Spring AI 从入门到精通:Java开发者的AI原生应用
Spring AI 从入门到精通:Java开发者的AI原生应用
1. AI相关概念
1.1 Model(模型)
人工智能模型(AI Model)是一种用于处理和生成信息的算法,是一套实现某个功能算法的合计, 它通常模仿人类的认知功能来工作。通过从大量数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出.
一句话:模型是通过大量数据训练得到的算法集合,能够解决特定类型任务。可以将其理解为“经验丰富的专家”——它在特定领域经过大量“学习”,能够根据输入给出专业的输出。
例如:
- 你通过大量动物图片,训练一个 AI 去判断图片里是什么动物 → 这个 AI 算一个“动物模型”
- 你通过大量股市行情走势数据, 训练 AI 预测股价 → 又是一个模型
从技术角度看,模型本质上是一套通过海量数据训练得到的数学参数集合。这些参数编码了数据中的模式和规律,使得模型能够对新的输入进行推理和预测。
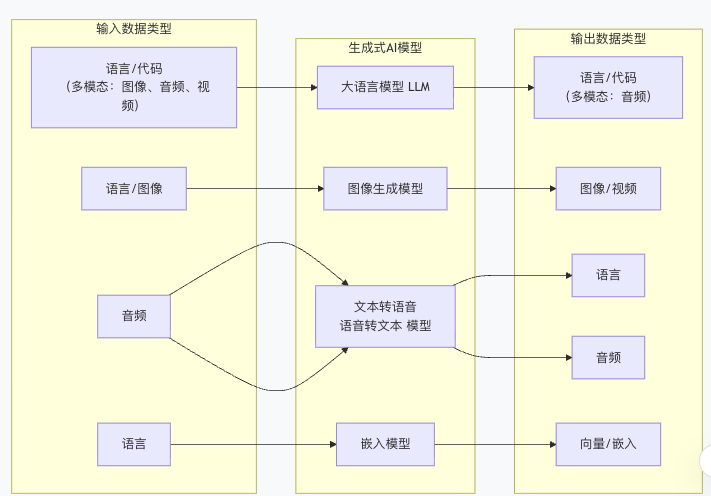
常见的模型的分类如下图
什么是“大模型”(LLM)
大模型(Large Model / Large Language Model)= 又大又聪明的模型。
参数越多 → 记忆能力越强 → 理解能力越好。
例如:
| 模型 | 参数规模 |
|---|---|
| 小模型 | 百万级 |
| 普通模型 | 千万级 |
| 大模型(GPT-3) | 1750亿 |
| 超大模型(GPT-4/5) | 万亿级 |
你不需要为每个任务训练一个模型,而是 一个模型能干很多事。
什么是“嵌入式模型”(Embedding Model)
嵌入式模型(Embedding Model) 的核心功能是将非结构化数据(如文本、图像)转换为高维向量。这个过程可以理解为:将人类可理解的信息映射到计算机可处理的数学空间中,同时保留语义信息。
这个模型经过海量数据训练,学会了如何捕捉语义信息。例如,它知道:
- “猫”和“狗”在向量空间里的位置比较接近(都是宠物)。
- “国王”和“男人”的关系,类似于“女王”和“女人”的关系。
- “苹果”这个词,在讨论水果时和讨论科技公司(Apple)时,其向量是不同的。
向量 - 含义的“数字坐标”
向量就是一串数字,例如 [0.023, -0.452, 0.123, ..., 0.843]。这可以看作是多维空间中的一个点的坐标。这个点表达的是该段信息的含义的具体表现, 因为计算机不擅长直接理解“意思”,但非常擅长计算数字之间的距离。我们可以用数学方法(如余弦相似度、欧氏距离)来计算两个向量有多“接近”,从而判断它们代表的含义有多相似。所以我们将每条信息都计算一个坐标.
例如:
| 文本 | 计算出的向量 |
|---|---|
| “宝马车多少钱” | [0,1,1] |
| “我想开宝马” | [1,2,1] |
| “猫能吃草吗?” | [-10,58,29] |
由向量坐标可见, “宝马车多少钱” 和 “我想开宝马” 的相关性更高.
它能做什么?
