人脸关键点检测--人脸对齐
Facial Keypoint

人脸关键点检测的技术原理
人脸关键点是人脸相关的项目中需要使用的, 是在人脸检测获取到人脸在图像中具体位置的基础上, 进一步定位人脸器官的位置。
获取到人脸上的关键点, 可以极大地提升人脸识别、人脸属性分析、表情分类等算法的性能和稳定性。人脸关键点可以使要识别的人脸做一个空间归一化,这个空间归一化的操作就叫:人脸对齐(face alignment)。这个操作可以使后续模型提取到与五官的位置无关,只有五官的形状纹理相关的特征。
人脸关键点分为2D关键点和3D关键点。2D关键点输出的是人脸关键点的x、y的坐标信息,常用的 2D 关键点数量 5 点、68 点、106 点等。
3D关键点,则输出关键点的 x、y、z的坐标信息。3D关键点的检测,是采用3DMM模型,重建人脸的3D mesh,再将3D mesh投射到2D的图像空间。由于3D关键点比2D关键点多了深度信息,在人脸姿态估计、3D 物体穿戴方面,优势较为明显。
人脸关键点检测算法演进与应用
人脸关键点检测的方法分为传统机器学习方法和深度学习方法。传统机器学习的方法,典开的代表包括 ASM(Active Shape Model)、AAM(Active Appearance Models)。
ASM 是一种基于点分布模型的算法,外形相似的物体的身体形状,可通过若干关键点的坐标依次串联形成的一个形状向量表示。ASM 算法需要人工标定的方法预先标定训练集,经过训练获得形状模型,再通过关键点的匹配实现特定物体的匹配。ASM 算法的优点是模型简单,架构清晰,对轮廓形状有较强的约束,但近似于穷举搜索的关键点定位方式,限制了其运算的效率。AAM 是 ASM 的进阶版,在形状约束的基础上,加入整个脸部的纹理特征。传统机器学习的方法,检测的速度相对较快,但关键点检测的精度有限,难以满足应用的要求。
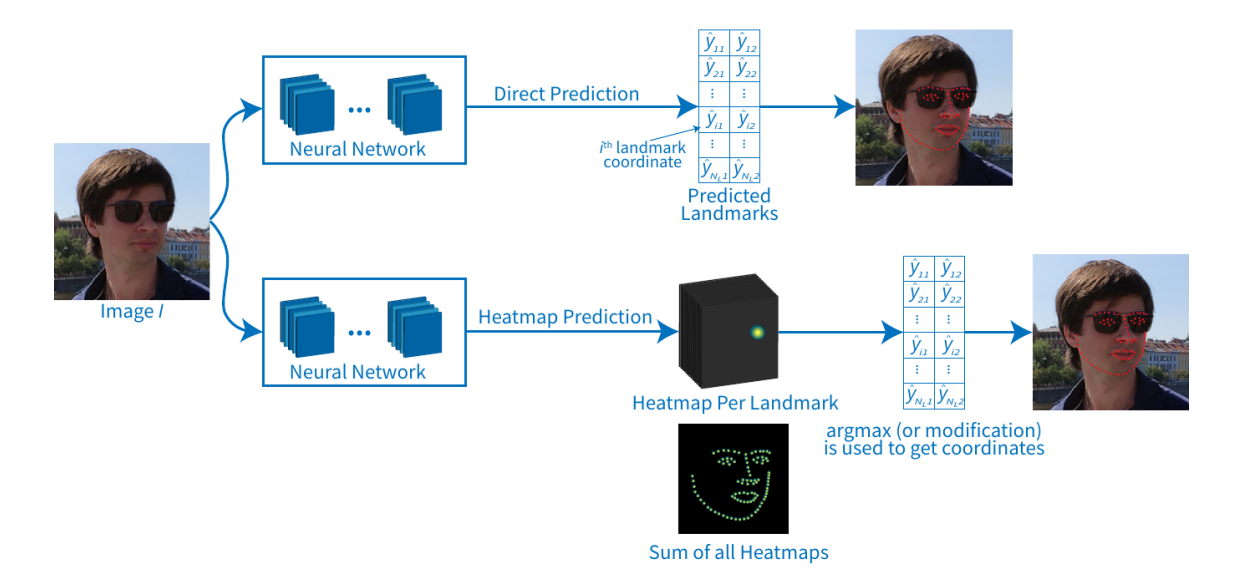
基于深度学习的人脸关键点检测方法,大致可分为两个流派:热力图方法和和直接回归方法。
热力图方法,是每个关键点生成一个热力图,关键点处的值最大,离关键点越远,值越小。该类方法常用MSE损失,也有论文提出对损失函数进行改进, 如Wing loss。热力图方法,关键点检测的精度高,并可判断关键点是否被遮挡,对遮挡的鲁棒性较好。由于热力图大小通常是输入图像的 1/4,对内存的占用大。检测关键点的数量越多,内存占用越大,限制了热力图方法在端侧设备上的应用。直接回归方法,通过卷积神经模型预测关键点的坐标,内存占用小,关键点检测的精度较热力图方法差一些。由于直接回归方法内存占用小,检测速度快,在端侧设备上的应用前景广阔。
人脸关键点的应用领域十分广泛,如人脸姿态对齐、人脸美颜、虚拟面部重现
挑战与困难
- 输入样本多样性问题:多变的人脸姿态和遮挡,不同的光照情况
- 大场景小样本问题:在图像中存在非常多的小尺寸人脸
- 检测速度: 在端侧的应用
数据集
-
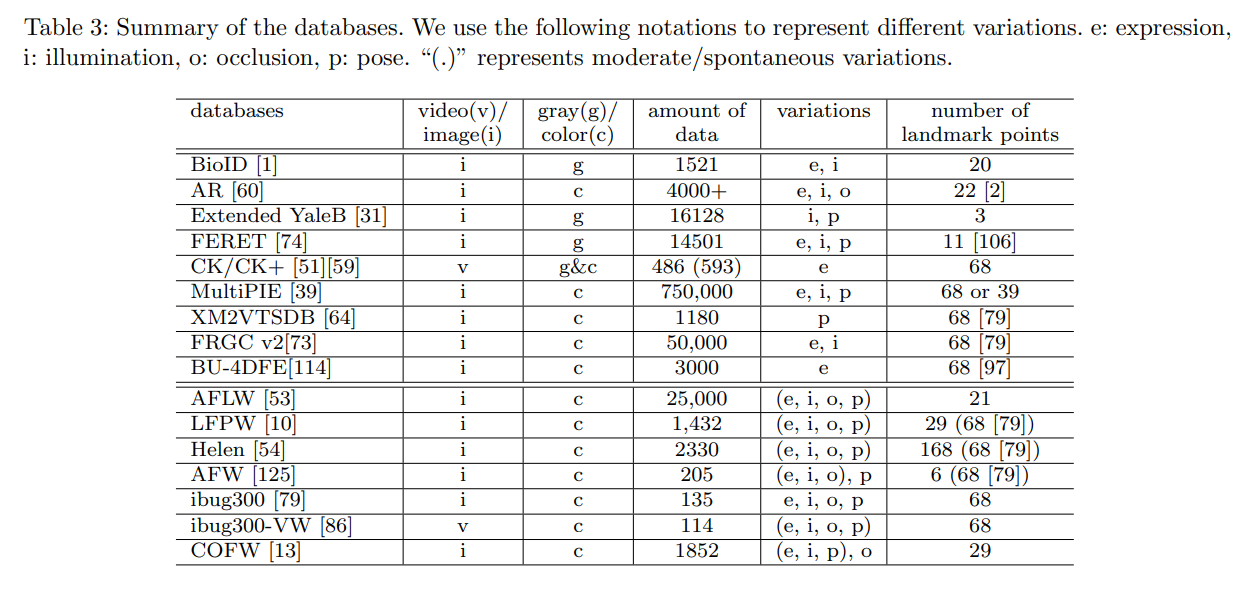
现阶段常见的数据集有5关键点、21关键点、68关键点、98关键点,以及超过100关键点的数据集。数据集地址: 300W、WFLW、COFW、AFLW
-
评价指标
\[NME = \frac{1}{K} \sum_{k=1}^{K}{NME_k} \quad (1) \]
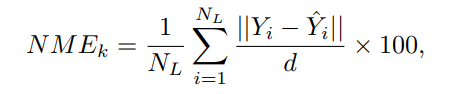
NME:Normalized Mean Error, 归一化平均误差。Y是真实标注的关键点矩阵, Yˆ是预测的关键点矩阵, d是数据集的归一化系数。Nl是数据集中每张图片的关键点数量, K是测试图片数量。此指标越小越好
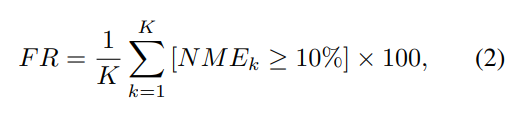
FR: Failure Rate, 表示NME高于10%阈值的图像数量。指标值越低越好。
CED-AUC: Cumulative Error Distribution – Area Under Curve, 累计误差分布-曲线下面积。绘制出NME小于或等于X轴上NME值的图像的比例, 然后计算出曲线下的面积。通常,NME的范围是[0: 10%]。计算出的CED-AUC值在[0:1]范围内进行缩放。计量值越大越好。
backbone
概述
一般地,人脸关键点和人体关键点算法使用的backbone类似。人脸关键点算法分类两种,直接回归方法和基于热力图的方法。直接回归方法即直接预测每个关键点的x,y的坐标。基于热力图的方法则是为每个关键点构建2d热力图,热图中的值表示为关键点在某个图像位置的概率,使用argmax来获取热图中关键点的精确位置。
直接回归方法通常采用分类中较为常用backbone,如Resnet、Mobilenetv2、Mobilenetv3、ShuffleNet-v2等。基于热力图的方法通常使用Hourglass网络架构,以及HRNet和CU-Net等。
Hourglass
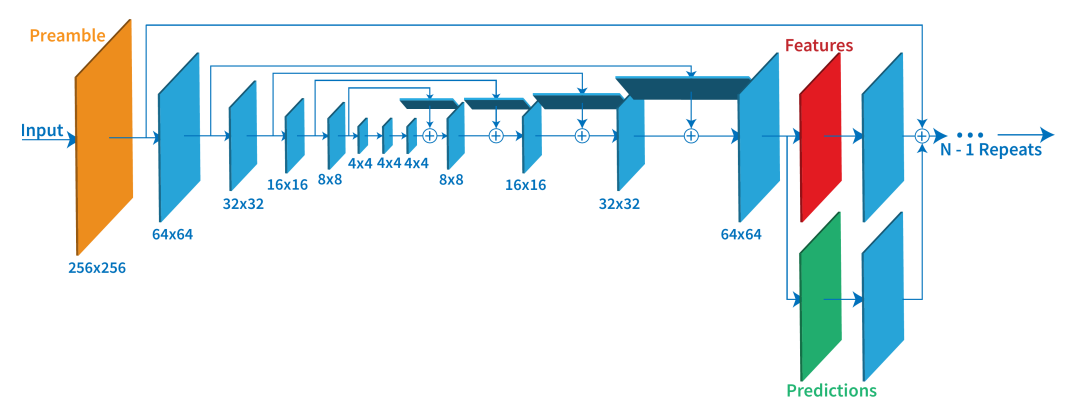
如上图所示为hourglass的网络结构。
-
为减少计算和内存,首先使用卷积将输入缩放至64*64, 并保持这个分辨率直至结束。输入的图片先通过一个卷积层,卷积核大小为7*7,slide为2,pad为3,输出层数为64。经过这一层的卷积后,conv1的大小为64*128*128,再接batch normalization和用ReLU激活。conv1接下来通过一个Residual的网络,接下来的网络依次是一个池化层和两个Residual模块网络,到这边为止,得到将是N*64*64的特征, 这里N一般是256
-
另外网络会以这个分辨率为每个关键点生成一个热图。Hourglass是典型的编码器解码器结构, 通过多种分辨率处理特征图,来提高姿态估计和关键点检测的准确率。hourglass模块的堆叠会导致降低训练的速度, 于是作者在模块之中加入跳跃连接, 改善梯度传播,加快网络收敛。Hourglass还加入了中继监督,即在每个模块结束时生成特征图(红色)和预测图(绿色), 不仅最终预测,这些中间的预测的损失也会加入损失函数的计算。
-
gt由关键点生成的二维高斯图, 损失函数是所有stack的输出热图与GT之间的MSE
import torch class HeatmapLoss(torch.nn.Module): """ loss for detection heatmap """ def __init__(self): super(HeatmapLoss, self).__init__() def forward(self, pred, gt): L = ((pred - gt)**2) L = L.mean(dim=3).mean(dim=2).mean(dim=1) return L ## L of dim bsize -
