BUAA面向对象课程博客 第1弹: 简单表达式化简
本文是北京航空航天大学计算机科学与技术专业本科二年级课程“面向对象设计与构造”第一单元的总结博客。作者:肖圣鹏
1 概述
本单元我使用面向对象的思想设计了一个简单的表达式化简程序。本文中我将从思路与实现两个角度总结本次学习。通过阅读本文你可以:
- 根据我的思路设计一个表达式化简程序
- 了解我在实践过程中总结的面向对象思想
- 了解一些Java编程的技巧
2 思路回顾
实战经验是最宝贵的资料。这一部分我将复盘我的开发历程,记录我在完成作业中获得的经验与教训,以及我对面向对象思想的理解逐渐加深的过程。
2.1 第一次作业:基本单变量表达式化简
第一次作业的内容是完成对包含加法(+)、减法(-)、乘法(*)和幂运算(**)的带括号的单变量表达式的化简。示例如下:
[input]: -(x+1)**2+x*2
[output]: -x**2-1
这个问题足够简单,有很多面向过程的精妙算法可以将其轻松完成。但是那不是我要在这里讨论的,我要说说如何使用面向对象的编程思想让对算法了解不多的人也能轻松解决这个问题。
首先我们思考一个更为简单的问题:常数表达式的计算(例如-9*9+8-(1+2)**2=-82)。这里我学习到了一个重要的面向对象编程的思想就是:每个人只需完成自己的工作。
观察常数表达式,不难发现它可以分为以下几个层级进行计算:
- “表达式”是若干“项”加减运算的结果;
- “项”是若干“因子”乘法运算的结果;
- “因子”是常数、常数的幂或一个括号表达式。
结合上面的思想不难得出以下算法:
/* 表达式计算算法 */
// I. 初始化结果为 0
// II. 结果加上下一个项的值
// III. 若没有下一项则结束(识别不到+/-)
// 否则回到 II
/* 项计算算法 */
// I. 初始化结果为 0
// II. 结果乘上下一个因子的值
// III. 若没有下一因子则结束(识别不到*)
// 否则回到 II
/* 因子计算算法 */
// I. 若识别到数字,到II
// 若识别到括号,到III
// II. 识别下一个数字和指数(默认为1),返回幂运算的值
// III. 递归调用 *表达式计算算法*
就是如此简单的程序结构,丝毫不见任何逆波兰表达式和栈,递归帮助我们完成了一切。
那么,如何刚才的方法如何应用到含有变量x的表达式的化简呢?不难注意到在常数表达式计算中,很关键的一点就是无论是“表达式”,“项”还是“因子”都可以计算为值——一个数字。接下来再使用这个数字进行进一步的化简工作。而对于单变量表达式,却有x+1这样不能计算的存在。但是,通过面向对象的技术,我们可以让x+1、x**2-5变得和数字同样可以计算。这里我学习到了第二个重要的面向对象思想:对行为的抽象让熟悉的算法可以运用到意想不到的数据结构上。
在常数表达式计算中,我们用整数作为化简结果,实际只利用了它加、减、乘、幂等行为。那么在单变量多项式的化简中,我们只需设计标准多项式类作为化简结果,并实现加、减、乘、幂等方法,替换掉原算法中的整数,就可以完美地迁移原先的算法。如果你对Java有所了解,一定能发现这就是接口Interface的典型使用场景。
2.2 第二次作业:函数的加入
第二次作业在第一次作业的基础上加入了函数作为新的因子,加入的函数有以下几种:
- 三角函数:cos(src)|sin(src)
- 求和函数:sum(i, inf, sup, src)
- 自定义函数:f(), g()
程序首先定义一些自定义函数,然后再进行化简,示例如下:
[input1]: 2
[input2]: f(x) = -x**2
[input3]: g(x,y,z) = (x-y)**2 + (y-z)**2 + (z-x)**2
[input4]: f(cos(x))+g(x,x,x)+sum(i, -2, 3, i*x)
[output]: -cos(x)**2 + 3 * x
如果你去本文第3部分看一看第一次作业的程序结构,你就知道本次需求的小小改动对我的代码有如何大的冲击。第一次作业中,无论表达式如何复杂,其化简结果最终都是一个标准多项式,而当三角函数引入后,带来了以下若干问题:
- 三角函数的多样性,多项式类与单项式类需要完全重构,以满足对包含三角函数的表达式的表示,如
x*sin(x**2)+x**2*cos(x) - 三角变换使得之前那样直接得到结果变得不可能:统一余弦化正弦的话,并不能总得到更好效果,如
cos(x)**2+sin(x)**2、cos(x)**2与1-cos(x)**
在连夜重构的不断思索中,我学习到了面向对象的第三个重要思想:先构建好完整的数据结构再对其进行操作可以避免在加入新类型的数据后对整个程序进行重构。这有点像制作一个魔方一类的玩具,我们在计算(解魔方)前构建一个简单但是完备的数据结构(一个魔方),那么当我们就可以直接在一个简单算法(解一个面)的基础上,继续使用基本的方法(拧魔方),实现一个更复杂的算法(解六个面)。
因此,本次作业的思路可以分为以下两个步骤: - 将字符串表达式按“表达式”、“项”和“因子”的层级构建成对应的数据结构
- 愉快地对构建好的表达式进行各种各样的操作:加、减、乘7幂运算,化简,代入等
构建表达式与第一次作业的方法类似,但是不需要进行化简,只要把解析的因子、项拼接起来即可。并且引入了函数因子:形如f(x,y),由一个函数名和括号参数表组成。
接下来对表达式进行化简: 实现simplify()方法,返回化简后的表达式。这依然可以归结到逐项化简并相加,而项的化简则可以归结到因子的化简与相乘。这里的难点有二: - 因子如何化简
- 加法与乘法如何合并项与因子
我们首先讨论因子的化简。
首先我们关注递归的终点:常数(2,-990)与变量(x,y),它们只需返回自身;
然后我们再考虑简单的子表达式:直接递归调用表达式化简;
最后是最有趣的函数化简: - 对于三角函数,判断是否可以转化为常数,可以则返回常数,否则化简操作数并返回
- 对于求和函数,将求和变量的值不断代入求和表达式进行求和,得到一个子表达式,化简并返回
- 对于自定义函数,将参数代入该函数定义式,得到一个子表达式,化简并返回
然后是如何进行合并:
