

目标检测相关资料整理 6
一、FPN
论文:《Feature Pyramid Networks for Object Detection》
https://arxiv.org/abs/1612.03144
本文主要研究的是针对目标检测中的尺度问题,尤其是小目标检测中存在的卷积神经网络分辨率和语义化程度之间的矛盾问题,并提出了一种特征金字塔网络的解决思路--FPN(Feature Pyramid Network)算法。同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
针对目标检测任务在coco上,AP提升2.3个点,在Pascal上,AP提升3.8个点。
网络中的亮点:

图a,特征金字塔featurized image pyramid,当我们检测不同尺度的目标的时候,将图片缩放到不同的尺度,对每个尺度的图片都经过我们的算法进行预测,问题是,存在多少个尺度,就要预测多少个,效率很低。图b,标准fast-rcnn的流程,在最后的特征图上预测,对小目标的预测效果并不是很好。图c,与ssd相似,在backbone得到的不同的特征图上分别的进行预测。图d,就是本文中的FPN结构,加入不同特征层的融合,在融合之后,进行预测。
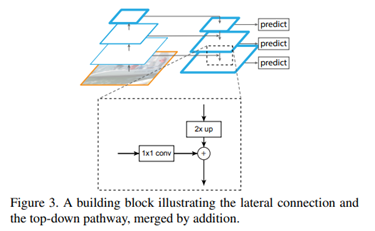
融合的细节:特征图按照2的整数倍缩小,首先,对于每一个骨架中的特征图,都会先接一个1*1的卷积层,卷积核channel 256,目的,调整不同特征图的channel。然后,将上面的特征图进行2倍的上采样,所以,shape与下面的特征层相同可以进行add融合。2倍的上采样是通过简单的临近插值算法实现的。
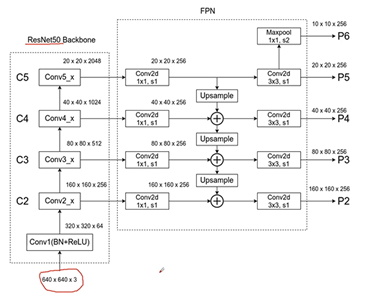
详细的过程,如上图所示。融合之后接上3*3卷积层,进行预测得到P5、P4、P3、P2,P5再下采样MAXPOOL步距是2得到P6,P6只用于RPN部分,不在Fast-RCNN部分使用。
不同的预测特征层会针对不同的面积,生成anchor,较低层的预测小目标。
综述:
Tsung-Yi Lin(2017)为了解决目标检测中的多尺度问题,利用CNN层级特征的金字塔形式,保持所有层都具有强语义信息,提出FPN结构,针对目标检测任务在coco上,AP提升2.3个点,在Pascal上,AP提升3.8个点。
二、 SSD
论文:《SSD: Single Shot MultiBox Detector》
https://arxiv.org/pdf/1512.02325.pdf
SSD网络是作者Wei Liu在ECCV 2016上发表的论文。对于输入尺寸300x300的网络使用Nvidia Titan X在VOC 2007测试集上达到74.3%mAP以及59FPS,对于512x512的网络,达到了76.9%mAP超越当时最强的Faster RCNN (73.2%mAP)。
网络中的亮点:
- SSD提取了不同尺度的特征图来做检测,大尺度特征图可以用来检测小物体,而小特征图用来检测大物体;
- SSD采用了不同尺度和长宽比的先验框,在faster r-cnn中称为Anchors。YOLO算法缺点是难以检测小物体,而且定位不准,但是对于这几点,SSD在一定程度上克服这些缺点。