现在有一个传统图书馆管理系统. 系统里面存有成千上万本书,比如小说、菜谱、科学论文。你想找一本书,但你不记得名字了。你只知道书中内容描述:“关于一个年轻人去魔法学校上学的冒险故事”
在传统图书馆(传统数据库例如mysql)里,图书管理员只会根据精确的关键词(比如“哈利·波特”)去卡片目录或电脑系统里搜索。如果你没说对书名,他就帮不了你。
但现在. 你将图书管理系统中的每一本书中的内容,名称等等信息, 转化成大量的向量数据, 并存入向量数据库中, 相当于你的图书管理系统,熟读你的每一本书,并了解每本书的内容, 此时,当你问出“关于一个年轻人去魔法学校上学的冒险故事”时. 先算出此问题的含义坐标,再去系统中寻找与此描述最接近的坐标即可
1.2 Prompt(提示)
提示(Prompt)是引导人工智能模型产生特定输出的语言输入的基础, 也就是输入部分。对于日常使用ChatGPT 的人来说,提示可能只是在对话框中输入并发送到 API 的文本。然而,它包含的内容远不止这些。在许多人工智能模型中,提示文本不仅仅是一个简单的字符串。
编写高效的提示既是一门艺术,也是一门科学。ChatGPT 专为人类对话而设计。这与使用类似 SQL 的东西来进行 “查询/对话” 完全不同。我们必须像与人对话一样与人工智能模型交流。
由于这种交互方式的重要性,“Prompt Engineering(提示工程)” 一词已成为一门独立的学科。提高提示有效性的技术层出不穷。在制作提示语方面投入时间,可以大大提高结果输出。
举例:
Prompt 不清楚
你: 写篇文章。
AI:输出随机一篇一般般的文章。
Prompt 清晰
你: 用简单易懂的方式写一篇 300 字文章,主题是“上班族的压力”,语气轻松幽默,分 3 段,让读者能产生共鸣。
AI:高质量符合要求的文章
Prompt 清晰程度 = AI 输出质量的 80% 决定因素。
一个比较标准的Prompt模板
你现在是一个 {角色}。
任务:{你要它做什么}
背景:{为什么要做}
要求:
1. {要求1}
2. {要求2}
3. 输出格式:{格式要求}
例如:
你是一个资深文案策划。
任务:帮我写一个直播间口播。
背景:我们在做双十一活动,目标是提升转化。
要求:
1. 语气热情但不要夸张
2. 控制在 30 秒内能读完
3. 输出格式为三段话
1.3 Token(令牌)
令牌(Token)是 AI 模型运作的基础单元。输入时,模型将词语转换为令牌;输出时,再将令牌转换回词语。Token 是 AI 将文字拆成的小片段。AI 不是以“字”来理解语言,而是以 token。
举例:
| 文本 | 大概会变成多少 Token? |
|---|---|
| “你好” | 2 个 token |
| “我爱北京天安门” | 大概 6~8 个 token |
| “Hello world” | 大概 2~3 个 token |
| “我有 100000 元” | AI 会把数字拆很多,可能 3~5 个 token |
Token有什么影响
1: 影响输入长度
每个模型对 Token 数有上限,比如:
- GPT-3.5:4k token
- GPT-4:128k token
- GPT-4.1 / GPT-5:几百万 token
(不同版本不一样)
2: 影响费用
像 OpenAI、月之暗面、Gemini 都按 token 收费。你发一句 1000 字的内容 = 消耗很多 token。
3: 影响处理速度
Token 越多,生成越慢、成本越高。
2. Spring AI 概述
Spring AI 是 Spring 官方推出的、用于简化 AI 应用开发的框架。它提供了一套统一的 API,让你可以用几乎相同的代码,对接不同的 AI 服务(如 OpenAI、Azure OpenAI、Anthropic、本地模型等)。
如果不使用SpringAI, 想要在你的应用中使用大模型的能力, 你需要编写下面这段代码接入:
// 你需要:手动处理 HTTP 请求、JSON 解析、错误处理、不同API的差异...
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.openai.com/v1/chat/completions"))
.header("Authorization", "Bearer sk-xxx")
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString("{\"model\": \"gpt-4\", \"messages\": [...]}"))
.build();
// 还要处理响应、重试、限流...很繁琐!
此种接入方式, 也是各个大模型文档中提供的最基础的接入方式, 但是,很繁琐,并且每个大模型的接入方式不同.
