


目录
- 具体分工
- 需求分析
- PSP表格
- 解题思路描述与设计实现说明
- 附加题设计与展示
- 关键代码解释
- 性能分析与改进
- 单元测试
- Github的代码签入记录
- 遇到的代码模块异常或结对困难及解决方法
- 评价队友
- 学习进度条
具体分工
-
我
- 使用工具爬取论文信息
- 加入权重的词频统计
- 单元测试
-
队友
- 字符、有效行、单词数目统计,单词词频统计
- 自定义输入输出文件
- 新增词组词频统计功能
- 自定义词频统计输出
- 多参数的混合使用
- 博客编辑排版
- 效能分析
需求分析
- 基本功能
- 使用工具爬取论文信息,输出到result.txt
- 统计文件的字符数
- 统计文件的单词数
- 统计文件的有效行数
- 按照规定格式输出结果至文件result.txt
- 进阶功能
- 自定义输入输出文件
- 加入权重的词频统计
- 新增词组词频统计功能
- 自定义词频统计输出
- 多参数的混合使用
解题思路描述与设计实现说明
-
爬虫使用
我们的爬虫是由java来实现的。
代码部分如下:
主要分为三个部分:
* 第一个部分主函数,用于输入与输出:
使用Jsoup方法,将爬取出的源代码转换成document类。再通过筛选标签dt[class=ptitle]寻找子页的连接,对子网页进行二次爬取,再将爬取的代码进行筛选,得到所需的文本,生成result.txt。
public static void main(String[] args) {
int number=0;
int i=0;
String code=geturlcode(url);
String code1=null;
//将源代码转换为Doc
Document doc= Jsoup.parse(code);
//筛选子网页连接
Elements ele=(doc).select("dt[class=ptitle]");
number=ele.size();
File f=new File("result.txt");
try {
PrintWriter output = new PrintWriter(f);
for(Element link : ele){
String test="http://openaccess.thecvf.com/";
link=link.child(1);
test=test+link.attr("href");
String text =null;
//读取子网页内容
text=geturlcode(test);
text=gettext(text);
output.print(i);
i++;
output.print("\r\n");
output.print(text);
}
output.close();
}catch (Exception e) {
System.out.println("写文件错误");
}
System.out.println("成功");
}
* 第二个部分文本筛选:
通过标签<div>与<id>筛选出标题与摘要,返回字符串。
//筛选标题与摘要
public static String gettext(String code)
{
String a,b,c;
Document doc=Jsoup.parse(code);
Elements ele1=(doc).select("div[id=papertitle]");
a=ele1.text();
Elements ele2=(doc).select("div[id=abstract]");
b=ele2.text();
c="Title: "+a+"\r\n"+"Abstract: "+b+"\r\n"+"\r\n"+"\r\n";
return c;
}
* 第三个部分网页源代码的获取:
爬取的方式通过java自带的URL方法,建立连接,读取网页的源代码,返回代码。
//爬取网页源代码
public static String geturlcode(String url) {
//定义url
URL newurl = null;
//定义连接
URLConnection urlcon = null;
//定义输入
InputStream input = null;
//定义读取
InputStreamReader reader = null;
//定义输出
BufferedReader breader = null;
StringBuilder code = new StringBuilder();
try {
//获取地址
newurl = new URL(url);
//获取连接
urlcon = newurl.openConnection();
//获取输入
input = urlcon.getInputStream();
//读取输入
reader = new InputStreamReader(input);
//输出
breader = new BufferedReader(reader);
String temp = null;
while ((temp = breader.readLine()) != null) {
code.append(temp + "\r\n");
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return code.toString();
}
}
-
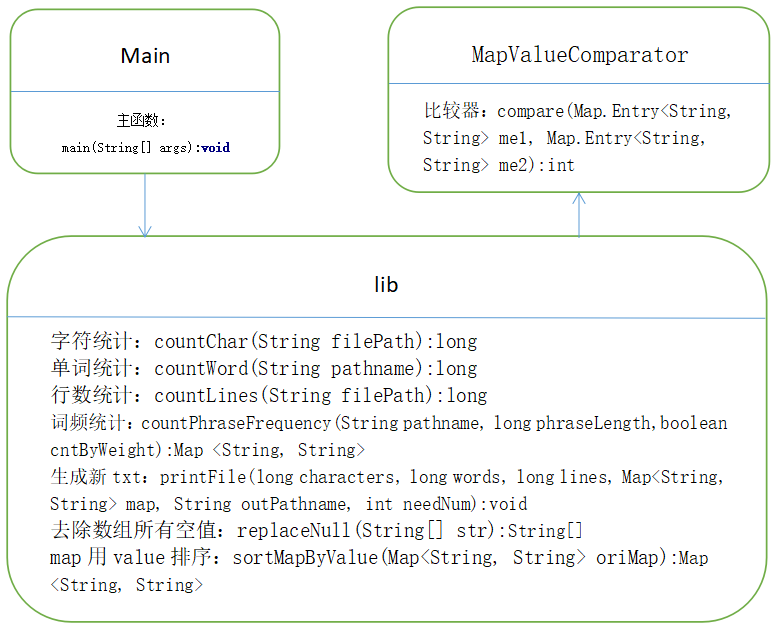
代码组织与内部实现设计(类图)
- 类图
![1]()
- 流程图
![]()
- 类图
-
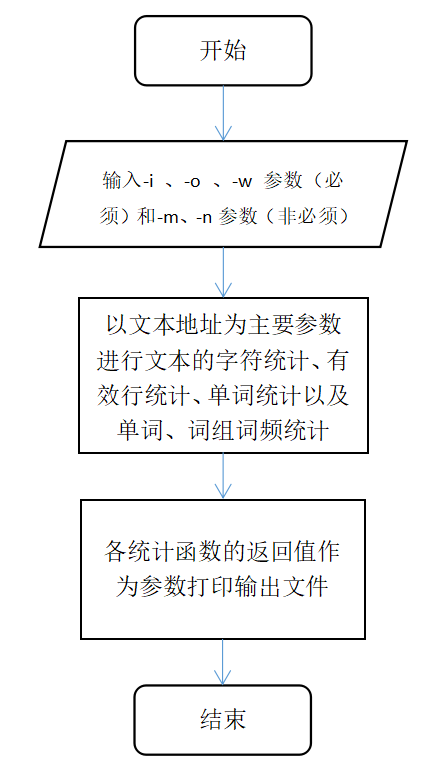
算法的关键与关键实现部分流程图
- 词组词频统计功能的实现
![]()
- 判断词组是否符合要求
![]()
- 词组词频统计功能的实现

附加题设计与展示
-
设计的创意独到之处
? -
实现思路
?? -
实现成果展示
???
