kafka集群搭建
kafka集群搭建
Date:9/6/2017 5:44:21 PM
Author:xnchall
- 准备篇
- 操作系统
本文适用于linux、mac os - 资源包下载
kafka资源包:http://kafka.apache.org/downloads.html
zookeeper资源包:https://zookeeper.apache.org/releases.html#download
由于kafka是依托于zookeeper管理,可以理解为zookeeper是kafka的代理。
分别解压缩包tar -zxvf kafka_2.10-0.9.0.1.tgztar -zxvf zookeeper-3.5.2-alpha.tar.gz -
zookeeper集群搭建
本文是模拟在一台机器上搭建zk集群,原理和多台主机搭建集群一样,只要集群主机之间可通过网络访问,均可以按照如下方式去实现集群搭建-
模拟多台主机
分别将上述zk解压包复制三份,具体如下:cp -r Documents/tools/zookeeper-3.5.2-alpha Software/zookeeper-3.5.2-alpha0cp -r Documents/tools/zookeeper-3.5.2-alpha Software/zookeeper-3.5.2-alpha1cp -r Documents/tools/zookeeper-3.5.2-alpha Software/zookeeper-3.5.2-alpha2
如下图![]()
然后分别去修改三个zookeeper的配置文件,将conf/zoo_sample.cfg内容复制,创建新文件zoo.cfgcp zoo_sample.cfg zoo.cfg
然后修改zoo.cfg内容,配置如下:clientPort=2181dataDir=/tmp/zookeeper1syncLimit=2initLimit=5tickTime=2000server.0=127.0.0.1:8880:7770server.1=127.0.0.1:8881:7771server.2=127.0.0.1:8882:7772
说明:
1> zoo.cfg配置文件中server.X=host:port1:port2,其中X分别是复制三个zk文件夹编号(用来标识该机器在集群中的机器序列号),即就是0、1、2。X为集群中该机器的编号(集群中唯一),该配置需要和dataDir目录下文件myid中的内容一致,为数字。集群启动的时候会去dataDir目录下查找myid,检查编号是否一致。因此在启动之前需要手动创建myid文件,myid文件只有一行,且值必须是X
2> port1是用于leader之间通信,port2是用于laeder选举。
3> 每个zookeeper启动端口不能相同,即就是zoo.cfg中【clientPort=】参数
4> 按照上述要求分别去完成其余zk配置文件创建与设置 -
启动zookeeper集群
首先需要分别启动三个zookeeperzkServer.sh start zoo.cfgbin/zkCli.sh -server host:2181 #随机选一个zookeeper作为客户端,没必要选leader
我们选取zookeeper0作为客户端的启动,注意的是启动命令需要输入zookeeper0目录下zoo.cfg中配置的端口zkCli.sh -server localhost:2181![]()
可以看到zookeeper集群启动成功了,也意味着准备阶段完成了,接下来搭建kafka集群。
-


- 小试牛刀
- 集群搭建:
1> 将已经准备好kafka资源解压文件,分别将kafka集群目录的配置文件夹config目录下server.properties复制三份并重命名,效果如下:xnchall@ubuntu:~/Software/kafka_2.10-0.9.0.1/config$ ls -al server*2> 下来通过修改三个配置文件,供启动时分别使用,达到kafka集群的目的(虽然是伪集群,原理和多台主机集群搭建一样)
-rw-r--r-- 1 xnchall xnchall 5292 Jun 16 14:33 server1.properties
-rw-r--r-- 1 xnchall xnchall 5298 Jun 15 16:59 server2.properties
-rw-r--r-- 1 xnchall xnchall 5323 Jul 24 20:37 server.properties
三个配置文件修改时,核心参数共同点是zookeeper集群接入点:zookeeper.connect=localhost:2183,localhost:2181,localhost:2182 #zookeeper集群核心参数不同设置:broker.id=Y #取决于集群规模,每个配置文件这个参数需不同3> 启动kafka集群
log.dirs= #kafka日志输出目录,每个kafka有自己独立日志文件
listeners=PLAINTEXT://:port #kafka监听请求的网络服务端口,伪集群port需不同bin/kafka-server-start.sh config/server.propertiesbin/kafka-server-start.sh config/server1.propertiesbin/kafka-server-start.sh config/server2.properties
4> 查看集群本地化运行
zookeeper集群本地化:![]()
kafka集群本地化:
这里就补贴kafka本地化目录了,后边有介绍
5> 创建topic深入理解kafka集群本地化./kafka-topics.sh --create --zookeeper localhost:2181 --topic testKakfa_lk --replication-factor 2 --partition 2 #创建topic,2个分区,2个副本
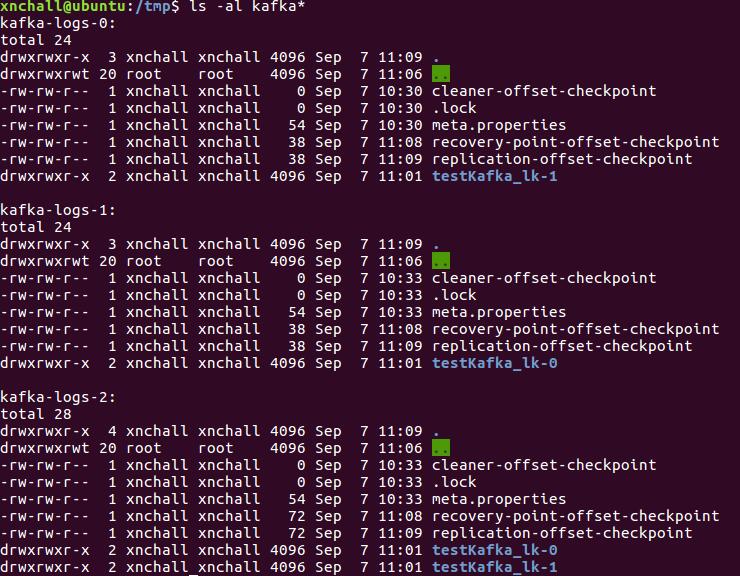
创建完成后,查看本地化状态(数据持久化)![]()
我们创建的kafka集群规模是3,创建topic时kafka会随机分配,理解上图需要一个命令xnchall@ubuntu:~/Software/kafka_2.10-0.9.0.1$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --topic testKafka_lk --describeTopic:testKafka_lk PartitionCount:2 ReplicationFactor:2 Configs:Topic: testKafka_lk Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: testKafka_lk Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
可以看出,topic两个分区laeder分布情况,0分区leader是编号为1的kafak主机,副本在编号2主机上。1分区laeder是编号为2的kafka主机,副本是编号为0主机。再看看上图kafka本地化的疑惑就迎刃而解了。
6> 关于kafka消息本地持久化
进入kafka-logs-2/testKafka_lk-0目录发现了有两个文件,.index文件是消息的偏移,根据偏移可以找到具体的消息。.log文件存的是具体消息体,所有向这个topic生产的消息都会记录,实现数据持久化 - 再来看看zookeeper集群:
上边我们创建了topic,下来去zookeeper集群是看一下会有什么呢?[zk: localhost:2181(CONNECTED) 0] ls /[admin, brokers, config, consumers, controller, controller_epoch, isr_change_notification, zookeeper]
对比一下发现多了很多kafka信息节点,进入brokers可以看到我们创建topic等节点信息,现在可以体会到zookeeper与kafka关系多么紧密了,其实zookeeper完成了leader选举、主备信息同步等很重要的功能。

- 总结
上述只是简单介绍,有问题多多提出,本文目的仅供技术交流使用~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号