数据采集与融合作业3
第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
完整代码如下:
weather_spider.py
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
for image_url in response.css('img::attr(src)').extract():
yield {'image_urls': [response.urljoin(image_url)]}
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
class JpgLinksPipeline:
def open_spider(self, spider):
self.file = open('jpg_links.txt', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
image_urls = item.get('image_urls', [])
jpg_urls = [url for url in image_urls if url.endswith('.jpg')]
for jpg_url in jpg_urls:
self.file.write(jpg_url + '\n')
return item # Don't forget to return the item!
pipelines.py
class WeatherImagesPipeline:
def process_item(self, item, spider):
return item
settings.py
BOT_NAME = "weather_images"
SPIDER_MODULES = ["weather_images.spiders"]
NEWSPIDER_MODULE = "weather_images.spiders"
ROBOTSTXT_OBEY = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
IMAGES_STORE = 'images'
ITEM_PIPELINES = {
'weather_images.spiders.weather_spider.JpgLinksPipeline': 100,
'weather_images.spiders.weather_spider.MyImagesPipeline': 200,
}
jpg_links.txt
https://i.i8tq.com/weather2020/search/rbAd.jpg
https://i.i8tq.com/weather2020/search/rbAd.jpg
https://i.i8tq.com/weather2020/search/rbAd.jpg
https://i.i8tq.com/weather2020/search/rbAd.jpg
http://pi.weather.com.cn/i//product/pic/l/sevp_nsmc_wxbl_fy4a_etcc_achn_lno_py_20231024234500000.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/24/202310240901372B0E8FDF7D8ED736C3BF947676D00ADA.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/24/2023102409575512407332009374DDA12F1788006B444F.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/24/2023102411140839FCD91101374DD69FD3ABD5A86259CA.jpg
http://pi.weather.com.cn/i//product/pic/m/sevp_nmc_stfc_sfer_er24_achn_l88_p9_20231025010002400.jpg
http://i.weather.com.cn/images/cn/video/lssj/2023/10/24/20231024160107F79724290685BB5A07B8E240DD90185B_m.jpg
http://i.weather.com.cn/images/cn/index/2023/08/14/202308141514280EB4780D353FB4038A49F4980BFDA8F4.jpg
http://i.tq121.com.cn/i/weather2014/index_neweather/v.jpg
https://i.i8tq.com/video/index_v2.jpg