下面是使用SpringAI的方式
@RestController
public class AIController {
@Autowired
private ChatClient chatClient; // 注入 AI 客户端
@GetMapping("/ask")
public String ask(String question) {
return chatClient.call(question); // 一行调用!
}
}
解决的问题:
-
消除样板代码:不再需要手动处理 HTTP 调用、JSON 序列化
-
统一接口:用同一套 API 对接 OpenAI、Azure、Google Vertex AI、本地模型等
-
Spring 生态集成:天然支持依赖注入、配置管理、测试框架等 Spring 全家桶
-
快速:几分钟就能让应用具备 AI 能力
3. Spring AI入门案例
使用SpringBoot 可以快速构建一个SpringAI项目, Spring AI 的环境要求:
- Spring AI 依赖 Spring Framework 6+
- Spring Framework 6 需要 Java 17+
- 因此 Spring Boot 必须是 3.x
引入pom依赖:
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
</dependencies>
//指定版本
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
application 配置: api-key需要在对应模型的官网后台获取,作为调用的凭证(需要充值), 我这里以deepseek为例
server:
port: 8089
spring:
application:
name: ai-test
ai:
openai:
# 你的api key
api-key: sk-**********
# 模型调用的路径
base-url: https://api.deepseek.com/v1
chat:
options:
#模型名称
model: deepseek-chat
temperature: 0.7
实现一个简单的调用: 使用SpringBoot自动配置的ChatClient类进行调用
@RestController
@RequestMapping("/ai")
public class AiController {
private final ChatClient chatClient;
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping
public String ai(@RequestParam String question) {
return this.chatClient.prompt()
.user(question)
.call()
.content();
}
}
启动调用http://127.0.0.1:8089/ai?question=你是谁
返回响应:
你好!我是DeepSeek,由深度求索公司创造的AI助手!😊 我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息进行分析处理。我完全免费使用,拥有128K的上下文长度,还支持联网搜索功能(需要你在Web/App中手动点开联网搜索按键)。 你可以通过官方应用商店下载我的App来使用。我很乐意为你解答问题、协助处理文档、进行对话交流等等! 有什么我可以帮助你的吗?无论是学习、工作还是日常问题,我都很愿意为你提供帮助!✨
3.1 系统提示词
在用户通过api访问大模型时, 可以预设一些系统消息, 这些消息将会携带在每一个请求之中. 使用方式如下:
可以在构建时指定系统消息
private final ChatClient chatClient;
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.defaultSystem("你将以一个数学老师的身份回答,并且语言幽默一下").build();
}
启动调用http://127.0.0.1:8089/ai?question=你是谁
返回响应:
我是你的数学老师,代号“π先生”!今天想聊聊三角函数还是微积分?或者……想挑战一道有趣的数学谜题?😄
3.2 消息参数
可以在系统或用户消息中设置参数,以便在访问时替换为不同的语句.
实现方式:
private final ChatClient chatClient;
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.defaultSystem("你将以一个数学老师的身份回答,并且语言{system_param}的口吻回复").build();
}
@GetMapping
public String ai(@RequestParam String question) {
return this.chatClient.prompt()
.user(u -> u
.text("回答这个问题:" + question + "并以:{user_param}同学,你好! 作为开头")
.param("user_param", "张三"))
.system(sp -> sp.param("system_param", "非常严肃"))
.call()
.content();
}
可以看到,我们在系统消息和用户消息中,分别携带了一个参数, 可以根据业务需要,定制不同的语句.