预测时,输入任意一张人物图片(256*256),得到最后一个stack的输出热图(不是所有的)。算出每一个joint对应的热图中最大值元素所在的坐标(argmax),然后scale回去,作为最后预测到的关键点位置。
CU-Net
CU-Net试图在精度、内存占用、推理速度上改进Hourglass的这种编码解码的unet结构,作者不仅在同一模块内添加跳跃链接而且在不同模块之间增加了跳跃链接。CU-Net通过避免不必要的特征复制、共享内存以及量化特征和参数来减少内存消耗并提高推理速度。
HRNet
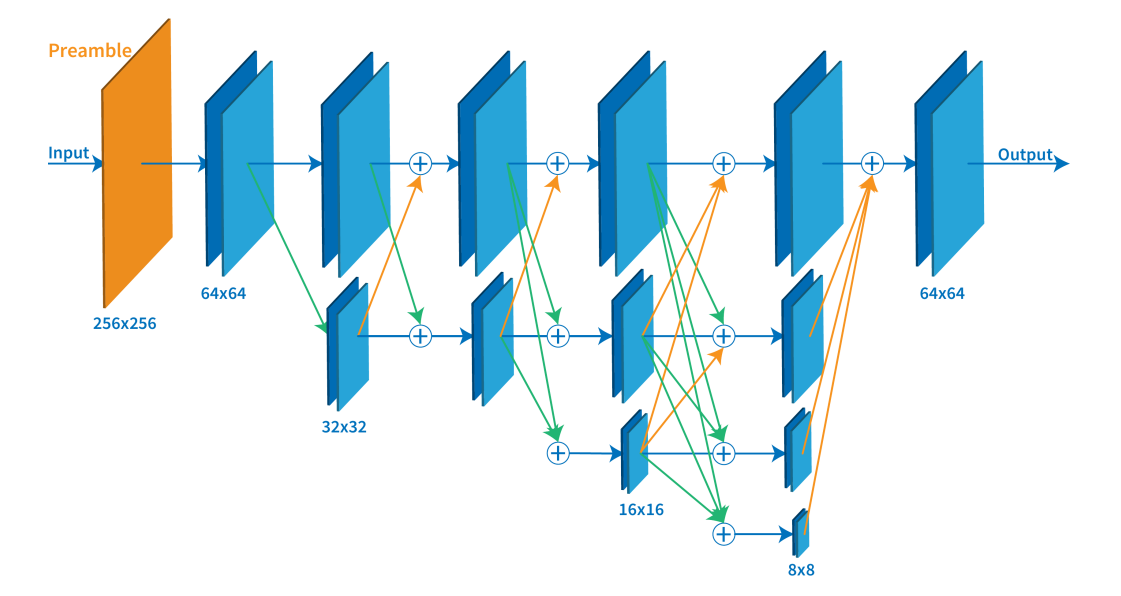
关于hrnet的论文、应用以及代码地址可以参考王井东博士主页,包含hrnet姿态估计、语义分割、人脸对齐、图像分类、目标检测这几项任务上实现的详细介绍。HRNet-pose。姿态估计中多数方法如上一节说到的Hourglass都是高分辨率到低分辨率,再逐步恢复提高分辨率。但是hrnet在整个过程中始终保持高分辨率的表征。如上图所示,输入图像首先经过卷积下缩放到64*64的大小, 在每组卷积块之后,添加一个分辨率小四倍的并行分支。总体而言,在网络端创建了 4 个并行分支,最小分辨率为 8×8。不同分辨率块之间的特征被交换。为了将特征传递给更高分辨率的块,使用最近邻上采样(橙色箭头)。为了将特征传递给分辨率较小的块,使用了跨步卷积(绿色箭头)。蓝色箭头表示特征图未重新缩放。最终输出包含所有尺度的特征总和。文章中的 Repeated multi-scale fusion, 也就是不同分辨率feature map的fusion。如下图所示图所示exchange unit:
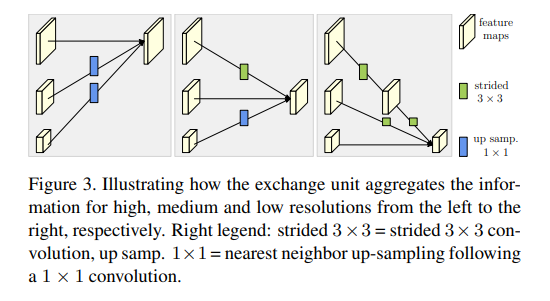
- 同分辨率之间的直接复制
- 需要升分辨率的使用bilinear upsample, 并利用1x1卷积统一通道数
- 需要降分辨率的使用stride 3x3卷积。这里降分辨率之所以不使用池化,是想利用stride3x3 可学习的方式降低信息的损耗
参数对比
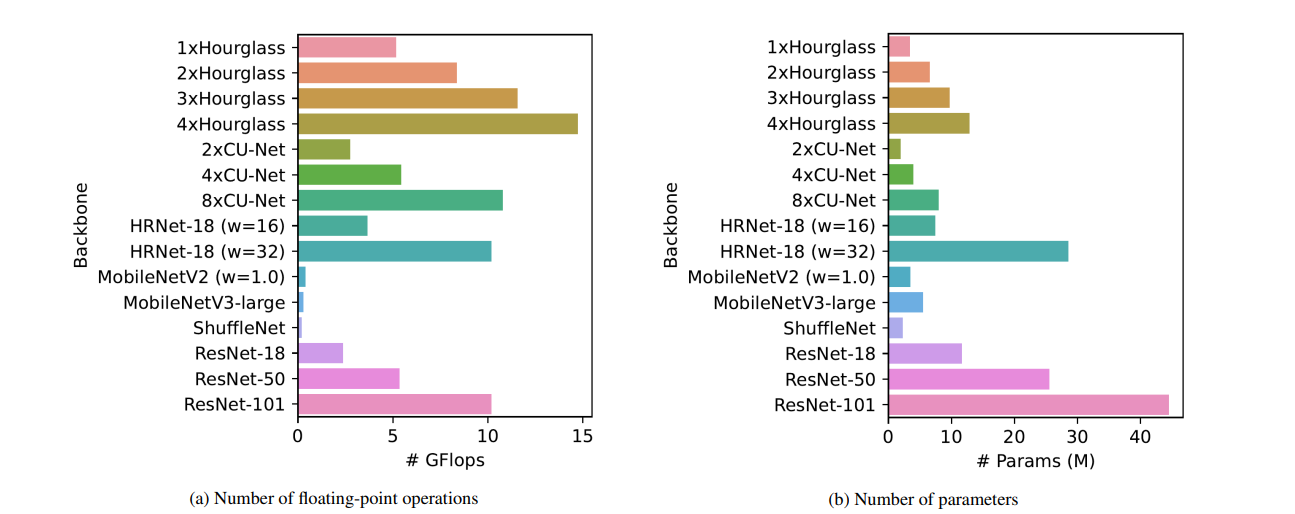
上图展示了不同backbone浮点运算量和参数量的对比。Hourglass、CUNet、HRNet参数量相对较少,但是浮点计算量要更大。这是因为这些网络是基于热图估计的方法,需要为每个关键点生成大分辨率的热图。
人脸关键点检测
基于回归的方法
DCNN
2013📕:Deep Convolutional Network Cascade for Facial Point Detection
2013 年,Sun 等首次将 CNN 应用到人脸关键点检测,提出一种级联的 CNN(拥有三个层级)——DCNN(Deep Convolutional Network),此种方法属于级联回归方法。
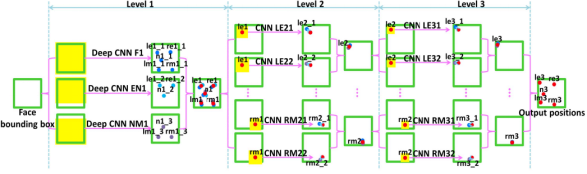
作者通过精心设计拥有三个层级的级联卷积神经网络,不仅改善初始不当导致陷入局部最优的问题,而且借助于 CNN 强大的特征提取能力,获得更为精准的关键点检测。DCNN 由三个 Level 构成。Level-1 由 3 个 CNN 组成;Level-2 由 10 个 CNN 组成(每个关键点采用两个 CNN);Level-3 同样由 10 个 CNN 组成。
Level-1 分 3 个 CNN,分别是 F1(Face 1)、EN1(Eye,Nose)、NM1(Nose,Mouth);F1 输入尺寸为 39x39,输出 5 个关键点的坐标;EN1 输入尺寸为 39x31,输出是 3 个关键点的坐标;NM11 输入尺寸为 39x31,输出是 3 个关键点。Level-1 的输出是由三个 CNN 输出取平均得到。
Level-2,由 10 个 CNN 构成,输入尺寸均为 15x15,每两个组成一对,一对 CNN 对一个关键点进行预测,预测结果同样是采取平均。
Level-3 与 Level-2 一样,由 10 个 CNN 构成,输入尺寸均为 15x15,每两个组成一对。Level-2 和 Level-3 是对 Level-1 得到的粗定位进行微调,得到精细的关键点定位。
DCNN 采用级联回归的思想,从粗到精的逐步得到精确的关键点位置,不仅设计了三级级联的卷积神经网络,还引入局部权值共享机制,从而提升网络的定位性能
MTCNN
2016
MTCNN, Multi-task Cascaded Convolutional Networks用以同时处理人脸检测和人脸关键点定位问题。作者认为人脸检测和人脸关键点检测两个任务之间往往存在着潜在的联系,然而大多数方法都未将两个任务有效的结合起来,本文为了充分利用两任务之间潜在的联系,提出一种多任务级联的人脸检测框架,将人脸检测和人脸关键点检测同时进行。
MTCNN 包含三个级联的多任务卷积神经网络,分别是 Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。网络结构如下图所示
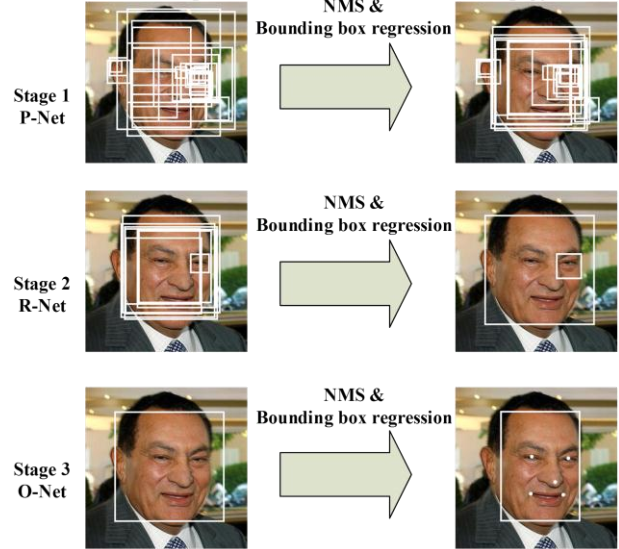
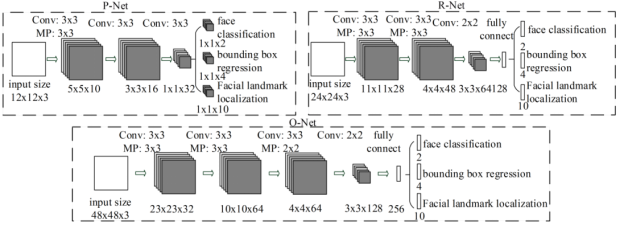
MTCNN 实现人脸检测和关键点定位分为三个阶段。首先由 P-Net 获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过NMS来合并高度重叠的候选框。然后将 P-Net 得出的候选框作为输入,输入到 R-Net通过边界框回归和 NMS 来去掉那些 false-positive 区域,得到更为准确的候选框;最后,利用 O-Net 输出 5 个关键点的位置。
在具体训练过程中,作者就多任务学习的损失函数计算方式进行相应改进。在多任务学习中,当不同类型的训练图像输入到网络时,有些任务时是不进行学习的,因此相应的损失应为 0。例如,当训练图像为背景(Non-face)时,边界框和关键点的 loss 应为 0,文中提供计算公式自动确定 loss 的选取,公式为:
其中,\(\alpha_j\)表示任务的重要程度,在 P-Net 和 R-Net 中,\(\alpha_{\mathrm{det}}=1, \alpha_{b o x}=0.5, \alpha_{l a t d m a v k}=0.5\), 在 R-Net 中,由于要对关键点进行检测,所以相应的增大任务的重要性,\(\alpha_{\mathrm{det}}=1, \alpha_{b o x}=0.5, \alpha_{l a t d m a v k}=1\)。\(\beta^{j}_{i}\in(0,1)\)作为样本类型指示器。
