
x264阅读记录-2
x264阅读记录-2
7. x264_encoder_encode函数-1
查看该函数代码(Encoder.c文件)可以发现,该函数中注释很详细,对编码的整个步骤展示的也相对比较清晰。
在查看具体的代码之前,我们需要了解牵扯到x264帧管理过程中的三个数组:
- x264_frame_t *current[X264_BFRAME_MAX*4+3];/*已确定帧类型,待编码帧,每一个GOP在编码前,每一帧的类型在编码前已经确定。当进行编码时,从这里取出一帧数据。*/
- x264_frame_t *next[X264_BFRAME_MAX*4+3];//尚未确定帧类型的待编码帧,当确定后,会将此数组中的帧转移到current数组中去。
- x264_frame_t *unused[X264_BFRAME_MAX*4 + X264_THREAD_MAX*2 + 16+4];/*这个数组用于回收那些在编码中分配的frame空间,当有新的需要时,直接拿过来用,不用重新分配新的空间,提高效率*/
A. Setup new frame from picture 根据picture中的数据建立frame数据结构
这儿要区分输入数据是否为NULL,如果为NULL就说明是要从缓冲中获取B帧来进行编码,否则直接根据输入数据建立当前要编码的帧结构:
步骤1:(这个步骤是在一个if判断语句之内进行操作的,判断条件就是传入的数据是否为NULL,联系前面对代码的阅读可以知道,如果是进行B帧的编码的话,参数就是NULL,这时是不需要取picture中的数据来建立frame数据结构的,因为在next列表中是存在有帧的,这时只需要从next列表中取就可以了)
/* 1: Copy the picture to a frame and move it to a buffer */
首先是:
/* Get the picture(fenc) from the start of List(h->frames.unused) */
x264_frame_t *fenc = x264_frame_get ( h->frames .unused );
从x264_frame_get 函数的代码可以看到是直接从h ->frames .unused这个列表中直接把第一个元素去了出来,然后后面的元素依次前移。
其次是:
/* Cpy data from pic_in to fenc for further processing */
x264_frame_copy_picture( h , fenc , pic_in );
查看x264_frame_copy_picture 代码可以知道,根据pic_in中图像的颜色空间情况进行了数据的复制。
i_frame是用来标示图像的原始顺序(播放顺序)的:
fenc-> i_frame = h ->frames. i_input++; //frame count, i_frame is in presentation(raw yuv input) order.
接下来:
/* Put the picture(fenc) at the end of Next List(h->frames.next) */
x264_frame_put( h ->frames. next, fenc );
函数x264_frame_put的代码告诉我们,我们是将当帧fenc添加到了frames.next列表中。
当current数组中不存在帧的时候,就需要填充这个数组:
步骤2:
/* 2: Select frame types */
if( h-> frames.next [0] == NULL )
return 0;
/* Decide the Slice(Frame) type for Slices in next list, Return Once we found a Non-B frame*/
x264_slicetype_decide( h );
步骤3:
/* 3: move some B-frames and 1 non-B to encode queue(current list) from next queue */
首先是找出第一个非B帧,同时统计出B帧之前的非B帧的数目。
while( IS_X264_TYPE_B ( h->frames .next [bframes ]->i_type ) )
bframes++;
然后是:
/* Move 1 non-B frame into current List*/
x264_frame_put( h ->frames. current, x264_frame_get( &h ->frames. next[ bframes] ) );
.....
接下来是跟前面统计的B帧的数目bframes,从next的列表的开头(因为x264_frame_get函数就是从列表开头开始操作)依次取出相应的B帧放入到current列表最后(因为x264_frame_put函数就是不断的将参数中给出的帧添加到队尾的)
这主要是因为B帧必须等后面的非B帧编码结束后才能编码,所以把暂时不编的一系列B帧存入队列中,一直到非B帧才取出进行编码,之后再进行前面的B帧编码
/* Move the consequent B frames to current list from next list*/
while( bframes -- )
x264_frame_put( h ->frames. current, x264_frame_get( h ->frames. next ) );
下面对A步骤进行一下总结:
这个步骤其实就是一个准备工作,就是为了下一步进行帧编码的时候可以取到正确的帧,为此主要是在3个和帧管理相关的列表之间转移帧。
B. 选取帧进行编码
/* ------------------- Get frame to be encoded ------------------------- */
步骤4:从current列表中取出第一帧进行编码
/* 4: get picture to encode(The first frame in current list) */
h-> fenc = x264_frame_get( h ->frames. current );
if( h-> fenc == NULL )
{
/* Nothing yet to encode (ex: waiting for I/P with B frames) ??*/
/* waiting for filling bframe buffer */
pic_out->i_type = X264_TYPE_AUTO ; //??