启动调用http://127.0.0.1:8089/ai?question=你是谁
返回响应:
张三同学,你好!我是你的数学老师。在数学学习中,严谨和专注至关重要。请记住,无论是解题还是提问,都要保持清晰的逻辑和认真的态度。现在,请专注于你的学习任务。
3.3 Advisor
Advisor API为Spring应用中的AI驱动交互提供灵活的强大的拦截、修改和增强能力。
调用AI模型时,常见模式是在用户消息基础上追加或增强上下文数据。
此类上下文数据可分为多种类型,常见包括:
- 自有数据:AI模型未训练过的数据。即使模型经过类似数据,追加的上下文数据仍会优先影响响应生成。
- 对话:历史聊天模型 API 是无状态的。如果告知 AI 模型你的姓名,后续交互中就不会记住。必须每次请求都发送对话历史,确保生成响应时考虑先前的交互。
可以在构建时, 设置对话的上下文:
ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(
// 指定 历史记录
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// 指定 自己公司的业务资料
QuestionAnswerAdvisor.builder(vectorStore).build()
)
.user(userText)
.call()
.content();
在上述的代码, 我们使用advisors 设置数据, 具体的使用方式, 可以继续看后面几章
4. 提示(Prompt)
在 Spring AI 与 AI 模型的基础交互层中,提示词的处理方式类似于 Spring MVC 中的 "View" 管理,即创建包含动态内容占位符的扩展文本,随后根据用户请求或应用代码替换这些占位符。另一种类比是包含表达式占位符的 SQL 语句。
提示词结构在 AI 领域持续演进:最初是简单字符串,逐渐发展为包含 "USER:",""SYSTEM:"" 等模型可识别的特定输入占位符。OpenAI 进一步引入结构化设计,在 AI 模型处理前将多条消息按不同角色分类。
使用提示词通常是使用 ChatModel 的 prompt() 方法,该方法接收 Prompt 实例.
Prompt 类作为有序 Message 集合对象和请求 ChatOptions 的容器。每个 Message 在提示中扮演独特角色,其内容和意图各异 — 从用户询问到 AI 生成响应,再到相关背景信息。这种结构支持与 AI 模型的复杂交互,因为提示由多条消息构建而成,每条消息在对话中承担特定角色。
以下是 Prompt 类的简化版本(省略构造函数和工具方法):
public class Prompt implements ModelRequest<List<Message>> {
private final List<Message> messages;
private ChatOptions chatOptions;
}
而每条消息又被分配特定角色,这些角色对消息进行分类,向 AI 模型阐明提示每个片段的上下文和目的。
这种结构化方法通过让提示的每个部分在交互中扮演明确角色,增强了与 AI 沟通的精细度和有效性。
角色(Role)
每条消息被分配特定角色,这些角色对消息进行分类,向 AI 模型阐明提示每个片段的上下文和目的。这种结构化方法通过让提示的每个部分在交互中扮演明确角色,增强了与 AI 沟通的精细度和有效性。
主要角色包括:
- System 角色:指导 AI 的行为和响应风格,设定 AI 解释和回复输入的参数或规则,类似于在开始对话前向 AI 提供指令。
- User 角色:代表用户的输入 — 包括问题、命令或对 AI 的陈述。该角色构成 AI 响应的基础,具有根本重要性。
- Assistant 角色:AI 对用户输入的响应,不仅是答案或反应,更对维持对话流至关重要。通过追踪 AI 之前的响应(其 "Assistant Role" 消息),系统确保连贯且上下文相关的交互。助手消息也可能包含函数工具调用请求信息 — 这是 AI 的特殊功能,在需要时执行计算、获取数据等超越对话的特定任务。
- Tool/Function 角色:专注于响应工具调用类助手消息,返回附加信息。
在上面的示例中,我们就使用了不同角色的提示词进行调用AI, 如下代码, 我们在构建Client时,指定了一个默认SystemText ,在call时,将用户问题传入user方法. 其实在SpringAI底层, 就是指定了两条Message对象,并赋予了不同的角色.
private final ChatClient chatClient;
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.defaultSystem("你将以一个数学老师的身份回答,并且语言幽默一下").build();
}
@GetMapping
public String ai(@RequestParam String question) {
return this.chatClient.prompt()
.user(question)
.call()
.content();
}
下面是org.springframework.ai.chat.client.DefaultChatClient#toAdvisedRequest 方法,是框架调用时处理Message的相关代码, 可以看到, 如果没有使用这种简易方式指定UserText,和 SystemText. 框架将会从Message列表中取出最后一条,作为Text设置.
// Process userText, media and messages before creating the AdvisedRequest.