为了提升网络性能,需要挑选出困难样本(Hard Sample),传统方法是通过研究训练好的模型进行挑选,而本文提出一种能在训练过程中进行挑选困难的在线挑选方法。方法为,在 mini-batch 中,对每个样本的损失进行排序,挑选前 70% 较大的损失对应的样本作为困难样本,同时在反向传播时,忽略那 30% 的样本,因为那 30% 样本对更新作用不大。
PFLD
2019
PFLD旨在开发一种实用的面部landmark检测器,可以在复杂的人脸情况下保持高精度,并实现在移动设备和端侧的应用。
欧拉角计算
世界坐标系 ==> 相机坐标系 ==> 像素坐标系, 可以参考博客
本算法中, 对齐的人脸世界坐标系对应的坐标如下
landmarks_3D = np.float32([
[6.825897, 6.760612, 4.402142], # LEFT_EYEBROW_LEFT,
[1.330353, 7.122144, 6.903745], # LEFT_EYEBROW_RIGHT,
[-1.330353, 7.122144, 6.903745], # RIGHT_EYEBROW_LEFT,
[-6.825897, 6.760612, 4.402142], # RIGHT_EYEBROW_RIGHT,
[5.311432, 5.485328, 3.987654], # LEFT_EYE_LEFT,
[1.789930, 5.393625, 4.413414], # LEFT_EYE_RIGHT,
[-1.789930, 5.393625, 4.413414], # RIGHT_EYE_LEFT,
[-5.311432, 5.485328, 3.987654], # RIGHT_EYE_RIGHT,
[-2.005628, 1.409845, 6.165652], # NOSE_LEFT,
[-2.005628, 1.409845, 6.165652], # NOSE_RIGHT,
[2.774015, -2.080775, 5.048531], # MOUTH_LEFT,
[-2.774015, -2.080775, 5.048531], # MOUTH_RIGHT,
[0.000000, -3.116408, 6.097667], # LOWER_LIP,
[0.000000, -7.415691, 4.070434], # CHIN
])
### 选取14个关键点, 送进来的2D坐标也是这14个对应的关键点
计算欧拉角的过程如下
### 求解平移向量和旋转向量
### camera_matrix 相机内参矩阵 camera_distortion 畸变系数, 全零
_, rvec, tvec = cv2.solvePnP(landmarks_3D, landmarks_2D, camera_matrix,
camera_distortion)
rmat, _ = cv2.Rodrigues(rvec)
pose_mat = cv2.hconcat((rmat, tvec))
### pose_mat 投影矩阵
_, _, _, _, _, _, euler_angles = cv2.decomposeProjectionMatrix(pose_mat)
损失函数
一般训练数据集中姿势较大、遮挡、光照等图片数据可能占比较少影响模型精度,PFLD为解决这一数据不平衡问题, 修改损失函数,以在训练中关注稀有样本。原始损失函数如下,
其中M代表样本数,N代表关键点数, γn表示赋予的不同的权重,||*|| 表示的是特征点距离度量(L1或者L2距离),考虑到数据集的类别不均衡,所以对损失函数重新设计如下:
原来的权重γn变成了括号中的公式。K=3,这一项代表着人脸姿态的三个维度, 即yaw,pitch,roll角度,角度越大权重越大。C为不同的人脸类别数,包括侧脸、正脸、抬头、低头、表情、遮挡等。w表示与类别对应的给定权重,类别样本数较少则给定权重大。作者之所以要如此设计权重公式, 是因为仅考虑2D空间预测点到真值坐标点的距离是有失偏颇的。然而网络又只是针对2D任务,于是需要加上3D信息,即考虑3D关键点在2D空间的投影,在人脸关键点这项任务,只需要考虑投影矩阵的3个自由度(欧拉角),即上面所说的yaw,pitch,roll。式中\(d_{mn}\)来自主干网络预测, \(θ_{kn}\)来自辅助网络(angle - euler_angle_gt)。
主干网络
整个网络的结构如下图所示,分为主网络(橙色框)和辅助网络(绿色框),主干网络backbone是用来预测关键点,而辅助网络用来预测人脸姿态,使关键点位置更加稳定、鲁棒性更好。辅助网络只在训练阶段使用, 推理阶段只用主干网络进行关键点的预测。主干网络使用mobilenetv2模块, 辅助网络使用的则是普通的卷积网络。

论文作者并未开源代码, 这里参考polarisZhao/PFLD-pytorch的实现。主干网络实现如下所示。其中out1会送入辅助网络来计算欧拉角矩阵,并用于损失函数的计算。
PFLDInference
class PFLDInference(nn.Module):
def __init__(self):
super(PFLDInference, self).__init__()
self.conv1 = nn.Conv2d(3,
64,
kernel_size=3,
stride=2,
padding=1,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64,
64,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv3_1 = InvertedResidual(64, 64, 2, False, 2)
self.block3_2 = InvertedResidual(64, 64, 1, True, 2)
self.block3_3 = InvertedResidual(64, 64, 1, True, 2)
self.block3_4 = InvertedResidual(64, 64, 1, True, 2)
self.block3_5 = InvertedResidual(64, 64, 1, True, 2)
self.conv4_1 = InvertedResidual(64, 128, 2, False, 2)
self.conv5_1 = InvertedResidual(128, 128, 1, False, 4)
self.block5_2 = InvertedResidual(128, 128, 1, True, 4)
