2.python-容器类型
容器类型
1. 通用操作
1.1 成员运算符
(1) 语法:
数据 in 容器
数据 not in 容器
(2) 作用:
如果在指定的序列中找到值,返回bool类型。
# 以字符串str为例,列表list,元组tuple,字典dict同理 字典判断的是键 content = "我是齐天大圣孙悟空" # in 用法表示包含,返回布尔值bool print("齐天大圣" in content) # True print("圣大天齐" in content) # False # 字符顺序不对 print("齐圣" in content) # False # 字符不连续 # not in 用法表示不包含,返回布尔值bool print("齐天大圣" not in content) # False print("圣大天齐" not in content) # True # 字符顺序不对 print("齐圣" not in content) # True # 字符不连续
1.2 索引index
(1) 作用:
定位单个容器元素。
(2) 语法:
容器[整数]
(3) 说明:
正向索引从0开始,第二个索引为1,最后一个为len(s)-1。
反向索引从-1开始,-1代表最后一个,-2代表倒数第二个,以此类推,第一个是-len(s)。
当索引n是负数时可看成是len(s) + n
# 以字符串str为例,列表list,元组tuple content = "我是齐天大圣孙悟空" # 顺取 print(content[0]) # 取第一个 "我" print(content[len(content) - 1]) # 取最后一个 "空" # 逆取 print(content[-len(content)]) # 取第一个 "我" print(content[-1]) # 取最后一个 "空" 相当于len(content) + (-1) # 索引超出范围会报错 print(content[-99]) # 报错 print(content[99]) # 报错
1.3 切片
(1) 作用:
定位多个容器元素。
(2) 语法:
# 以字符串str为例,列表list,元组tuple message = "我是花果山水帘洞美猴王孙悟空" # 包前不包后 # 语法1 容器[开始:结束:间隔] print(message[2:5:1]) # 打印的是"花果山" # 负索引 print(message[-6:-3:1]) # 打印的是"美猴王" # 语法2 容器[开始:结束] # 间隔为1时可省略 print(message[2:5]) # 打印的是"花果山" # 负索引 print(message[-6:-3]) # 打印的是"美猴王" # 语法3 容器[:结束] # 开头为0时可以省略 print(message[:5]) # 打印的是"我是花果山" # 负索引 print(message[:-3]) # 打印的是"我是花果山水帘洞美猴王" # 语法4 容器[开始:] # 一直取到结尾时可省略结尾 print(message[2:]) # 打印的是"花果山水帘洞美猴王孙悟空" # 负索引 print(message[-3:]) # 打印的是"孙悟空" # 语法5 容器[:] # 从0取到结尾,开始和结束都可以省略 print(message[:]) # 打印的是"我是花果山水帘洞美猴王孙悟空" # 间隔为负时倒着切片 # 技巧,翻转字符串 print(message[::-1]) # 打印的是"空悟孙王猴美洞帘水山果花是我" # 特殊情况,开始大于结束 print(message[4:1]) # 切片为空 print(message[4:1:-1]) # 倒着切 打印的是"山果花" # 特殊情况,开始等于结束 print(message[2:2]) # 切片为空
1.4 通用函数
# (1) len(x) 返回序列的长度 # (2) max(x) 返回序列的最大值元素 # (3) min(x) 返回序列的最小值元素 # (4) sum(x) 返回序列中所有元素的和(元素必须是数值类型)
1.5 算数运算符
# 以字符串str为例,列表list,元组tuple cool = "abcd" hello = "efg" # 两容器拼接 print(cool + hello) # "abcdefg" # 3个容器自身拼接 print(cool * 3) # "abcdabcdabcd"
2 字符串str
2.1 定义
由一系列字符组成的不可变序列容器,存储的是字符的编码值。
""" 数据不可变 因为在原有空间修改,可能破坏其他数据(损人利己) 所以会开辟新空间存储新数据,替换变量的内存地址 """ # 创建字符串 name = "小明" # 创建字符串,改变变量存储的内存地址 name = "郑X" name = "齐天大圣" print(name) # 齐天大圣

2.2 编码
2.2.1 基础知识
(1) 字节byte:计算机最小存储单位,等于8 位bit.
