

从底层汇编理解 c++ 引用实现机制 (转+增加)
参考:http://blog.csdn.net/wanwenweifly4/article/details/6739687
红色是我添加的,其他地方是原作者的。
主要是看了上面的这篇“从底层汇编理解 c++ 引用实现机制“的文章之后,觉得不错。就转了过来,同时,对文中的程序都在自己的机器上验证了一下。
使用的G++版本:g++ (GCC) 4.5.1 20100924
如果要查看汇编后代码与源码的关系,我用的方法是:
先用g++生成带有调试信息的目标文件:g++ -g -c ref.cc
然后再利用objdump命令查看目标文件ref.o:objdump -S ref.o
引用类型到底是什么?它和指针有什么关系?它本身占用内存空间吗? 带着这些疑问,我们来进行分析。 先看代码:
| int main() { int x=1; int &b=x; return 0; } |
通过汇编查看代码如下:
|
| 00000000 <main>: int main() { 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 83 ec 10 sub $0x10,%esp int x=1; 6: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%ebp) int &b=x; d: 8d 45 f8 lea -0x8(%ebp),%eax 10: 89 45 fc mov %eax,-0x4(%ebp) return 0; 13: b8 00 00 00 00 mov $0x0,%eax } 18: c9 leave 19: c3 ret |
可以知道x的地址为ebp-4,b的地址为ebp-8,因为栈内的变量内存是从高往低进行分配的。所以b的地址比x的低。
lea eax,[ebp-4] 这条语句将x的地址ebp-4放入eax寄存器
mov dword ptr [ebp-8],eax 这条语句将eax的值放入b的地址ebp-8中
上面两条汇编的作用即:将x的地址存入变量b中,这不和将某个变量的地址存入指针变量是一样的吗?
所以从汇编层次来看,的确引用是通过指针来实现的。
下面我们通过程序来验证,我们知道,在程序一层我们只要直接涉及到引用变量的操作,我们操作的总是被引用变量,即编译器帮我们做了些手脚,总是在引用前面加上*。所以我们要读取真正的“引用变量的值”,必须采取一定的策略,好吧,我们就按照变量在栈中分布的特点来绕过编译器的这个特点。
| [cpp] view plaincopyprint?
输出结果为:&x=12ff7c,&y=12ff78,&b=12ff74,b=12ff7c | #include <cstdio>
int main() { int x=1; int y=2; int &b=x; printf("&x=%x,&y=%x,&b=%x,b=%x\n",&x,&y,&y-1,*(&y-1)); return 0; } 输出结果是: &x=bfe1b308,&y=bfe1b304,&b=bfe1b300,b=8048460
这个地方的结果和作者不一样,可以看后面的解释。 |
|
输出结果为:&x=12ff7c,&b=12ff7c. | #include <cstdio>
int main() { int x=1; int &b=x; printf("&x=%x,&b=%x\n",&x,&b); return 0; } 输出结果:&x=bfe74aa8,&b=bfe74aa8 |
b的地址我们没法通过&b获得,因为编译器会将&b解释为:&(*b) =&x ,所以&b将得到&x。也验证了对所有的b的操作,和对x的操作等同。
但是我们可以间接通过&y-1来得到b的地址,从而得到b的值:*(&y-1) 从结果可以知道,b的值即x的地址,从而可以知道,从地层实现来看,引用变量的确存放的是被引用对象的地址,只不过,对于高级程序员来说是透明的,编译器 屏蔽了引用和指针的差别。
下面是程序的变量在内存栈中的分布,引用变量一样也占用内存空间,而且应该是4个字节的空间。