return 0;
}
C.建立帧上下文
/* ------------------- Setup frame context ----------------------------- */
步骤5: /* 5: Init data dependant of frame type */
根据帧的类型来进行变量赋值,主要是这3个变量:i_nal_type, i_nal_ref_idc,i_slice_type
需要注意的是:对于IDR帧,需要调用函数x264_reference_reset来重置参考帧列表。(IDR帧是两个GOP之间的边界)
i_poc是帧在GOP中的顺序,i_frame是帧的播放顺序。
D. 初始化
/* ------------------- Init ----------------------------- */
首先,为当前帧建立参考帧列表
/* build ref list 0/1 for current encoding frame.*/
x264_reference_build_list( h, h-> fdec-> i_poc, i_slice_type );
其次,初始化码率控制相关
/* Init the rate control */
x264_ratecontrol_start( h, i_slice_type, h->fenc ->i_qpplus1 );
// Get the qp for macroblock.
i_global_qp = x264_ratecontrol_qp( h );
接下来,如果是B帧,需要为双向参考做好准备:
if( i_slice_type == SLICE_TYPE_B )
x264_macroblock_bipred_init( h );
E. 创建Slice头
/* ------------- Create(Initialize) slice header ----------------------- */
x264_slice_init( h, i_nal_type, i_slice_type , i_global_qp );
F. 写比特流
/* ---------------------- Write the bitstream -------------------------- */
首先是:初始化比特流上下文
/* Init bitstream context */
h-> out. i_nal = 0;
bs_init( & h-> out. bs, h-> out. p_bitstream, h->out .i_bitstream );
注意:access unit delimiters 是NALU的一种类型,用于分割不同的访问单元。
然后是:写SPS和PPS
/* Write SPS and PPS */
由于SPS和PPS是一组图像共同的信息,只有当本帧图像是IDR是才需要写SPS和PPS信息。
/* generate sequence parameters */
x264_nal_start( h , NAL_SPS , NAL_PRIORITY_HIGHEST );
x264_sps_write( &h ->out. bs, h-> sps );
x264_nal_end( h );
/* generate picture parameters */
x264_nal_start( h , NAL_PPS , NAL_PRIORITY_HIGHEST );
x264_pps_write( &h ->out. bs, h-> pps );
x264_nal_end( h );
x264_nal_start 和x264_nal_end 两个函数完成对NALU的码流写入。x264_sps_write 和x264_pps_write 函数就是根据H.264规定的语法结构进行相应信息的写入。
接下来是:对帧的数据进行编码,并写码流
/* Write frame ,The Key function*/
i_frame_size = x264_slices_write( h );
x264_slices_write 是进行具体编码的核心函数。
注意:这个地方不明白为什么要执行下列操作?
/* restore CPU state (before using float again ??) */
x264_cpu_restore( h-> param.cpu );
之后可能还要有一些操作:如果P帧编码出错,就重新编码成I帧。设置码流特征信息,设置码流输出。码流控制更新(x264_ratecontrol_end),更新参考帧(x264_reference_update),重置缓冲区(x264_frame_put),计算编码状态信息。
最后是:结束码流
/* End bitstream, set output */
*pi_nal = h-> out. i_nal;
*pp_nal = h-> out. nal;
G. 在编码完当前帧之后,更新编码器的相关状态
/* ---------------------- Update encoder state ------------------------- */
首先:更新码流控制相关
/* update rc */
x264_cpu_restore( h-> param.cpu );
x264_ratecontrol_end( h, i_frame_size * 8 );
然后:更新参考帧列表(同时回收了当前帧所使用的空间)
/* handle references , Update references after Encoing One frame.*/
if( i_nal_ref_idc != NAL_PRIORITY_DISPOSABLE )//
x264_reference_update( h );
// Put back.