String userText = inputRequest.userText;
List<Media> media = inputRequest.media;
List<Message> messages = inputRequest.messages;
// If the userText is empty, then try extracting the userText from the last
// message
// in the messages list and remove it from the messages list.
if (!StringUtils.hasText(userText) && !CollectionUtils.isEmpty(messages)) {
Message lastMessage = messages.get(messages.size() - 1);
if (lastMessage.getMessageType() == MessageType.USER) {
UserMessage userMessage = (UserMessage) lastMessage;
if (StringUtils.hasText(userMessage.getText())) {
userText = lastMessage.getText();
}
Collection<Media> messageMedia = userMessage.getMedia();
if (!CollectionUtils.isEmpty(messageMedia)) {
media.addAll(messageMedia);
}
messages = messages.subList(0, messages.size() - 1);
}
}
下面的示例,是使用Prompt对象构建提示词,相比之前的简易方式, 此种方式, 可以做出更复杂的业务逻辑
private final ChatClient chatClient;
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping
public String ai(@RequestParam String question) {
String userText = """
今天的微积分课程太难了!
""";
// 直接创建不带参数的Message对象
Message userMessage1 = new UserMessage(userText);
Message userMessage2 = new UserMessage(question);
Message systemMessage1 = new SystemMessage("你要以一个老师的身份回答学生的问题");
String systemText = """
你需要以一个非常{param}的口吻回答问题
""";
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemText);
Message systemMessage2 = systemPromptTemplate.createMessage(Map.of("param", "严肃"));
// 加入的顺序也很重要
Prompt prompt = new Prompt(List.of(userMessage1, userMessage2, systemMessage1, systemMessage2));
return this.chatClient.prompt(prompt)
.call()
.content();
}
启动调用: http://127.0.0.1:8089/ai?question=老师请你帮帮我
响应:
别怕!微积分就像吃披萨——看起来复杂,但切开后都是美味的小三角!📐🍕 让我用魔法把导数变成你的超能力,积分变成存钱罐,包你下节课能对着黑板说:“就这?”
5. 结构化输出
在一些非客服类型,或者聊天类型的调用中, 我们通常是把大模型做为一个第三方API调用, 我们希望快速将 AI 模型结果转换为 JSON、XML 或 Java Class 等数据类型,以便传递给其他应用函数和方法。大语言模型生成结构化输出的能力对依赖可靠解析结果的下游应用至关重要。
Spring AI 结构化输出转换器(Structured Output Converter)帮助将 LLM 输出转为结构化格式。
目前常用的几种转换实现类
BeanOutputConverter<T>-BeanOutputConverter<T>:通过配置 Java 类或ParameterizedTypeReference,该转换器(Converter)使用FormatProvider实现指导 AI 模型生成符合DRAFT_2020_12、JSON Schema的响应(基于指定 Java 类生成),随后用ObjectMapper将 JSON 输出反序列化为目标类的 Java 对象实例。MapOutputConverter- 继承AbstractMessageOutputConverter的功能,通过FormatProvider实现引导 AI 模型生成符合 RFC8259 标准的 JSON 响应,并利用提供的MessageConverter将 JSON Payload 转换为java.util.Map<String, Object>实例。ListOutputConverter- 继承AbstractConversionServiceOutputConverter,包含专为逗号分隔列表输出定制的FormatProvider实现。该转换器利用提供的ConversionService将模型文本输出转换为java.util.List。****
从大语言模型(LLM)生成结构化输出需谨慎处理输入输出。结构化输出转换器在 LLM 调用前后起关键作用,确保获得预期输出结构。
在 LLM 调用前,转换器向提示词追加格式指令,为模型生成预期输出结构提供明确指导。这些指令作为蓝图,引导模型响应符合指定格式。
LLM 调用后,转换器(Converter)将模型的原始文本输出转换为结构化类型实例。该转换过程包括解析原始文本输出,并将其映射 为JSON、XML 或领域特定数据结构等对应的结构化数据表示。
转换器会尽力将模型输出转换为结构化格式,但 AI 模型并不保证按请求返回结构化输出(可能无法理解提示或生成所需结构)。建议实现验证机制以确保模型输出符合预期。
用户引导大模型返回指定格式的方式, 通常通过 PromptTemplate 追加到用户输入末尾,如下所示:
StructuredOutputConverter outputConverter = ...
String userInputTemplate = """
... user text input ....