self.block5_3 = InvertedResidual(128, 128, 1, True, 4)
self.block5_4 = InvertedResidual(128, 128, 1, True, 4)
self.block5_5 = InvertedResidual(128, 128, 1, True, 4)
self.block5_6 = InvertedResidual(128, 128, 1, True, 4)
self.conv6_1 = InvertedResidual(128, 16, 1, False, 2) # [16, 14, 14]
self.conv7 = conv_bn(16, 32, 3, 2) # [32, 7, 7]
self.conv8 = nn.Conv2d(32, 128, 7, 1, 0) # [128, 1, 1]
self.bn8 = nn.BatchNorm2d(128)
self.avg_pool1 = nn.AvgPool2d(14)
self.avg_pool2 = nn.AvgPool2d(7)
self.fc = nn.Linear(176, 196)
def forward(self, x): # x: 3, 112, 112
x = self.relu(self.bn1(self.conv1(x))) # [64, 56, 56]
x = self.relu(self.bn2(self.conv2(x))) # [64, 56, 56]
x = self.conv3_1(x)
x = self.block3_2(x)
x = self.block3_3(x)
x = self.block3_4(x)
out1 = self.block3_5(x)
x = self.conv4_1(out1)
x = self.conv5_1(x)
x = self.block5_2(x)
x = self.block5_3(x)
x = self.block5_4(x)
x = self.block5_5(x)
x = self.block5_6(x)
x = self.conv6_1(x)
x1 = self.avg_pool1(x)
x1 = x1.view(x1.size(0), -1)
x = self.conv7(x)
x2 = self.avg_pool2(x)
x2 = x2.view(x2.size(0), -1)
x3 = self.relu(self.conv8(x))
x3 = x3.view(x3.size(0), -1)
multi_scale = torch.cat([x1, x2, x3], 1)
landmarks = self.fc(multi_scale)
return out1, landmarks
其中InvertedResidual(Mobilenetv2模块)实现
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, use_res_connect, expand_ratio=6):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.use_res_connect = use_res_connect
self.conv = nn.Sequential(
nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(inp * expand_ratio,
inp * expand_ratio,
3,
stride,
1,
groups=inp * expand_ratio,
bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
主干网络结构
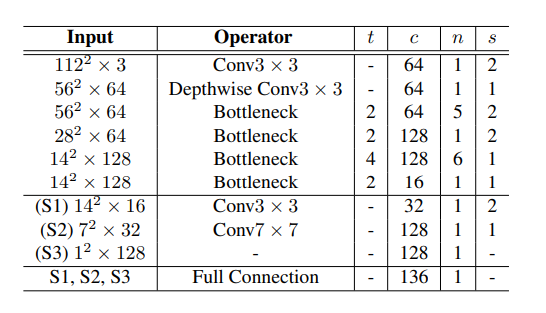
辅助网络实现如下。在论文中有提到, 并没有关于计算欧拉角的额外标注文件。计算方法是首先预定义一个平均人脸,固定N个关键点作为所有训练人脸的参考。接着使用每个人脸的N个特征点和参考点来估计旋转矩阵。最后利用旋转矩阵计算欧拉角。
AuxiliaryNet
class AuxiliaryNet(nn.Module):
def __init__(self):
super(AuxiliaryNet, self).__init__()
self.conv1 = conv_bn(64, 128, 3, 2)
self.conv2 = conv_bn(128, 128, 3, 1)
self.conv3 = conv_bn(128, 32, 3, 2)
self.conv4 = conv_bn(32, 128, 7, 1)
self.max_pool1 = nn.MaxPool2d(3)
self.fc1 = nn.Linear(128, 32)
self.fc2 = nn.Linear(32, 3)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.max_pool1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return x
辅助网络结构

AnchorFace
2021📕 AnchorFace: An Anchor-based Facial Landmark Detector Across Large Poses
AnchorFace是一种直接回归方法, 考虑了两种修改后的骨干网: ShuffleNet-V2(推理速度更快)和 HRNet-18(准确度更高)。HRNet 的结果仅用于 WFLW 数据集。作者解决了大姿态图像的地标预测问题。为此,他们建议为不同姿态的人脸配置一组anchor模板。anchor模板可以手动配置,也可以通过对数据集进行 KMeans 聚类来配置。然后利用网络对模板进行改进,该网络可预测每个anchor模板的偏移和置信度。
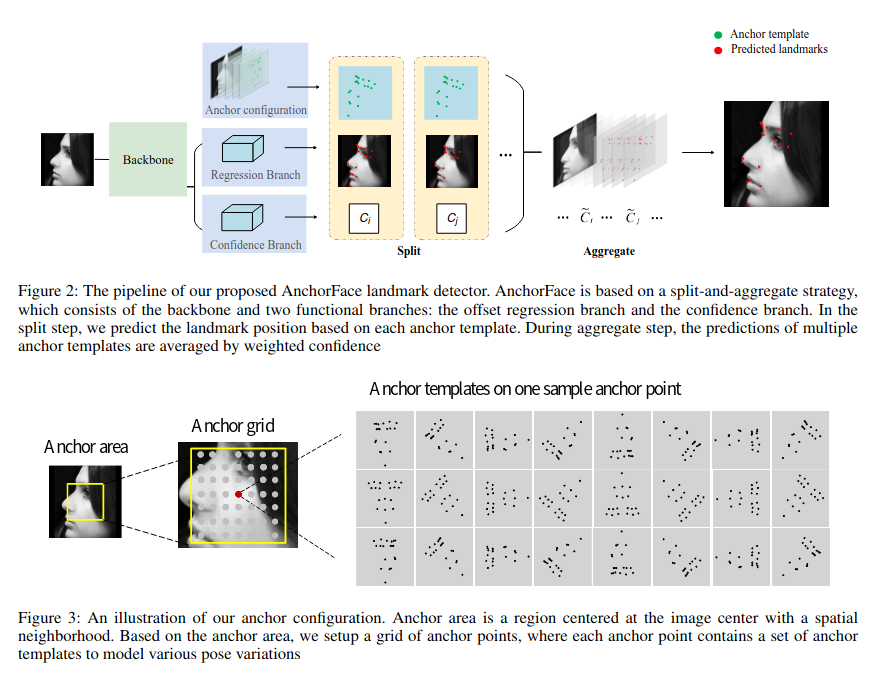
基于热图的方法
FAN
2017📕 How far are we from solving the 2D & 3D Face Alignment problem
🔥 code

该文主要贡献如下:
- 构建了一个2D人脸关键点检测baseline,主是结合了已有的最优的关键点检测的网络结构,并且在一个大规模的综合扩展了的2D人脸landmark数据集上进行训练。
- 为了弥补3D face alignment数据集的不足,提出了一个由2D标注转3D标注的CNN,并使用该网络创建了LS3D-W数据集,约230000张图片。