x264_frame_put( h-> frames.unused , h ->fenc );
H. 计算相关的统计数据
/* ---------------------- Compute/Print statistics --------------------- */
包括各类型帧的数目,PSNR 等。
8. x264_encoder_encode函数-2
给出该函数的调用图:
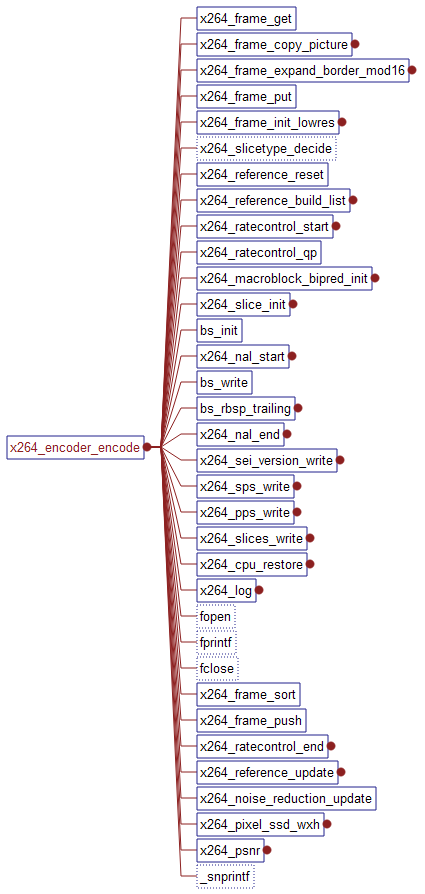
对于其中的一些函数,已经进行了简单分析,就不再分析了,主要分析一些重要的函数。
(1)x264_slicetype_decide
用于判断next list中的slice的类型。

这个函数中涉及到x264在何种情况下怎样决定帧的类型,同时对GOP的大小进行了限定。
(2)x264_ratecontrol_start和x264_ratecontrol_qp
和码率控制相关。

(3)x264_slice_init

主要包括头信息的初始化和宏块信息初始化。
(4)x264_sps_write和x264_pps_write
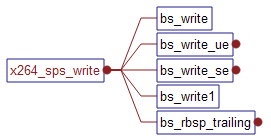
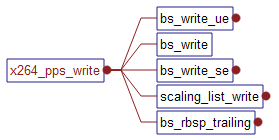
从调用函数可以看到,主要是调用了和写码流相关的函数:bs_write, bs_write_ue, bs_write_se, bs_write1,
这些函数都是将具体的信息采用熵编码的方式转换为码流。
(5) x264_slices_write
这个是核心函数。
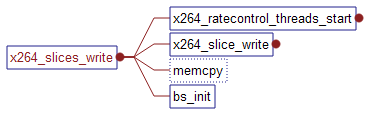
这个函数是根据是否采用多线程而形成了两个分支
9. x264_slice_write函数
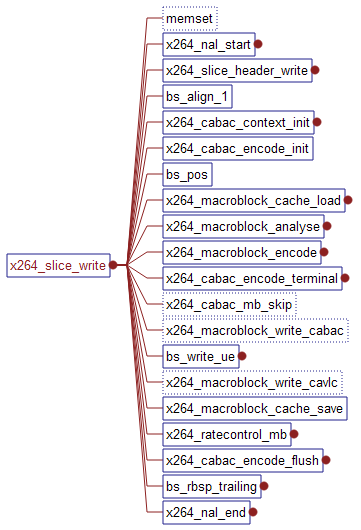
(1)首先是对存储帧统计数据的结构体进行初始化
/* init stats */
memset( & h-> stat. frame, 0, sizeof (h ->stat. frame) );
(2)由于本函数是对slice进行编码,所以先调用x264_nal_start来将slice相关的一些信息写入到NALU中。
(3)将slice的头信息写入到NALU中:x264_slice_header_write
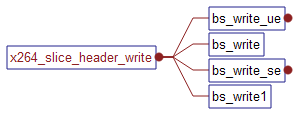
主要是调用相关的码流写入函数。
(4)如果采用了CABAC编码的话,需要进行相关初始化。
主要调用x264_cabac_context_init和x264_cabac_encode_init
(5)for循环:这是对slice中的每一个宏块进行编码。
bs_pos函数用于输出比特流的当前当前读写位置。
x264_macroblock_cache_load函数是将已编码数据参数和待编码数据装入到h->mb.cache中。
x264_macroblock_analyse函数完成模式选择:* Slice I: choose I_4x4 or I_16x16 mode
* Slice P: choose between using P mode or intra (4x4 or 16x16)
x264_macroblock_encode函数是根据选定的模式进行编码。
宏块编码完成之后,根据所采用的熵编码方式来进行码流的写入:x264_macroblock_write_cabac或x264_macroblock_write_cavlc
x264_macroblock_cache_save函数保存已编码的信息,为了下一次的编码做参考。
然后统计编码状态数据,如果使用了动态qp值,用 x264_ratecontrol_mb进行qp调整。
(6)bs_rbsp_trailing,写入编码结尾数据。
(7)x264_nal_end结束NALU
10. x264_macroblock_cache_load和x264_macroblock_cache_save函数
x264_macroblock_cache_load将参考帧中某位置的(重建后)数据保存进cache,供参考和反复使用。
x264_macroblock_cache_save在分析和编码后将当前块写进cache。
这两个函数都是在操作h->mb.cache,在而h->mb.cache的设计是非常巧妙的,这里还要牵扯到数组x264_scan8用来索引cache。
11. x264_macroblock_analyse函数-1
这个函数是进行H.264中主要的一个工作:模式选择,所以调用的函数也很多。这儿主要分析其流程。
