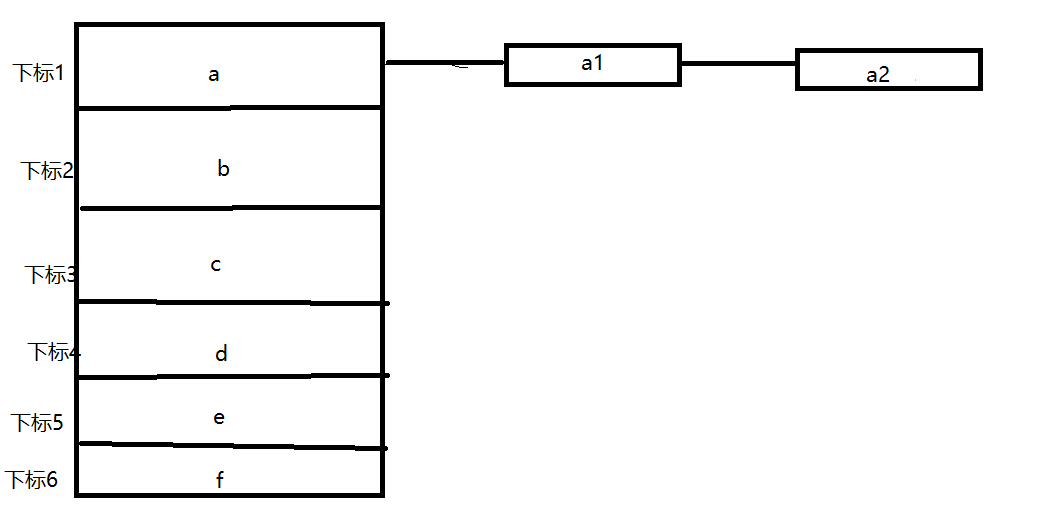
如a与a1的关系
若key为null ,怎么办呢?

可以看到,他会直接把此元素放在下标为0的位置,但注意,key可以为null,但只允许存在一个。
插入元素
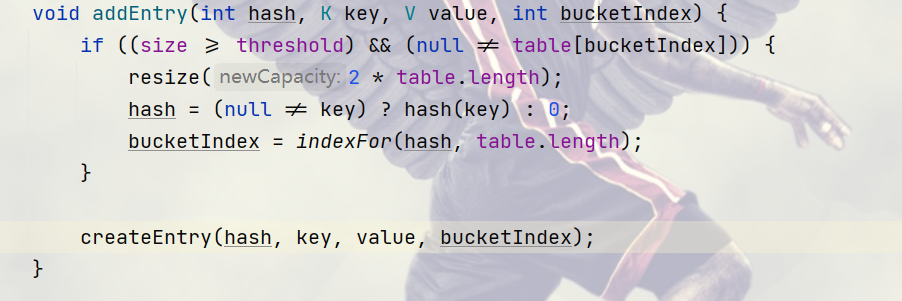
当当前的元素个数大于等于扩容阈值的时候,并且分配给新元素的这个位置以及有值,则扩容,长度为当前长度*2
如果key为null,直接放到索引为0的位置
然后得到新的长度进行indexFor()计算出次元素的索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号