
[Deep Learning] 使用多分类的Sequential神经网络模型实现新闻分类
一、内容实现概述
本文主要讲述使用keras库内置的Sequential(序列)模型,实现新闻分类。 具体实现过程如下:
- 导入所需库:预先导入keras以及numpy库
- 导入数据:调用keras库内置的新闻数据库(reuters, 即路透社)方法load_data(),导入并分割好数据
- 数据预处理:对由整数表示的新闻数据进行向量化
- 构建模型:调用keras库的Sequential模型类,构建模型
- 添加网络层,使用常见的Relu类型激活函数以及最后一层激活函数为Softmax(由于是多分类)
- 编译模型:调用keras库的compile()方法对模型进行编译,设置常损失函数模板(分类交叉熵误差)和评估模板(准确率)
- 训练模型:调用keras库的fit()方法对训练集数据进行拟合,设置好迭代轮次和批次参数值
- 评估模型:调用keras库的evaluate()方法对测试集数据进行预测
- 预测模型:调用keras库的predict()方法对测试集数据进行预测
注:
- 在Python中使用(导入)keras库时,需要先安装,本实现使用的是pip命令安装 pip install --upgrade keras
- 在Python中使用(导入)numpy库时,需要先安装,本实现使用的是pip命令安装 pip install numpy
- Keras官方教程
二、代码实现
注:源代码地址
# 该实现为新闻分类模型的优化,并利用训练好的模型对新数据进行预测
## 总结:
# 1. 如果要对N个类别的数据点进行分类,那么模型的最后一层应该是大小为N的Dense层
# 2. 对于单标签、多分类问题,模型的最后一层应该使用softmax激活函数,这样可以输出一个在N个输出类别上的概率分布
# 3. 对于这种问题,损失函数几乎总是应该使用分类交叉熵。它将模型输出的概率分布与目标的真实分布之间的距离最小化。
# 4. 处理多分类问题的标签有两种方法:
# a. 通过分类编码(也叫one-hot编码)对标签进行编码,然后使用categorical_crossentropy损失函数;
# b. 将标签编码为整数,然后使用sparse_categorical_crossentropy损失函数。
# 5. 如果你需要将数据划分到多个类别中,那么应避免使用太小的中间层,以免在模型中造成信息瓶颈
import os
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
from keras.src.datasets import reuters
import numpy as np
from keras.src import Sequential
from keras.src.layers import Dense
# 1. 导入Reuters新闻数据集
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=10000)
# 2. 数据预处理
def vectorize_sequences(sequences, dimension=10000):
result = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
result[i, j] = 1
return result
# def to_one_hot(labes, dimension=46):
# result = np.zeros((len(labes), dimension))
# for i, label in enumerate(labes):
# result[i, label] = 1
# return result
X_train = vectorize_sequences(X_train)
X_test = vectorize_sequences(X_test)
# 处理多分类问题的标签有两种方法:
# 1. 通过分类编码(也叫one-hot编码)对标签进行编码,然后使用categorical_crossentropy损失函数
# 2. 将标签编码为整数,然后使用sparse_categorical_crossentropy(稀疏分类交叉熵)损失函数
# y_train = to_one_hot(y_train)
# y_test = to_one_hot(y_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
# 3. 模型处理
# 第一步:导入模型
model = Sequential()
# 第二步:添加网络层
model.add(Dense(64, activation='relu'))
# 如果需要将数据划分到多个类别中,那么应避免使用太小的中间层,以免在模型中造成信息瓶颈。本例有46个分类
model.add(Dense(64, activation='relu'))
model.add(Dense(46, activation='softmax'))
# 如果要对N个类别的数据点进行分类,那么模型的最后一层应该是大小为N的Dense层
# 对于单标签、多分类问题,模型的最后一层应该使用softmax激活函数,这样可以输出一个在N个输出类别上的概率分布
# 第三步:编译模型
# 对于这种单标签、多分类问题,损失函数几乎总是应该使用分类交叉熵(categorical_crossentropy)。
# 它将模型输出的概率分布与目标的真实分布之间的距离最小化
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 第四步:训练模型
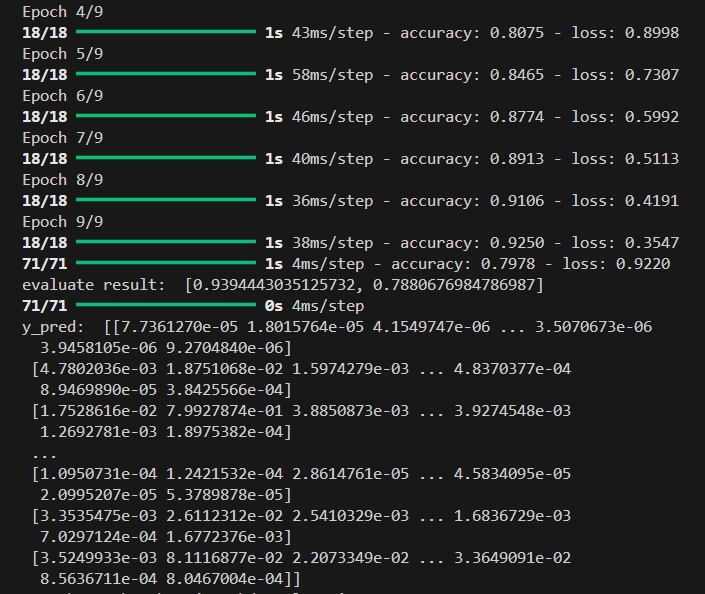
history = model.fit(X_train, y_train, epochs=9, batch_size=512)
# 第五步:评估模型
result = model.evaluate(X_test, y_test)
print("evaluate result: ", result)
# 第六步:预测模型
y_pred = model.predict(X_test)
print("y_pred: ", y_pred)
三、运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号