基于python的爬虫项目
一、项目简介
1.1 项目博客地址
https://www.cnblogs.com/xsfa/p/12083913.html
1.2 项目完成的功能与特色
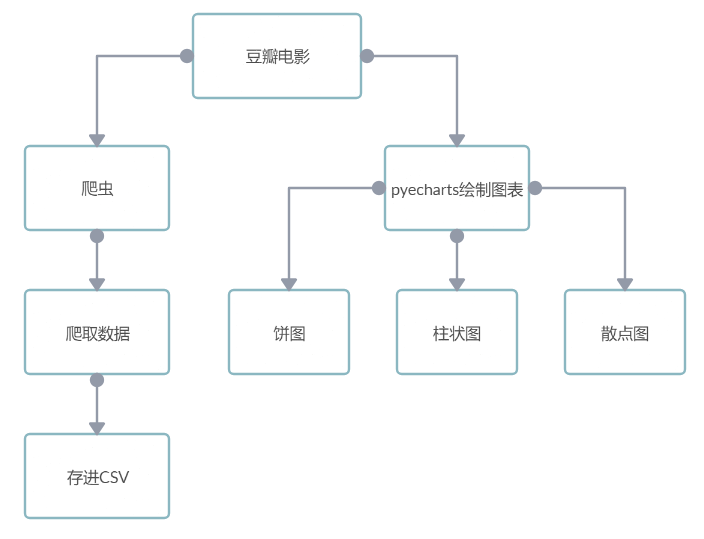
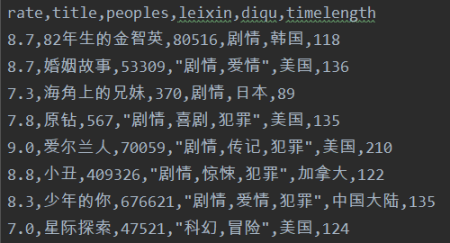
通过豆瓣电影网站分析network查找js的数据,并爬取数据生成CSV文件,对表中的数据进行分析,然后绘制相应的饼图,柱状图,散点图。
使用python中的第三方库requests,pandas,pyecharts,snapshot_phantomjs
Echarts是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts诞生了。
(1)爬取豆瓣电影热门分类的评分,名称,评论数,类型,地区,时长
(2)生成CSV文件
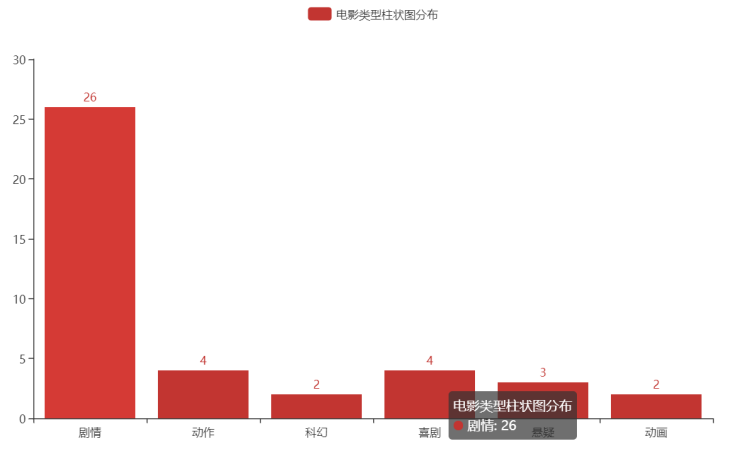
(3)对电影类型进行分析,然后获得数据进行分析,并绘制柱状图
