PICOAUDIO2
PICOAUDIO2
PICOAUDIO2: TEMPORAL CONTROLLABLE TEXT-TO-AUDIO GENERATION WITH NATURAL LANGUAGE DESCRIPTION
动机
重要性
- 虚拟现实
- 社交媒体
存在的问题
- 现有的模型根据时间戳,可以生成很好的时间上控制的audio,但是只能生成固定集合(不能由自然语言给出吧)
- 现有的通常是在合成数据上进行训练的
- 现有的数据没有音频事件的准确时间戳
贡献
- 构建数据集,pipeline,在生成数据集上引入真实数据集
- 更加明确地控制了各个事件的时间
- 达到了很好的效果
相关工作
audio:音频
TCC:对音频进行的描述,可能仅仅包含时间或者是粗略的位置
TDC:事件以及具体的发声时刻
Make-An-Audio 2 (MAA2):通过大语言模型(LLM)将输入文本转化为结构化描述,以指定时间上的发生(事件在整个过程中、开始时或结束时发生)。然而,这种控制仍然是粗粒度的。
AudioComposer:使用结构化文本编码时间发生和能量等控制信息,取得了较高的控制精度。但其训练数据中的字幕是模拟的,因此在使用真实数据(如人类标注的AudioCaps数据集)时,音频质量受限。