(1)调用x264_macroblock_init函数
主要是初始化变量,如帧间、帧内的satd值、初始化MV的范围等一些参数。
(2)针对不同类型的帧进行分析。
A. 对于I帧,调用x264_mb_analyse_intra进行帧内预测。在这个函数中,分别对16x16, 4x4 和8x8进行模式预测,计算SATD。然后进行比较16x16,8x8,4x4的cost,获得帧内编码的宏块的模式。
注意到最后的模式是使用h->mb .i_type来记录的,并且只是宏块的模式,对于具体的模式是记录在x264_mb_analysis_t结构体的元素i_predict16x16,i_predict8x8[2][2]和i_predict4x4[4][4]中。
B. 对于P帧,首先判断是否是skip模式,只有在左,上,左上,右上有一个是skip模式的时候,这时mb才可能是skip模式。然后调用函数x264_macroblock_probe_pskip来判断当前宏块是否可以采用skip模式进行编码。
当不采用p_skip模式时,就需要从帧间模式中选择合适的模式来编码。
首先是调用函数x264_mb_analyse_load_costs来对所有可能的MV来提前计算cost:lambda*nbits.
这儿代码中的注释好像有些问题,对我有些误导。我仔细看了这儿的代码之后,具体理解是:
对于16x16,16x8,8x16,8x8,8x4,4x8,4x4,这些块的划分方式,代码中是先对16x16进行分析,调用函数x264_mb_analyse_inter_p16x16,然后可以计算得到相应的运动矢量和l0.me16x16 .cost(其中还要考虑到参考帧部分,运动估计)。
在开启对宏块进行子划分的情况下,先对8x8模式进行分析,调用的是函数x264_mb_analyse_inter_p8x8或x264_mb_analyse_inter_p8x8_mixed_ref(主要看是否允许子块采用不同的参考帧),对4个8x8块进行分析,包括运动估计,参考帧选择等,最后得到运动矢量、参考帧和l0.i_cost8x8,l0.me8x8[i].cost。
接下来比较一下16x16和8x8下的cost,如果8x8的l0.i_cost8x8较小,就需要进行子划分8x4,4x8和4x4的分析。这样,对于4个8x8块,在for循环中进行依次分析。也是首先调用x264_mb_analyse_inter_p4x4函数对8x8块中的4个4x4块进行分析(运动估计,参考帧选择),最后计算得到i_cost4x4[i8x8],将这个i_cost4x4[i8x8]与l0.me8x8[i].cost比较,看是否要进行8x4,4x8的划分,对应的调用函数x264_mb_analyse_inter_p8x4和x264_mb_analyse_inter_p4x8,得到相应的l0.i_cost8x4 [i ]和l0.i_cost4x8 [i ],并经过和i_cost4x4[i]进行比较,选出最优的子划分保存在h->mb .i_sub_partition [i]中。经过这一系列操作,8x8模式就分析完了。
再接着分析16x8和8x16两种模式,分别调用函数x264_mb_analyse_inter_p16x8和x264_mb_analyse_inter_p8x16,计算得到l0.i_cost16x8和l0.i_cost8x16,并经过比较得到最优划分保存在mb.i_partition中。这样就完成了模式的选择。
完成模式选择之后,为了提高运动估计的精确度,对最优模式划分进行亚像素运动搜索,调用函数x264_me_refine_qpel。
由于在P帧中同样可以采用帧内预测,所以接着调用函数x264_mb_analyse_intra进行帧内模式选择,还有可能调用x264_mb_analyse_intra_chroma对色度进行模式选择。
最终经过一系列的比较,得到最优的模式保存在h->mb .i_type中。
C. 对于B帧,由于B帧可以双向参考,所以比较复杂。
首先调用x264_mb_predict_mv_direct16x16判断是否采用B_Direct模式,如果采用直接模式,则分别进行空间和时间的直接预测。这里B帧双向参考,前向和后向的参考和p帧的方向是类似的。
也调用x264_mb_analyse_load_costs函数来进行运动估计cost方面的初始化。
接着调用函数x264_mb_analyse_inter_b16x16来对16x16划分方式分析,其中对L0和L1两个参考列表中的帧都进行了运动搜索。