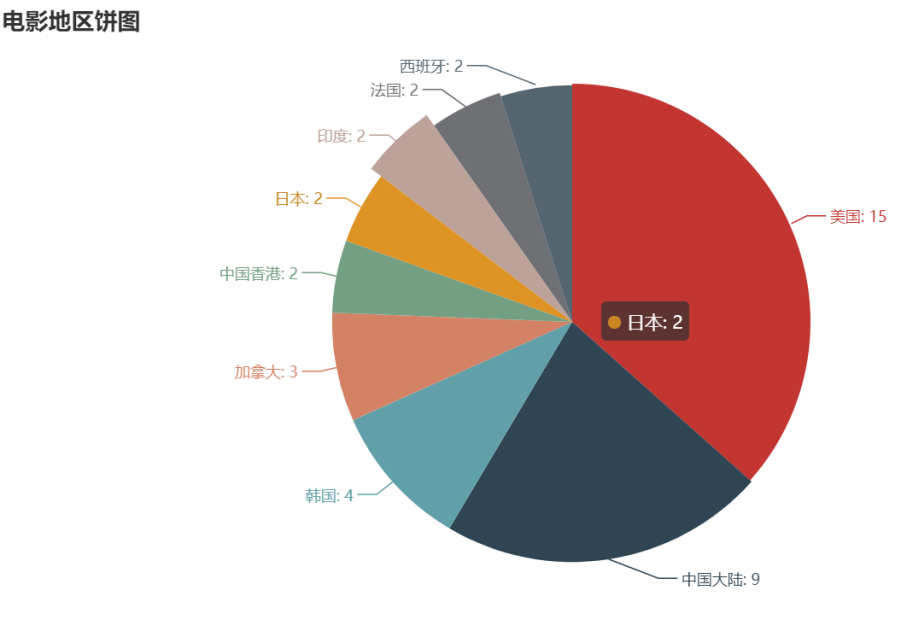
(4)对电影地区进行分析,然后获得数据进行分析,并绘制饼图
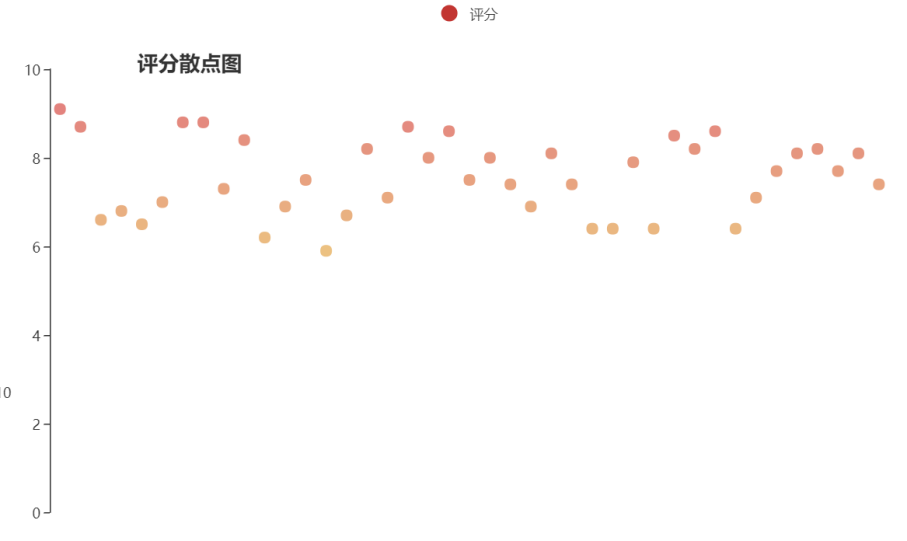
(5)对电影评分进行分析,然后获得数据进行分析,并绘制散点图
1.3 项目采用的技术栈
python requests pyecharts
利用requests获取豆瓣电影的js文件并转换成json,然后提取评分、名称、评论数、类型、地区、时长这些数据利用pyecharts里面的Echarts生成饼图,柱状图,散点图。
二、项目的需求分析
随着互联网的发展壮大,网络数据越来越多,如何高效抓取信息成为难题。网络爬虫具有自动提取网页信息的能力。根据网站的特点,提出了一种基于Python中requests模块及Py Query模块进行数据采集的爬虫程序设计,可采集豆瓣网大量信息。本设计具有针对性强,操作容易、简单,采集数据准确,采集量大等优点。
项目功能图:
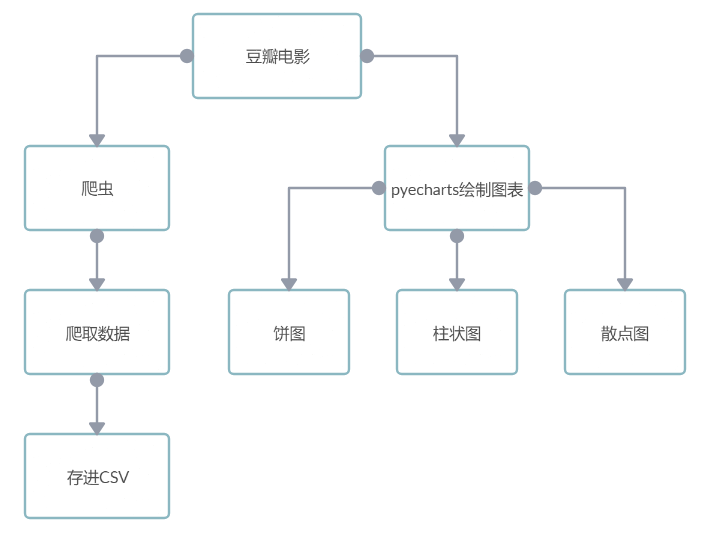