这里我们用到了数学中的一个经典思想:如果两个集合互为子集,那么它们相等,对于两个项也是如此,若两个项的所有非常数因子都可以在另一个项中找到,则它们是同类项。表达式的相等判断与项类似。而因子的相等判断则是简单的相等判断:类型与属性的相等。
2.3 第三次作业:多层函数嵌套
第三次作业允许在自定义函数的定义不包含自定义函数的情况下,进行f(f(f(x))+1,g(x)),sum(i,-7,9,f(x))这样的多层函数嵌套。很容易发现这我们的第二次作业已经可以完成这一点了,这带来了轻松的第三周,但以地狱般的第二周为代价。因此本次作业的收获只有两条重要的思想:
- 一条关于编程:好的面向对象程序有自己的生命
- 一条关于人生:一次达到完美并不如逐渐进步
3 程序设计
本部分给出程序结构设计与关键实现细节。
3.1 第一次作业
首先展示UML图。可以清楚地看到程序分为了两个部分,左侧负责解析字符串(同时进行计算),右侧则完成了多项式行为的抽象,让我们可以如同处理数字那样处理多项式。
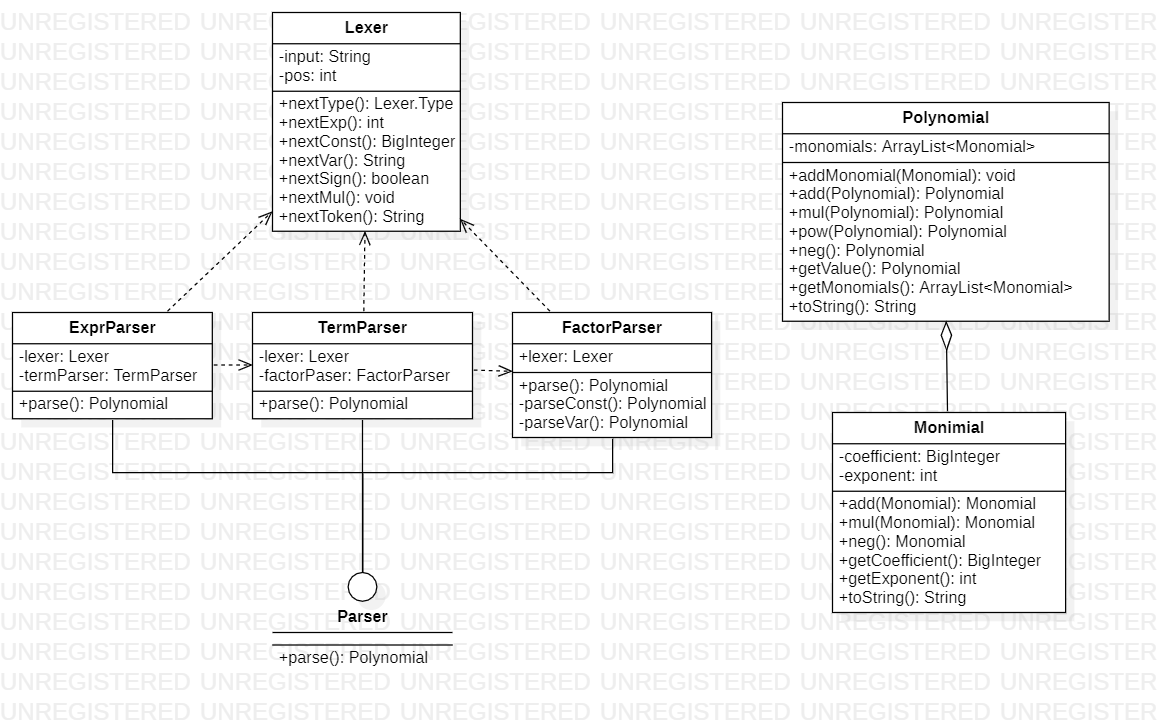
我们先来看看逻辑更为简单的右侧部分。多项式是单项式的聚合,多项式的加法运算是所有单项式相加,多项式的乘法运算是所有单项式交叉相乘再相加,多项式的幂类似。
现在问题的终点落到了单项式的计算上,这里是递归的终点,是程序抽象度最低的点。在设计使用递归的程序时,我们最应该注意这里。
在我的程序里需要注意的一点就是单项式层级的加法与多项式层级的加法的不同。多项式层级的加法把所有多项式中所有单项式能合并的合并,不能合并的拼接;因此单项式的加法需要做的就是判断两个单项式是否能合并,在可以时返回合并结果。
public Monomial add(Monomial monomial) throws RuntimeException {
if (this.getExponent() != monomial.getExponent()) {
throw new RuntimeException("Monomial addition: Exponents must be same!");
}
BigInteger coefficient = this.getCoefficient().add(monomial.coefficient);
return new Monomial(coefficient, this.getExponent());
}
接下来我们再来看看解析的部分。Parser接口的各个实现负责“表达式”、“项”和“因子”这样抽象的句法解析,其代码结构与第2部分的算法描述并无二致。而Lexer这个类负责字符串结构的具体的词法解析,其接口模仿了输入流。这里附上最复杂的FactorParser的parse()方法的实现:
public Polynomial parse() {
Polynomial polynomial;
switch (lexer.nextType()) {
case CONSTANT:
polynomial = parseConstant(lexer.nextConstant());
break;
case VARIABLE:
lexer.nextVariable();
polynomial = parseVariable();
break;
case EXPRESSION:
polynomial = new ExprParser(lexer.nextExpression()).parse();
break;
default:
throw new RuntimeException("Unknown next factor: " + lexer.nextType());
}
if (lexer.nextType() == Lexer.Type.EXPONENT) {
polynomial = polynomial.pow(lexer.nextExponent());
}
return polynomial;
}
本次的代码充分利用了层级化处理与递归下降,较为优雅地解决了本次作业的需求,但依然存在以下不足:
- 使用的数据结构——多项式类,对输入数据进行了压缩,导致扩展性差,不能轻松加入新类型因子——函数
- 数据的构建与对数据的操作耦合在一起,导致各部分难以修改。在加入三角函数后,无法进行三角优化(因为三角优化需要通过尝试进行)
Parser接口的3个实现过于冗余,完全可以合并为一个类
3.2 第二次作业
同样首先展示UML图。可以看出本次作业对第一次作业列出的3个不足之处进行了修改。
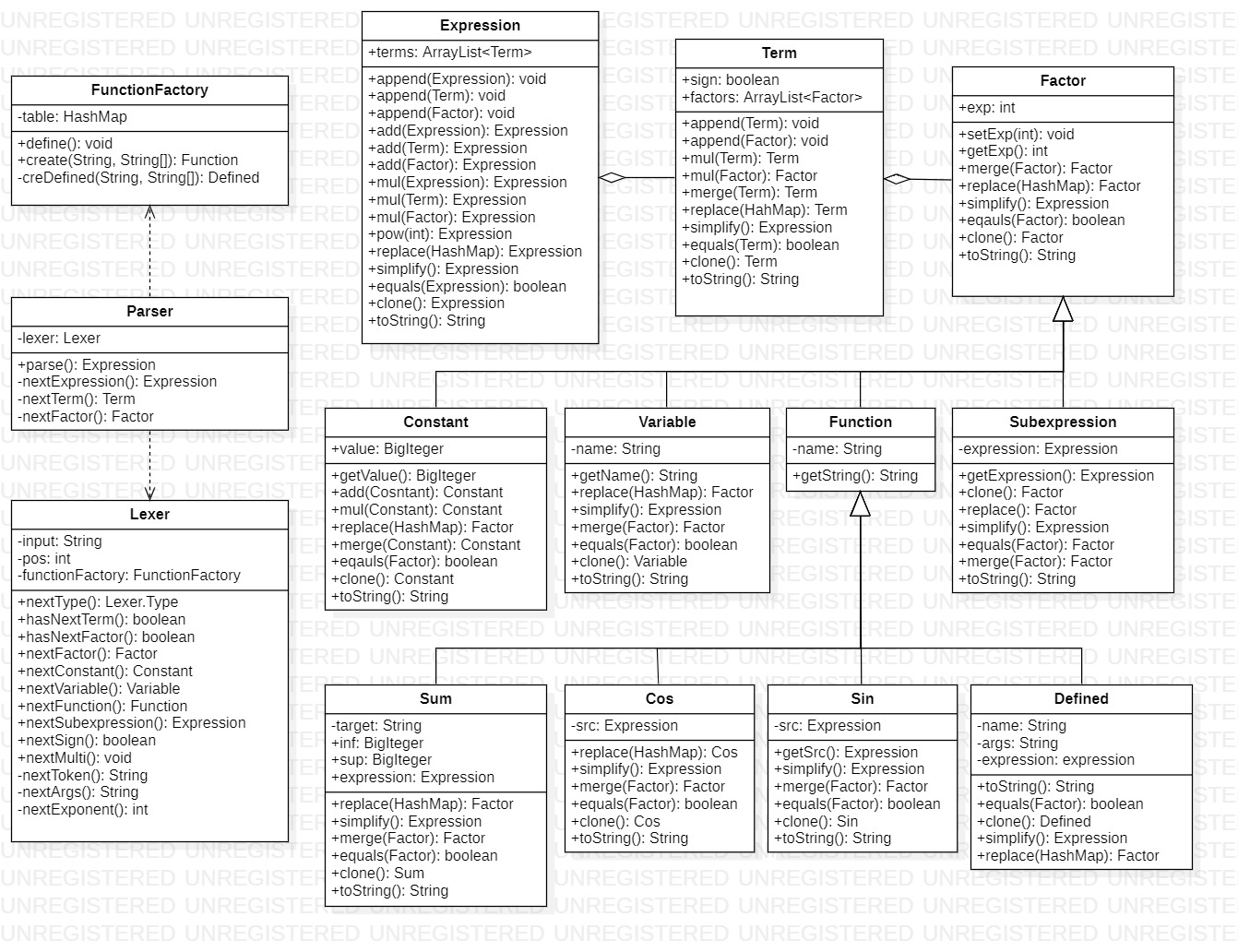
表达式的构建的方法通过图片一目了然,由于ddl快到了,我直接开始介绍对表达式的操作的实现细节。首先我们看看表达式的化简方法,依然十分简单,复杂的部分都封装在了add方法里,它会对两个表达式里所有项进行合并尝试,若不能合并则拼接它。这里运用到一个技巧:将复杂的代码封装为简单的底层操作
public Expression simplify() {
Expression result = new Expression();
for (Term term : terms) {
result = result.add(term.simplify());
}
return result;
}
public Expression add(Term term) {
if (term.onlyConst().equals(Constant.zero())) {
return this.clone();
}
Expression result = new Expression();
boolean find = false;
for (Term term1 : terms) {
if (!find && term1.merge(term) != null) {
find = true;
Term merged = term.merge(term1);
if (!merged.onlyConst().equals(Constant.zero())) {
result.append(term1.merge(term));
}
continue;
}
result.append(term1);
}
if (!find) {
result.append(term);
