
python爬虫抓取妹子图片
1.使用模块
bs4
requests
2.实现思路
首先通过requests库的get方法获取对应url地址的Response对象,然后得到content(字节类型信息),解码,并编码为utf-8,再通过bs转换为lxml类型,分析具体的样式,定位到目标图片所在标签,得到图片的src和标题,最后下载妹子图片并保存到本地
3.主要接口
1.获取妹子图片下载地址和标题
这里主要有两点要考虑:
1.网页的编码问题
2.怎么定位到妹子图片
对于第1点,如果网站编码格式为utf-8,则不需要考虑,如果不是,则需要解码。比如我爬取的https://pic.netbian.com/4kmeinv/这个地址,格式为GBK编码。怎么查看对应网站的编码呢,点击F12,然后输入document.charset即可看到,如下图所示。
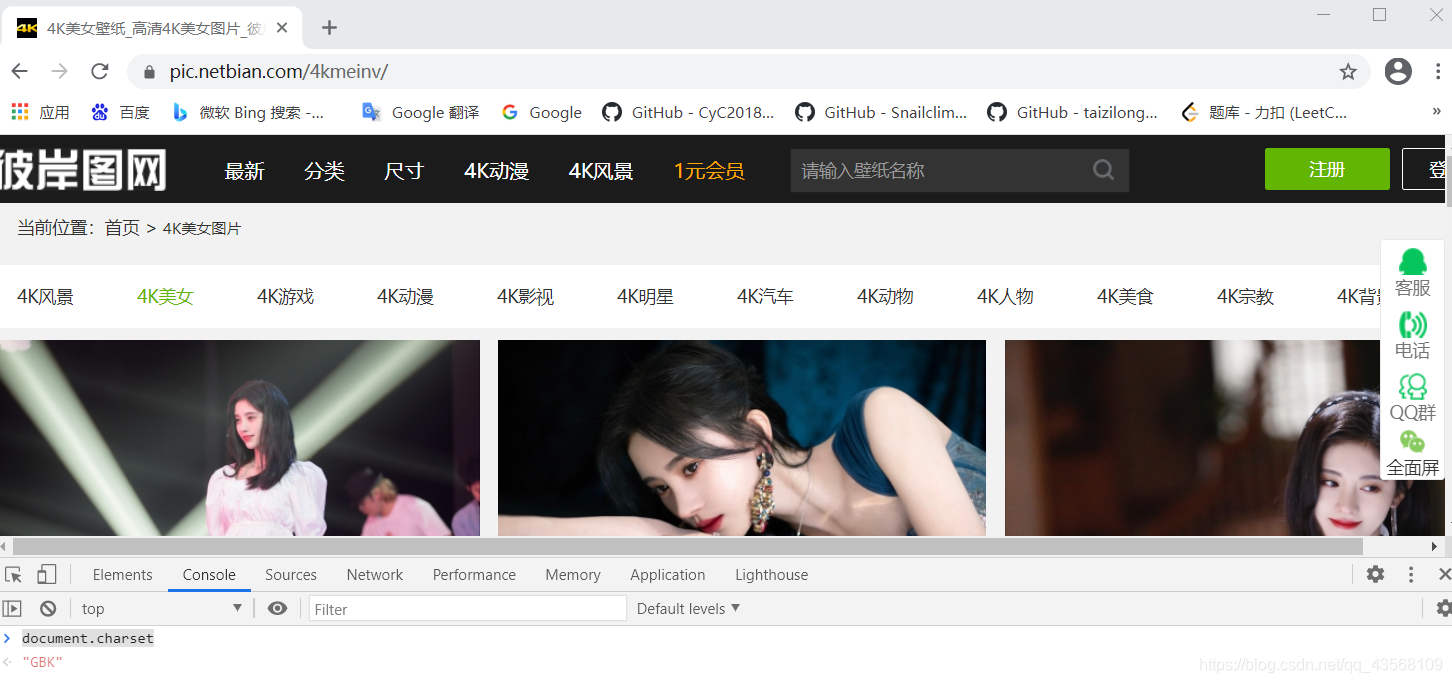
对于第2点,同样先F12进入开发者模式,然后点击红框标记的图标,放到妹子图片上,即可看到对应的样式,分析发现所有妹子的图片都在li标签里面,并且遵循li a img 的规律,所以这时候可以通过bs4的select函数定位到img标签,获取的是一个list,然后得到里面的src和alt,分别对应下载资源和标题。将鼠标悬停在src,即可看到实际的下载地址,一般是网站主域名+图片src

代码实现:
def imagespider(url):
global headers
try:
urls = []
r = requests.get(url, headers=headers)
#由于某些网站编码不一定是utf-8,需要译码
r.content.decode('GBK')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.content, 'lxml')
lis = soup.select("li a img")
for li in lis:
try:
img = li['src']
name = li['alt']
url1 = 'https://' + 'pic.netbian.com/' + img
if url1 not in urls:
download(url1, name)