https://i.i8tq.com/adImg/tanzhonghe_pc1.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/10/17/202310171416368174046B224C8139BAD7CC113E3B54B2.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/10/16/20231016172856E95A6146BB0849E1C165777507CEAB0D.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/10/16/20231016163046E594C5EB7CD06C31B6452B01A097907E.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/10/16/2023101610255146894E5E20CD8F84ABB5C4EDA8F7223E.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/09/27/202309271054160CE1AF5F9EC5516A795F3528B5C1A284.jpg
http://i.weather.com.cn/images/cn/life/shrd/2023/09/25/202309251837219DDB4EB6B391A780A1E027DA3CA553A6.jpg
http://i.weather.com.cn/images/cn/sjztj/2020/07/20/20200720142523B5F07D41B4AC4336613DA93425B35B5E_xm.jpg
http://pic.weather.com.cn/images/cn/photo/2019/10/28/20191028144048D58023A73C43EC6EEB61610B0AB0AD74_xm.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/20/20231020170222F2252A2BD855BFBEFFC30AE770F716FB.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/24/20231024152112F91EE473F63AC3360E412346BC26C108.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/24/202310240901372B0E8FDF7D8ED736C3BF947676D00ADA.jpg
http://pic.weather.com.cn/images/cn/photo/2023/09/20/2023092011133671187DBEE4125031642DBE0404D7020D.jpg
http://pic.weather.com.cn/images/cn/photo/2023/10/16/20231016145553827BF524F4F576701FFDEC63F894DD29.jpg
http://i.weather.com.cn/images/cn/news/2021/05/14/20210514192548638D53A47159C5D97689A921C03B6546.jpg
http://i.weather.com.cn/images/cn/news/2021/03/26/20210326150416454FB344B92EC8BD897FA50DF6AD15E8.jpg
http://i.weather.com.cn/images/cn/science/2020/07/28/202007281001285C97A5D6CAD3BC4DD74F98B5EA5187BF.jpg
http://pi.weather.com.cn/i//product/pic/m/sevp_nmc_stfc_sfer_er24_achn_l88_p9_20231025010002400.jpg
http://pi.weather.com.cn/i//product/pic/m/sevp_nsmc_wxbl_fy4a_etcc_achn_lno_py_20231024234500000.jpg
下载图片文件夹截图
心得体会
首先,我通过命令行创建了一个新的Scrapy项目和一个新的爬虫。在爬虫的parse方法中,我使用Scrapy的CSS选择器提取了所有图片的URL。我定义了两个Pipeline类,一个是MyImagesPipeline用于处理和下载图片,另一个是JpgLinksPipeline用于将.jpg图片的链接写入到一个文本文件中。在settings.py文件中,我们通过ITEM_PIPELINES配置了这两个Pipeline,并通过IMAGES_STORE设置了图片的存储路径。最后,通过运行scrapy crawl weather_spider命令来执行爬虫。MyImagesPipeline确保所有图片被下载到指定的images子目录,而JpgLinksPipeline则将所有.jpg图片的链接保存到了jpg_links.txt文件中。为了实现单/多线程爬取,可以在settings.py中设置CONCURRENT_REQUESTS = 1/n。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
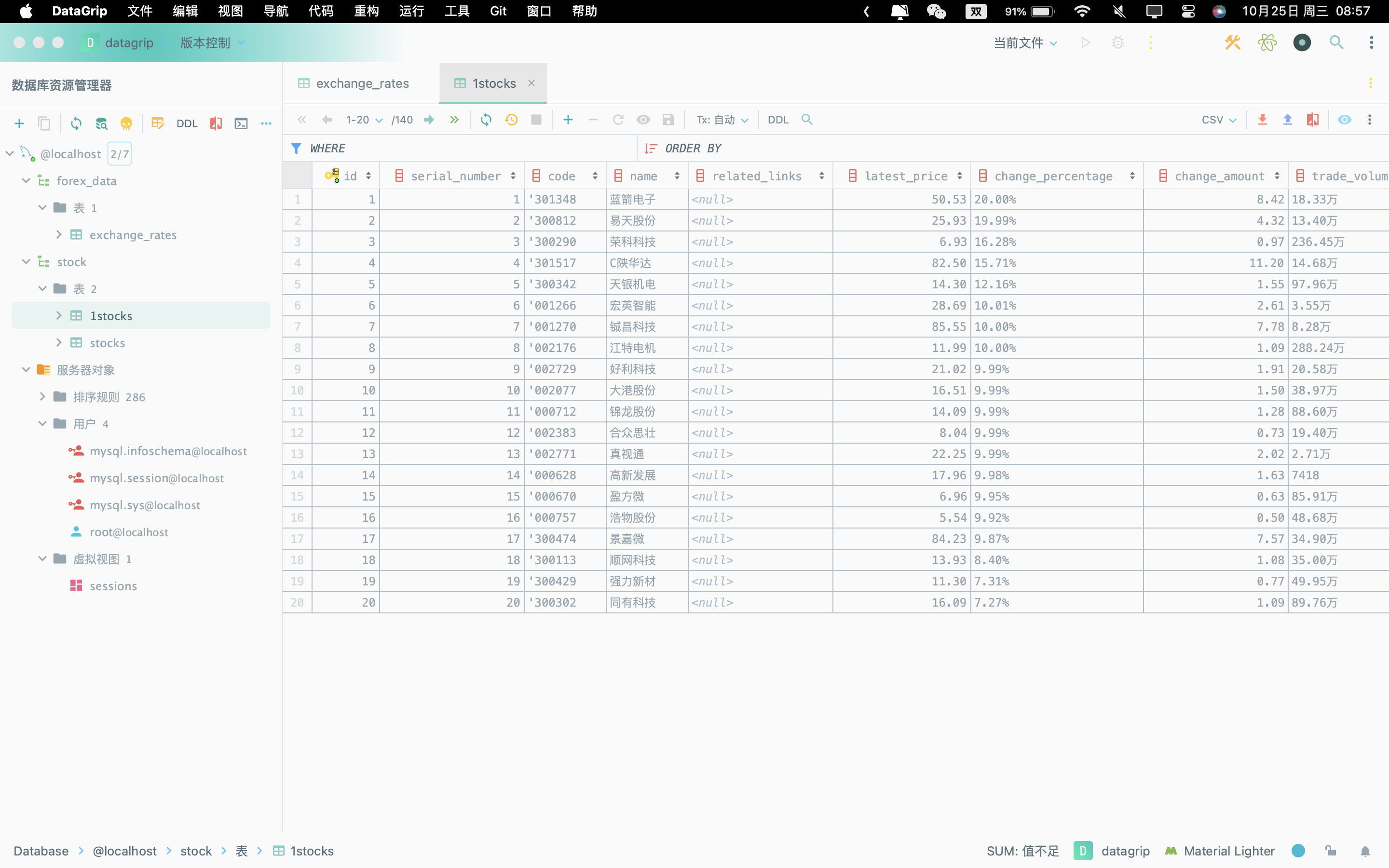
输出信息:MySQL数据库存储和输出格式如下:
完整代码如下:
easymoney_spider.py
import scrapy