接下来对8x8方式进行分析,调用的是函数x264_mb_analyse_inter_b8x8,对4个8x8块进行了操作,得到i_cost8x8bi。并将i_cost8x8bi与16x16情况进行比较,如果i_cost8x8bi较小的话,需要根据4个8x8块在x264_mb_analyse_inter_b8x8函数中决定的子划分方式mb.i_sub_partition [i]来决定是采用8x16还是16x8,调用相应的函数x264_mb_analyse_inter_b16x8和x264_mb_analyse_inter_b8x16,计算得到相应的cost之后,就能比较得到最优的划分方式,保存在 h-> mb. i_partition中。
从上面可以看到,在x264中B帧中宏块不支持8x8以下的划分的。
这样完成模式选择之后,同样对最优的划分模式进行亚像素的运动搜索,与P帧情况类似。还是调用函数x264_me_refine_qpel,只是调用的次数更多。
同样采用了函数x264_mb_analyse_intra进行了帧内模式选择,最后从帧内和帧间中选出最佳的模式,保存在h->mb .i_type中。
(3)根据上面的分析更新宏块的信息,在函数x264_analyse_update_cache中完成。
12.x264_macroblock_analyse函数-2

上图就展示了x264_macroblock_analyse函数中调用函数。
(1)x264_mb_analyse_init函数
x264_mb_analyse_init()函数的功能包括:初始化码率控制的模型参数(码率控制依然基于Lagrangian率失真优化算法,所以初始化lambda系数),把各宏块分类的Cost设为COST_MAX,计算MV范围,快速决定Intra宏块。
(2)x264_mb_analyse_intra 函数
这个函数进行帧内的模式选择,主要包括对16x16,4x4和8x8三种大小遍历所有模式并比较其cost
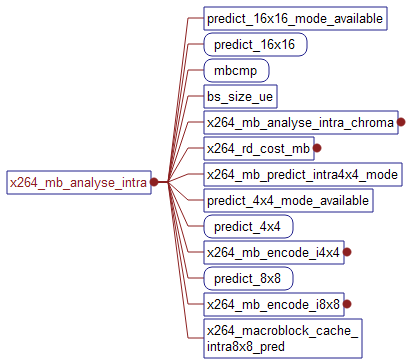
首先,对于16x16模式,调用函数predict_16x16_mode_available来判断V,H,DC和Plane四种模式中有哪些是可用的(因为对于不同位置的宏块,其左、上,左上和右上位置的宏块不一定都是存在的).结果保存在数组predict_mode中(记录了哪些模式可用),然后在for循环中对可行的模式进行预测计算,在循环中选出最好的一种模式。
A. h->predict_16x16 是函数指针数组,是通过x264_predict_16x16_init( h->param.cpu, h->predict_16x16 );来完成赋值的,具体代码在x264_encoder_open函数中。通过x264_predict_16x16_init的代码可以看到,h->predict_16x16 中就是Intra16x16所对应的4种预测方式(但是考虑到边界的情况,x264中是有7种方式),所以,代码:
h->predict_16x16 [i_mode ]( p_dst );
就完成了相应i_mode模式的预测计算,p_dst指向的就是相应的预测值。
B. h->pixf.mbcmp是函数指针数组,而这儿的h->pixf.mbcmp[PIXEL_16x16]就是该数组的第一个元素,可以发现这是一个函数,根据输入的参数可以计算得到一个值,经过查找,最终发现,mbcmp的值就是h->pixf中的的sad和satd中的一个,具体代码是在x264_encoder_open函数中:
memcpy( h-> pixf. mbcmp,( h-> mb. b_lossless || h->param .analyse .i_subpel_refine <= 1 ) ? h-> pixf. sad : h->pixf .satd , sizeof(h ->pixf. mbcmp) );
这样由p_src和p_dst就计算得到失真SAD或SATD。
C. 函数bs_size_ue用于对所采用的模式进行码率大小的估算,然后计算cost(仍然是基于Lagrange的):
i_sad = h ->pixf. mbcmp[PIXEL_16x16 ]( p_dst , FDEC_STRIDE , p_src,FENC_STRIDE ) + a-> i_lambda * bs_size_ue ( x264_mb_pred_mode16x16_fix[i_mode ] );
接下来,根据b_mbrd变量来采用不同的方式(这儿对b_mbrd并不理解其含义)。调用x264_mb_analyse_intra_chroma对色度进行模式选择。和亮度16x16类似,采用了predict_8x8chroma_mode_available函数来选取合适的模式,然后利用for循环选出cost最小的模式,操作方式和上面的分析都是类似的。之后,有可能要调用函数x264_rd_cost_mb,现在还没有弄明白这是为什么?!