}
return result;
}
然后再让我们看看函数因子是如何被化简的。我们以sum函数为例,可见函数的化简封装了对应函数的运算规则。而就sum函数而言,使其代码简洁的一点在于replace()方法的封装。replace()传入一个HashMap参数,表示某个名字的变量需要被换成某个子表达式。它依然使用递归下降的方法完成,在此不做赘述。
@Override
public Expression simplify() {
if (getExp() == 0) {
return Expression.one();
}
Expression result = new Expression();
BigInteger i = inf;
while (i.compareTo(sup) <= 0) {
HashMap<String, Expression> replacement = new HashMap<>();
Expression expression = new Expression(new Constant(i));
replacement.put(target, expression);
result = result.add(this.expression.replace(replacement).simplify());
i = BigInteger.ONE.add(i);
}
return result;
}
在本次作业中,除了以上叙述的部分,我还有以下几点收获:
- 重载的使用:表达式可以使用相同的接口加上表达式、项或者因子
- 工厂类的实例化:
FunctionFactory采用工厂模式创建函数,但与我以往见到的工厂不同,本次我使用了非静态方法创建函数。因为此工厂还记录了自定义函数定义的信息,相当于一个数据库。这说明工厂类的实例化是有意义的。
4 测试经验
简洁起见,我用一个问题概括本部分的内容:是否更测试用例,能测出更多的bug?至少在本次作业中,这个问题的答案是否定的。在递归下降的算法中,可能存在的bug分为以下两种:
- 递归终点处的bug
- 递归过程处的bug
对于第一种bug,我们只需考虑终点的测试样例:各种因子的全覆盖。我们可以对每一种因子的有特点的数据进行构建。
对于第二种bug,我们需要考虑递归调用的过程:加法与乘法的调用。需要注意的一点就是多层嵌套和两层嵌套没有任何区别,我们用以上的因子样例组合成嵌套的样例。
5 总结
迫于时间和篇幅所限,本次博客暂且包含以上内容。我认为本文最精华的部分是各黑体字所示的编程思想。如果你认为它们没什么用,那么你也可以试着通过我的思路设计与改进一个新的表达式化简程序,看看有没有更好的解决方案,那样本文也是有意义的。
附录:度量分析
| expr.Expression.add(Expression) | 2.0 | 1.0 | 3.0 | 3.0 |
|---|---|---|---|---|
| expr.Expression.add(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.add(Term) | 9.0 | 4.0 | 7.0 | 7.0 |
| expr.Expression.append(Expression) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.Expression.append(Factor) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.Expression.append(Term) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.Expression.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.equals(Expression) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.Expression() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.Expression(Expression) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.Expression(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.Expression(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.infTo(Expression) | 10.0 | 6.0 | 4.0 | 6.0 |
| expr.Expression.mul(Expression) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Expression.mul(Factor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.mul(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.neg() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.one() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expression.pow(int) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Expression.replace(HashMap<String, Expression>) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.simplify() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expression.toString() | 3.0 | 3.0 | 3.0 | 4.0 |
