Python多线程爬虫
什么是多任务
两种表现形式:并发和并行
并发:
并发指在一段时间交替地去执行多个任务。
并发一般发生在任务数量大于CPU核心数的时候。
并行
并行指在一段时间内真正的同时去执行多个任务。
如何实现多任务
使用多进程和多线程来完成
进程
进程是系统中正在运行的一个程序,程序一旦运行就是进程。
进程可以看成程序执行的一个实例。进程是系统资源分配的独立实体,每个进程都拥有独立的地址空间。一个进程无法访问另一个进程的变量和数据结构,如果想让一个进程访问另一个进程的资源,需要使用进程间通信,比如管道,文件,套接字等。
线程
是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
进程和线程的关系
一个进程可以拥有多个线程,每个线程使用其所属进程的栈空间。线程与进程的一个主要区别是,统一进程内的一个主要区别是,同一进程内的多个线程会共享部分状态,多个线程可以读写同一块内存(一个进程无法直接访问另一进程的内存)。同时,每个线程还拥有自己的寄存器和栈,其他线程可以读写这些栈内存。
线程是进程的一个实体,是进程的一条执行路径。
线程是进程的一个特定执行路径。当一个线程修改了进程的资源,它的兄弟线程可以立即看到这种变化。
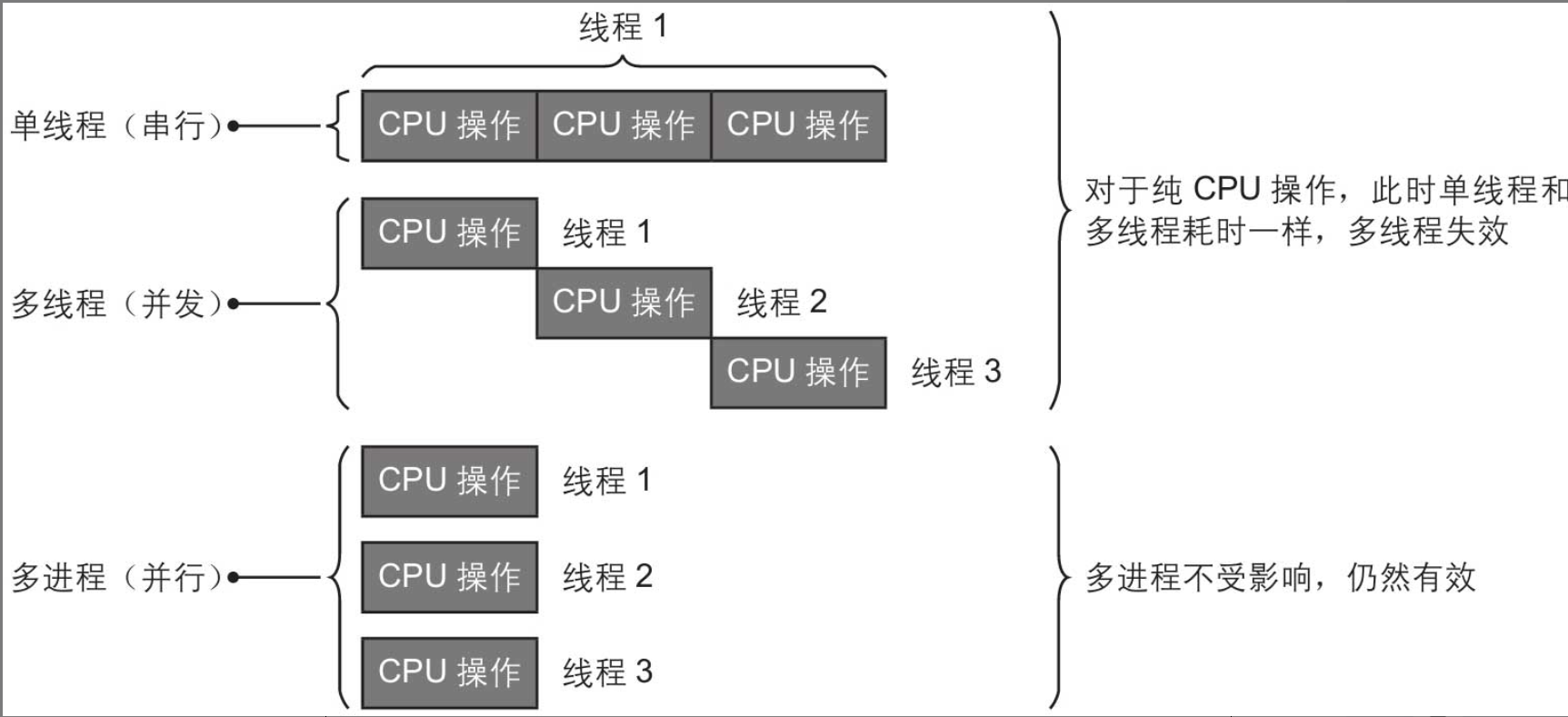
单线程,多线程,多进程
1. 单线程
单线程又称为串行操作。如上图所示,对于常规单线程操作而言,必须等待上一个程序执行完毕后才能执行下一个程序。在Python中,程序默认都是以单线程的方式执行。
2. 多线程
多线程又称为并发操作,指在一个时间段里执行多个任务,通常针对单核CPU而言。虽说单核CPU在一个时间点上只能执行一个任务,但是如果执行任务的过程中有不需要用到CPU的环节,如上图中的IO操作是用不到CPU的,那么就可以在线程1不再使用CPU时执行线程2,从而提高工作效率。
3. 多进程
多进程又称为并行操作,指在同一时刻可以执行多个任务,通常针对多核CPU而言。因为一个CPU同一时刻只能执行一个任务,所以真正的多进程往往对应多核CPU。通过多进程可以同时执行多个任务,从而提高工作效率。
什么是CPU操作和IO操作
计算机任务可以分为CPU计算密集型操作和IO(Input/Output)密集型操作。
CPU计算密集型操作(简称CPU操作)是指需要进行大量计算和逻辑判断的任务,如计算从1到1亿的累加和、机器学习、视频解码、图片处理等。这种任务主要依靠CPU的运算能力来完成。
IO密集型操作(简称IO操作)主要是指数据的输入与输出任务,如读写文件、网络数据交换、向硬盘读写数据等。这种任务除了涉及与硬盘的数据交换,还涉及与网络的数据交换。例如,在爬取网页时,首先需要发送数据(output),告诉网站服务器想要某网页的源代码,随后服务器把网页源代码发回来,这就是从网络接收数据(input)。在IO操作中,CPU参与较少,使用多进程和多线程都能提高效率。
如果是纯CPU操作(如数字加减乘除、机器学习中的模型训练),因为一个CPU同一时间只能执行一个CPU操作,那么对于下图中的线程1、2、3而言,多线程是失效的,而多进程仍然有效。
爬虫任务中的CPU操作:启动爬虫,解析网页源代码(时间短)
爬虫任务中的IO操作:请求网址,等待响应,接收网页源代码(时间长)
举例说明
在饭店吃饭,有服务员上菜,吃饭的过程属于CPU操作,等待上菜的过程(类似于等待网络响应)则属于非CPU操作。
单线程意味着必须吃完一份菜才等待上菜,假设吃完一份菜耗时20分钟,而等待一份菜耗时10分钟,那么吃完3份菜共耗时90分钟。
多线程意味着可以边吃边等待下一份菜,虽然并不能同时吃两份菜,但是因为可以在吃菜的过程中等菜,所以吃完3份菜共耗时60分钟,比单线程还是节省了不少时间。
多进程则是多人同时吃多份菜。假设一次性把3份菜上齐,那么3个人吃完3份菜耗时20分钟。当然,计算机中的实际执行过程要复杂一些。
应用(贴代码)
多线程
线程库:import threading
创建线程:t1=threading.Thread(target=test1,args=(a,)) #创建线程t1,test1是函数名,a是函数test1的参数
如果函数没有参数,就不用写args了
需要注意的是,args的值应为一个元组。如果只传入一个参数,那么一定要在该参数后加一个逗号,如args=(参数1, ),否则就不是一个元组。如果是传入多个参数,就不用考虑该问题,如写成args=(参数1, 参数2)即可。