对于Intra4x4,采用的是分成16个4x4块来处理的。所以整个过程式在for循环中的。
A. 为了减少编码时的比特数,x264先对所要采用的模式进行了一个预测,如果预测中的话就只需要一个比特,而预测不中的话就需要4个比特来保存所采用的模式。
从x264_mb_predict_intra4x4_mode函数代码可以看到,预测的方式就是根据左和上的宏块的预测模式中选择较小的那个模式。
B. 还是老方法,调用函数predict_4x4_mode_available来找出哪些模式是可行的,然后针对这些模式利用predict_4x4进行预测,再计算cost,从中选择最优模式。
C. 为了下一个4x4块编码使用,需要对当前4x4块进行编码(这儿我还不是很理解):
/* Luma prediction */
h-> predict_4x4[a ->i_predict4x4[ x][ y]]( p_dst_by );
/* encoding the current 4x4 Block, Update the reconstructed data(fdec). */
x264_mb_encode_i4x4( h , idx , a ->i_qp );
/* Cache the intra 4x4 prediction mode of current Block */
h->mb .cache .intra4x4_pred_mode [x264_scan8 [idx ]] = a->i_predict4x4 [x ][y ]; //Update the prediction mode for later use??.
D. 需要注意的是为了和Intra16x16进行比较,这儿所采用的cost计算方式:
a-> i_sad_i4x4 += a ->i_lambda * 24; /* from JVT (SATD0) */ //??
//非RDO率失真优化模式下,宏块总代价cost_intra4*4 = 16个 4*4 小块的最佳 cost 求和 + 4 * 6 * lambda_mode.
//此处由于还未进行4X4代价计算,只是预先增加4 * 6 * lambda_mode.
//当采用4X4分块时,由于每个4X4块的最优预测编码模式都需要进行编码传输,这样,相比较于16X16模式就多了传输比特数,
//为了合理公平比较,规定每个8*8块加一个6*lambda_mode,因此就等于是加了一个 4 * 6 * lambda_mode.
同样出现b_mbrd,以后弄懂了再讨论。
对于Intra8x8,采用的是分成4个8x8块来处理,仍然是在for循环中进行的。
A. 为了减少比特数,同样进行了模式预测,和Intra4x4时采用的是同样的函数,只是参数有些改变。
B. 调用函数predict_4x4_mode_available来找到可行的模式。
C. 和Intra4x4类似,也是对当前8x8块进行编码:
/* Luma prediction for each 8x8 Block. */
h-> predict_8x8[a ->i_predict8x8[ x][ y]]( p_dst_by, h ->mb. i_neighbour8[idx ] );
/* Calculate the reconstructed data,Store the prediction data in p_dec */
x264_mb_encode_i8x8( h , idx , a ->i_qp );
/* Cache the intra 8x8 prediction mode for each 8x8 Block */
x264_macroblock_cache_intra8x8_pred( h , 2*x , 2*y, a ->i_predict8x8[ x][ y] );
这样Intra16x16,Intra4x4和Intra8x8模式都选择完了,得到了三种情况下的cost,然后进行比较得到最优的划分方式:
i_cost = analysis .i_sad_i16x16 ; // SAD cost of i_16x16
h-> mb. i_type = I_16x16 ;
if( analysis.i_sad_i4x4 < i_cost )
{
i_cost = analysis .i_sad_i4x4 ;
h-> mb. i_type = I_4x4 ;
}
if( analysis.i_sad_i8x8 < i_cost )
h-> mb. i_type = I_8x8 ; // We Only remember the Macro-block type.