- 训练了一个3D face alignment网络,并且在新建的最大规模的3D face alignment数据集上进行评测。
- 进一步研究了影响face alignment性能的"传统"因素,像姿态、初始值以及分辨率等,并且提出了一个新的因素,就是网络的size
SAN
2018📕 Style Aggregated Network for Facial Landmark Detection
🔥 code
Style Aggregated Network, 是一种基于heatmap的方法, backbone为改进的resnet152。作者注意到300W和AFLW数据集中照片可以是深色也可以是浅色, 可以彩色也可以黑白, 其他的算法并没有考虑到这一点, 于是也会导致这些算法在不同风格的数据上预测也会略有差异。SAN的解决办法是首先训练一个GAN(CycleGAN)将不同风格的图片转成中性,并训练另外的网络将CycleGAN的输出和原图作为两个输入,来进行最终的关键点预测。Cycle的存在使得输入数据具有相似的颜色分布,这简化了神经网络对于人脸特征的学习。但又由于GAN的输出有可能存在伪影, 所以作者采用其输出和原图一起来进行联合预测。
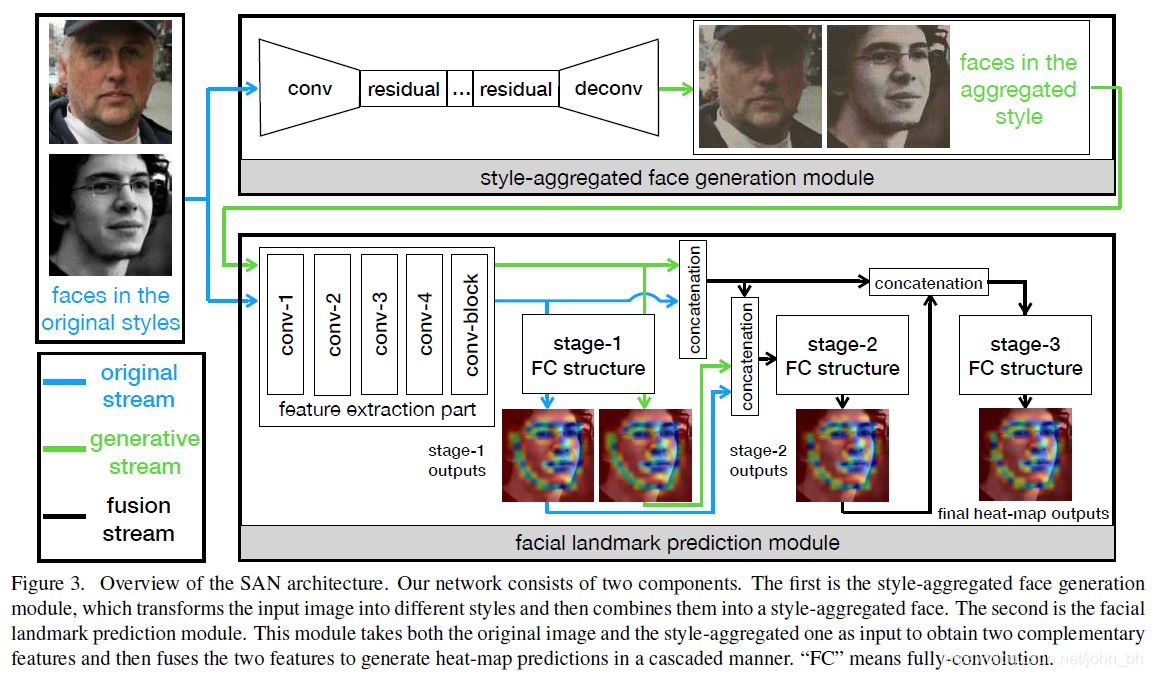
LAB
2018📕 Look at Boundary: A Boundary-Aware Face Alignment Algorithm
🔥 code
Look at Boundary,是一种热图和回归相结合的方法,使用4个堆叠的Hourglass模块来预测人脸轮廓热图,另外一个神经网络从中预测landmark。前者可以在不同数据集上同时训练得到轮廓热图,而后者则需要针对不同的数据集训练得到相应数量的关键点。对于面部被遮挡的情况,使用消息传递机制,在不同热图之间传递信息, 因此信息可以从可见边界传递到遮挡边界。
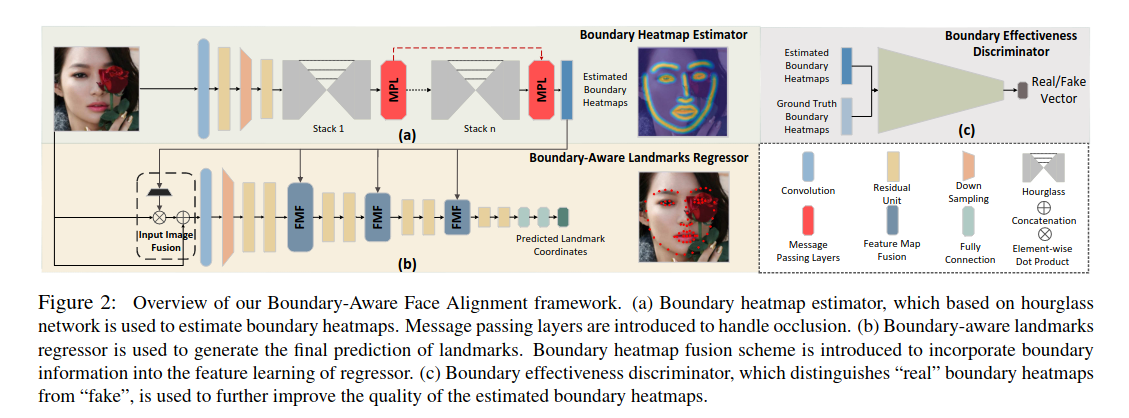
Boundary-Aware Face Alignment框架
-
基于hourglass网络的边缘热图估计器(Boundary heatmap estimator),用于估计边缘热图。采用 stack hourglass 通过最小化生成边界热图与真实边界热图之间的均方误差(MSE)对边界热图进行预测。为了缓解遮挡带来的负面影响, 不同的stack会关注不同的面部边界信息,以在不同的边界热图之间传递信息,由此信息可从可见边界传递到遮挡边界。
-
边缘感知关键点回归器(Boundary-aware landmarks regressor)用于生成关键点的最终预测。引入边缘热图融合方案,将边缘信息纳入回归问题的特征学习中。边界热图中各个像素取决于它们到相应边界线的距离。为了更好地利用丰富的边界热力图信息,采用多级边界热力图信息融合机制,如上图中,4级res-18网络作为基础网络,每级网络都进行边界信息融合(Boundary heatmap fusion),包含1次输入图像融合(Input Image Fusion),3次特征图融合(Feature Map Fusion)。实验结果表明在基础网络上执行的如何次数越多,得到的效果越好
-
引入对抗学习,边缘有效性鉴别器(Boundary effectiveness discriminator)区分“真实”边缘热图与“假”的边缘热图,用于进一步改善估计的边界热图的质量。

LAB在300w、COFW、AFLW上皆达到了最佳精度,此外作者团队还提出了一个新的数据集WFLW(Wider Facial Landmark in the Wild),以统一针对不同因素(包括姿势,表情,照明,化妆,遮挡和模糊)的训练和测试,该数据集共10000个样本,7500供训练,2500供测试。
AWing
2019📕 Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
🔥 code
Wing Loss
主要贡献:
- 对比不同的损失函数, 使用L1和平滑L1, 使得模型性能在广泛使用的L2损失上有所提升(mse对于小误差不明显)
- 提出新的损失函数wing loss, 旨在提高深度网络训练中应对小范围和中等范围内误差的能力
这里\(C = w - w ln(1+|x| / \epsilon)\), wing loss结合了用于大偏差的L1和用于中小偏差的\(ln()\)
- 提出了基于人脸姿态的数据平衡策略, 可以补偿训练集中头部姿势旋转较大的样本少的问题
- 提出一个二阶段的人脸关键点检测网络框架, 使用定制的网络CNN-6产生粗略的landmark然后使用CNN-7进行细化。
Adaptive Wing loss
这是一篇在人脸关键点检测中基于热图回归的损失函数研究。使用Hourglass作为backbone
-
wing loss存在梯度不连续点, 训练较难收敛,
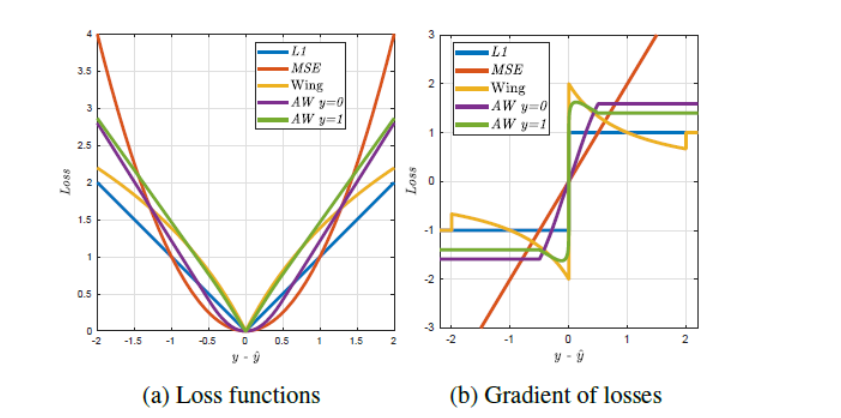
-
改进了wing loss ,提出了基于热图回归的Adaptive wing loss,它能够使其形状适应不同类型的 ground truth heatmap pixels,自适应属性可减少前景像素上的小误差,以实现精确的 landmark 定位,同时容忍背景像素上的小误差,以实现更高的收敛速度;
\[AWing(y,\hat{y})=\begin{cases}\omega\text{ln}(1+|\frac{y-\hat{y}}{\epsilon}|^{\alpha-y})&\text{if}|(y-\hat{y})|<\theta\\A|y-\hat{y}|-C&\text{otherwise}\end{cases} \]- y和 \(\hat{y}\) 分别表示 ground truth heatmap 和预测的 heatmap;
- A = $\omega(1/(1+(\theta /\omega)^{(\alpha - y)}))(\alpha -y)((\theta / \omega)^{(\alpha -y -1)})(1/\omega) $
- $C = (\theta A-\omega ln(1+(\theta /\omega)^{(\alpha -y)})) \(,使得函数在\)|y - \hat y|=\theta $处平滑连续。
- $\omega, \theta, \alpha, \epsilon $ 都是正数,$\omega = 14, \theta = 0.5, \alpha = 2.1, \epsilon = 1 \(;其中\)\alpha = 2.1 $ 因为 y的区间是[0,1],对 y 值接近1像素,幂指数$ \alpha -y $ 将略大于1,非线性部分将像wing loss ,在小的误差上由较大影响,但与wing loss 不同的是,当误差非常接近于零时,其影响会迅速降至零。另外,较大 $\omega $的和较小的 $\epsilon $ 增加对小误差的影响;