启动线程:t1.start() #线程1启动
挂起线程:t1.join() #等待线程t1结束后再执行主线程
必须先执行ti.start()才能再执行t1.join()
点击查看代码
import threading
import requests
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.36'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word='+company
res = requests.get(url, headers=headers).text
# 对数据进行清洗和提取
# 提取网址和来源
p_href = '<h3 class="news-title_1YtI1"><a href="(.*?)"'
href = re.findall(p_href, res, re.S)
p_title = '<h3 class="news-title_1YtI1">.*?>(.*?)</a>'
title = re.findall(p_title, res, re.S)
# 提取日期和来源
p_date = '<span class="c-color-gray2 c-font-normal" aria-label=".*">(.*?)</span>'
date = re.findall(p_date, res)
p_source = '<span class="c-color-gray c-font-normal c-gap-right" aria-label=".*">(.*?)</span>'
source = re.findall(p_source, res)
# 数据清洗
for i in range(len(title)):
title[i] = re.sub('<.*?>', '', title[i])
print(str(i+1)+'.'+title[i]+'('+source[i]+' '+date[i]+')')
print(href[i])
# 多线程
companies=['阿里巴巴','华能信托','京东','腾讯']
start_time=time.time()
thread_list=[] #创建一个空列表,用来存储每一个线程
for i in range(len(companies)):
t=threading.Thread(target=baidu,args=(companies[i],))
thread_list.append(t)
for i in thread_list:
i.start()
for i in thread_list:
i.join()
end_time=time.time()
total_time=end_time-start_time
print('所有任务结束,总耗时为:'+str(total_time))
进阶知识:利用队列进行多线程爬虫
我们希望创建固定数量的线程,如5~10个线程,然后把多个网址分配给各个线程去爬取。要实现这样的操作,肯定需要有一个容器存放这些网址,而且还要能无放回地取出这些网址,也就是取出一个网址后容器里就少一个网址,这样不会重复爬取同一个网址。
点击查看代码
# 这里使用了队列
import time
import re
import requests
import queue
import threading
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.36'}
companies = ['阿里巴巴', '华能信托', '京东', '腾讯']
url_queue = queue.Queue()
for company in companies:
url_i = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word='+company
url_queue.put(url_i)
def crawl():
while not url_queue.empty():
url = url_queue.get()
res = requests.get(url, headers=headers, timeout=10).text
# 对数据进行清洗和提取
# 提取网址和来源
p_href = '<h3 class="news-title_1YtI1"><a href="(.*?)"'