三、项目功能架构图、主要功能流程图
项目功能架构图:
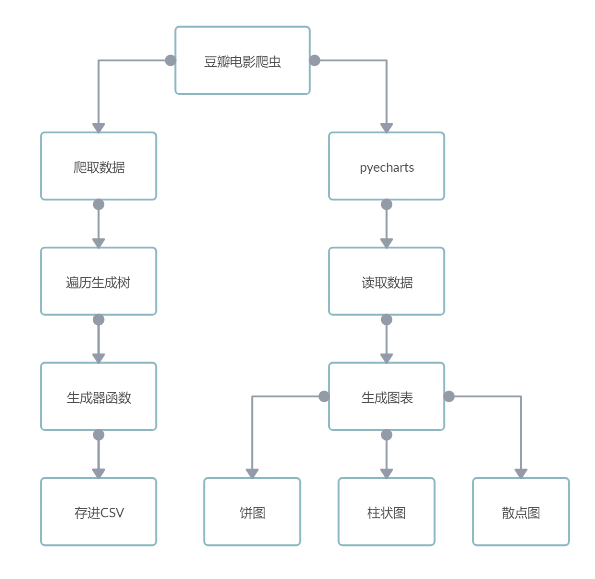
主要功能流程图:
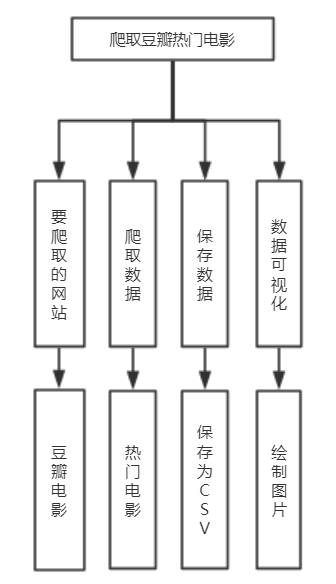
四、系统模块说明
4.1 系统模块列表
4.2 各模块详细描述(名称,功能,运行截图,关键源代码)
1.名称:爬虫
功能:爬取豆瓣电影热门分类的评分,名称,评论数,类型,地区,时长
关键源代码:
(1)设置一些headers信息,模拟成浏览器访问网站

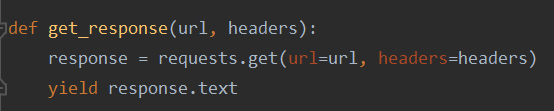
(2)返回URL

(3)返回响应文本
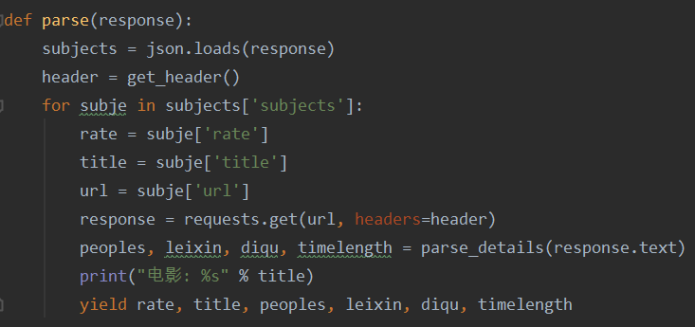
(4)把js数据转换成json格式的字符串并数据提取数据
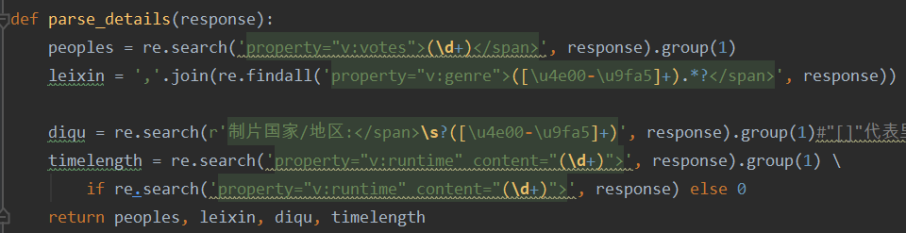
(5)通过正则表达式提取,解析评论数,类型,地区,时长的数据
(6)把数据存入到csv文件