(2) 字符:单个的数字,文字与符号。
(3) 字符集(码表):存储字符与二进制序列的对应关系。
(4) 编码:将字符转换为对应的二进制序列的过程。
(5) 解码:将二进制序列转换为对应的字符的过程。
2.2.2 编码方式
(1) ASCII编码:包含英文、数字等字符,每个字符1个字节。
(2) GBK编码:兼容ASCII编码,包含21003个中文;英文1个字节,汉字2个字节。
(3) Unicode字符集:国际统一编码,旧字符集每个字符2字节,新字符集4字节。
(4) UTF-8编码:Unicode的存储与传输方式,英文1字节,中文3字节。
2.3 字符串的写法
2.3.1 单引号和双引号
# 单引号和双引号定义字符串没有差别 # 推荐双引号 # 单引号 name = '小红' # 双引号 name = '小明' # 引号冲突 # 解决方法双引号套单引号 或 单引号套双引号 news = "这是'猪'" news = '这是"猪"'
2.3.2 三引号字符串
# 三个引号 # 可用做注释 # 换行会自动转换为换行符\n # 三个引号内可以包含单引号和双引号 # 作为文档字符串(包含的内容是什么就是什么) content = """ "你好 我好 '哈哈' 大家好" """ print(content) # 在控制台打印会保留缩进,看到的是什么就打印什么
2.3.3 转义符
# 转义符:改变字符原始含义 # \ \\ \n \n为回车换行 \\为有时写单\会转义为其他内容,打印不出\ # 写url字符时需注意 url = "C:\program Files\google\chrome\application" # 单杠\后面跟小写字母容易被当做转义符改变原有样式 url = "C:\program Files\google\chrome\application" # 单杠\换成双杠\\避免被转义 # 原始字符:在字符串前添加r,表达字符串中没有转义符 content = r"今天看新闻\n有大事呢" print(content) # \n不会转义为回车
2.3.4 格式化字符串(字符串连接变量)
适用性:在固定格式的字符串中插入变量
语法:"格式" % (数据)
%s保持原样,字符串
usd = 2 cny = usd * 7 print("将" + str(usd) + "美元转换为人民币是" + str(cny) + "元") # 使用%s 可将上述式子修改为 print("将%s美元转换为人民币是%s元" % (usd, cny))
%d整数,使用0占位
s1 = 70 m = s1 // 60 s2 = s1 % 60 print(str(s1) + "秒等于" + str(m) + "分零" + str(s2) + "秒") # 70秒等于1分零10秒 print("%.2d秒等于%.2d分零%.2d秒" % (s1, m, s2)) print("%.3d秒等于%.2d分零%.2d秒" % (s1, m, s2)) # 070秒等于01分零10秒 # %.4d表示变量不足4位数时用0占位 print("%d秒等于%.4d分零%.4d秒" % (s1, m, s2)) # 70秒等于0001分零0010秒 # %6.4d表示变量不足6位数时用0占位占够4位,其余空格补 print("%d秒等于%6.4d分零%6.4d秒" % (s1, m, s2)) # 70秒等于 0001分零 0010秒 # %2.4d不足4位用0占位,%.1d占位小于变量的位数时,变量不变 print("%d秒等于%2.4d分零%.1d秒" % (s1, m, s2)) # 70秒等于0001分零10秒
%f浮点数,保留小数位数
old = 53 total = 66 proportion = old / total print("比例为" + str(proportion)) # 比例为0.803030303030303 # 保留两位小数 print("比例为%.2f" % (proportion)) # 比例为0.80 # 保留四位小数,只有一个参数可以省略括号 print("比例为%.4f" % proportion) # 比例为0.8030 # 百分比显示,要显示 % 号要用%%号表示 print("比例为%.2f%%" % (proportion * 100)) # 比例为80.30% # %6.4f设置6没有用处 print("比例为%6.4f" % proportion) # 比例为0.8030
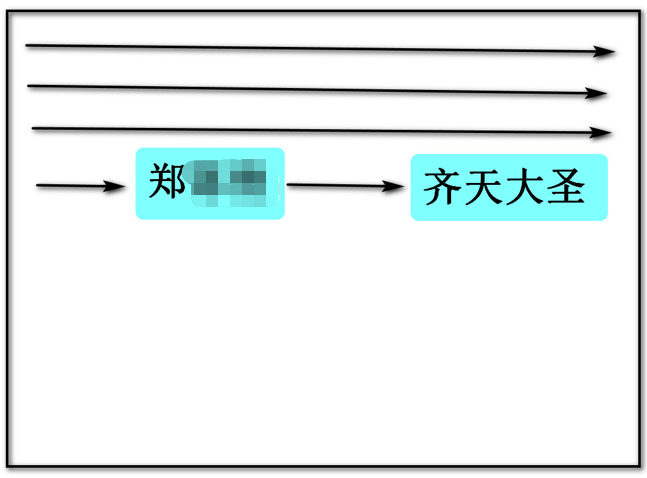
2.4 字符串内存图
字符串的不可变性
name = "郑XX"
name="齐天大圣"
当变量name被赋值为"齐天大圣"时,是新开辟了内存空间存储,而不是在原有"郑XX"的内存位置,因为字符串没有预留有多余的空间
3. 列表list
3.1 定义
由一系列变量组成的可变序列容器。
适用性:存储单一维度的数据
3.2 基础操作
3.2.1 创建列表
# 方法1 # 根据元素:列表名 = [数据1, 数据2] list_name = ["小红","小明","小华"] # 方法2 # 根据可迭代对象:列表名 = list(可迭代对象) content = "hello world" list_content = list(content)
3.2.2 添加元素
