k8s的Health Check
Health Check(健康检查)


apiVersion: v1 kind: Pod metadata: labels: test: healthcheck name: healthcheck spec: restartPolicy: OnFailure containers: - name: healthcheck image: centos args: - /bin/sh - -c - sleep 10; exit 3

Liveness 探测
Liveness 探测让用户可以自定义判断容器是否是健康的条件。如果探测失败,Kubernetes 就会重启容器
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness spec: restartPolicy: OnFailure containers: - name: liveness image: centos args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: #定义如何执行Liveness探测 exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 #容器启动后10s开始执行Liveness探测 periodSeconds: 5 # 每5s执行一次Liveness 探测
- 通过cat检查/tmp/healthy文件是否存在。如果命令执行成功,返回值为0,Kubernetes则认为本次Liveness 探测成功;如果命令返回值非零,本次Liveness探测失败。
- initialDelaySeconds : 10 指定容器启动10s后开始执行Liveness探测,我们一般会根据应用启动的准备时间设置。比如某个应用的正常启动时间要花30s, 那initialDelaySeconds 的值就应该大于30s
- periodSeconds : 5 指定每5秒执行一次Liveness 探测。Kubernetes 如果连续执行3次Liveness 探测均失败,则会杀掉并重启容器。
Readiness 探测
Readiness 探测的配置语法与 Liveness 探测完全一样
apiVersion: v1 kind: Pod metadata: labels: test: readiness name: readiness spec: restartPolicy: OnFailure containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5
Pod readiness 的 READY 状态经历了如下变化:
-
刚被创建时,
READY状态为不可用。 -
15 秒后(initialDelaySeconds + periodSeconds),第一次进行 Readiness 探测并成功返回,设置
READY为可用。 -
30 秒后,
/tmp/healthy被删除,连续 3 次 Readiness 探测均失败后,READY被设置为不可用 STATUS变为Completed,而RESTARTS一直为0。
通过 kubectl describe pod readiness 也可以看到 Readiness 探测失败的日志。
- Liveness 探测是两种Health Check 机制,如果不特意配置,Kubernetes 将会对两种探测采取相同的默认行为,即通过判断容器启动进程的返回值是否为0来判断是否探测成功
- 两种探测的配置方法完全一致,支持的配置参数也是一致的。不同之处在于探测失败后的行为:
- Liveness 探测是重启容器
- Readiness 探测是容器设置为不可用,不接收Service转发的请求。
- Liveness 探测和Readiness 探测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用Liveness探测容器是否需要重启以实现自愈;用Readiness探测判断容器是否已准备好对外提供服务。
Health Check 在Scale Up中的应用
当执行Scale Up 操作时,新副本会作为backend被添加到Service 的负载均衡中,与已有副本一起处理客户的请求。考虑到应用启动通常都需要一个准备阶段,比如加载缓存数据、连接数据库等,从容器启动到真正能够对外提供服务是需要一段时间的。可以通过Readiness探测判断容器是否就绪,避免将请求发送到没有准备好的backend
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: web spec: replicas: 3 template: metadata: labels: run: web spec: containers: - name: web image: nginx ports: - containerPort: 8080 readinessProbe: httpGet: scheme: HTTP path: /health port: 8080 initialDelaySeconds: 10 periodSeconds: 5 --- apiVersion: v1 kind: Service metadata: name: web-svc spec: selector: run: web ports: - protocol: TCP port: 8082 #ClusterIP 上监听端口 targetPort: 80 #Pod 监听端口
- 容器启动10s后开始探测
- 如果http://[container_ip]:8080/healthy 返回代码不是200~400,表示容器没有就绪,不接收Service web-svc的请求。
- 每5秒探测一次
- 直到返回代码为200~400,表明容器已经准备就绪,然后让其加入web-svc的负载均衡中,开始处理客户请求。
- 探测会以5秒的间隔执行,如果连续发生3次失败,容器又会从负载均衡中移除。
Health Check 在滚动更新中的作用
-
正常情况下新副本需要10s完成准备工作,在此之前无法响应业务请求
-
由于人为配置错误,副本始终无法完成工作(比如无法链接到后端数据库)
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: app spec: replicas: 6 template: metadata: labels: run: app spec: containers: - name: app image: nginx args: - /bin/sh - -c - sleep 10; touch /tmp/healthy; sleep 30000 readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5
10 秒后副本能够通过Readiness 探测

接下来滚动更新应用,配置文件 app.v2.yml 如下:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: app spec: replicas: 6 template: metadata: labels: run: app spec: containers: - name: app image: nginx args: - /bin/sh - -c - sleep 30000 readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5
很显然,由于新副本中不存在/tmp/healthy,因此无法通过Readiness 探测的,验证如图
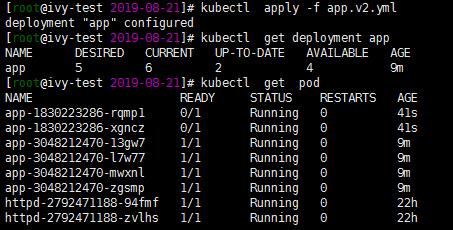
-
Pod 的AGE栏可判断,前两个Pod是新的副本,目前处于NOT READY的状态
-
旧副本从最初的6个减少为5个
看 kubectl get deployment app 输出

- DESIRED 6 表示期望状态为6个READY 副本
- CURRNET 7 表示当前副本的数量,即2个新副本+5个旧副本
- UP-TO-DATA 2 表示当前已经完成更新的副本数,即2个新副本
- ALAILABLE 5 表示当前处于READY 状态的副本数,即5个旧副本
参考
https://www.cnblogs.com/benjamin77/p/9939050.html#auto_id_4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号