

大模型评测探索
大模型评测探索
一、简介:大模型评测方法对比,对比传统的机器学习、深度学习与大模型测试过程,分析大模型评测体系。

二、以前的评价(机器学习、深度学习)
评价分散:以前标准能力评价往往较为零散,每个能力有各自的评价,局限在下游任务,比如图像识别:准确率、精准率、召回率,文本分类:Micro,推荐系统:RMSE、精确率等。
评价较为简单:通过广泛的自动评价方法就能有效的评测出模型效果,而且存在以下优点: 效率与一致性:自动评价指标通常可以快速计算出来,并且每次评价时都能保持一致,不受情绪和疲劳的影响。 可重复性:因为评价是自动化的,其他类似能力可以重复测试验证模型效果。
三、现在的评价(大模型)
综合能力:大模型将百种能力集一身,评测需要对大模型的综合能力进行测试。
数据集:例如LLM大模型的综合评价也是将过去的NLP领域单一任务的基准人工合成大的测试集,像我们分享的superCLUE、HELM、MMLU数据集,数据更加多样化。
四、以LLM大模型评测为例子,梳理模型评估体系图

大模型的评测应该从以上3个方向考虑,在测试任务领域上选择合适的任务、测试数据要全面(权威数据集、业务数据集)、测试手段要相应设置,避免资源浪费。
五:未来大模型项目应用测试需要关注的点
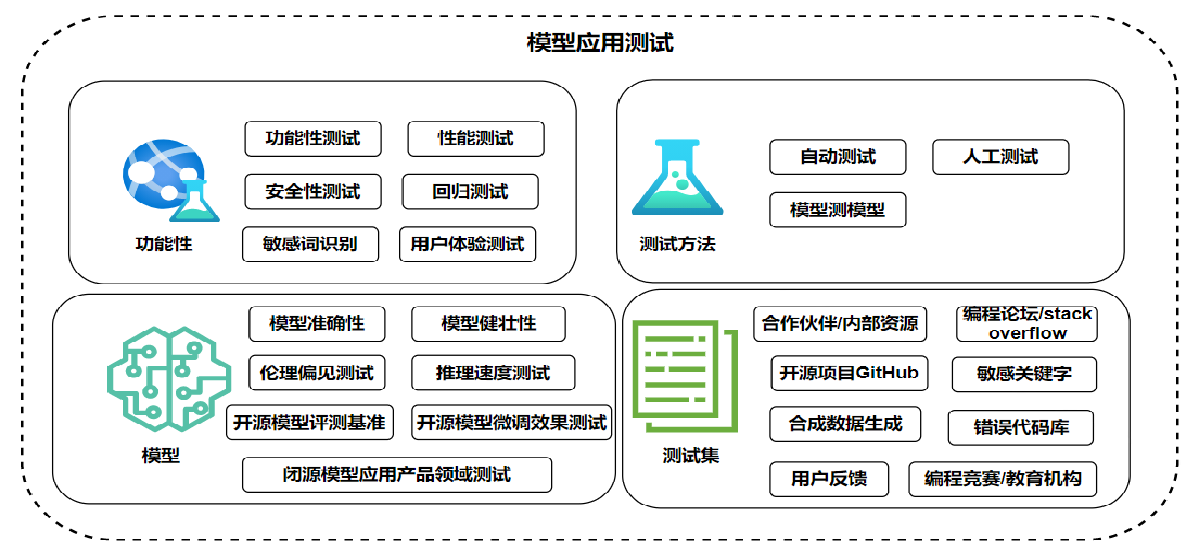
六、感兴趣的可以留言,一起探索大模型应用测试的项目实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号