list_name = ["小红","小明","小华"] # 方法1 从最后面添加 # 追加:列表名.append(元素) list_name.append("小绿") # 方法2 从指定位置添加 # 插入:列表名.insert(索引,元素) list_name.insert(1,"小黄")
3.2.3 定位元素
list_name = ["小红","小明","小华"] # 索引:列表名[整数] print(list_name[1]) # 小明 # 修改元素 list_name[1] = "小黄" # 将列表索引1存储的元素改为小黄
3.2.4 切片
list_name = ["小红", "小蓝", "小橙", "小绿", "小紫", "小黄", "小黑"] # 切片:列表名[开始索引:结束索引:间隔] print(list_name[-2:]) # ["小黄", "小黑"] # 切片修改元素 # 切片长度和修改值列表长度一样长,一一对应 list_name[:4] = ["大红", "大蓝", "大橙", "大绿"] print(list_name) # ["大红", "大蓝", "大橙", "大绿", "小紫", "小黄", "小黑"] # 切片的长度比修改值列表长度长时 list_name[:4] = ["红红", "蓝蓝"] print(list_name) # ["红红", "蓝蓝", "小紫", "小黄", "小黑"] # 切片的长度比修改值列表长度短时 list_name[:2] = ["小红花", "小兰花", "小橙花", "小绿花"] print(list_name) # ["小红花", "小兰花", "小橙花", "小绿花", "小紫", "小黄", "小黑"] # 总结,切片修改元素,相当在切片的位置插入修改值列表
3.2.5 删除元素
list_name = ["小红","小明","小华","小明","小明"] # 根据元素:list_name.remove("小明") 只会删除一个小明 list_name.remove("小明") print(list_name) # ["小红","小华","小明","小明"] # 根据定位:del 列表[索引或切片] del list_name[2] # 删除索引2的元素 del list_name[:2] # 删除前两个元素
3.2.6 遍历列表
list_name = ["小红","小明","小华","小明","小明"] # 从头到尾读取 # for item in 列表: # item 是元素 for item in list_name: print(item) # 从头到尾修改 # for i in range(...): # 列表[i] 是元素 for i in range(len(list_name)): # 0 1 2 if list_name[i] == "小明": list_name[i] = "小高" # 将列表中的小明改小高 print(list_name)
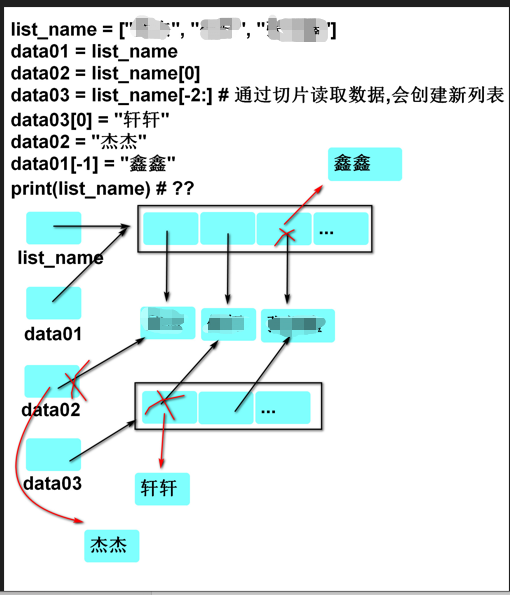
3.3 列表的内存图
变量list_name存储的是列表的地址值
将变量list_name赋值给data01,是将list_name存储的地址值给data01,所以data01存储的是列表的地址值
将list_name[0]赋值给data02,是将list_nama[0]存储的地址值给data02,所以data02存储的是元素的地址值
将list_name[-2:]赋值给data03,是将切片产生的新列表的地址值给data03.所以data03存储的是新列表的地址值
将"轩轩"赋值给data03[0]后,data03[0]存储的地址值变为"轩轩"的地址值
将"杰杰"赋值给data02,data02存储的地址值变为"杰杰"的地址值
将"鑫鑫"赋值给data01[-1],则data01[-1]存储的地址值为"鑫鑫"的地址值
列表用del删除元素,内存中被删元素后面的元素都往前移,将位置填满
列表用remove删除元素,先在查找到元素,再删除元素,内存中被删元素后面的元素都往前移,将位置填满
列表用append添加是添加在,列表的最后面,效率最高
列表用insert插入元素,在内存中插入位置及后面的元素都要往后移,为要插入的元素,腾出位置
4. 元组tuple
4.1 定义
(1) 由一系列变量组成的不可变序列容器。
(2) 不可变是指一但创建,不可以再添加/删除/修改元素。
4.2 基础操作
4.2.1 创建元组
# --根据元素:元组名 = (元素1,元素2) tuple_name = ("小黄", "小孙", "小钱") # --根据可迭代对象:元组名 = tuple(可迭代对象) list_name = ["小黄", "小孙", "小钱"] tuple_new = tuple(list_name)
4.2.2 定位元素
tuple_name = ("小黄", "小孙", "小钱") # -- 索引 print(tuple_name[-1]) # 小钱 最后一个 # -- 切片 print(tuple_name[:2]) # 小黄,小孙 前两个
4.2.3 遍历元素
