

OO第三单元总结博客
OO第三单元总结博客
一、架构设计
其实,整个工程的大体架构已经在接口中给出来了,三次作业,实现增量开发。在接口的帮助下,除了为了修正性能问题之外,没有进行太大的代码改动。
图用邻接表来实现。主干部分是MyNetwork类,有容器用来存储MyPerson, MyMessage, MyGroup类,还有容器用来存储表情包id和其热度的映射关系,还有变量为blockNum(连通分量个数),和level(并查集)。具体维护方式见后文。
关于MyPerson类,有属性id, name, age, socialValue, money,还有用来存储与其有连接的人acquaintance, 和相应权值value,以及用来存储接收信件的容器messages。并且根据jml对其进行改变、维护。
关于MyGroup类,有属性id, 存储群成员的容器people。还有因为性能要求需要动态维护的变量ageSum(年龄之和), ageSquareSum(年龄平方之和), valueSum(导出子图的边的权值之和),具体维护方式见后文。
关于MyMessage类,有属性id, type, socialvalue, person1, person2, group,还有一些方法,根据jml来对其字段进行改变。
具体类图如下(第三次作业):
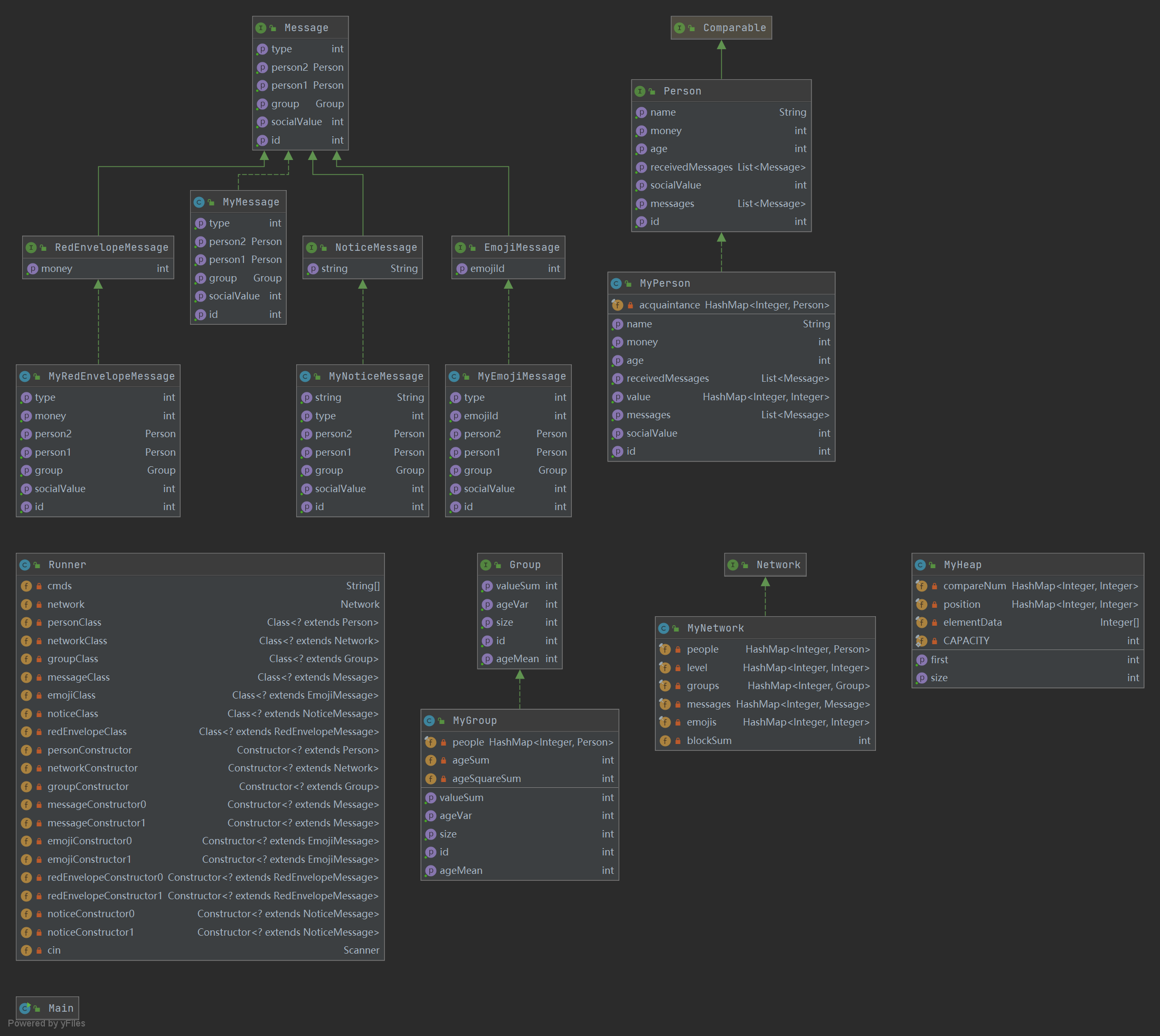
二、容器选择
在MyPerson类里面,acquaintance和value字段使用的是HashMap,其中键对应的是人的id,值用来存储Person实例(acquaintance)或者边的权值(value)。因为这样,查询权值或者找Person的时候,通过containsKey来找可以使时间复杂度最短可达o(1)。如果使用arrayList容器,他使用contain方法会利用遍历的方式,复杂度o(N),较大。而messages使用LinkedList容器,这样插入头结点的时候速度较快,不需要向arrayList一样来回移动。
在MyGroup类里面,用来存储群成员的容器使用的是HashMap数据结构。原因跟上面一致,HashMap的containsKey方法速度比较快,时间复杂度比较低。
在MyNetwork类里面,因为关于时间复杂度的原因,所有容器字段的数据结构都采用的是HashMap(people, 并查集level, groups, messages, emojis)。
在所有异常类里面,用来存储参数触发异常次数的容器Counter使用HashMap来记录,键值为相应触发异常时的参数,值为触发异常次数。使用原因依然是为了使时间复杂度最小。
三、采取设计策略
这三次代码作业,jml部分已经很大程度上帮助我们搭建好了框架。关于具体的指令,使用的实现方法如下:
第九次作业:
getPerson,contains,addPerson,queryPeopleSum: 使用存储Person的容器HashMap的自带方法get,comtainsKey,put,size来实现,其复杂度为o(1)addRelation: 通过getPerson函数来找到人,并且对人的邻接表acquaintance进行add操作,复杂度o(N),因为涉及到动态维护valuesumqueryvalue: 与addRelation类似,对人的邻接表进行get操作,复杂度o(1)compareName: 通过getPerson函数来找到人,并且对人的name字段进行compareTo操作,复杂度o(1)queryNameRank: 遍历People并进行compareName操作,复杂度o(N)isCircle: 使用并查集算法来做,addPerson,addRelation要对并查集进行维护,复杂度o(N)queryBlockSum: 在addRelation,addPerson时动态维护变量blockSum,复杂度o(1)
第十次作业:
addGroup,getGroup,queryGroupSum: 使用存储Group的容器Hashmap的自带方法put,get,size来实现,其复杂度为o(1)addToGroup,delFromGroup: 通过getGroup函数来找到群,通过getPerson函数来找到人,并且对群的People(存储群成员的容器HashMap)来进行put,remove操作,需要维护群的变量ageSum,ageSquareSum,同时需要遍历人的acquaintance来动态维护群的变量valueSum, 复杂度o(N)queryGroupValueSum,queryGroupAgeMean,queryGroupAgeVar: 通过getGroup函数来找到群,并且直接返回群的变量valueSum,并通过计算得到平均数和方差,复杂度o(1)containsMessage,addMessage,getMessage: 使用存储Message的容器Hashmap的自带方法containsKey,put,get来实现,其复杂度为o(1)sendMessage: 通过getMessage方法来找到消息,通过getPerson来找人。之后按照jml按部就班改需要改的变量。单发消息复杂度o(N), 因为需要调用isCircle方法,群发消息复杂度o(N)
第十一次作业:
querySocialValue,queryMoney: 通过getPerson函数来找到人, 之后输出人的socialValue和Money变量,复杂度o(1)。queryReceivedMessages: 通过getPerson函数来找到人, 之后输出人的socialValue和Money变量,复杂度o(1)。containsEmojiId,storeEmojiId,queryPopularity: 使用存储 表情包ID-热度 的Hashmap容器emojis的自带方法containsKey,put,get来实现,其复杂度为o(1)deleteColdEmoji: 遍历容器emojis, 删除不满足要求的键值对;遍历存储信息的容器,删除相应键值对,复杂度o(N)。使用removeIf语句。sendIndirectMessage: 其他功能与sendMessage一样。并且用堆优化dijskra来计算最小路径,复杂度为o(NlogN)。
四、基于jml进行测试
其实并没有做太多相关单元测试,因为感觉有针对性的设计样例比单元测试更快,用Junit写测试文件比较麻烦,当然这是因为现有方法比较简单,当有大型工程的时候一定会需要的。
主要方法就是根据jml来编写一些针对性的测试样例,并且发现了一些问题。
以下是针对性构造的一份代码:
f = open("testpoint10.txt", "w")
f.write("ag 0\n")
for i in range(1112):
f.write("ap " + str(i) + " " + str(i) + " " + str(i) + "\n")
for j in range(1112):
f.write("atg " + str(j) + " 0\n")
f.write("qgam 0\n")
f.write("qgav 0\n")
f.close()
这主要测试是否会群里加超过1111个人。
还有一种方法就是和同学进行对拍。随机构造测试样例,扔进评测机里,来看是否会出现问题。
五、性能问题
目前可知:如果有指令的复杂度在o(N^2)及以上,就会有性能问题。
在三次作业的强测和互测中,所有的bug(自己的或者是互测屋内的)都是CTLE错误,时间性能不佳。
第九次作业
- 强测没有出现bug
- 互测在
queryBlockNum方法中发现了一个bug,原因是我完全照搬jml,使用了二重循环,因此复杂度高达o(N^3),被卡了CTLE,因此,我在addPerson和addRelation时维护了变量blockSum。在加人的时候,对blockSum加一;在加边的时候,我们先用isCircle方法判断原来两个人是否在一个连通分量里面,如果不在的话,就把blockSum减一 - 其实
isCircle函数也容易出现性能问题,因此我使用并查集来处理这件事情。我在addPerson和addRelation时对level进行改变。另外,其实使用dfs算法的复杂度应该是o(N + e),应该也不会出问题。
第十次作业
- 强测没有出现bug
- 互测总共出现了两个问题。
- 第一个是在
