
MNIST识别
mnist数据集:
train-images-idx3-ubyte.gz:训练集图像(9912422 bytes)
train-lables-idx1-ubyte.gz:训练集标签(28881 bytes)
t10k-images-idx3-ubyte.gz:测试集图像(1648877 bytes)
t10k-lables-idx1-ubyte.gz:测试集标签(4542 bytes)
idx3的数字表示数据维度。也就是3维,标签1维
图像的3个维度分别是:训练集图像28pix*28pix*60000张 测试集28pix*28pix*10000张
图片以字节的形式进行存储,把文件读到NumPy array中,以训练和测试算法。
1 def load_mnist(path,kind='train'): 2 labels_path=os.path.join(path, 3 '%s-labels.idx1-ubyte' 4 % kind) 5 ''' 6 path:读取文件路径 7 ‘%s-lable.idx1-ubyte’:拼接文件的后半部分 8 %kind 拼接文件类别 9 完整的数据名称:t10k-lables.idx3-utype,t10k=kind 10 ''' 11 images_path=os.path.join(path, 12 '%s-images.idx3-ubyte' 13 % kind) 14 with open(labels_path,'rb')as lbpath: 15 magic,n=struct.unpack('>II',lbpath.read(8)) 16 lables=np.fromfile(lbpath, 17 dtype=np.uint8) 18 19 with open(images_path,'rb')as imgpath:
20 magic,num,rows,cols=struct.unpack('>IIII', 21 imgpath.read(16)) 22 images=np.fromfile(imgpath, 23 dtype=np.uint8).reshape(len(lables),784) 24 return images,lables
25 x_train,y_train=load_mnist('C:\\Users\\lenovo\\Desktop\\mnist',kind='train') 26 print('Rows:%d,columns:%d'%(x_train.shape[0],x_train.shape[1])) 27 x_test,y_test=load_mnist('C:\\Users\\lenovo\\Desktop\\mnist',kind='t10k') 28 print('Rows:%d,columns:%d'%(x_test.shape[0],x_test.shape[1]))
▶load_mnist函数返回两个数组,第一个是n x m维的Numpy array(images),这里的n是指样本数(行数),m是特征数(列数)。训练数据集包含60,000个样本,测试数据集包含10,000样本。在MNIST数据集中的每张图片由28x28个像素点构成,每个像素点用一个灰度值表示。在这里,我们将以28x28的像素展开一个一维的行向量,这些行向量就是图片数组里的行(每行784个值,或者说每行就是代表了一张图片)。load_mnist函数返回的第二个数组(lables)包含了相应的目标变量,也就是手写数字的类标签(整数0-9)
▶os.path.join():
path:读取文件路径
‘%s-la ble.idx1-ubyte’:拼接文件后半部分
%kind 拼接文件类别
完整的数据名称:t10k-lables.idx3-utype,t10k=kind
▶img.shape[0]、[1]、[2]
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
在矩阵中,[0]表示行数、[1]表示列数
▶numpy.fromfile(file,dtype=float,count=-1,sep='')
根据文本或二进制文件中的数据构造数组。
一种使用已知数据类型读取二进制数据的高效方法,以及解析简单格式化的文本文件。使用tofile方法写入数据,可以使用此函数读取。
参数: file:file或str 打开文件对象或文件名。
dtype:数据类型 返回数组的数据类型。对于二进制文件,它用于确定文件中项目的大小和字节顺序。
count:int 要读取的项目数。-1表示所有项目(即完整文件)。
sep:str 如果文件是文本文件,则项目之间的分隔符。空(‘’’)分隔符表示该文件应被视为二进制文件。分隔符中的空格(‘’’)匹配零个或者多个空白字符。仅由空格组成的分隔符必须至少匹配一个空格。
numpy.fromfile()函数读回数据时需要用户指定元素类型,并对数组的形状进行适当的修改。
b=numpy.fromfile("filename.bin",dtype=**)
读出来的是一维数组,需要利用 b.shape=3,4重新指定维数。
▶读取图片:
magic, n = struct.unpack('>II', lbpath.read(8)) labels = np.fromfile(lbpath, dtype=np.uint8)
为了更好的理解代码,MNSIT网站对数据集的介绍:
TRAINING SET LABEL FILE (train-labels-idx1-ubyte): [offset] [type] [value] [description] 0000 32 bit integer 0x00000801(2049) magic number (MSB first) 0004 32 bit integer 60000 number of items 0008 unsigned byte ?? label 0009 unsigned byte ?? label ........ xxxx unsigned byte ?? label The labels values are 0 to 9.