| expr.Expression.zero() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.add(Constant) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.Constant(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.Constant(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.Constant(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.equals(Factor) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.factor.Constant.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.merge(Factor) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.factor.Constant.mul(Constant) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.neg() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.one() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.replace(HashMap<String, Expression>) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Constant.simplify() | 1.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.Constant.toString() | 2.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.Constant.zero() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Factor.Factor() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Cos.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Cos.Cos(Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Cos.Cos(String[], FunctionFactory) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.factor.func.Cos.equals(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.func.Cos.getSrc() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Cos.merge(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.func.Cos.replace(HashMap<String, Expression>) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Cos.simplify() | 2.0 | 3.0 | 3.0 | 3.0 |
| expr.factor.func.Cos.toString() | 4.0 | 1.0 | 5.0 | 6.0 |
| expr.factor.func.Defined.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Defined.create(String[], FunctionFactory) | 2.0 | 2.0 | 2.0 | 3.0 |
| expr.factor.func.Defined.Defined(String, String[], Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Defined.equals(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Defined.merge(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Defined.replace(HashMap<String, Expression>) | 4.0 | 1.0 | 3.0 | 3.0 |
| expr.factor.func.Defined.simplify() | 1.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.func.Defined.toString() | 4.0 | 1.0 | 4.0 | 4.0 |
| expr.factor.func.FunctionFactory.create(String, String[]) | 1.0 | 4.0 | 1.0 | 4.0 |