-
提出了加权损失图, 解决前景像素和背景像素之间的不平衡问题,能够在训练过程中专注于前景像素和困难的背景像素,有助于使得前景回传更大的loss,背景传递更小的loss,使得训练效果更好;
-
使用CoordConv 对坐标信息包括边界坐标信息进行编码,更像一种attention机制,有助于网络学习到更好的效果;
-
提出了将关键点的边界Boundary和关键点landmark一起训练的思路;
import torch import torch.nn as nn class AddCoordsTh(nn.Module): def __init__(self, x_dim, y_dim, with_r=False, with_boundary=False): super(AddCoordsTh, self).__init__() self.x_dim = x_dim self.y_dim = y_dim self.with_r = with_r self.with_boundary = with_boundary def forward(self, input_tensor, heatmap=None): """ input_tensor: (batch, c, x_dim, y_dim) """ batch_size_tensor = input_tensor.shape[0] xx_ones = torch.ones([1, self.y_dim], dtype=torch.int32).to(input_tensor) xx_ones = xx_ones.unsqueeze(-1) xx_range = torch.arange(self.x_dim, dtype=torch.int32).unsqueeze(0).to(input_tensor) xx_range = xx_range.unsqueeze(1) xx_channel = torch.matmul(xx_ones.float(), xx_range.float()) xx_channel = xx_channel.unsqueeze(-1) yy_ones = torch.ones([1, self.x_dim], dtype=torch.int32).to(input_tensor) yy_ones = yy_ones.unsqueeze(1) yy_range = torch.arange(self.y_dim, dtype=torch.int32).unsqueeze(0).to(input_tensor) yy_range = yy_range.unsqueeze(-1) yy_channel = torch.matmul(yy_range.float(), yy_ones.float()) yy_channel = yy_channel.unsqueeze(-1) xx_channel = xx_channel.permute(0, 3, 2, 1) yy_channel = yy_channel.permute(0, 3, 2, 1) xx_channel = xx_channel / (self.x_dim - 1) yy_channel = yy_channel / (self.y_dim - 1) xx_channel = xx_channel * 2 - 1 yy_channel = yy_channel * 2 - 1 xx_channel = xx_channel.repeat(batch_size_tensor, 1, 1, 1) yy_channel = yy_channel.repeat(batch_size_tensor, 1, 1, 1) if self.with_boundary and type(heatmap) != type(None): boundary_channel = torch.clamp(heatmap[:, -1:, :, :], 0.0, 1.0) zero_tensor = torch.zeros_like(xx_channel).to(xx_channel) xx_boundary_channel = torch.where(boundary_channel>0.05, xx_channel, zero_tensor) yy_boundary_channel = torch.where(boundary_channel>0.05, yy_channel, zero_tensor) ret = torch.cat([input_tensor, xx_channel, yy_channel], dim=1) if self.with_r: rr = torch.sqrt(torch.pow(xx_channel, 2) + torch.pow(yy_channel, 2)) rr = rr / torch.max(rr) ret = torch.cat([ret, rr], dim=1) if self.with_boundary and type(heatmap) != type(None): ret = torch.cat([ret, xx_boundary_channel, yy_boundary_channel], dim=1) return ret class CoordConvTh(nn.Module): """CoordConv layer as in the paper.""" def __init__(self, x_dim, y_dim, with_r, with_boundary, in_channels, out_channels, first_one=False, relu=False, bn=False, *args, **kwargs): super(CoordConvTh, self).