
[Machine Learning] 使用经典聚类模型k均值(k-means)实现blobs聚类
一、内容实现概述
本文主要讲述使用scikit-learn库内置的k-means模型,实现斑点聚类。具体实现过程如下:
- 1. 导入所需库:预先导入numpy、matplotlib以及scikit-learn库
- 2. 导入数据:调用sklearn库内置的加载数据的方法make_blobs(),导入斑点数据
- 3. 数据预处理:对blobs数据进行预处理,获得特征数据与目标数据
- 4. 数据分割:使用sklearn库的数据分割方法对步骤3中的数据进行比例分割,得到训练集和测试集数据
- 5. 构建模型:调用sklearn库的聚类模型类KMeans构建模型(本实现已手动设置聚类数这个超参数值为4,根据该数据训练后的结果观察得来)
- 6. 训练模型:调用sklearn库的fit()方法对训练集数据进行训练
- 7. 预测模型:调用sklearn库的predict()方法对测试集数据进行预测
注:
- 在Python中使用(导入)numpy库时,需要先安装,本实现使用的是pip命令安装 pip install numpy
- 在Python中使用(导入)matplotlib库时,需要先安装,本实现使用的是pip命令安装 pip install matplotlib
- 在Python中使用(导入)scikit-learn库时,需要先安装,本实现使用的是pip命令安装 pip install -U scikit-learn
- Scikit-Learn官方教程
二、代码实现
注:源代码地址
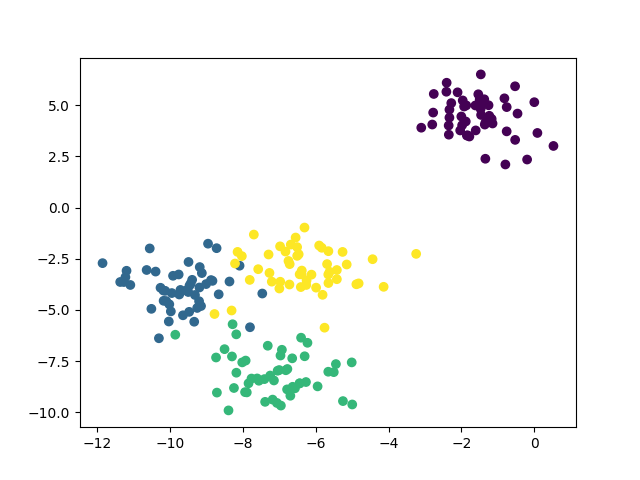
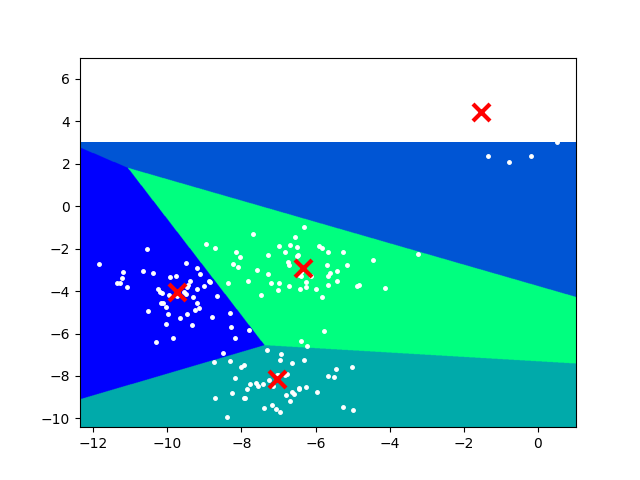
from sklearn.datasets import make_blobs from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np # 加载数据 blobs = make_blobs(n_samples=200, random_state=1, centers=4) # 数据预处理 X = blobs[0] y = blobs[1] ## 特征X的值对应的类别标签数据 plt.scatter(X[:, 0], X[:, 1], c=y) plt.show() # 导入模型 kmeans = KMeans(n_clusters=4, n_init=10, max_iter=300, random_state=None) # 训练模型 kmeans.fit(X) # 预测模型:聚类 ## 获取簇边界 X_min, X_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5 y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5 ## 生成网络点矩阵 xx, yy = np.meshgrid(np.arange(X_min, X_max, 0.02), np.arange(y_min, y_max, 0.02)) ### 把这个密集的网格坐标点当作一个测试集,把这些坐标点拿去预测,看它们分别属于哪个簇 ### np.c_[arr_1, arr_2],表示将两个一维数组变成一个二维数据 Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # 评估模型 # 绘制图表 plt.figure(1) plt.clf() ## 根据每个网格点所属的簇不同,渲染不同的颜色 plt.imshow(Z, cmap=plt.cm.winter, origin='lower', interpolation='hermite', extent=(xx.min(), xx.max(), yy.min(), y.max()), aspect='auto') plt.plot(X[:, 0], X[:, 1], 'w.', markersize=5) ## 簇中心(质心)的坐标 centroid = kmeans.cluster_centers_ ## 将簇中心用标记“×”标识出来 plt.scatter(centroid[:, 0], centroid[:, 1], c='r', marker='x', linewidths=3, s=150, zorder=10) plt.xlim(X_min, X_max) plt.ylim(y_min, y_max) plt.xticks() plt.yticks() plt.show()
三、运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号