| expr.factor.func.FunctionFactory.creDefined(String, String[]) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.factor.func.FunctionFactory.define(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.FunctionFactory.FunctionFactory() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sin.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sin.equals(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.func.Sin.getSrc() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sin.merge(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.func.Sin.replace(HashMap<String, Expression>) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sin.simplify() | 2.0 | 3.0 | 3.0 | 3.0 |
| expr.factor.func.Sin.Sin(Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sin.Sin(String[], FunctionFactory) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.factor.func.Sin.toString() | 4.0 | 1.0 | 5.0 | 6.0 |
| expr.factor.func.Sum.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.equals(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.getExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.getInf() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.getSup() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.merge(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.replace(HashMap<String, Expression>) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.simplify() | 2.0 | 2.0 | 3.0 | 3.0 |
| expr.factor.func.Sum.Sum(String, BigInteger, BigInteger, Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.Sum(String[], FunctionFactory) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.func.Sum.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.factor.Function.Function() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Function.Function(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Function.getName() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Factor.getExp() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Factor.setExp(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.equals(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.Subexpression.getExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.merge(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.replace(HashMap<String, Expression>) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.simplify() | 1.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.Subexpression.Subexpression(Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Subexpression.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.factor.Variable.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Variable.equals(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.Variable.getName() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.factor.Variable.merge(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| expr.factor.Variable.replace(HashMap<String, Expression>) | 1.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.Variable.simplify() | 1.0 | 2.0 | 2.0 | 2.0 |
