Python爬虫教程-03-使用 chardet 检测编码
Spider-03-使用chardet
继续学习python爬虫,我们经常出现解码问题,因为所有的页面编码都不统一,我们使用chardet检测页面的编码,尽可能的减少编码问题的出现
网页编码问题解决
- 使用chardet 可以自动检测页面文件的编码格式,但是也有可能出错
- 需要安装chardet,
- 如果使用Anaconda环境,使用下面命令:
conda install chardet
- 如果不是,就自己手动在【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】>【chardet】>【install】
具体操作截图:
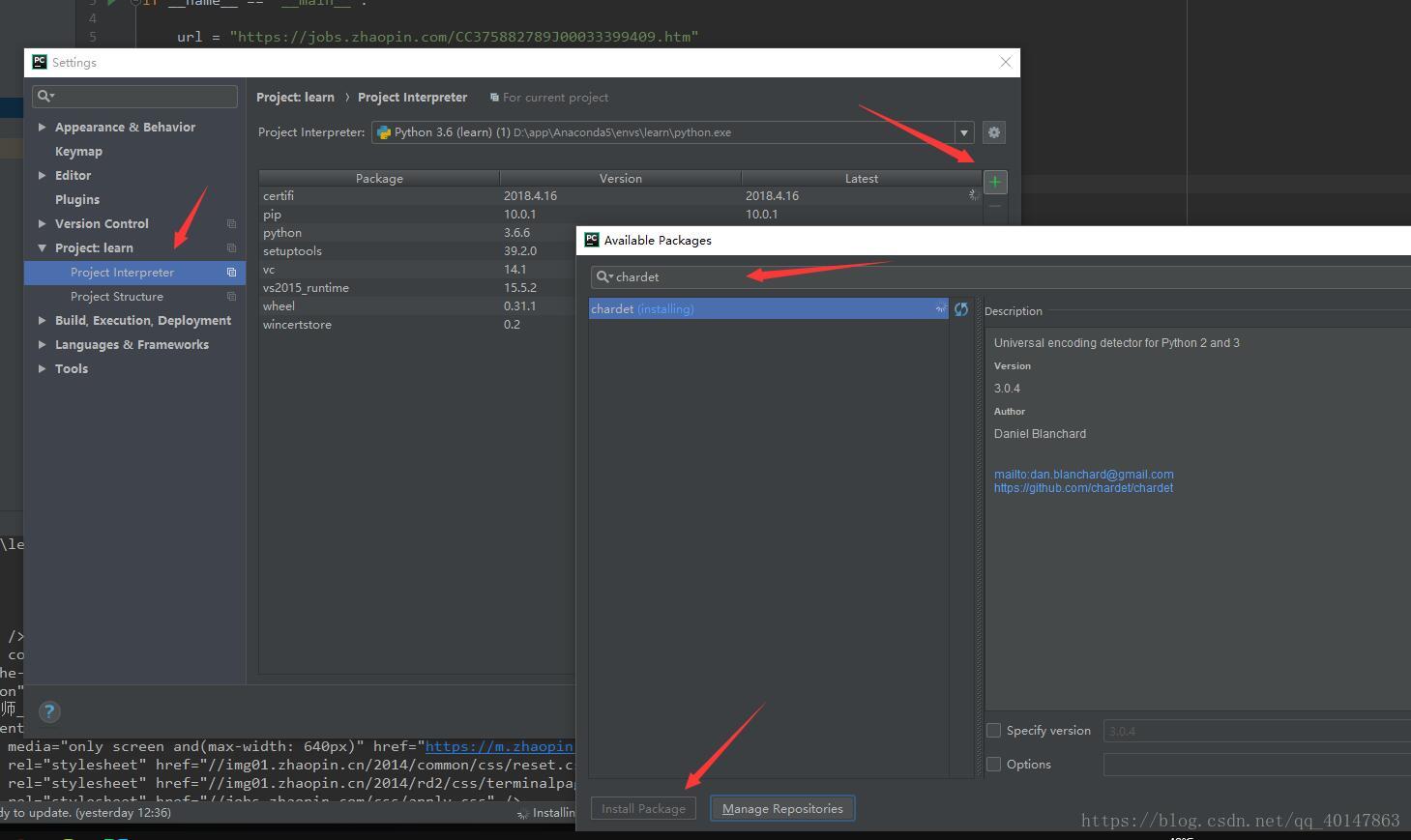
案例v2
- py03chardet.py文件:https://xpwi.github.io/py/py爬虫/py03chardet.py
# py03chardet.py
# 使用request下载页面,并自动检测页面编码
from urllib import request
import chardet
if __name__ == '__main__':
url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm'
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
cs = chardet.detect(html)
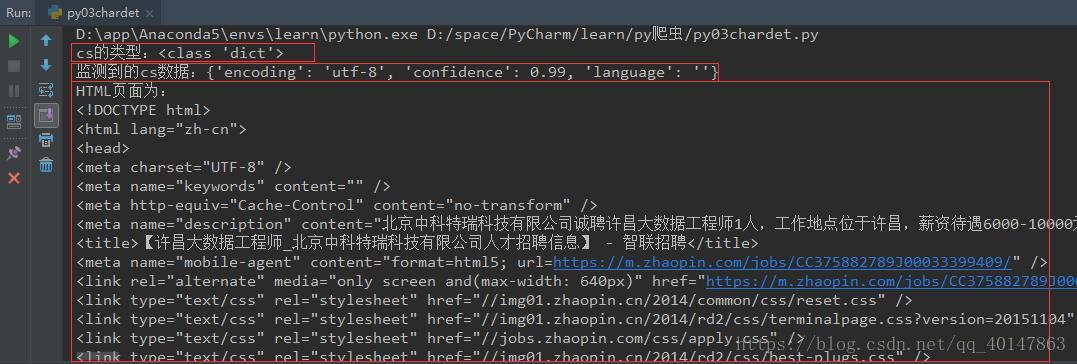
print("cs的类型:{0}".format(type(cs)))
print("监测到的cs数据:{0}".format(cs))
html = html.decode(cs.get("encoding", "utf-8"))
# 意思是监测到就使用监测到的,监测不到就使用utf-8
print("HTML页面为:\n%s" % html)
右键运行,截图如下
编码检测就介绍完了,最要的功能是检测页面的编码,尽可能的减少编码问题的出现
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号