{format}
"""; // 包含 "format" 占位符的用户输入。
Prompt prompt = new Prompt(
new PromptTemplate(
this.userInputTemplate,
Map.of(..., "format", outputConverter.getFormat()) // 将 "format" 占位符替换为转换器的格式指令。
).createMessage());
下面是一个此类格式指令的示例:
您的回复应该是JSON格式。
JSON的数据结构应该匹配这个Java类:Java .util. hashmap
不包含任何解释,只提供遵循此格式的符合RFC8259的JSON响应,没有偏差。
5.1 Map格式转换
下面这段代码是指定响应格式为Map类型的示例, 可以看到, 我们需要的模板和框架自动生成的格式,都拼接在消息的下方. 引导ai生成的格式为指定格式.
@GetMapping
public String ai(@RequestParam String question) {
MapOutputConverter mapOutputConverter = new MapOutputConverter();
// 转化类自动生成的标准提示词,可以默认加上
String format = mapOutputConverter.getFormat();
String template = """
请给我{name}的销量最好的专辑信息.
包含字段:
- song:包含的歌曲(数组)
- sales:销量(数字)
- name:专辑名称(字符串)
{format}
""";
Prompt prompt = new PromptTemplate(template,
Map.of("name", "周杰伦" , "format", format)).create();
Map<String, Object> entity = this.chatClient.prompt(prompt).call().entity(mapOutputConverter);
return JSON.toJSONString(entity);
}
启动调用: http://127.0.0.1:8089/ai
响应:
调试一下源码, 可以看到发送消息的原文,其中英文部分为框架生成的标准生成json格式的提示信息:
请给我周杰伦的销量最好的专辑信息.
包含字段:
- song:包含的歌曲(数组)
- sales:销量(数字)
- name:专辑名称(字符串)
Your response should be in JSON format.
The data structure for the JSON should match this Java class: java.util.HashMap
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Remove the ```json markdown surrounding the output including the trailing "```".
{spring_ai_soc_format}
5.2 对象格式转换
下面这段代码是指定响应格式为Object类型的示例
创建类:
@Setter
@Getter
public class AlbumInfo {
/**
* 专辑的名称
*/
private String name;
/**
* 销量
*/
private Integer sales;
/**
* 此专辑中包含的歌曲名称集合
*/
private List<String> song;
}
转换方法
@GetMapping
public String ai(@RequestParam String question) {
BeanOutputConverter<List<AlbumInfo>> outputConverter = new BeanOutputConverter<>(
new ParameterizedTypeReference<>() {
});
String format = outputConverter.getFormat();
// 框架错误, json格式被识别成模板{}
format = format.replace("{", "\\\\\\{");
format = format.replace("}", "\\\\\\}");
String template = """
请给我{name}的销量前五的专辑信息,并按从高到低排列.
{format}
""";
Prompt prompt = new PromptTemplate(template, Map.of("name", "周杰伦", "format", format)).create();
List<AlbumInfo> entity = this.chatClient.prompt(prompt).call().entity(outputConverter);
return JSON.toJSONString(entity);
}
启动调用: http://127.0.0.1:8089/ai
响应:
[{
"name": "Jay",
"sales": 3000000,
"song": ["可爱女人", "星晴", "龙卷风", "黑色幽默", "印第安老斑鸠"]
}, {
"name": "范特西",
"sales": 2800000,
"song": ["爱在西元前", "简单爱", "开不了口", "双截棍", "安静"]
}, {
"name": "叶惠美",
"sales": 2600000,
"song": ["以父之名", "晴天", "三年二班", "东风破", "她的睫毛"]
}, {
"name": "八度空间",
"sales": 2500000,
"song": ["半兽人", "半岛铁盒", "暗号", "龙拳", "回到过去"]
}, {
"name": "七里香",
"sales": 2400000,
"song": ["七里香", "借口", "外婆", "止战之殇", "园游会"]
}]
6. 聊天记忆
大语言模型(LLM)本质上是无状态的,这意味着它们不会保留历史交互信息。当需要跨多轮交互保持上下文时,大模型将无法联系上下文。因此,Spring AI 提供了聊天记忆功能,支持在 LLM 交互过程中存储和检索上下文数据。
ChatMemory抽象类支持实现多种记忆类型满足不同场景需求。ChatMemory实现类可自主决定消息保留策略——例如保留最近N条消息、按时间周期保留或基于Token总体保留。
InMemoryChatMemoryRepository基于ConcurrentHashMap实际内存存储。是SpringAI对于ChatMemory的默认实现,数据主要存储在内存中.