__init__() self.addcoords = AddCoordsTh(x_dim=x_dim, y_dim=y_dim, with_r=with_r, with_boundary=with_boundary) in_channels += 2 if with_r: in_channels += 1 if with_boundary and not first_one: in_channels += 2 self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, *args, **kwargs) self.relu = nn.ReLU() if relu else None self.bn = nn.BatchNorm2d(out_channels) if bn else None self.with_boundary = with_boundary self.first_one = first_one def forward(self, input_tensor, heatmap=None): assert (self.with_boundary and not self.first_one) == (heatmap is not None) ret = self.addcoords(input_tensor, heatmap) ret = self.conv(ret) if self.bn is not None: ret = self.bn(ret) if self.relu is not None: ret = self.relu(ret) return ret -
Adaptive wing loss还有助于其他热图回归任务,例如人体关键点
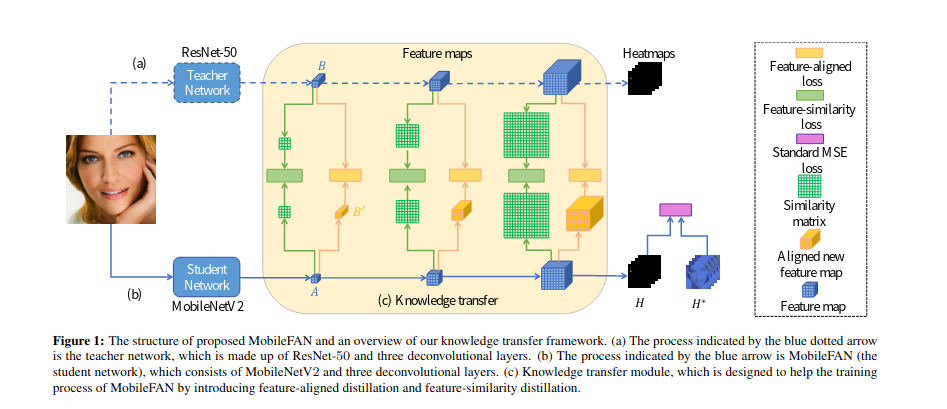
MobileFAN
2019📕 https://arxiv.org/pdf/1908.03839.pdf
🔥 code
MobileFAN是一种基于热图的方法,基于宽度为 1 倍或 0.5 倍的改进型 MobileNetV2 主干网。作者研究了网络蒸馏方法,以减少模型参数数量,提高基于热图方法的推理速度。需要说明的是, 该网络并非是继承自FAN
LUVLi
2020📕 LUVLi Face Alignment: Estimating Landmarks’ Location, Uncertainty, and Visibility Likelihood
🔥 code
作者发现,选择用于计算均值和协方差的方法至关重要。最好使用热图而不是直接回归来获得地标位置。为了使用热图以可区分的方式估计地标位置,LUVLI不选择每个地标热图的最大值(argmax)的位置,而是建议使用每个热图的正元素的空间均值。与地标位置不同,不确定性分布参数最好通过直接回归而不是从热图获得。为了估计预测位置的不确定性,作者添加了一个Cholesky估计器网络(CEN)分支来估计多元高斯或拉普拉斯概率分布的协方差矩阵。为了估算每个地标的可见性,作者添加了可见性估算器网络(VEN)。文中使用联合损失函数(称为位置,不确定性和可见性可能性(LUVLi)损失)将这些估计值合并在一起。设计此模型的主要目的是估计地标定位的不确定性。在此过程中,该方法不仅可以产生准确的不确定性估计,而且还可以在多个面部对齐数据集上产生SOTA界标定位结果。
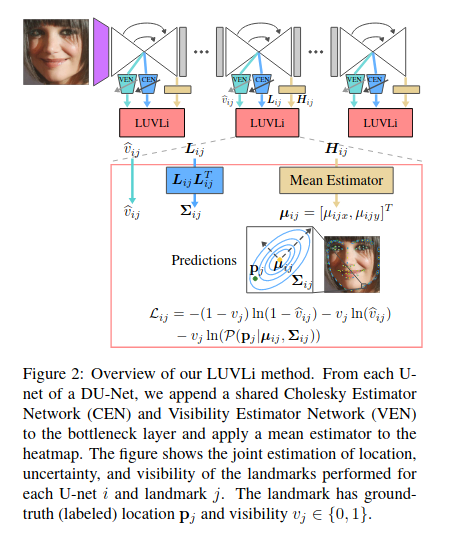
除了提出LUVLi作为损失函数来优化网络, 作者团队还发布了一个新的68点的数据集, 数据集包含19000张人脸图像,并且每张图像的每个关键点都被标明是否被遮挡
PropagationNet
2020📕 PropagationNet: Propagate Points to Curve to Learn Structure Information
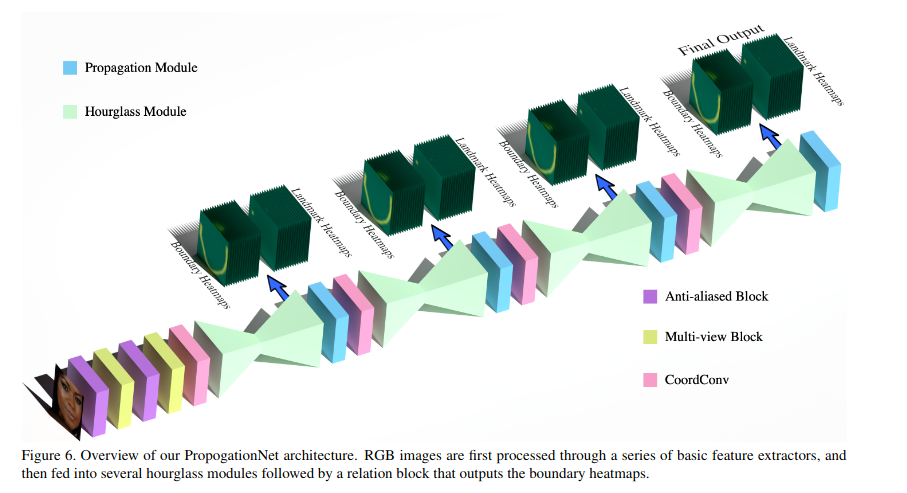
PropagationNet是一种基于热图的算法,以4个沙漏模块堆叠为骨干。作者指出了人脸边界信息对地标预测的重要性。之前的 LAB 方法使用了大量生成式对抗网络进行边界估计。PropagationNet 的作者提出了更简单、更快速的方法:在每个沙漏模块之后,由几个卷积块将地标热图转换为边界热图。边界热图可作为沙漏模块中间预测的注意力掩码,从而提高最终预测的准确性。此外,Hourglass 模块对 FAN 进行了修改,并使用 CoordConv和 Anti-aliased CNN进行了扩展。此外,作者还引入了 Focal Wing Loss,它是 Adaptive Wing loss 的扩展,可为当前训练批次中较少出现的图像场景分配更大权重。图像场景的例子包括大头姿势、夸张表情等。
PIPNet
2021📕 Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild
🔥 code
热力图回归擅长对单个关键点精准定位,但面对困难样本时,例如大面积遮挡、较大的转动角度等,热力图输出的部分关键点容易产生较大偏移,从而影响整体的预测结果。
此外,热力图回归需依赖高分辨率特征图,这给轻量级设备上的部署带来了更多计算负担。与其相反,坐标回归并不依赖高分辨率特征,且通过全局特征直接输出所有关键点的坐标,这使得它的预测具有全局形状约束,较为鲁棒,但平均每个点的精度并不高。
作者认为,经典的热力图回归将特征图上采样是没有必要的。启发于目标检测任务,当模型认为当前位置存在目标时,可直接回归预测目标点的位置, 这边是文中提出的pixel-in-pixel regression。考虑到坐标回归法的鲁棒性来源于特征共享,受此启发,作者提出在局部预测某个目标点偏移量的同时,也让它用同一个特征向量预测该目标点近邻的偏移量,这样就可以学到类似坐标回归的形状约束,以上便是近邻回归模块
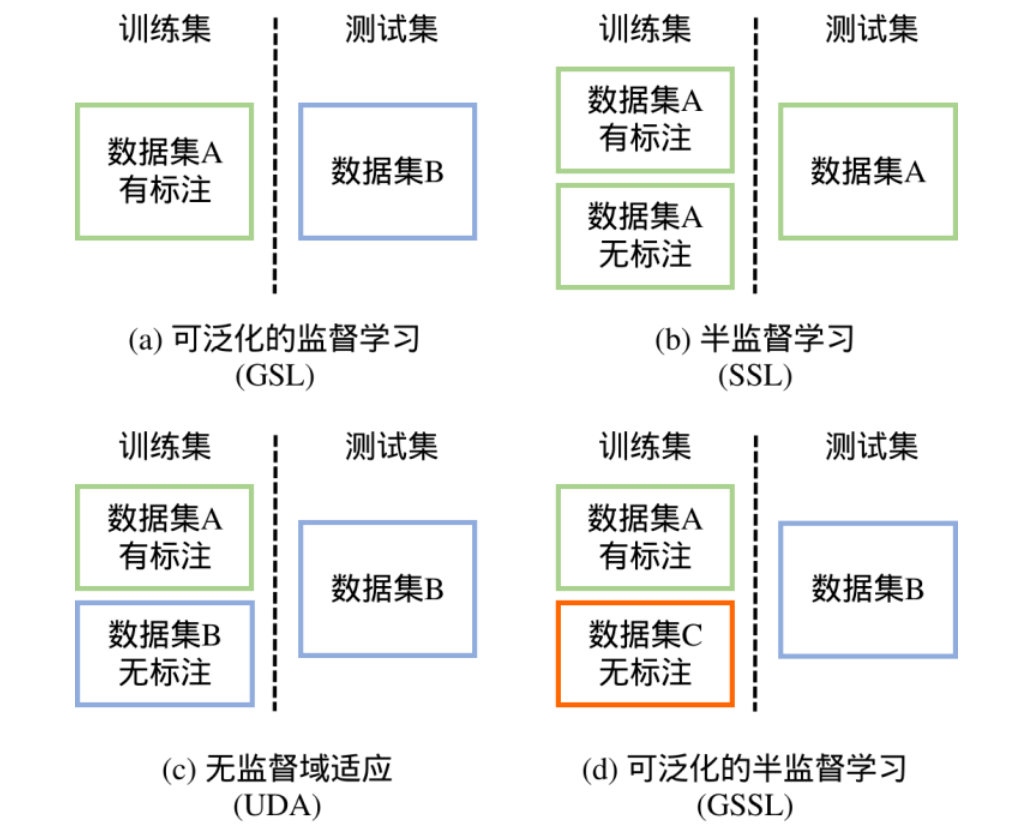
可泛化的监督学习依赖人工经验设计模块,不具有可扩展性。因此,文章提出了可泛化的半监督学习(generalizable semi-supervised learning, GSSL)范式,即利用大量跨领域的无标注数据来提升模型的跨领域泛化性能。
与GSL相比,GSSL更具有扩展性,因为其是数据驱动的,且无标签数据也容易收集。下图展示了不同范式之间的区别。
嵌套回归 pixel-in-pixel regression
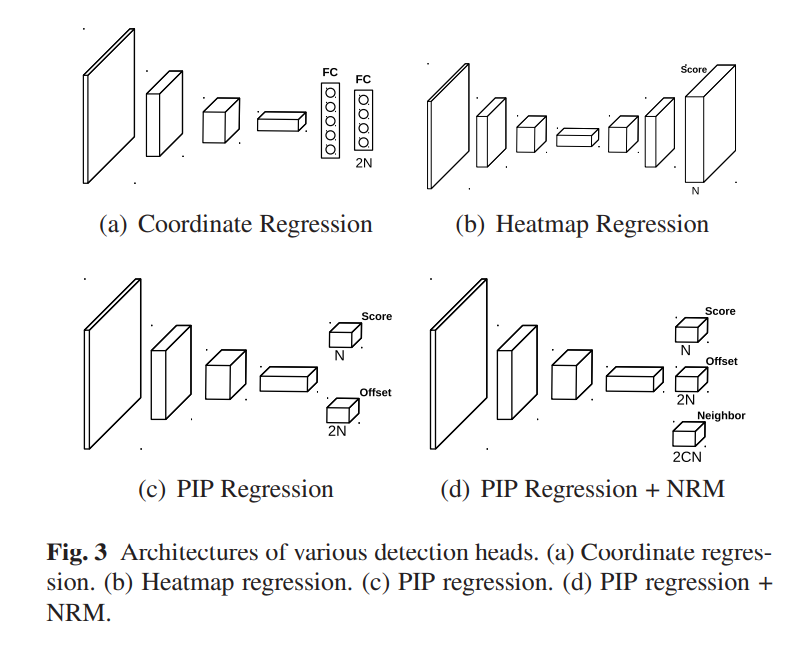
可以看到嵌套回归相比于热力图回归,除了特征图分辨率的差别,其额外需要在每个位置上预测所有点在x和y轴方向上的偏移量, 下图展示了嵌套回归训练时标签的生成机制

假设图中的红点是当前的目标关键点,我们首先根据其标注计算出该点会落到特征图的哪一个格子里,那么相应格子的分类标签设为1,其余格子均为0。
其次,假设目标点在该格子内的横向位移为0.3(位移范围0到1),纵向为0.8,那么x位移图和y位移图相应的格子上的标签分别为0.3和0.8,其余格子依然为0。该检测头的损失函数由两部分组成:
1)每个格子是否包含目标点的分类损失函数;
2)每个格子内目标点偏移量的回归损失函数。
然后两者通过平衡系数相加。需要注意的是,有关偏移量的损失函数只在分类图上相应格子标签为1时才计算。