| expr.factor.Variable.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.factor.Variable.Variable(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.append(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.append(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.equals(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.getSign() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.infTo(Term) | 10.0 | 6.0 | 4.0 | 6.0 |
| expr.Term.merge(Term) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.Term.mul(Factor) | 9.0 | 4.0 | 7.0 | 7.0 |
| expr.Term.mul(Term) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.onlyConst() | 4.0 | 1.0 | 4.0 | 4.0 |
| expr.Term.replace(HashMap<String, Expression>) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.revSign() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.setSign(boolean) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.simplify() | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term(boolean) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.toString() | 10.0 | 2.0 | 8.0 | 8.0 |
| expr.Term.withoutConst() | 3.0 | 3.0 | 2.0 | 3.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| parser.Lexer.hasNextFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.hasNextTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.Lexer(String, FunctionFactory) | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextArgs() | 8.0 | 4.0 | 6.0 | 7.0 |
| parser.Lexer.nextConstant() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextExponent() | 2.0 | 2.0 | 2.0 | 2.0 |
| parser.Lexer.nextFactor() | 2.0 | 5.0 | 6.0 | 6.0 |
| parser.Lexer.nextFunction() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextMulti() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextSign() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextSubexpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Lexer.nextToken() | 4.0 | 1.0 | 2.0 | 4.0 |
| parser.Lexer.nextType() | 9.0 | 1.0 | 8.0 | 9.0 |
| parser.Lexer.nextVariable() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Parser.nextExpression() | 5.0 | 1.0 | 4.0 | 4.0 |
| parser.Parser.nextFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Parser.nextTerm() | 3.0 | 1.0 | 4.0 | 4.0 |
| parser.Parser.parse() | 0.0 | 1.0 | 1.0 | 1.0 |
| parser.Parser.Parser(String, FunctionFactory) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 172.0 | 210.0 | 249.0 | 288.0 |
| Average | 1.2027972027972027 | 1.4685314685314685 | 1.7412587412587412 | 2.013986013986014 |
posted on 2022-03-26 14:53 ^^^TOO_LOW^^^ 阅读(313) 评论(2) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号