通过使用上面两行代码,我们首先读入magic number,它是一个文件协议的描述,也是我们调用fromfile方法将字节读入Numpy array之前在文件缓冲中的item数(n)。作为参数值传入。
struct.unpack的> 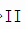 有两个部分:
有两个部分:
- >:这是指大端(用来定义字节是如何存储的);
< : Little-Endian就是低位字节排放在内存的低地址端(栈顶),高位字节排放在内存的高地址端(栈底)
>:Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
!: 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
![]() 这是指一个无符号整数。
这是指一个无符号整数。
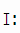 这是指一个无符号整数。
这是指一个无符号整数。unpack(fmt,string) 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple
demo中unpack('>II', lbpath.read(8)) 以大端的无符号整数读取label path的8个字节
▶.read()每次读取整个文件,它通常将读取到底文件内容放到一个字符串变量中,也就是说.read()生成文件内容是一个字符串类型。
.readline()每次只读取文件的一行,通常也是读取到的一行内容放到一个字符串变量中,返回 str
.readlines()每次按行读取整个文件内容,将读取到的内容放到一个列表中,返回list类型。
通过执行下面的代码,我们将会从刚刚解压MNIST数据集后的mnist目录下加载60,000个训练样本和10,000个测试样本。
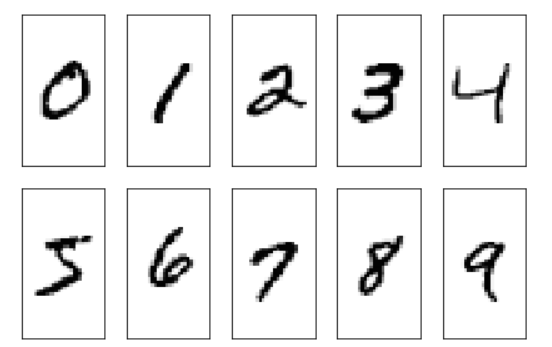
为了了解MNIST中的图片看起来到底是个啥,让我们来对它们进行可视化处理,从feature matrix中将784-像素值的向量reshape为之前的28*28的形状,然后通过matplotlib的imshow函数进行绘制:
1 import matplotlib.pyplot as plt 2 3 fig,ax=plt.subplots( 4 nrows=2, 5 ncols=5, 6 sharex=True, 7 sharey=True,) 8 9 ax=ax.flatten() 10 for i in range(10): 11 img=x_train[y_train==i][0].reshape(28,28) 12 ax[i].imshow(img,cmap='Greys',interpolation='nearest') 13 14 ax[0].set_xticks([]) 15 ax[0].set_yticks([]) 16 plt.tight_layout() 17 plt.show()
▶subplot()参数
nrows,ncols:整形,可选参数,默认为1.表示子图网格(grid)的行数与列数。
sharex,sharey:布尔值或者{‘none’,'all','row','col'},默认False
控制x(sharex)或y(sharey)轴之间的属性共享:
- True或者all:x或y轴属性将在所有子图中共享。
- False或none:每个子图的x或y轴都是独立部分。
- row:每个子图在一个x或y轴共享行(row)
- col:每个子图在一个x或y轴共享列(column)
当子图在x轴有一个共享列时,只有底部子图的x tick标记是可视的
同理,当子图在y轴有一个共享行时,只有第一列子图y tick标记是可视的
subplot_kw:字典类型,可选参数。把字典的关键字传递给add_subplot()来创建每个子图。
gridspec_kw:字典类型,可选参数。把字典的关键字传递给GridSpec构造函数创建子图放在网格里(grid)
**fig_kw:把所有详细的关键字参数传给figure()函数
返回结果:
fig:matplotlib.figure.Figure对象
ax:Axes(轴)对象或Axes(轴)对象数组。
▶ax.flatten(),返回一个折叠成一维的数组,默认按横的方向降。但只能适用于numpy对象,即array或mat。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号