tuple_name = ("小黄", "小孙", "小钱") # 从头到尾读取 for item in tuple_name: print(item)
4.2.2 特殊用法
# 注意1:在没有歧义的情况下,元组可以省略小括号 tuple_name = "小黄", "小孙", "小钱" # 注意2:元组只有一个元素,必须添加逗号 tuple_name = ("小黄",) # 单个元素不加逗号,系统会误认为其他类型赋值,例如字符串,数值... print(type(tuple_name)) # 序列拆包:右侧一个序列,左侧多个遍历 tuple_surname = "黄", "孙", "钱" a, b, c = tuple_surname print(a, b, c) # "黄", "孙", "钱" list_color = ["红", "黄", "绿"] a, b, c = list_color print(a, b, c) # "红", "黄", "绿" a, b, c = "福禄寿" print(a, b, c) # "福", "禄", "寿" # 变量交换:a,b=b,a name01 = "小华" name02 = "小明" name01, name02 = name02, name01 # 相当于序列拆包的 name01,name02 = (name02, name01)
5. 字典dict
5.1 定义
(1) 由一系列键值对组成的可变散列容器。
(2) 散列:对键进行哈希运算,确定在内存中的存储位置,每条数据存储无先后顺序。
(3) 键必须惟一且不可变(字符串/数字/元组),值没有限制。
(4) 适用于存储多个维度信息
5.2 基础操作
5.2.1 创建字典
# 根据元素:字典名 = {键1:值,键2:值} dict_tai_wan = { "region": "台湾", "new": 16, "now": 2339, "total": 16931, "cure": 13741, "die": None } list_name = [["红", "彤彤"], ("绿", "油油"), "飘飘"] # 根据可迭代对象: 字典名 = dict(可迭代对象) # --要求:可迭代对象的元素,必须一分为二 dict_name = dict(list_name) print(dict_name) # {"红":"彤彤","绿":"油油","飘":"飘"}
5.2.2 增删改查
dict_shan_xi = { "region": "陕西", "new": 182, "now": 859 } # 2. 添加 # 字典名[键] = 值 dict_shan_xi["total"] = 1573 # 3. 定位 # 修改 # --字典名[键] = 值 dict_shan_xi["new"] = 200 print(dict_shan_xi) # {"region": "陕西", "new": 200, "now": 859, "total": 1573} # 读取 # --值 = 字典名[键] print(dict_shan_xi["region"]) # 陕西 # 4. 删除 # --del 字典名[键] del dict_shan_xi["now"] print(dict_shan_xi) # {"region": "陕西", "new": 200, "total": 1573}
5.2.3 遍历字典
# 快捷键:iter + 回车 dict_shan_xi = { "region": "陕西", "new": 182, "now": 859, "total": 1573, "cure": 711, "die": None } for key in dict_shan_xi: print(key) # 打印键 for value in dict_shan_xi.values(): print(value) # 打印值 for key, value in dict_shan_xi.items(): print(key, value) # 打印键和值
深拷贝浅拷贝
""" 深浅拷贝 拷贝:数据一分二的过程(俗称复制、备份),防止数据被意外破坏 浅拷贝:复制第一层数据,共享深层数据 优点:占用内存较少 缺点:深层数据有可能被破坏 适用性:优先 深拷贝:复制所有层数据 优点:一份数据被破坏,绝对不影响另外一份 缺点:占用内存较多 适用性:深层数据会被修改 """ list_name = ["小黄", ["小钱", "小孙"]] # 浅拷贝 data01 = list_name[:] data01[0] = "小李" data01[1][0] = "小夏" print(list_name) # ["小黄", ["小夏", "小孙"]] # 准备深拷贝工具 import copy list_name = ["小黄", ["小钱", "小孙"]] # 深拷贝 data02 = copy.deepcopy(list_name) data02[0] = "小李" data02[1][0] = "小夏" print(list_name) # ["小黄", ["小钱", "小孙"]]
结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号