关键代码解释
- 控制台传参
遍历args,根据args[i]的值取args[i+1]的值处理。
for(int i=0;i<args.length;i+=2){
switch(args[i]){
/*-w 参数设定是否采用不同权重计数*/
case "-w":
if(Integer.parseInt(args[i+1])==1){
System.out.println("采用权重计数。");
cntByWeight=true;
}else{
System.out.println("不采用权重计数。");
cntByWeight=false;
}
break;
/*-i 参数设定读入文件的存储路径*/
case "-i":
inPathname=args[i+1];
System.out.println("读入文件路径为"+inPathname+"。");
break;
/*-o 参数设定生成文件的存储路径*/
case "-o":
outPathname=args[i+1];
System.out.println("生成文件路径为"+outPathname+"。");
break;
/*-m 参数设定统计的词组长度*/
/*使用词组词频统计功能时,不再统计单词词频,而是统计词组词频,但不影响单词总数统计*/
/*未出现 -m 参数时,不启用词组词频统计功能,默认对单词进行词频统计*/
case "-m":
phraseLength=Integer.parseInt(args[i+1]);
System.out.println("采用词组词频统计功能,词组长度为"+phraseLength+"。");
break;
/*-n 参数设定输出的单词数量*/
/*未出现 -n 参数时,不启用自定义词频统计输出功能,默认输出10个*/
case "-n":
needNum=Integer.parseInt(args[i+1]);
System.out.println("输出的单词/词组数量为"+needNum+"。");
break;
}
}
- 字符统计
用bufferedreader.readline()按行读取每一个非空且非论文编号的字符个数,每行字符个数额外+1(换行符算一个),每读完一篇论文将总字符数-17("abstract: "+"title: ")。
BufferedReader br = new BufferedReader(new FileReader(file));
while (br.readLine() != null) {
try {
while ((sb = br.readLine()) != null) {
if (sb.length() == 0) {
break;
}
characters += (sb.length() + 1);
}
characters -= 17;
br.readLine();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 单词统计
用bufferedreader.readline()按行读取,每读完一篇论文将总单词数-2("abstract"+"title")。文件内容用.split()方法分词并统计符合要求的个数。
StringBuilder sb = new StringBuilder();
while (br.readLine() != null) {
String temp = null;
try {
while ((temp = br.readLine()) != null) {
if (temp.length() == 0) {
break;
}
sb.append(temp);
sb.append(" ");//每行结束多读一个空格
}
words -= 2;
br.readLine();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
……
- 有效行统计
每读一行行数+1,论文编号行和空白行除外。
代码略。
- 生成新文件
以之前各统计函数的返回值为参数在指定路径生成新txt。
代码略。
- map用value排序
map用list存储然后使用sort()方法排序。
public static Map<String, String> sortMapByValue(Map<String, String> oriMap) {
if (oriMap == null || oriMap.isEmpty()) {
return null;
}
Map<String, String> sortedMap = new LinkedHashMap<String, String>();
List<Map.Entry<String, String>> entryList = new ArrayList<Map.Entry<String, String>>(oriMap.entrySet());
entryList.sort(new MapValueComparator());
Iterator<Map.Entry<String, String>> iter = entryList.iterator();
Map.Entry<String, String> tmpEntry = null;