except Exception as err:
print(err)
except:
return ''
2.根据地址和标题,下载图片,并保存到本地
利用requests,根据图片资源,得到content,然后写入磁盘即可
实现代码:
def download(url1, name ):
global count
count = count + 1
r = requests.get(url1, timeout=100)
data = r.content
with open("F:/crawling/girl/" + str(count) + '.' + str(name) + '.jpg', 'wb') as f:
f.write(data)
print('已打印第{}张图片'.format(count))
3.主函数
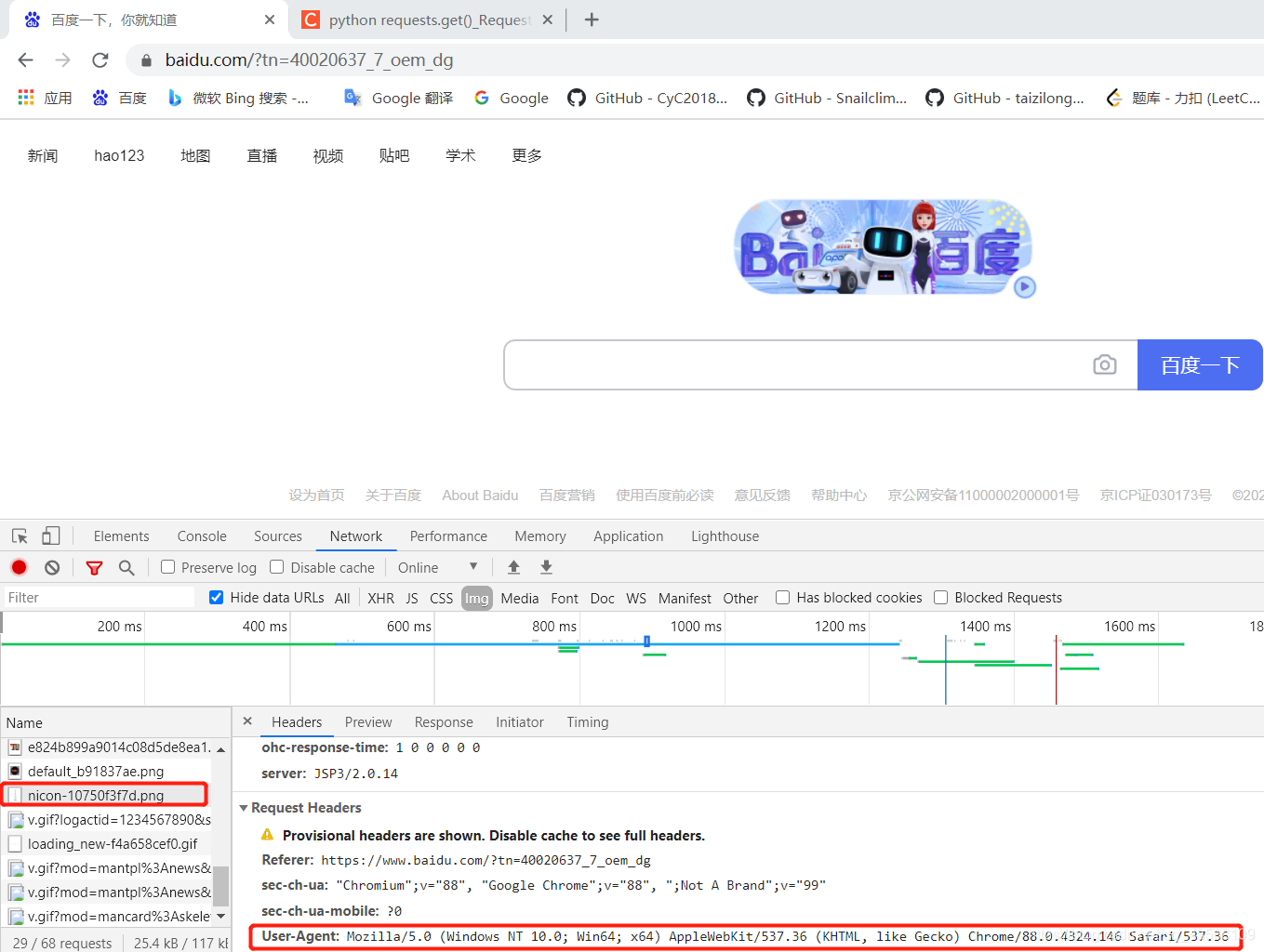
首先通过headers模拟浏览器访问,headers怎么获取?
打开任何一个网页,比如百度,F12,然后刷新一下,随便点击左边一个请求,即可找到User-Agent键值对,就是我们需要的headers。
然后分析美女图片每一页的url变化,发现只有一个数字在变,所以我们可以通过一个循环,获取所有页面的url。
实现代码:
if __name__ == '__main__':
t_start = time.time()
#获取用户代理,模仿浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36'}
count = 0
for i in range(1, 9):
url = 'https://' + 'pic.netbian.com/4kmeinv/index_' + str(i) + '.html'
imagespider(url)
t_end = time.time()
print('the normal way take %s s' % (t_end - t_start))
4.最终效果

4.完整代码
爬虫代码持续跟新中,目前增加了多线程版本和任务队列版本,github地址:
https://github.com/xqxls/spider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号