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
from stock_scraper.items import StockItem
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
start_urls = ['http://quote.eastmoney.com/center/gridlist.html#sz_a_board']
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get(self.start_urls[0])
self.wait = WebDriverWait(self.driver, 10)
def parse(self, response):
all_data = pd.DataFrame()
num_pages_to_scrape = 5
# 在保存到数据库之前,使用 fillna 方法替换 NaN 值
all_data = all_data.fillna({
'related_links': '', # 用空字符串替换 NaN 值
'latest_price': 0, # 用 0 替换 NaN 值
})
for _ in range(num_pages_to_scrape):
try:
# 获取表格数据
table = self.wait.until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table'))
)
table_html = table.get_attribute('outerHTML')
# 使用 pandas 读取表格数据
df = pd.read_html(table_html, header=0, converters={'代码': str})[0]
# 确保股票代码是6位数,填充前导0
df['代码'] = df['代码'].apply(lambda x: "'" + str(x).zfill(6)) # 在每个代码前添加单引号
# 添加数据到总的 DataFrame 中
all_data = pd.concat([all_data, df], ignore_index=True)
# 点击 "下一页" 按钮
next_button = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//a[text()="下一页"]'))
)
next_button.click()
except Exception as e:
self.logger.error(f"An error occurred: {e}")
break
# 关闭 driver
self.driver.quit()
# 将 DataFrame 中的数据转换为 Scrapy items 并返回
for index, row in all_data.iterrows():
item = StockItem()
item['serial_number'] = row['序号']
item['code'] = row['代码']
item['name'] = row['名称']
item['related_links'] = row['相关链接']
item['latest_price'] = row['最新价']
item['change_percentage'] = row['涨跌幅']
item['change_amount'] = row['涨跌额']
item['trade_volume'] = row['成交量(手)']
item['trade_value'] = row['成交额']
item['amplitude'] = row['振幅']
item['highest_price'] = row['最高']
item['lowest_price'] = row['最低']
item['opening_price'] = row['今开']
item['closing_price'] = row['昨收']
item['volume_ratio'] = row['量比']
item['turnover_rate'] = row['换手率']
item['pe_ratio'] = row['市盈率(动态)']
item['pb_ratio'] = row['市净率']
item['add_to_watchlist'] = row['加自选']
yield item
items.py
import scrapy
class StockItem(scrapy.Item):
serial_number = scrapy.Field() # 序号
code = scrapy.Field() # 代码
name = scrapy.Field() # 名称
related_links = scrapy.Field() # 相关链接
latest_price = scrapy.Field() # 最新价
change_percentage = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
trade_volume = scrapy.Field() # 成交量(手)
trade_value = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