while (iter.hasNext()) {
tmpEntry = iter.next();
sortedMap.put(tmpEntry.getKey(), tmpEntry.getValue());
}
return sortedMap;
}
- 比较器Comparator
之前的比较器有重大bug,直接把String拿去比较了,这次修改的时候才发现>_<。
public class MapValueComparator implements Comparator<Map.Entry<String, String>> {
@Override
/*负整数:当前对象的值 < 比较对象的值 , 位置排在前
* 零:当前对象的值 = 比较对象的值 , 位置不变
*正整数:当前对象的值 > 比较对象的值 , 位置排在后
*/
public int compare(Map.Entry<String, String> me1, Map.Entry<String, String> me2) {
int flag=0;
if(Long.parseLong(me2.getValue()) > Long.parseLong(me1.getValue())){
flag=1;
}else if(Long.parseLong(me1.getValue()) > Long.parseLong(me2.getValue())){
flag=-1;
}else if(Long.parseLong(me1.getValue()) == Long.parseLong(me2.getValue())){
flag=me1.getKey().compareTo(me2.getKey());
}
return flag;
}
}
- 去除数组中所有空值
用StringBuffer来存放数组中的非空元素,用“;”分隔,用String的split方法分割,得到数组。
public static String[] replaceNull(String[] str) {
//用StringBuffer来存放数组中的非空元素,用“;”分隔
StringBuilder sb = new StringBuilder();
for (int i = 0; i < str.length; i++) {
if ("".equals(str[i])) {
continue;
}
sb.append(str[i]);
if (i != str.length - 1) {
sb.append(";");
}
}
//用String的split方法分割,得到数组
str = sb.toString().split(";");
return str;
}
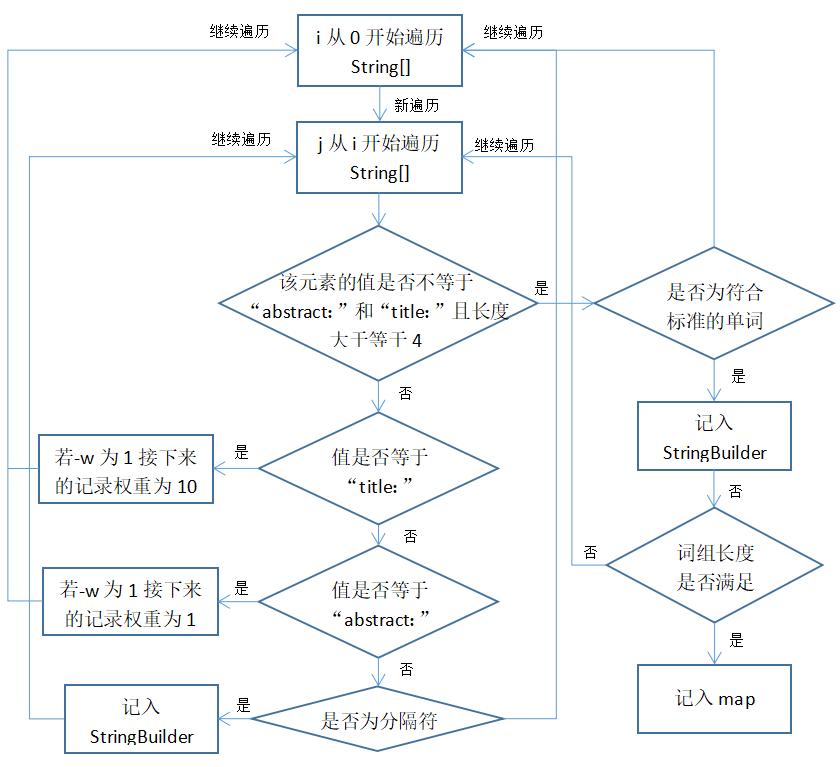
- 词频统计
主要就是先记录文件为一个String,然后用分隔符切割成String[],并保留分隔符,根据词组长度筛选符合条件的词组,根据是否以权重统计记入map,然后排序。
代码较长,建议看流程图更加直观。
public static Map<String, String> countPhraseFrequency(String pathname, long phraseLength,boolean cntByWeight) {
Map<String, String> map = new HashMap<String, String>();
boolean flag = false;
try {
String encoding = "UTF-8";
File file = new File(pathname);
if (file.isFile() && file.exists()) {
InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
/*读取文件数据*/
StringBuffer sb = null;
BufferedReader br1;
try {
br1 = new BufferedReader(new FileReader(file));
String temp = br1.readLine();
sb = new StringBuffer();
while (temp != null) {
sb.append(temp);
sb.append(" ");//每行结束多读一个空格
temp = br1.readLine();
}
} catch (Exception e) {
e.printStackTrace();
}
/*读取的内容*/
String info = null;
if (sb != null) {
info = sb.toString();
}
/*保留分隔符*/
Pattern p =Pattern.compile("[^a-zA-Z0-9]");
Matcher m = null;
String s[] = new String[0];
if (info != null) {
m = p.matcher(info);
s = info.split("[^a-zA-Z0-9]");
}
if(s.length > 0)
{
int count = 0;
while(count < s.length)
{
if(m.find())
{