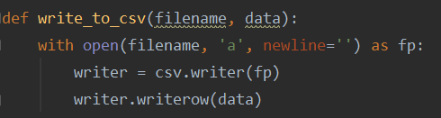
(7)控制爬虫,遍历获取的每一条数据,存进csv文件
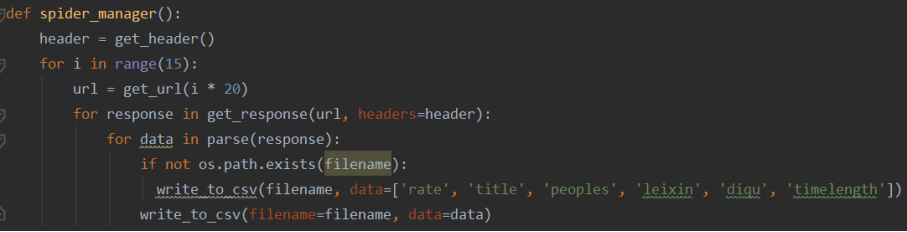
(8)读取CSV文件,没有CSV文件的话就报错
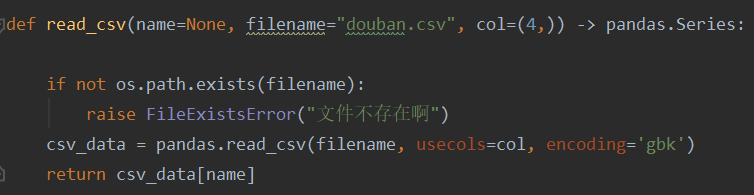
运行截图:
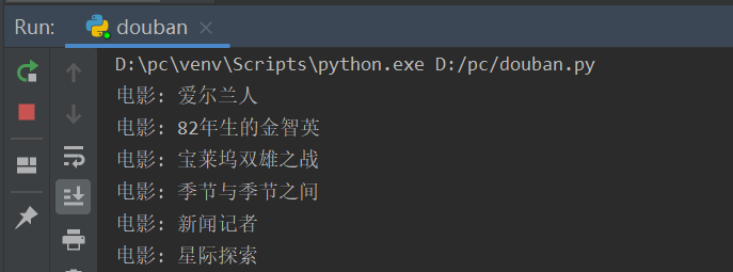
2. 名称:可视化数据分析
功能:
对电影类型进行分析,然后获得数据进行分析,并绘制柱状图
对电影地区进行分析,然后获得数据进行分析,并绘制饼图
对电影评分进行分析,然后获得数据进行分析,并绘制散点图
关键源代码:
pycharts是python中调用百度基于js开发的echarts接口,也可以对数据进行各种可视化操作。调用接口画出了饼图,柱状图和散点图。
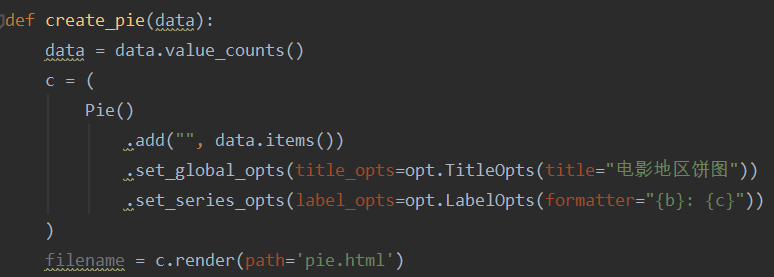
(1)通过传入data这个数据,使用pycharts把数据生成电影地区饼图,并渲染到pie.html