highest_price = scrapy.Field() # 最高
lowest_price = scrapy.Field() # 最低
opening_price = scrapy.Field() # 今开
closing_price = scrapy.Field() # 昨收
volume_ratio = scrapy.Field() # 量比
turnover_rate = scrapy.Field() # 换手率
pe_ratio = scrapy.Field() # 市盈率(动态)
pb_ratio = scrapy.Field() # 市净率
add_to_watchlist = scrapy.Field() # 加自选
pipelines.py
import mysql.connector
from stock_scraper.items import StockItem
class MySQLPipeline:
def open_spider(self, spider):
self.db = mysql.connector.connect(
host='localhost',
user='root',
password='xck030312',
database='stock'
)
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
if isinstance(item, StockItem):
sql = (
"INSERT INTO 1stocks "
"(serial_number, code, name, latest_price, change_percentage, change_amount, trade_volume, trade_value, "
"amplitude, highest_price, lowest_price, opening_price, closing_price, volume_ratio, turnover_rate, pe_ratio, pb_ratio)"
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
)
values = (
item['serial_number'], item['code'], item['name'], item['latest_price'],
item['change_percentage'], item['change_amount'], item['trade_volume'], item['trade_value'],
item['amplitude'], item['highest_price'], item['lowest_price'], item['opening_price'],
item['closing_price'], item['volume_ratio'], item['turnover_rate'], item['pe_ratio'],
item['pb_ratio']
)
self.cursor.execute(sql, values)
self.db.commit()
return item
settings.py
BOT_NAME = "stock_scraper"
SPIDER_MODULES = ["stock_scraper.spiders"]
NEWSPIDER_MODULE = "stock_scraper.spiders"
ITEM_PIPELINES = {'stock_scraper.pipelines.MySQLPipeline': 1}
ROBOTSTXT_OBEY = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
运行后部分结果如下
心得体会
此项目结合了Scrapy, Selenium, XPath, 和 MySQL,以爬取和存储东方财富网上的股票信息。项目结构包括一个Scrapy爬虫,一个用于定义数据结构的Items模块,和一个Pipelines模块用于处理和存储数据。在爬虫中,利用Selenium和XPath来定位和获取网页中的表格数据,包括股票代码、名称、最新价格等信息。Pandas库被用于处理和清洗从网页表格获取的数据。数据清洗包括删除不必要的列和确保股票代码的格式正确。项目还包括一个MySQLPipeline类,用于将清洗后的数据保存到MySQL数据库中。mysql中表的结构设计以适应该页面的各个字段,并确保所有字段都正确映射到数据库表中。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
完整代码如下:
forex_spider.py
import scrapy
from selenium import webdriver
from selenium.webdriver.common.by import By
from forex.items import ForexItem
from scrapy.selector import Selector
class ForexSpider(scrapy.Spider):
name = "forex"
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def __init__(self):