s[count] += m.group();
}
count++;
}
}
s = replaceNull(s);
/*统计单词个数*/
for (int i = 0; i < s.length; i++) {
StringBuilder content = new StringBuilder();
int cnt=0;
for (int j = i; cnt<phraseLength&&j<s.length; j++) {
if (s[j].length() >= 4 && !s[j].toLowerCase().equals("title:") && !s[j].toLowerCase().equals("abstract:")) {
String temp = s[j].substring(0, 4);
temp = temp.replaceAll("[^a-zA-Z]", "");
if (temp.length() >= 4) {
cnt++;
if(cnt==phraseLength){
content.append(s[j].substring(0,s[j].length()-1));
}else{
content.append(s[j]);
}
} else {
break;
}
} else if (s[j].toLowerCase().equals("title:")) {
flag = true;
break;
} else if (s[j].toLowerCase().equals("abstract:")) {
flag = false;
break;
} else if(s[j].matches("[^a-zA-Z0-9]")&&cnt>=1){
content.append(s[j]);
}else{
break;
}
if (cnt==phraseLength) {
String phrase = content.toString();
if (flag && cntByWeight) {
if (map.containsKey(phrase.toLowerCase())) {//判断Map集合对象中是否包含指定的键名
map.put(phrase.toLowerCase(), Integer.parseInt(map.get(phrase.toLowerCase())) + 10 + "");
} else {
map.put(phrase.toLowerCase(), 10 + "");
}
} else {
if (map.containsKey(phrase.toLowerCase())) {//判断Map集合对象中是否包含指定的键名
map.put(phrase.toLowerCase(), Integer.parseInt(map.get(phrase.toLowerCase())) + 1 + "");
} else {
map.put(phrase.toLowerCase(), 1 + "");
}
}
}
}
}
/*map排序*/
map = sortMapByValue(map);
read.close();
} else {
System.out.println("找不到指定的文件");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
return map;
}
性能分析与改进
-
改进的思路
- 多线程
参考大佬的代码把原来Main函数中顺序执行的计数函数改为建立线程池,并行运行三个计数函数,词频统计由于开销较大所以独立运行。
- 多线程
ExecutorService executor = Executors.newCachedThreadPool();
//计算字符数
String finalInPathname = inPathname;
Future<Long> futureChar = executor.submit(() -> lib.countChar(finalInPathname));
//计算单词数
Future<Long> futureWord = executor.submit(() -> lib.countWord(finalInPathname));
//计算行数
Future<Long> futureLine = executor.submit(() -> lib.countLines(finalInPathname));
* 简化代码
之前写的较匆忙,有很多地方冗余或存在风险,在不改变功能的情况下进行了精简和错误预防。
如:
info = sb.toString();
改为
if (sb != null) {
info = sb.toString();
}
* 其他改动
原先记录文档内容采用的是用StringBuffer,后来与StringBuilder做了比较,相比来说StringBuilder更快,虽然在多线程环境下不能保证线程安全,但线程池中只有一个线程有用到StringBuilder,因此还是选择了速度更快的StringBuilder替代StringBuffer。
对于分割字符串,我最初是准备StringTokenizer替代.splite()方法。但是String.Split()使用正则表达式,而StringTokenizer的只是使用逐字分裂的字符。因此如果我想用更复杂的逻辑比单个字符(如\ r \ n分割)来标记一个字符串,所以还是选择String.Split() 。