PicoAudio:通过引入时间戳矩阵来标明事件发生的时间,实现了较好的音质和预定义短时事件的时间控制。然而,时间戳矩阵仅限于预定义的类别,缺乏灵活性,无法适应自然语言描述和开放式事件规范。
我觉得:主要改进是:1:声音描述、时间描述可以使用自然语言(如果不存在TDC,会使用LLM生成;就算生成之后,也是使用一个编码器转化为固定格式带有时间戳的输入,这里的适配仅仅是可以使用自然语言描述)2:使用了数据集的构造方式
数据飞轮
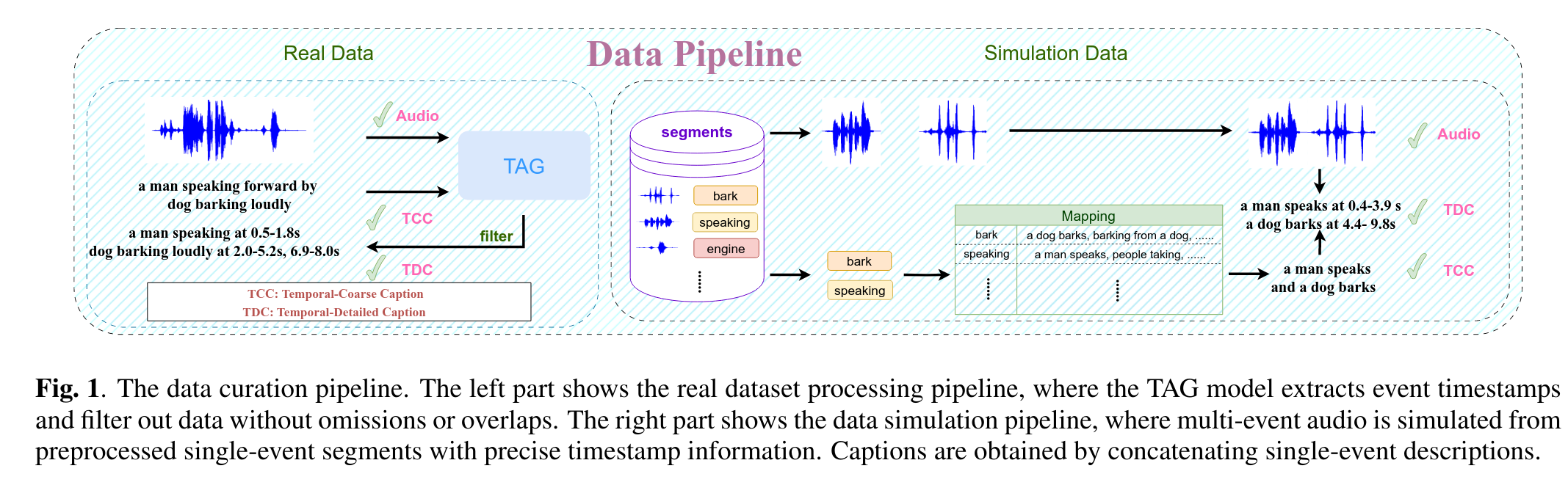
合成数据
三元组:audio-TCC-TDC
使用的是 AudioTime Benchmark Dataset
对于TCC,原始数据集中仅仅有音频的种类,但是不是自然语言描述:
- 种类 -> LLM 的若干个自然语言描述 -> 使用CLAP筛选匹配度最高的30个 -> 人工校验 -> 对于这个类别的音频,会随机选择30个caption中最可能的一个
真实数据
使用audiocaps
对于TDC
- 使用LLM根据TCC得到所有的音频事件 -> TAG 标注时间 -> 去除没有识别的;去除有重叠的音频事件