href = re.findall(p_href, res, re.S)
p_title = '<h3 class="news-title_1YtI1">.*?>(.*?)</a>'
title = re.findall(p_title, res, re.S)
# 提取日期和来源
p_date = '<span class="c-color-gray2 c-font-normal" aria-label=".*">(.*?)</span>'
date = re.findall(p_date, res)
p_source = '<span class="c-color-gray c-font-normal c-gap-right" aria-label=".*">(.*?)</span>'
source = re.findall(p_source, res)
# 数据清洗
for i in range(len(title)):
title[i] = re.sub('<.*?>', '', title[i])
print(str(i+1)+'.'+title[i]+'('+source[i]+' '+date[i]+')')
print(href[i])
start_time = time.time()
thread_list = []
for i in range(5): # 激活5个线程
thread_list.append(threading.Thread(target=crawl))
for i in thread_list:
i.start()
for i in thread_list:
i.join()
end_time = time.time()
total_time = end_time-start_time
print('所有任务结束,总耗时为'+str(total_time))
多进程
导入进程库 import multiprocessing
查看CPU核心数 print(multiprocessing.cpu_count()) #一般启用的进程数量不要超过核心数
创建线程 t1=multiprocessing.Process(target=test1) #创建进程1
如果需要带参数,和上面的多线程操作一样
启动进程 t1.start()
加入进程 t1.join()
if__name__=='main'在多进程中的作用:
一个Python代码文件有两种使用方法:一种是直接执行;另一种是通过import语句导入到其他Python代码文件中执行,例如,import requests,其实调用的就是Python代码文件“requests.py”。
if__name__ == 'main':”的作用就是控制在这两种情况下执行代码的过程。在这行代码下的代码只有在第一种情况下才会被执行,在第二种情况下则不会被执行
这是因为每个Python代码文件其实都有一个内置名字__main__,而__name__是每个Python代码文件的内置属性。感兴趣的读者可以在代码文件中输入print(name)后运行,会发现打印结果就是__main__。
为什么在多进程时要写这行代码呢?
这是因为使用多进程时,主模块(主进程)会被import到各子进程中,所以对创建子进程的代码段必须使用“if name == 'main:”进行保护,否则会产生runtime error,或者导致递归创建子进程。
总结:运行多进程任务时一定要加上“if__name__ == 'main':”这行代码,并且需要在“.py”文件中运行(PyCharm或Spyder都可以),尽量不要在Jupyter Notebook中运行。
点击查看代码
import multiprocessing
import time
def test1():
result = 0
for i in range(20000000):
result += i
print(result)
def test2():
result = 0
for i in range(20000000):
result += i
print(result)
if __name__ == '__main__':
start_time = time.time()
t1 = multiprocessing.Process(target=test1)
t2 = multiprocessing.Process(target=test2)
t1.start()
t2.start()
t1.join()
t1.join()
end_time = time.time()
total_time = end_time-start_time
print('所有任务结束,总耗时为:'+str(total_time))
进阶知识:进程池
初始化进程池:pool=multiprocessing.Pool(process=N) #process用于设置进程池的最大进程数
将函数传递给进程:pool.map(test,num) #传入两个参数:函数名和函数的参数列表
点击查看代码
import multiprocessing
import requests
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.36'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word='+company
res = requests.get(url, headers=headers).text
# 对数据进行清洗和提取
# 提取网址和来源
p_href = '<h3 class="news-title_1YtI1"><a href="(.*?)"'
href = re.findall(p_href, res, re.S)
p_title = '<h3 class="news-title_1YtI1">.*?>(.*?)</a>'
title = re.findall(p_title, res, re.S) # 提取日期和来源
p_date = '<span class="c-color-gray2 c-font-normal" aria-label=".*">(.*?)</span>'
date = re.findall(p_date, res)
p_source = '<span class="c-color-gray c-font-normal c-gap-right" aria-label=".*">(.*?)</span>'
source = re.findall(p_source, res)
# 数据清洗
for i in range(len(title)):
title[i] = re.sub('<.*?>', '', title[i])
print(str(i+1)+'.'+title[i]+'('+source[i]+' '+date[i]+')')
print(href[i])
if __name__ == "__main__":
start_time = time.time()
pool = multiprocessing.Pool(processes=6)
companies = ['阿里巴巴', '华能信托', '京东', '腾讯']
pool.map(baidu, companies)
end_time = time.time()
total_time = end_time-start_time
print('所有任务结束,总耗时为:'+str(total_time))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号