-
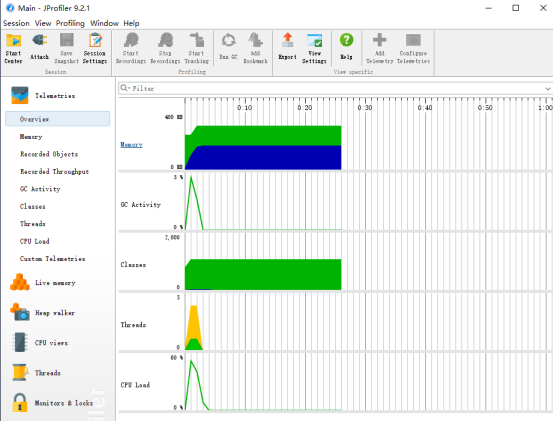
性能分析图和程序中消耗最大的函数

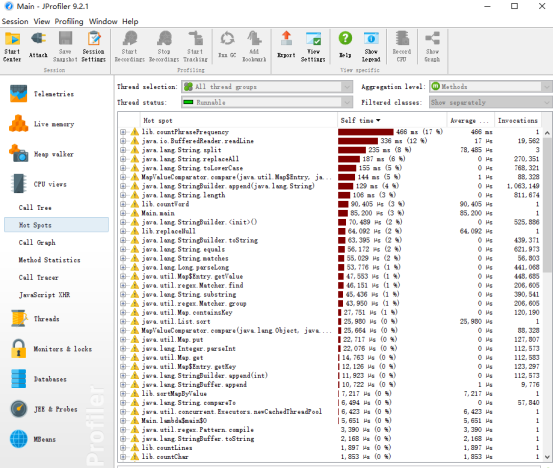
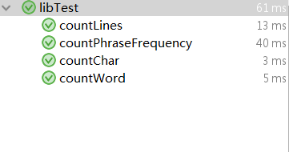
单元测试
代码如下:
public void countChar() {
System.out.println("count Char1");
long r=lib.countChar("C:\\Users\\Administrator\\Desktop\\test\\test2.txt");
assertEquals(1040,r);
System.out.println("count Char2");
r=lib.countChar("C:\\Users\\Administrator\\Desktop\\test\\test.txt");
assertEquals(2914,r);
System.out.println("count Char3");
r=lib.countChar("C:\\Users\\Administrator\\Desktop\\test\\test3.txt");
assertEquals(418,r);
}
@Test
public void countWord() {
System.out.println("count Word1");
long w=lib.countWord("C:\\Users\\Administrator\\Desktop\\test\\test2.txt");
assertEquals(208,w);
System.out.println("count Word2");
w=lib.countWord("C:\\Users\\Administrator\\Desktop\\test\\test.txt");
assertEquals(287,w);
System.out.println("count Word3");
w=lib.countWord("C:\\Users\\Administrator\\Desktop\\test\\test3.txt");
assertEquals(42,w);
}
@Test
public void countPhraseFrequency() {
System.out.println("count Phrase1");
String f;
StringBuilder content = new StringBuilder("");
int i=1;
Map<String, String> t=lib.countPhraseFrequency("C:\\Users\\Administrator\\Desktop\\test\\test2.txt",5,true);
Set<String> keys = t.keySet();
for (String key : keys) {
content.append("<").append(key).append(">:").append(t.get(key));
i++;
if (i > 5)
break;
content.append("\r\n");
}
f=content.toString();
assertEquals("<aaaa aaaa aaaa aaaa aaaa>:192\r\n",f);
System.out.println("count Phrase2");
i=1;
content = new StringBuilder("");
t=lib.countPhraseFrequency("C:\\Users\\Administrator\\Desktop\\test\\test.txt",5,true);
keys = t.keySet();
for (String key : keys) {
content.append("<").append(key).append(">:").append(t.get(key));
i++;
if (i > 5)
break;
content.append("\r\n");
}
f=content.toString();
assertEquals("<wild with generative adversarial network>:10\r\n" +
"<clear high-resolution face from>:2\r\n" +
"<active perception, goal-driven navigation>:1\r\n" +
"<agent must first intelligently navigate>:1\r\n" +
"<challenging dataset wider face demonstrate>:1",f);
System.out.println("count Phrase3");
i=1;
content = new StringBuilder("");