queryNameRank出现问题。原因是queryNameRank循环调用compareName,而在修正bug前,我关于Person的容器是用ArrayList存储的,因此,contains方法的复杂度为o(N)。compareName首先需要调用contains来判断是否异常,因此它复杂度也为o(N)。这样queryNameRank复杂度为o(N^2)。被卡CTLE。修正方法是修改存储Person的容器为HashMap。我同时还把所有需要改的容器数据结构都改为HashMap了。 - 第二个问题是在
MyPerson类中的isLinked方法。性能不好的原因是看传来的参数是实例而不是id,因此选择了containValue而不是containsKey。经过提醒,我了解到前者使用遍历查找,复杂度o(N),后者用哈希值计算索引,复杂度o(1)。addToGroup和delFromGroup由于需要维护valueSum变量,因此,需要循环调用isLinked方法来看一个人与哪些人有连接。因此上述两个方法复杂度均为o(N^2)。 - 还有一个容易出现性能问题的地方就是
queryGroupValueSum,这个方法需要求解图中点集子集的生成子图中所包含边的权值之和。正常写法肯定是二重循环调用queryValue。这样时间复杂度为o(N^2)。时间复杂度过高。我采用的是动态维护valueSum变量。在addRelation,addToGroup,delFromGroup方法中对valueSum进行修改,代码如下:
addRelation:
for (Group group : groups.values()) {
if (group.hasPerson(getPerson(id1)) && group.hasPerson(getPerson(id2))) {
((MyGroup) group).addValueSum(value);
}
}
加边的时候,如果某一个群里这两个人都有的话,那该群的valueSum要加上该边权值的2倍。
addToGroup:
for (Integer integer : people.keySet()) {
if (((MyPerson) person).isLinkedId(integer)) {
valueSum += 2 * ((MyPerson) person).queryValueThroughId(integer);
}
}
向群里加人的时候,遍历群里原有成员,如果某一成员和新加入成员有边连接的话,就把valueSum加上该边权值2倍。
delFromGroup:
for (Integer integer : people.keySet()) {
if (((MyPerson) person).isLinkedId(integer)) {
valueSum -= 2 * ((MyPerson) person).queryValueThroughId(integer);
}
}
向群里减人的时候,遍历群里剩下成员,如果某一成员和退群成员有边连接的话,就把valueSum减去该边权值2倍。
第十一次作业
- 强测没有bug
- 互测没有bug
- 其实经过两次的打击,第三次作业,同学关于避免出现性能问题方面都已经轻车熟路。在此背景下,倒是有
sendIndirectMessage方法容易出现问题。因为暴力dij的复杂度为o(N^2)。因此,我使用堆优化。这样,复杂度就降为了o(NlogN)
六、一些感想
这一章的主题是jml,形式化语言。这种语言可以用来规范某一个函数需要干的事情,同时也使框架更为清晰。但是,当方法所要实现的功能比较复杂的时候,jml就很容易写错,甚至可能比代码还容易写错,这是其不足之处。jml目前是并不成熟的一个方向,希望后续能对这个系统进行完善。
还有一个事情是,性能是不是要求的比较严格了?导致我不得不在某一些方法中使用耦合度比较高的方法来避免被卡T。比如queryGroupValueSum,我不得不在多个方法中动态维护valueSum。为了性能放弃“高内聚,低耦合”的编程思想是否值得?建议减少指令规模。当然这是我比较片面的一点点拙见,我以后可能还会重新看待这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号