(3)x264_macroblock_probe_pskip和x264_macroblock_probe_bskip
这两个函数是判断是否要采用skip模式。虽然是分别针对p帧和B帧,但是两个函数最终都是调用的同一个函数x264_macroblock_probe_skip,只是调用的时候参数是不一样的。下面是x264_macroblock_probe_skip的调用方式:

这个函数主要原理就是对宏块进行预测,然后计算残差,然后对残差进行DCT变换,量化,然后利用x264_mb_decimate_score函数来为DCT系数打分,看是否可以将这些系数设置为0,这样就不用对这个宏块编码了,即skip模式,对于不同的块,有不同的阈值来限制。
(4)x264_mb_analyse_load_costs函数
关于这个函数,代码中给出的注释是:/* initialize an array of lambda*nbits for all possible mvs */
应该是对运动矢量所需要的cost进行提前计算,p_cost_mv[i]用于保存这些值。由于MVD的值可能为正也可为负,所以操作中对于正负MVD的运动矢量cost计算是一样的。操作的时候是先将p_cost_mv[i]的指针移动到数组中间的,然后从中间往两边赋值的。
网上有人指出,这个数组存在内存泄露的问题,确实我找了好多次都没有找到关于这个对这个数组释放内存的操作。
(5)x264_mb_analyse_inter_p16x16函数
这个函数实现的是16x16的运动搜索。
首先利用宏LOAD_FENC加载需要编码的宏块数据,然后是一个for循环,该循环是参考帧的循环,从最近的一个参考帧开始搜索,一直到最远的一个参考帧。在循环中,先利用宏LOAD_HPELS载入参考帧数据,然后调用x264_mb_predict_mv_16x16函数寻找运动矢量的预测值MVP,主要以上、右上、左块运动矢量的中值作为预测值,并存储在m.mvp中。然后调用x264_mb_predict_mv_ref16x16函数,来寻找候选运动矢量。这些候选者包括:空间相邻的左、左上、上、右上块的MV;第0个参考帧中的当前块、右边块、下边快运动矢量乘以时间差权重。接下来调用x264_me_search_ref进行运动搜索。搜索时先从所有候选运动矢量中选出最佳的起点,然后使用小钻石法、六边形法、UMH或者全搜索搜索出最佳的整像素位置。在x264_me_search_ref函数的最后,同时调用了函数refine_subpel了进行1/2和1/4运动搜索,并且都是使用小钻石法。在搜索出最佳运动矢量后,如果当前是最近一个参考帧,而且最佳SA(T)D小与检测门限,则尝试对其进行P_SKIP编码。最后调用函数x264_macroblock_cache_ref保存搜索结果。
(6)x264_mb_analyse_inter_p8x8和x264_mb_analyse_inter_p8x8_mixed_ref函数
这两个函数实现对8x8模式的运动搜索。这两个函数区别在于,函数x264_mb_analyse_inter_p8x8只使用在16x16运动搜索中用到的帧。候选MV的数目也是有限制的。而x264_mb_analyse_inter_p8x8_mixed_ref则没有限制,这些8x8块的参考帧可以是不同的帧。
(7)x264_mb_analyse_inter_p4x4函数
对8x8块内的4个4x4小块进行运动搜索的分析。和x264_mb_analyse_inter_p8x8是类似的。
(8)x264_mb_analyse_inter_p8x4和x264_mb_analyse_inter_p4x8函数