t=lib.countPhraseFrequency("C:\\Users\\Administrator\\Desktop\\test\\test3.txt",4,true);
keys = t.keySet();
for (String key : keys) {
content.append("<").append(key).append(">:").append(t.get(key));
i++;
if (i > 4)
break;
content.append("\r\n");
}
f=content.toString();
assertEquals("<active perception, goal-driven>:1\r\n" +
"<commonsense reasoning, long-term>:1\r\n" +
"<driven navigation, commonsense reasoning>:1\r\n" +
"<goal-driven navigation, commonsense>:1",f);
}
@Test
public void countLines() {
System.out.println("count Lines");
long l=lib.countLines("C:\\Users\\Administrator\\Desktop\\test\\test2.txt");
assertEquals(4,l);
System.out.println("count Lines");
l=lib.countLines("C:\\Users\\Administrator\\Desktop\\test\\test.txt");
assertEquals(6,l);
System.out.println("count Lines");
l=lib.countLines("C:\\Users\\Administrator\\Desktop\\test\\test3.txt");
assertEquals(2,l);
}
主要对字符统计,行数统计,单词统计,词组词频排序进行测试,每个单元用三个样例进行测试。
Github的代码签入记录

 由于使用github不熟,所以代码签入比较混乱,commit也比较随意,以后会慢慢改进的。
#遇到的代码模块异常或结对困难及解决方法
* 爬取网页源代码异常
爬取的文本会在开头加上“/n”字符,后来发现是整理文本时,将"\n“错打成”/n“。
* map排序及统计异常
这个是上次作业遗留的问题了,我为什么这么晚才发现.>_<.!!!之前存map的时候,虽然计算的时候会转为long计算,但是储存value的值是String格式。写比较器的时候忽略了这点直接使用了compareTo方法,后来随手一测发现不对,3居然排在101上面。一开始以为是计数逻辑的问题,找了好久才发现原来是比较器写错了。把value值转为String比较后问题解决。
* 进程结束异常
程序运行完后过一段时间进程才会结束,后来发现是忘记把executor对象shutdown了。
* 结对困难
国庆两个人都要回家所以在前一天晚上制定了工作计划,国庆期间很完美的完成了,几乎没遇到什么困难。
#评价队友
* ##值得学习的地方
做事认真,仔细。能够发现一些不容易发现的问题。
* ##需要改进的地方
彼此交流不足。
#学习进度条
由于使用github不熟,所以代码签入比较混乱,commit也比较随意,以后会慢慢改进的。
#遇到的代码模块异常或结对困难及解决方法
* 爬取网页源代码异常
爬取的文本会在开头加上“/n”字符,后来发现是整理文本时,将"\n“错打成”/n“。
* map排序及统计异常
这个是上次作业遗留的问题了,我为什么这么晚才发现.>_<.!!!之前存map的时候,虽然计算的时候会转为long计算,但是储存value的值是String格式。写比较器的时候忽略了这点直接使用了compareTo方法,后来随手一测发现不对,3居然排在101上面。一开始以为是计数逻辑的问题,找了好久才发现原来是比较器写错了。把value值转为String比较后问题解决。
* 进程结束异常
程序运行完后过一段时间进程才会结束,后来发现是忘记把executor对象shutdown了。
* 结对困难
国庆两个人都要回家所以在前一天晚上制定了工作计划,国庆期间很完美的完成了,几乎没遇到什么困难。
#评价队友
* ##值得学习的地方
做事认真,仔细。能够发现一些不容易发现的问题。
* ##需要改进的地方
彼此交流不足。
#学习进度条
- 进度表
| 领域 | skills | 课前评估 | 第五次实践作业 | 课后评估 |
|---|---|---|---|---|
| 编程 | 对编程整体的理解 | 3 | 3.3 | 6 |
| 编程 | 程序理解 | 4 | 4.2 | 7 |
| 编程 | 单元测试 | 2 | 2.5 | 5 |
| 编程 | 性能分析 | 1 | 1.2 | 5 |
| 软件工程 | 需求分析 | 2 | 2.5 | 6 |
| 软件工程 | 个人源码管理 | 1 | 1.2 | 5 |
| 职业技能 | 自主学习能力 | 2 | 2.3 | 5 |
| 职业技能 | 任务计划 | 2 | 2.2 | 6 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号