- 最初的原始的仅仅含有TCC和音频的全部保留
模型
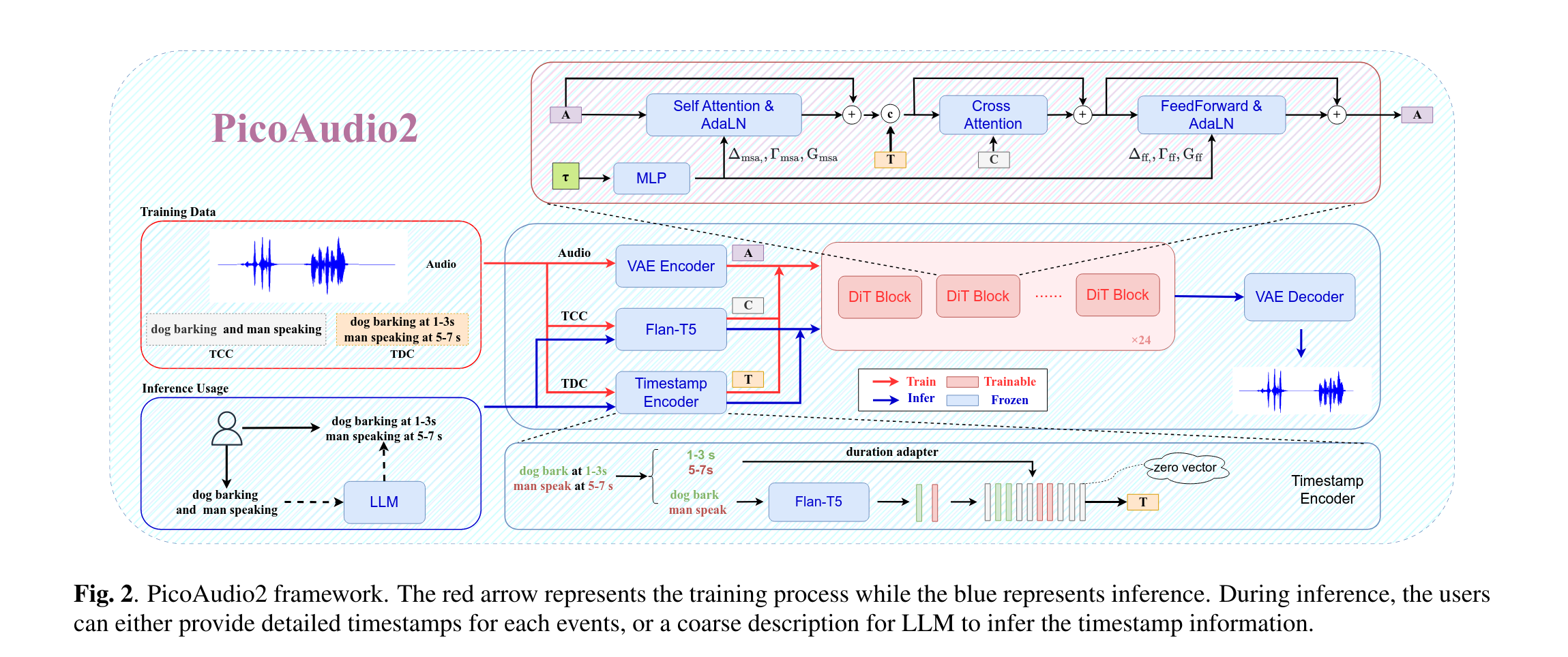
- Audio - VAE:EzAudio
- TCC Flan-T5
- TDC 自己训练了一个编码器
- DiT:EzAudio
Timestamp Encoder
- 训练的时候选择性丢弃,便于无条件生成(但是在推理的时候,缺少TDC的话也是让LLM生成的)
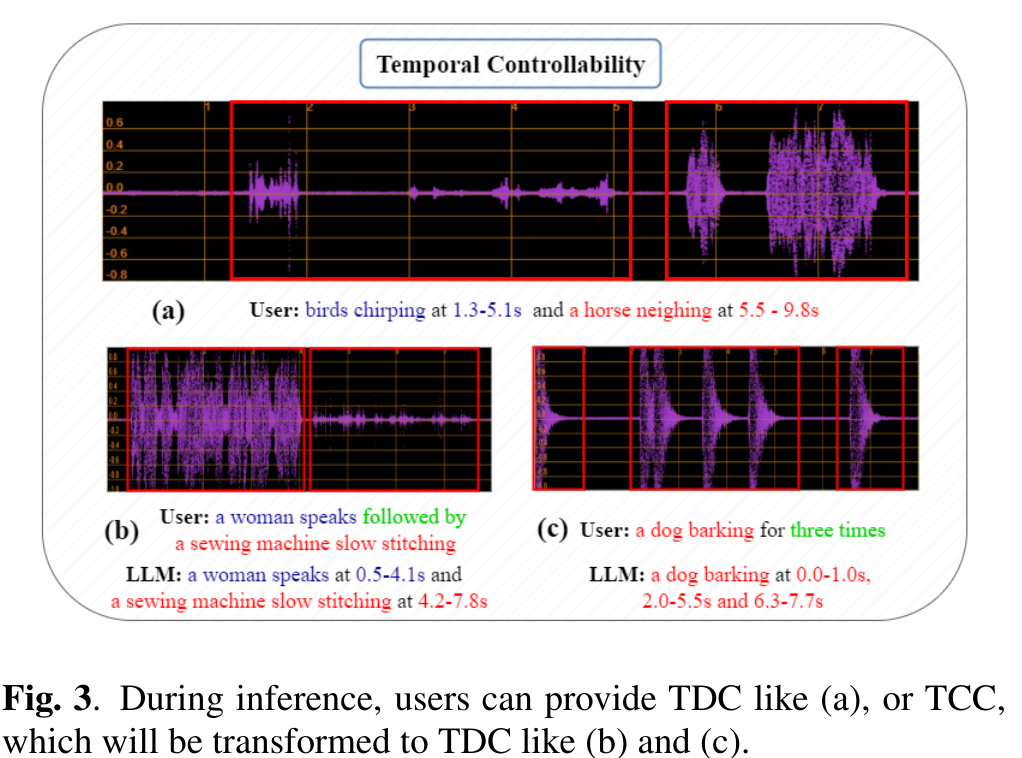
- 看上面的图
实验
| 数据类型 | 数据量 | 数据内容 |
|---|---|---|
| 模拟数据 | 64K音频片段 | 每个片段最大时长10秒,包含1至4个事件 |
| 真实数据 | 49K高质量音频-TDC对 | AudioCaps和WavCaps-ASSL子集的转化数据 |
| 时间弱数据 | 约106K | 来自AudioCaps和WavCaps-ASSL的数据,时间弱 |
| 时间强数据 | 约113K(64K + 49K) | 包含音频-TCC-TDC三元组 |