这两个函数是对8x8块的两个8x4或两个4x8进行运动搜索。和上面的都是类似的。
(9)x264_mb_cache_mv_p8x8函数
这个函数是为每个8x8块保存MV。
(10)x264_mb_analyse_inter_p16x8和x264_mb_analyse_inter_p8x16函数
这两个函数完成对16x16块中的两个16x8块或两个8x16块的搜索。
为了加快搜索的速度,x264对这两个函数所采用的参考帧进行了限制:Only search in the reference frame found in the inter_8x8 motion estimation. The mv candidates is also limited. 也就是只采用在x264_mb_analyse_inter_p8x8_mixed_ref中使用到的参考帧。
(11)x264_me_refine_qpel函数
这个函数是完成亚像素的运动搜索,其实在该函数中是调用了refine_subpel来具体实施的。
(12)x264_mb_predict_mv_direct16x16函数
判断是否可以使用Direct模式。
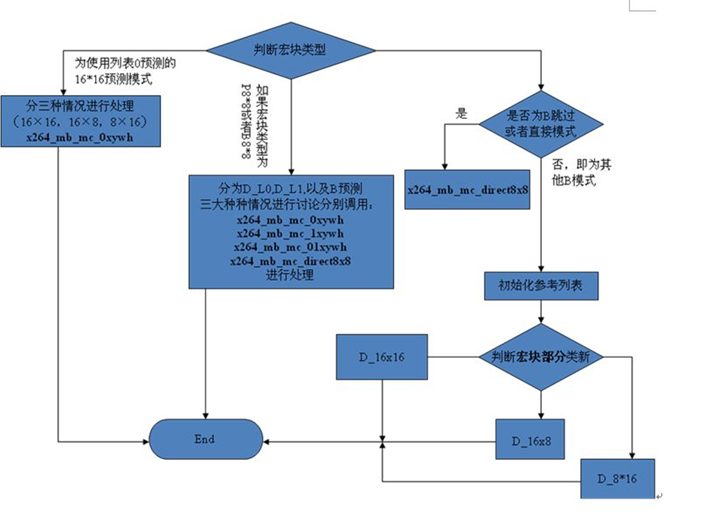
(13)x264_mb_mc 函数
这个函数是根据运动搜索完成之后的MV来进行宏块的运动补偿。
在这个函数中根据不同的宏块类型进行运动补偿,下面是该函数调用的函数:
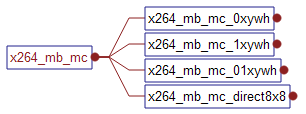
该函数在运动补偿时是和采用的参考序列式相关的。下面是一个流程图:
(14)x264_mb_analyse_inter_b16x16 函数
这对16x16进行运动搜索,由于是针对B帧的,所以涉及到了采用L0和L1参考帧列表的情况。
(15)x264_mb_analyse_inter_b8x8函数
这是B帧对应的8x8运动搜索,还是宏块分为4个8x8块进行。
(16)x264_mb_analyse_inter_b16x8和x264_mb_analyse_inter_b8x16函数
B帧对应的16x8和8x16搜索,将宏块分成两个16x8或两个8x16.
13. x264_mb_analyse_inter_p16x16函数

(1)x264_mb_predict_mv_16x16
这个函数是对宏块的运动矢量进行预测,从而得到MVP。在进行MVP计算中采用的是左A,上B,右上C和左上D四个宏块的运动矢量。
在函数中要判断一下C是否存在的,如果C存在,则是优先使用C的MV,如果C不存在,那么就用D来代替C。
然后统计当前宏块所参考的参考帧序号与邻块ABC或ABD所参考的参考帧序号相同数 。如果与ABC或ABD中的两个或两个以上宏块的参考帧相同,那么直接调用x264_median_mv来取这三个邻块的运动矢量的中值作为预测运动矢量。如果只有一个相同时,预测运动矢量设置为该邻块的运动矢量。
(2)x264_mb_predict_mv_ref16x16
在代码中给出了注释,指出这个函数并不是标准要求的,而是x264为了提高编码器系能而自己添加的。因为标准中并没有要求在运动估计之前给出候选MV,而是只要求找到最优MV即可。x264为了加快MV的搜索,采用了候选MV的方式来预测搜索起点。
(3)x264_me_search_ref
这个函数就是具体进行运动搜索。搜索时从候选运动矢量中选取起点,然后根据设定进行运动搜索。最后调用了refine_subpel进行亚像素运动搜索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号