虽然从底层来说,引用的实质是指针,但是从高层语言级别来看,我们不能说引用就是指针,他们是两个完全不同的概念。有人说引用是受限的指针,这种说法我不赞同,因为从语言级别上,指针和引用没有关系,引用就是另一个变量的别名。对引用的任何操作等价于对被引用变量的操作。从语言级别上,我们就不要去考虑它的底层实现机制啦,因为这些对你是透明的。所以在面试的时候,如果面试的人问到这个问题,可以先从语言级别上谈谈引用,深入的话就从底层的实现机制进行分析。而不能什么条件没有就说:引用就是指针,没有差别,......之类的回答
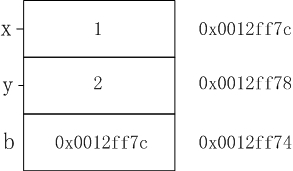
对于下面的程序:
#include <cstdio>
int main()
{
int x=1;
int y=2;
int &b=x;
printf("&x=%x,&y=%x,&b=%x,b=%x\n",&x,&y,&y-1,*(&y-1));
return 0;
}
我的结果是&x=bfe1b308,&y=bfe1b304,&b=bfe1b300,b=8048460
与原作者的不同,然后我就将上面的程序进行编译得到下面的结果:
| 00000000 <main>: #include <cstdio>
int main() { 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 83 e4 f0 and $0xfffffff0,%esp 6: 83 ec 30 sub $0x30,%esp int x=1; 9: c7 44 24 28 01 00 00 movl $0x1,0x28(%esp) 将1赋值给x(x在堆栈的0x28处) 10: 00 int y=2; 11: c7 44 24 24 02 00 00 movl $0x2,0x24(%esp) 将2赋值给y(y在堆栈的0x24处) 18: 00 int &b=x; 19: 8d 44 24 28 lea 0x28(%esp),%eax 将x的地址0x28 传给寄存器%eax 1d: 89 44 24 2c mov %eax,0x2c(%esp) 将%eax的值赋给堆栈0x2c处(这儿比较重要) printf("&x=%x,&y=%x,&b=%x,b=%x\n",&x,&y,&y-1,*(&y-1)); 21: 8d 44 24 24 lea 0x24(%esp),%eax 将堆栈0x24处的地址传给寄存器%eax 25: 83 e8 04 sub $0x4,%eax 将%eax的值减掉4 28: 8b 10 mov (%eax),%edx 将寄存器%eax中地址所指向的内容传给寄存器%edx 2a: 8d 44 24 24 lea 0x24(%esp),%eax 将堆栈0x24处的地址传给寄存器%eax 2e: 83 e8 04 sub $0x4,%eax 将%eax的值减掉4 31: 89 54 24 10 mov %edx,0x10(%esp) 将%edx的内容传给堆栈0x10处 35: 89 44 24 0c mov %eax,0xc(%esp) 将%eax的内容传给堆栈0xc处 39: 8d 44 24 24 lea 0x24(%esp),%eax 将堆栈0x24处的地址传给寄存器%eax 3d: 89 44 24 08 mov %eax,0x8(%esp) 将%eax的内容传给堆栈0x8处 41: 8d 44 24 28 lea 0x28(%esp),%eax 将堆栈0x28处的地址传给寄存器%eax 45: 89 44 24 04 mov %eax,0x4(%esp) 将%eax的内容传给堆栈0x4处 49: c7 04 24 00 00 00 00 movl $0x0,(%esp) 50: e8 fc ff ff ff call 51 <main+0x51> return 0; 55: b8 00 00 00 00 mov $0x0,%eax } 5a: c9 leave 5b: c3 ret |
上面基本每一句中都进行解释。
从这儿可以看到我的机器上生成的汇编代码是将x的地址赋给了堆栈中地址所在处的下一个地址单元。
从printf所生成的汇编代码处我们也可以看到,是按照逆序来计算的(&*(&y-1), &y-1, &y, x)这也印证了C标准中提到的函数的参数是逆序入栈的。
为了验证上面的想法,将原程序中的*(&y-1)改为*(&x+1)
结果为:
&x=bf9a74c8,&y=bf9a74c4,&b=bf9a74cc,b=bf9a74c8
这样就和作者的符合起来了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号