【转载】Spark集群环境搭建——部署Spark集群
转在doublexi: https://www.cnblogs.com/doublexi/p/15624795.html
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等。并且已经安装好了hadoop集群。
如果还没有配置好的,参考我前面两篇博客:
Spark集群环境搭建——服务器环境初始化:https://www.cnblogs.com/doublexi/p/15623436.html
Spark集群环境搭建——Hadoop集群环境搭建:https://www.cnblogs.com/doublexi/p/15624246.html
集群规划:
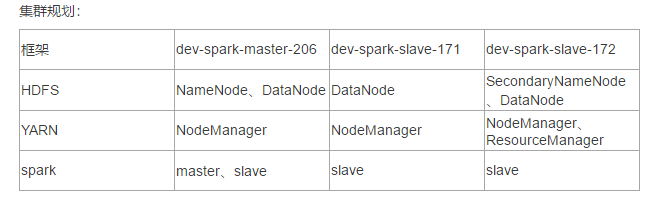
搭建Spark集群
1、下载:
下载地址:https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
01 02 | cd /data/apps/shell/softwarewget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz --no-check-certificate |
2、解压安装:
01 02 | tar xf spark-3.1.2-bin-hadoop3.2.tgzmv spark-3.1.2-bin-hadoop3.2 /data/apps/spark-3.1.2 |
编辑环境变量:
01 02 03 04 | vim /etc/profile## SPARK_HOMEexport SPARK_HOME=/data/apps/spark-3.1.2export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin |
加载使生效:
01 | source /etc/profile |
3、修改配置:
进入conf目录:
01 02 03 04 05 | cd /data/apps/spark-3.1.2/confmv spark-defaults.conf.template spark-defaults.confmv spark-env.sh.template spark-env.shmv log4j.properties.template log4j.properties |
修改slaves文件,添加从机
01 02 03 04 05 | vim slavesdev-spark-master-206dev-spark-slave-171dev-spark-slave-172 |
修改spark-defaults.conf
01 02 03 04 05 | vim spark-defaults.conf spark.master spark://dev-spark-master-206:7077spark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 1g |
修改spark-env.sh
01 02 03 04 05 06 07 08 | vim spark-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_162export HADOOP_HOME=/data/apps/hadoop-3.2.2/export HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoopexport SPARK_DIST_CLASSPATH=$(/data/apps/hadoop-3.2.2/bin/hadoop classpath)export SPARK_MASTER_HOST=dev-spark-master-206export SPARK_MASTER_PORT=7077 |
4、解决与Hadoop冲突
这里要注意,备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh 文件,如果同时加载到环境变量,会有冲突,我们选择改掉其中一个:
在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会产生冲突。
解决方案:
- 删除一组 start-all.sh / stop-all.sh 命令,让另外一组命令生效
- 将其中一组命令重命名。如:将 $HADOOP_HOME/sbin 路径下的命令重命名为:start-all-hadoop.sh / stopall-hadoop.sh
- 将其中一个框架的 sbin 路径不放在 PATH 中
这里我们选择第二种方式,修改Hadoop的脚本文件名。
01 02 03 04 05 | cd /data/apps/hadoop-3.2.2/sbin/mv start-all.cmd start-all-hadoop.cmdmv start-all.sh start-all-hadoop.shmv stop-all.cmd stop-all-hadoop.cmd mv stop-all.sh stop-all-hadoop.sh |
5、将spark目录分发到其他两个节点:
01 | rsync-script spark-3.1.2/ |
登录其他两个从节点,添加环境变量,并加载
01 02 03 04 05 | vim /etc/profile## SPARK_HOMEexport SPARK_HOME=/data/apps/spark-3.1.2export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin |
01 | source /etc/profile |
6、启动集群:(standalone模式)
在master节点上:
01 | start-all.sh |
在各个节点用jps查看:
master节点是因为运行了zookeeper和kafka,所以jps多了两个进程



在web界面查看spark ui:http://192.168.90.206:8080/

7、测试:
运行SparkPi案例测试:
01 | spark-submit --class org.apache.spark.examples.SparkPi /data/apps/spark-3.1.2/examples/jars/spark-examples_2.12-3.1.2.jar 1000 |
最后能看到这个输出就表示OK