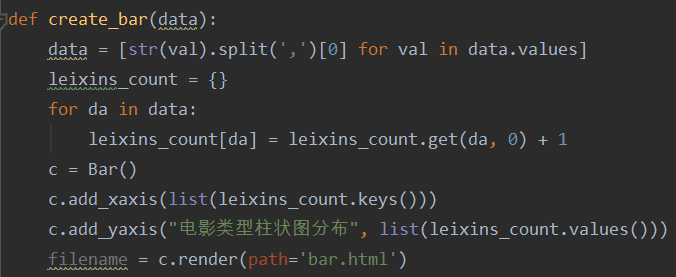
(2)通过传入data这个数据,使用pycharts把数据生成电影类型柱状图,并渲染到bar.html
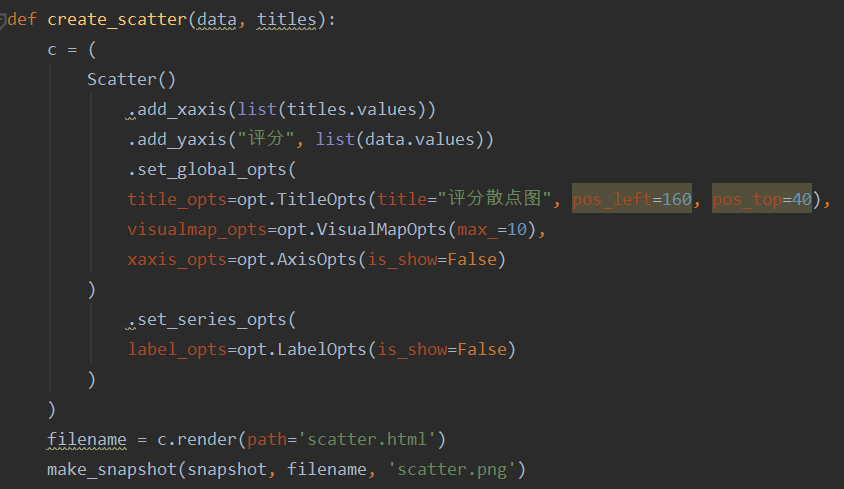
(3)通过传入data和titles这两个数据,使用pycharts把数据生成电影评分散点图,并渲染到scatter.html
运行截图:
五、项目总结
5.1 特点
该项目爬取的数据生成CSV文件,对表中的数据进行分析。绘制成的饼图可以看出各个地区生产数的多少;绘制成的柱状图可以看出各个电影类型数量的多少;绘制成的散点图可以看出电影评分的高低,在网页上移动到某一散点,可以看到该散点对应的电影名称。
5.2 不足之处
在做这个项目时还是有点艰难的,显然自己平时学习的还不够多。有的内容经过查阅资料后还做得不是很好。像散点图由于数据太多没办法显示完整的名称就只能把名称隐藏了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号