近邻回归模块
嵌套回归可以很容易地增加近邻回归模块。如上图(d)所示的结构,只需额外在每个格子上预测每个目标点的C个(repo中为10)近邻的偏移量即可。但是每个目标点应该预测哪C个近邻呢?作者的做法是,根据训练标注计算出平均脸的关键点,然后根据欧氏距离找出离目标关键点最近的C个即可(不包括它自己)。对于训练时该模块的标签,假设上图(a)中的蓝点为目标点(红点)的其中一个邻居,可以看到蓝点相对红点所在格子在x、y上的偏移量为1.8(该模块偏移量可大于1)和0.7,那么近邻偏移图中相应的格子标签设为1.8和0.7,其余均为0。近邻回归模块的损失函数与目标点的偏移量类似
循序渐进的自训练方法
为了更好地利用跨领域的无标注数据来提升模型性能,作者提出循序渐进的自训练方法(self-training with curriculum, STC)。其思想为,在用自训练法估计伪标签时,一开始在较简单的任务上进行,然后逐渐增加难度直至标准的任务,这样可以减少因错误的伪标签带来的标签噪声。
图7展示了适用于STC的模型框架,可以看到,两个额外的热力图回归层被添加到一个标准的PIPNet中。假设输入图像是256,标准PIPNet的步长为32,那么PIPNet回归层的尺度为8,两个额外添加的热力图尺度分别为4和2。在传统的自训练中,模型不断在一个固定任务上从带有伪标签的图像中学习,直到收敛(比如,task 3就是这种情况)。对比,作者提出的STC,任务序列被安排成Task1->Task 2->Task 3循环,其任务难度不断增加直到任务3。通过这样做,模型引入和学习到的伪标签误差更少,因此可以缓解自训练中的错误强化问题。
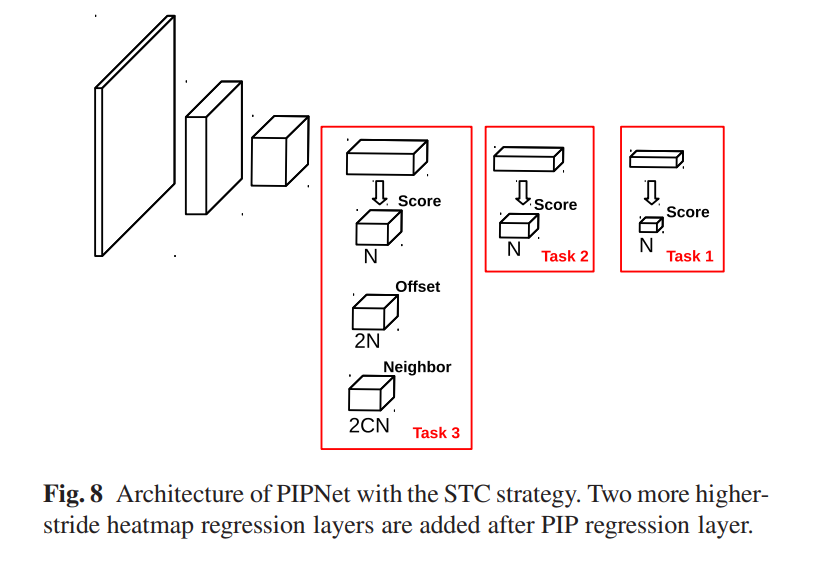
带有课程自训练的流程可以描述如下:
- 修改后的PIPNet以标准的方式(即Task3)使用真实标签来训练;
- 使用上述训练的检测器去评估未标注数据的伪标签;
- 将真实标注和伪标签数据组成一个新训练集;
- 修改后的PIPNet在新的训练集上训练,使用真实标注数据通过Task 3去训练模型,使用伪标签数据通过Task X去训练模型,其中Task X是从Task 1-2-3序列中循环选择。
推理阶段就是标准的pipnet。pipnet使用了多个backbone进行性能的对比,如res18、res50、mobilenetv2、mobilenetv3等等
ADNet
2021📕 ADNet: Leveraging Error-Bias Towards Normal Direction in Face Alignment
🔥 code
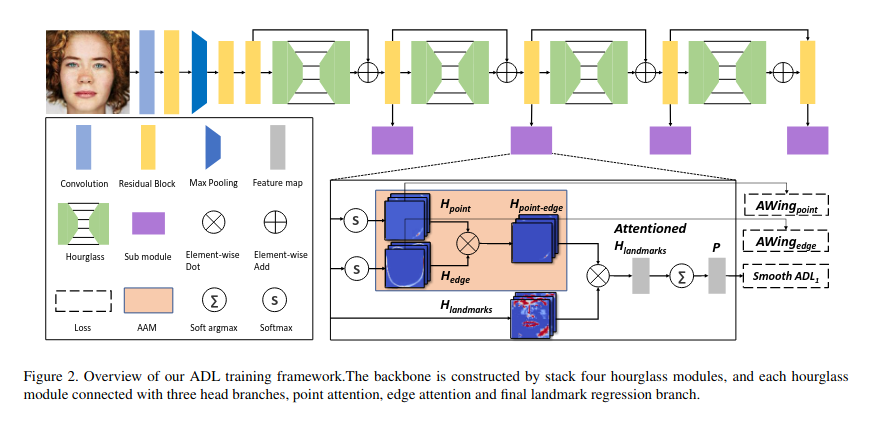
ADNet以 4 个沙漏模块堆叠为骨干。这项工作基于LAB 和PropagationNet。该文研究了人脸对齐中的误差偏差问题,其中landmark误差的分布倾向于沿着切线扩展到landmark曲线。这种错误偏差并非微不足道,因为它与模糊的landmark标记任务密切相关。作者寻求一种方法来利用误差偏差属性来更好地收敛 CNN 模型。为此,ADNet分别为坐标和热图回归提出了各向异性方向损失(ADL)和各向异性注意模块(AAM)。ADL 对面部边界上的每个标志点在法线方向施加强大的约束力。另一方面,AAM是一个注意力模块,可以得到各向异性的注意力掩码,聚焦于点的区域及其由相邻点连接的局部边缘,它在切线的响应比正常的要强,这意味着切线的约束放松。这两种方法以互补的方式工作以学习面部结构和纹理细节。

HIH
2021📕 HIH: Towards More Accurate Face Alignment via Heatmap in Heatmap
🔥 code

HIH是基于热图的方法, 使用Hourglass 模块作为主干。该算法的重点是减少热图量化误差。输入图像和地标注释的分辨率为 256 × 256。然而,每个地标的热图通常大小为 64 × 64,这是源图像分辨率的 1/16。然后使用 argmax 找到地标位置。将浮点地标位置映射到离散网格的过程称为量化。
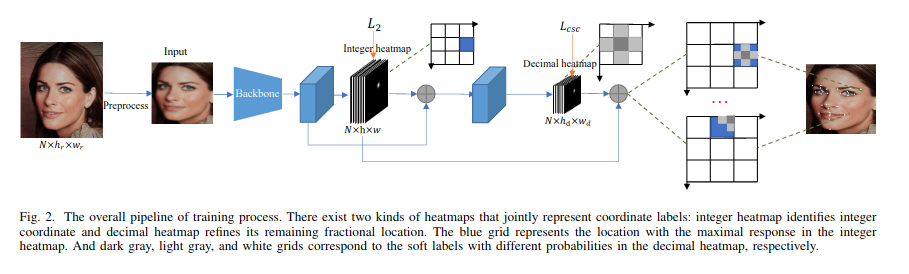
作者通过将热图分为整数和decimal来解决这个问题。整数热图通过基于热图的面部landmark预测pipeline进行预测。然后,另一个decimal热图块预测量化地标位置的精确偏移。预测偏移量的方法有两种:基于CNN和transformer,分别称为 HIHC 和 HIHT。
SubpixelHeatmap
2022📕 Subpixel Heatmap Regression for Facial Landmark Localization
🔥 code
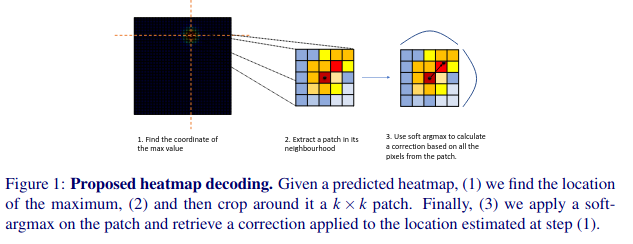
SubpixelHeatmap也想解决HIH中提到的量化问题, 而作者给出了一种不同的解决方案, 即局部soft-argmax计算。对于给定的heatmap \(H_k\), 一般找到第k个landmark的方法是\((\hat{\hat{y}}_{k}^{[1]},\hat{\hat{y}}_{k}^{[2]})=\arg\max H_{k}\), 然后通过近邻patch dxd 上的局部soft-argmax进行细化:
其中\(\tau\)为10, d为5, 最终的坐标通过\((\hat{y}_{k}^{[1]}+\Delta\hat{y}_{k}^{[1]}-l,\hat{y}_{k}^{[2]}+\Delta\hat{y}_{k}^{[2]}-l)\)得到, \(\hat{y}_{k}^{[1]}\)、\(\hat{y}_{k}^{[2]}\)分别表示XT轴上的坐标, l = d/2。
此外, backbone采用的是根据 FAN 算法进行修改得到的 Hourglass
SPIGA
2022📕 Shape Preserving Facial Landmarks with Graph Attention Networks
🔥 code
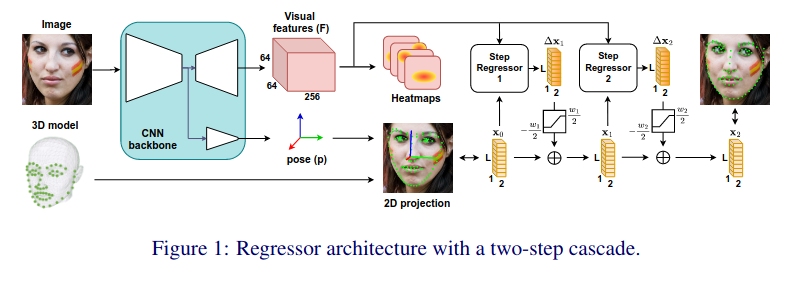
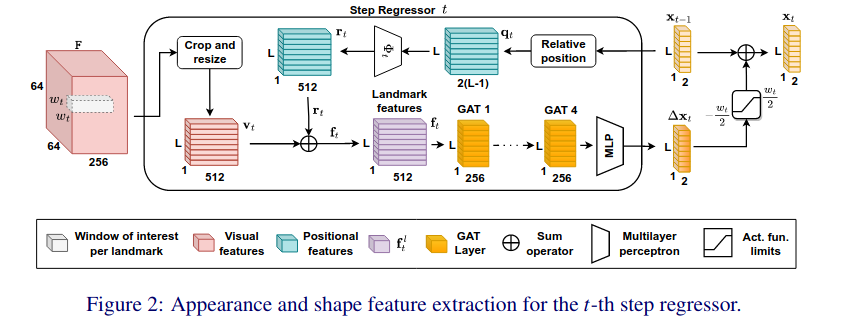
本文提出了用于估计人脸特征点的 SPIGA(带有 GAts 的形状保持)模型。该算法遵循传统的回归器级联方法,并提出了一种将多级热图主干与图注意网络(GAT)回归器级联相结合的算法。级联 GAT 回归器具有位置编码和注意力机制,可以学习地标之间的几何关系。作者使用多任务方法训练我们的骨干网,该方法还估计头部姿势,使用其投影来建立初始地标位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号