self.driver = webdriver.Edge()
def parse(self, response):
self.driver.get(response.url)
for page in range(10):
sel = Selector(text=self.driver.page_source)
rows = sel.xpath('/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr')[1:] # Skip header row
for row in rows:
item = ForexItem()
item['currency'] = row.xpath('td[1]/text()').get()
item['tbp'] = row.xpath('td[2]/text()').get()
item['cbp'] = row.xpath('td[3]/text()').get()
item['tsp'] = row.xpath('td[4]/text()').get()
item['csp'] = row.xpath('td[5]/text()').get()
item['bank_conversion_price'] = row.xpath('td[6]/text()').get()
item['release_date'] = row.xpath('td[7]/text()').get()
item['release_time'] = row.xpath('td[8]/text()').get()
yield item
next_button = self.driver.find_element(By.XPATH, '/html/body/div/div[5]/div[2]/div/ol/li[7]')
next_button.click()
def close(self, reason):
self.driver.quit()
items.py
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
bank_conversion_price = scrapy.Field()
release_date = scrapy.Field()
release_time = scrapy.Field()
pipelines.py
import mysql.connector
class ForexPipeline:
def open_spider(self, spider):
self.connection = mysql.connector.connect(
host='localhost',
user='root',
password='xck030312',
database='forex_data'
)
self.cursor = self.connection.cursor()
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
self.cursor.execute("""
INSERT INTO exchange_rates (currency, tbp, cbp, tsp, csp, bank_conversion_price, release_date, release_time)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", (
item['currency'],
item['tbp'],
item['cbp'],
item['tsp'],
item['csp'],
item['bank_conversion_price'],
item['release_date'],
item['release_time']
))
self.connection.commit()
return item
settings.py
BOT_NAME = "forex"
SPIDER_MODULES = ["forex.spiders"]
NEWSPIDER_MODULE = "forex.spiders"
ROBOTSTXT_OBEY = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
ITEM_PIPELINES = {
'forex.pipelines.ForexPipeline': 300,
}
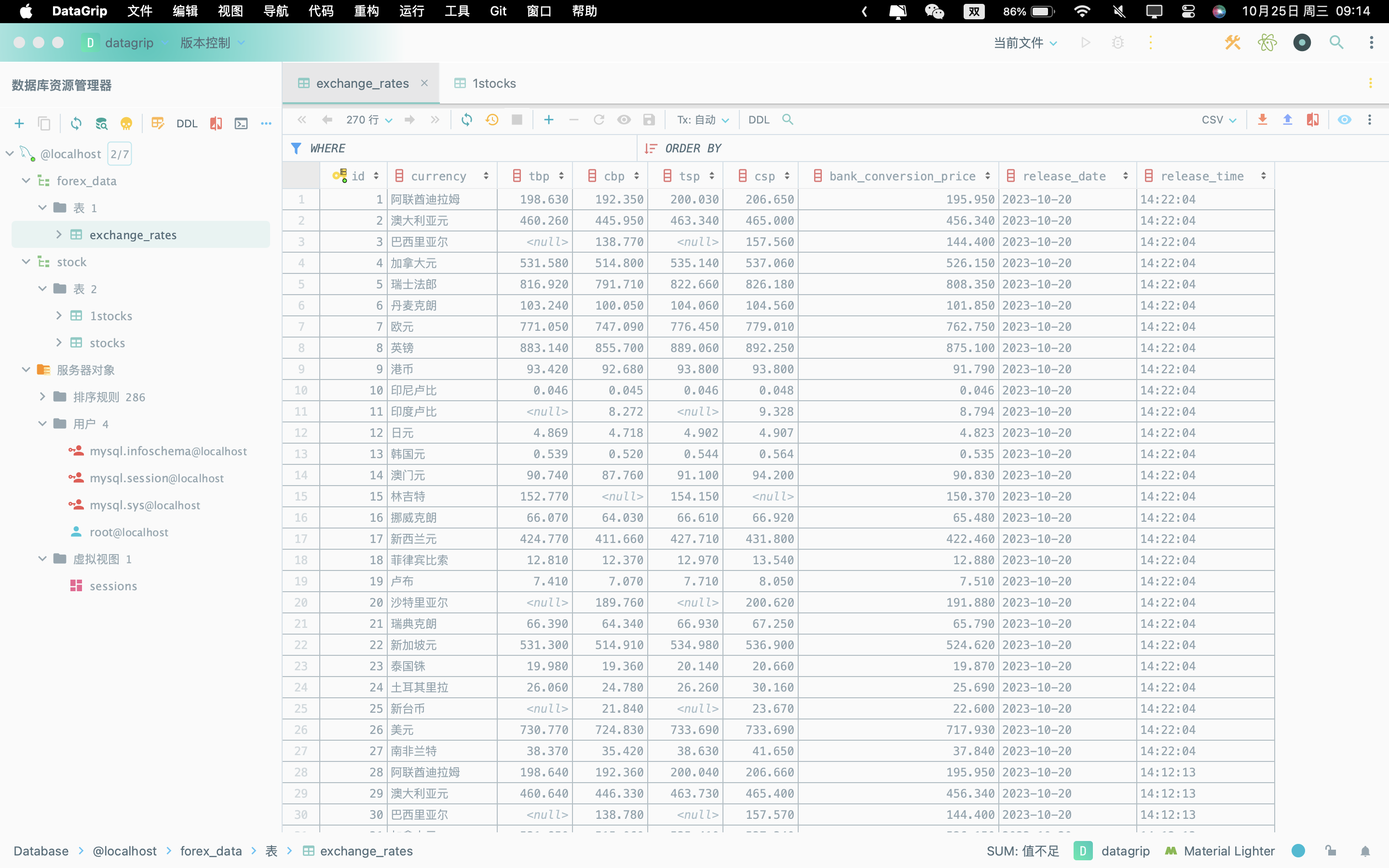
运行结果数据库截图:
心得体会
这个项目的目标是通过Scrapy和Selenium框架,以及XPath和MySQL技术,爬取并存储外汇网站的数据。首先,创建一个Scrapy项目和一个数据项类来定义需要爬取的字段。然后,创建一个Spider,使用Selenium和Edge浏览器来加载网页,并通过XPath来定位和提取表格中的数据。为了遍历网站上的10个页面,我们在循环中使用Selenium点击“下一页”按钮。提取的数据通过Scrapy的Pipeline处理,其中定义了如何将数据存储到MySQL数据库。最终,运行Scrapy爬虫,它会自动遍历所有页面,提取所有数据,并将其保存到MySQL数据库中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号