网络结构:
VGG-16模型为基础,进行修改。分别将VGG16的全连接层FC6和FC7转换成 3x3 的卷积层 Conv6和 1x1 的卷积层Conv7;去掉所有的Dropout层和FC8层;同时将池化层pool5由原来的 stride=2 的 2x2 变成stride=1的 3x3 ;添加了Atrous算法(hole算法),目的获得更加密集的得分映射;然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。
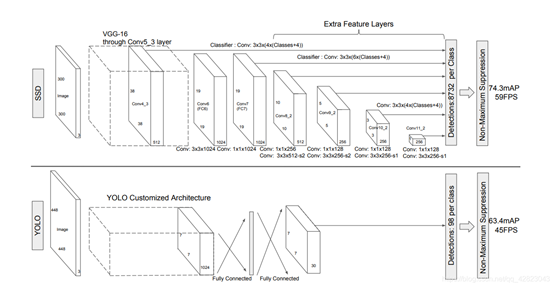
综述:
Wei Liu(2016)以VGG-16模型为基础,在不同特征尺度上预测不同尺度的目标,构建SSD框架,实验结果说明,在VOC 2007测试集上,对于300x300网络,达到74.3%mAP以及59FPS,对于512x512的网络,达到了76.9%mAP,超越当时最强的Faster RCNN (73.2%mAP)。
三、RetinaNet
论文:《RetinaNet:Focal Loss for Dense Object Detection》
https://arxiv.org/pdf/1708.02002.pdf
RetinaNet是作者Tsung-Yi Lin发表在ICCV 2017的文章,并获得了ICCV 2017的Best,创新点就是Focal Loss了,其主要贡献就是解决了one-stage算法中正负样本的比例严重失衡的问题,不需要改变网络结构,只需要改变损失函数就可以获得很好的效果。one-stage算法首次超越two-stage算法。在coco数据集上,最高AP达到40.8。
网络中的亮点:
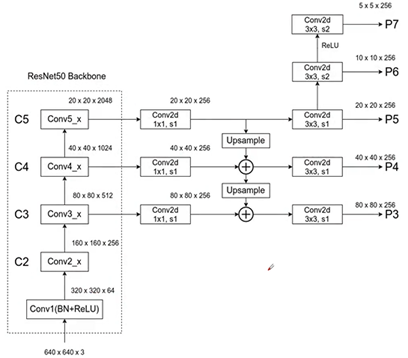
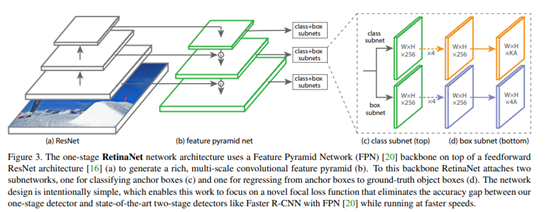
与FPN区别是,第一、没有C2生成P2,节约资源。第二、P6不同,利用3*3卷积层进行下采样。第三、在FPN中是P2-P6,但是在RetinaNet中,是P3-P7。
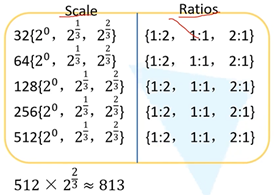
三个scale,三个ratios,共9组。
网络结构:
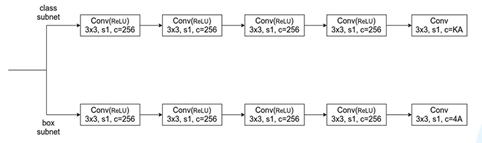
不同层但使用同一个预测器,分别预测每个anchor的类别和预测它的目标边界框回归参数。第一,预测类别。使用有relu的3*3卷积层,channel=256,最后一个没有relu,channel=KA,K检测目标类别数,在每个特征层上预测个数,这里A=9。第二,预测边界框回归参数,使用有relu的3*3卷积层,channel=256,最后一个没有relu,channel=4A。减少训练参数。
综述:
Tsung-Yi Lin(2017)利用Focal Loss,构建了RetinaNet网络,是one-stage算法首次超越two-stage算法,实验结果,在coco数据集上,最高AP达到40.8。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号