8、设置history
在hdfs上创建spark-eventlog目录存放历史日志:
01 | hdfs dfs -mkdir /spark-eventlog |
修改spark-default
01 02 03 04 05 06 07 08 09 10 | # cd /data/apps/spark-3.1.2/conf/# vim spark-defaults.confspark.master spark://dev-spark-master-206:7077spark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 1g# 加上history server配置spark.eventLog.enabled truespark.eventLog.dir hdfs://dev-spark-master-206:8020/spark-eventlogspark.eventLog.compress true |
修改spark-env.sh
01 02 03 | vim spark-env.shexport SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://dev-spark-master-206:8020/spark-eventlog" |
spark.history.retainedApplications。设置缓存Cache中保存的应用程序历史记录的个数(默认50),如果超过这个值,旧的将被删除;
前提条件:启动hdfs服务(日志写到HDFS)
启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。
重启服务:
01 02 03 04 | stop-all.shstart-all.shstart-history-server.sh |
web查看地址:http://192.168.90.206:18080/

集群模式--Yarn模式(可选)
上面默认是用standalone模式启动的服务,如果想要把资源调度交给yarn来做,则需要配置为yarn模式:
参考:http://spark.apache.org/docs/latest/running-on-yarn.html
需要启动的服务:hdfs服务、yarn服务
需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二虎!
在Yarn模式中,Spark应用程序有两种运行模式:
- yarn-client。Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
- yarn-cluster。Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
二者的主要区别:Driver在哪里
1、关闭 Standalon 模式下对应的服务;开启 hdfs、yarn、historyserver 服务
2、修改 yarn-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn 服务
01 02 03 04 05 06 07 08 09 | # vim /data/apps/hadoop-3.2.2/etc/hadoop/yarn-site.xml <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value></property><property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value></property> |
备注:
yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务正使用的物理内存量,如果任务
超出分配值,则直接将其杀掉,默认是true
yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务
超出分配值,则直接将其杀掉,默认是true
3、修改配置,分发到集群
01 02 03 04 05 06 07 08 09 | # spark-env.sh 中这一项必须要有# cd /data/apps/spark-3.1.2/confexport HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoop# spark-default.conf(以下是优化)# 与 hadoop historyserver集成# vim spark-defaults.confspark.yarn.historyServer.address dev-spark-master-206:18080spark.yarn.jars hdfs:///spark-yarn/jars/*.jar |
# 将 $SPARK_HOME/jars 下的jar包上传到hdfs
01 02 03 | cd /data/apps/spark-3.1.2/jarshdfs dfs -mkdir -p /spark-yarn/jars/hdfs dfs -put * /spark-yarn/jars/ |
4、测试:
记得,先把Master与worker进程停掉,否则会走standalone模式
01 02 | # 停掉standalone模式stop-all.sh |
01 02 03 04 05 | # clientspark-submit --master yarn \--deploy-mode client \--class org.apache.spark.examples.SparkPi \$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000 |
在提取App节点上可以看见:SparkSubmit、YarnCoarseGrainedExecutorBackend
在集群的其他节点上可以看见:YarnCoarseGrainedExecutorBackend
在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)
01 02 03 04 05 | # clusterspark-submit --master yarn \--deploy-mode cluster \--class org.apache.spark.examples.SparkPi \$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000 |
在提取App节点上可以看见:SparkSubmit
在集群的其他节点上可以看见:YarnCoarseGrainedExecutorBackend、ApplicationMaster(Driver运行在此)
在提取App节点上看不见最终的结果
整合HistoryServer服务
前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
Hadoop:JobHistoryServer
Spark:HistoryServer
修改 spark-defaults.conf,并分发到集群
01 02 03 04 05 06 07 08 09 10 11 | # vim spark-defaults.confspark.master spark://dev-spark-master-206:7077spark.eventLog.enabled truespark.eventLog.dir hdfs://dev-spark-master-206:8020/spark-eventlogspark.eventLog.compress truespark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 1gspark.yarn.historyServer.address dev-spark-master-206:18080spark.history.ui.port 18080spark.yarn.jars hdfs:///spark-yarn/jars/*.jar |
发送到其他两台机器:
01 | rsync-script spark-defaults.conf |
重启/启动 spark 历史服务
01 02 | stop-history-server.shstart-history-server.sh |
测试:
01 02 03 04 05 | # clientspark-submit --master yarn \--deploy-mode client \--class org.apache.spark.examples.SparkPi \$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 2000 |
登录yarn的地址:http://192.168.90.172:8088/

点击history会自动跳转到spark的history页面:

至此,spark集群搭建完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号