示例:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
private final String conversationId = UUID.randomUUID().toString();
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatMemory = new InMemoryChatMemory();
this.chatClient = chatClientBuilder.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()).build();
}
@GetMapping
public String ai(@RequestParam String question) {
Message userMessage = new UserMessage(question);
Prompt prompt = new Prompt(List.of(userMessage));
String content = this.chatClient.prompt(prompt)
.call()
.content();
chatMemory.add(conversationId, userMessage);
return content;
}
上面的示例中,演示了如何在构建时加入一个ChatMemory, 用于保存和读取历史记录, 可以看到在保存时将消息,以当前会话为Id进行存储, 这样只要是这个会话ID进行调用的请求, 框架将会自动读取历史记录,并携带到请求中
启动调用: http://127.0.0.1:8089/ai?question=北京天气怎么样
响应:
好的,针对 北京 的天气,我为您整理了以下信息: ### 明日(近期)天气预报 根据主流气象平台的预报模式,未来24-48小时北京的天气情况如下: * 天气状况:近期北京以晴到多云天气为主,天气比较稳定。明天大概率是晴天或多云,出现降雨的可能性较低。 * 气温:日间最高气温预计在 28℃ ~ 33℃ 之间,夜间最低气温在 18℃ ~ 22℃ 左右。昼夜温差较大,午后阳光下体感较热。 * 风力:风力不大,通常为北转南风2-3级。 * 空气质量:近期北京空气质量整体较好,以良为主,但建议出行前查看实时AQI指数。 ### 给您的出行建议 1. 防晒防暑:白天紫外线较强,天气干燥炎热,请务必做好防晒(防晒霜、遮阳帽、太阳镜)和补水措施。 2. 穿衣指南:建议穿着短袖、裙子等夏季衣物,并备一件薄外套或衬衫,用于傍晚后温差较大时穿着。 3. 无需雨具:明日降雨概率低,可不携带雨具。 ### 最准确的查询方式(强烈推荐) 为了获得最精确的预报,请您通过以下方式在出行前做最终确认: * 打开手机自带的天气APP。 * 在微信中搜索“北京天气”小程序。 * 直接访问“中国天气网” 并搜索“北京”。 总结:明天北京预计是晴热天气,昼夜温差大,请注意防晒补水,并以实时查询为准。 希望这些信息能帮助您!祝您在北京一切顺利! ☀️
再次调用: http://127.0.0.1:8089/ai?question=杭州呢
好的,再次为您查询 杭州 的天气。 根据最新的气象数据模式,杭州未来24-48小时的天气与之前提到的趋势相似,但更加具体: ### 明日天气预报(更新) * 天气状况:多云转阵雨或雷阵雨。降雨概率较高,尤其是午后到夜间。请您务必做好防雨准备。 * 气温:最高温 27℃ ~ 30℃,最低温 20℃ ~ 22℃。湿度大,体感会比较闷热。 * 风力:微风,东南风2-3级。 ### 核心提醒 1. 雨伞必备:明天出门一定要带伞,既可防晒,更能防突如其来的阵雨。 2. 穿衣建议:穿透气的夏装(短袖、裙子),并多备一件薄外套应对室内空调或雨后微凉。 3. 出行注意:如果遇到雷雨,请小心道路湿滑,注意交通安全。 ### 最佳查询方式 天气变化快,最准确的永远是实时信息。建议您: * 立即打开手机天气APP查看分钟级预报。 * 在微信搜索“杭州天气” 使用官方小程序。 总结:明天杭州很可能有雷阵雨,天气闷热。请以实时查询为准,并随身带伞。 祝您在杭州出行顺利! 🌦️
可以看到,当再次询问时, 返回的仍然是天气信息, 本次调用,携带了上次的历史记录.