| 训练数据采样比例 | 1:2 | 时间弱数据与时间强数据的采样比例 |
我们保留无时间戳遗漏或重叠的数据,将该子集命名为AudioCaps-DisJoint(DJ)
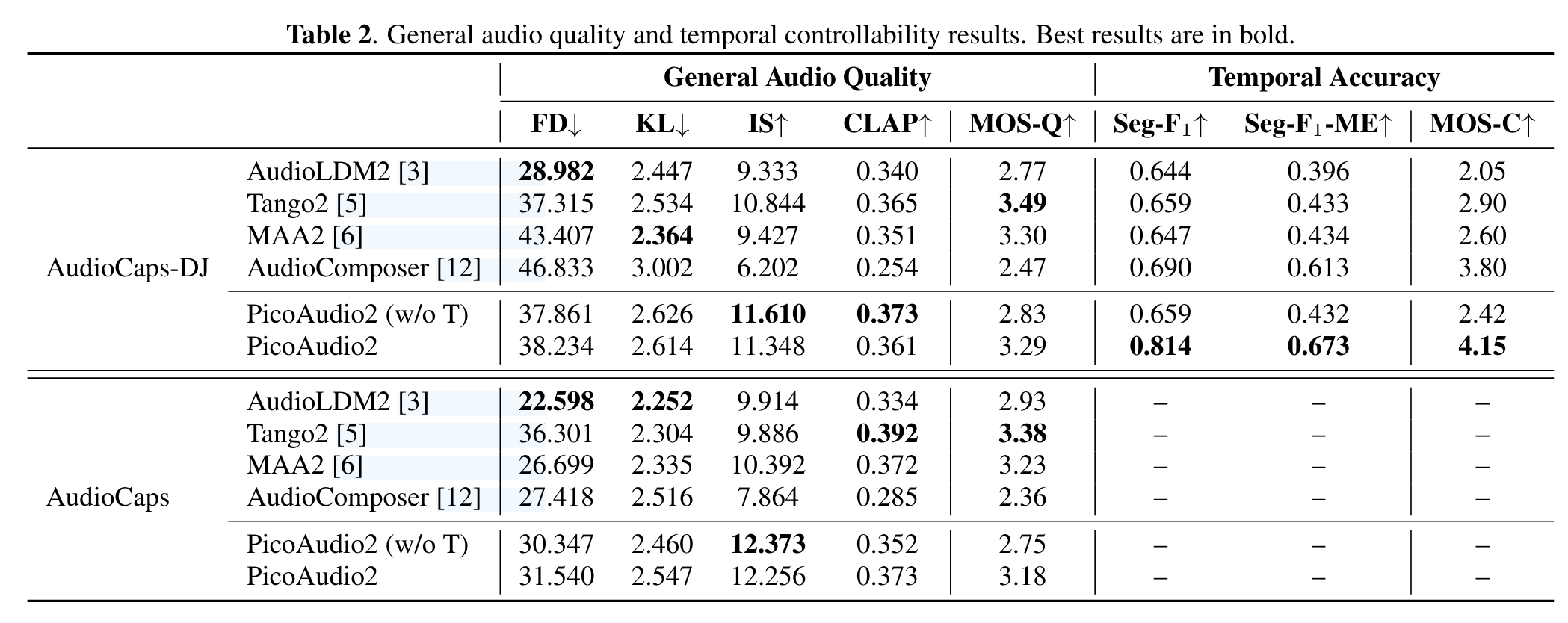
- AudioComposer仅仅使用了合成的数据,所以效果差吧
- 在AudioComposer中给定TDC之后效果变差,因为它同时处理事件和时间信息,导致事件的保真度较低。说明将音频内容和时间分开之后效果会根好
- PICOAUDIO2 相比 PICOAUDIO2(w/o T)有了控制矩阵之后时间对齐上效果根好
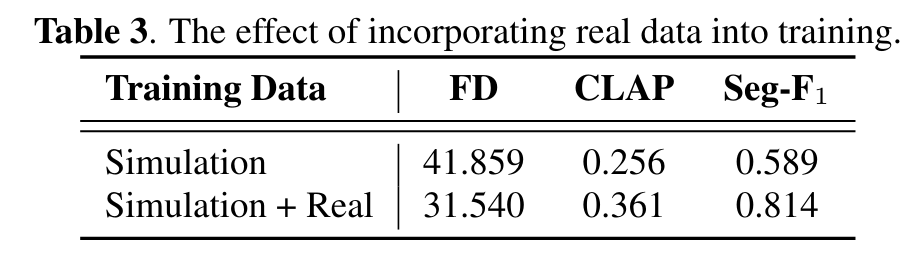
- 引入真实的数据很重要(我感觉引入Seg-F1是因为这个数据构造的方式使用了TAG,评估的时候也是使用TAG算的)
局限性
仅仅在TAG打标的没有重叠,并且对音频事件有具体时间上进行训练
本文来自博客园,作者:心坚石穿,转载请注明原文链接:https://www.cnblogs.com/xjsc01/p/19084067

 浙公网安备 33010602011771号
浙公网安备 33010602011771号