除了默认实现的内存存储, 还可以引用第三方jar包,实现从数据库中存取: JdbcChatMemoryRepository
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
7. 工具调用
工具调用(亦称函数调用)是AI应用的常见模式,允许模型通过与一组API(即工具)交互来扩展其能力。
工具主要评估以下场景:
- 信息搜索。此类工具可用于从外部源搜索信息,例如数据库、网络服务、文件系统或网络搜索引擎。目的是增强模型的知识,从而能够回答哪些无法回答的问题。因此,它们可用于搜索增强生成(RAG)场景。例如,可以使用工具搜索文章给定位置的当前天气、搜索其最新新闻或查询数据库中的特定记录。
- 执行操作。可用于在软件系统中执行操作的工具,例如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。其目的是自动化那些到底需要人工干预或显着式编程的任务。例如,可以使用工具与聊天机器人交互的客户预订航班、填写网页上的表单,或在基于自动化测试(TDD)实现 Java 类的代码生成场景中。
工具的设计安全问题:
- 防止未授权访问:AI 不能直接访问数据库或内部系统
- 输入验证:应用程序可以验证参数是否合法
- 权限控制:只有应用程序知道当前用户的权限
- 数据脱敏:可以在返回前脱敏敏感数据
也就是说:AI是"建议者",应用程序是"执行者"。AI建议要做什么,但真正的操作权在应用程序手中,这样可以确保安全可控。不可以直接操作数据库等等
下面,通过一个示例,来表示,如何让AI去执行查询和设置操作.
先定义两个函数,函数即工具
@Configuration
public class MyAiTools {
public record operation(String name) {
}
@Bean
@Description("根据姓名查询工作状态,入参是姓名,返回值是Boolean类型")
public Function<operation, Boolean> select() {
return request -> {
return StrUtil.equals("张三", request.name());
};
}
@Bean
@Description("根据姓名设置提醒,入参是姓名,返回值是是否成功")
public Function<operation, Boolean> set() {
return request -> {
System.out.println(request.name + "设置成功");
return true;
};
}
}
注册函数
@GetMapping
public String ai(@RequestParam String question) {
return chatClient.prompt()
.system("""
你是一个工作管家,当有人报姓名给你时,你将自动调用select函数,查询此姓名状态, 如果为True,则调用set函数, 并提示设置成功, 如果返回false,你将提示状态异常
""")
.user(question)
.functions("select", "set")
.call()
.content();
}
我们模拟一个打卡设置提醒的场景.
启动调用: http://127.0.0.1:8089/ai?question=我是张三
响应:
设置成功!已为张三设置了工作提醒。
并且后台打印 : 张三设置成功, 说明调用成功
再次调用: ``http://127.0.0.1:8089/ai?question=我是李四`
状态异常!李四的工作状态为false,无法设置提醒。
8. 检索增强生成(RAG)
大语言模型(LLM)在训练完成后即固化,导致知识陈旧,尤其是公司内部操作手册,公司文档等一些私有数据, AI大模型更无从得知. 所以AI大模型无法帮助分析这些,
搜索增强生成(RAG)是一项关键技术,用于克服大语言模型在长文本处理、事实准确性和捕捞方面的局限性。
Spring AI 通过提供升级架构支持 RAG,既可以构建自定义 RAG 流程,也可以使用AdvisorAPI 开箱即用的 RAG 流程。
下面这个示例,将演示SpringAI如何使用RAG
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
List<Document> documents = List.of(
new Document("上班时间9:30,下班时间6:30"),new Document("公司地址在浙江杭州萧山"));
//向量化存储
simpleVectorStore.add(documents);
return simpleVectorStore;
}
上述代码,将创建一个基于本地内存存取的VectorStore实现类, 并向其中存了两条规章制度, 使用默认的嵌入模型进行向量计算(需要换模型,deepseek不支持嵌入模型)
使用advisors方法, 设置vectorStore:
@GetMapping
public String ai(@RequestParam String question) {
return chatClient.prompt()
.system("""
你是一个工作管家,将从公司规章中读取信息,回答用户问题
""")
.user(question)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}
启动调用: http://127.0.0.1:8089/ai?question=我从西湖区出发坐地铁上班,早上几点起好
响应:
根据公司提供的上班时间9:30和地址在杭州萧山,建议您: 1. 先查询从西湖区到萧山的地铁路线和所需时间(通常需要1小时左右) 2. 预留30分钟步行/换乘缓冲时间 3. 加上洗漱、早餐等准备时间(建议1小时) 因此如果您住在西湖区,建议: - 地铁需要1小时:7:00-7:30出发 - 加上准备时间:6:00-6:30起床 具体起床时间建议您根据: - 住所到地铁站的距离 - 早高峰拥挤程度 - 个人准备时长 来调整。由于我无法获取您的具体住址和路线信息,建议使用地图APP查询精确的通勤时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号