【KBQA RD论文阅读】Knowledge Base Relation Detection via Multi-View Matching
论文: Knowledge Base Relation Detection via Multi-View Matching
垃圾英语水平预警
摘要
论文提出一种基于multi-view匹配的知识库关系检测方法。
实验在SimpleQuestions和WebQSP上进行。
1 介绍
除了经常使用的关系名称之外,可以利用关系逻辑包含的实体信息(比如objects)。
比如,知识库三元组<subject, predicate, object>
问题:What country is located in the Balkan Peninsula?
对应的relation为contains,该relation的object type应该为location。
所以论文假设,除了关系名称之外,匹配问题和object实体类型也是有用的。
论文提出:
(1)将关系检测视为多视图匹配任务(问题, 关系),使用基于注意力机制的模型,在每个视图比较问题和关系。
(2)在多视图匹配模型中利用object type信息。
2 相关工作
知识库问答 - 关系检测
(1)使用预训练的关系嵌入(e.g. TransE)
(2)将关系检测视为序列匹配和排序任务。
3 问题概述
问题定义: 对于问题q,任务是识别出候选关系\(R=\{r\}\)中正确的关系\(r^{gold}\),所以关系检测的目标是:学习一个评分函数\(s(r|q)\),使排序损失最优。
问题和关系都有不同的输入特征视图。每个视图可以被表示为token序列(常规的单词或者关系名)。对关系\(r\)的视图i,有\(r^{(i)}=\{r_1^{(i)},...,r_{M_i}^{(i)}\}\),\(M_i\)为关系r在视图i的单词序列长度。对问题的定义类似。
最终,问题多视图输入为\(q = \{q^{(1)}, ...,q^{(N_q)}\}\),关系输入为\(r = \{r^{(1)},...,r^{(N_r)}\}\),\(N_q\)不一定等于\(N_r\)。
KB关系检测视图:对于输入的问题,从关系名称及其对应的尾部实体类型生成视图,并在模型中使用三对输入。
<entity name, entity mention>:实体链接<relation name, abstracted question>:用特殊标记替换问题中提到的实体成为抽象问题。<relation tail entity types, abstracted question>
通过第二视图和第三视图的输入,生成两个匹配的特征向量 (比如,<a,b>,\(a\rightarrow b\), 以及 \(a\leftarrow b\))。模型联合两对交互信息组合在一起,以具有高级联合视图。
4 关系尾部实体类型抽取
问题:What country is located in the Balkan Peninsula?
所对应的relation为contains,对应的尾部实体类型必须为location。
故而认为利用尾部实体的类型信息可以提升关系检测的效果。
但关系的尾部实体可能与多种类型相关联,比如<The_Audacity_of_Hope, author, Barack_Obama>,其中的Barack_Obama从泛化的类型,比如person,到更具体的类型,比如writer、politician、和us_president。因此,给出关系名author,去掉无联系的实体类型(politician, us_president),保留相关类型(preson, writer)至关重要。
具体做法:
- 对
Freebase中的每个关系获取最多500个实例。 - 查询第一部中获得的每个尾部实体的类型。
- 仅保留至少95%的尾部实体都具有的类型。
如果这种方法找不到任何类型,则使用默认的特殊标记。一旦或者类型,则串联每种尾部类型的单词来作为一个字符串,将该字符串用作尾部实体类型输入。
5 模型结构
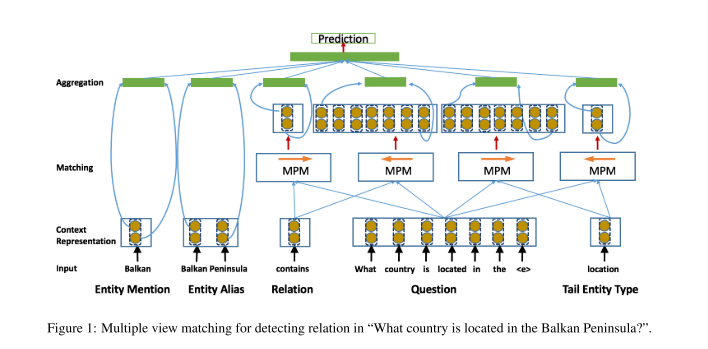
输入模块:
每个视图的输入都是词序列,模型对序列的编码可以分为两步。模型为每个单词构造一个d-维向量,包括两个方面:基于单词和基于字符的embedding。
词嵌入是固定的、预训练的向量(glove和word2vec等)。
基于字符的嵌入是通过将单词中的每个字符送到LSTM中计算得出。
上下文表示模块:
使用Bi-LSTM编码所有视图输入。
一个问题的上下文向量被用于多个匹配模块,为了与关系和尾部实体类型匹配。
目的:将上下文信息合并到每个输入序列的每个时间步的表示中。
匹配模块:
设计了带有注意力机制的匹配模块,将关系的每个视图与给定问题进行匹配。在这里attention可能很重要的原因是关系的不同视图通常对应于问题的不同部分。比如,如Figure 1中,问题单词可能指示关系类型。
使用双边多视图匹配模型(BiMPM[1]),假设问题的唯一视图需要与关系和尾实体类型 相匹配,并且匹配方法应该在多个粒度和多个视角将问题和关系相匹配。
一共四个MPM模块,所有模块共享相同的参数。每个MPM模块将两个序列(anchor和target)作为输入,将anchor的每个上下文向量与target的每个上下文向量进行匹配。在Figure 1中,箭头表示匹配方向,即\(anchor \rightarrow target\)。例如将问题和关系分别视为anchor和target。在匹配过程中,通过组合target的所有上下文向量,为anchor的每个上下文向量计算匹配向量,之后使用多视角余弦相似度函数从多个角度计算anchor上下文向量和匹配向量之间的相似度。
多视角余弦相似度计算为:
\(W \in R^{(l\times d)}\)是可训练的参数,返回的参数m是一个一维向量。每个\(m_k\in m\)是在k视角的匹配值,计算公式为:
其中,\(⊙\)为逐个元素相乘,\(W_k\)表示\(W\)中的第k行,\(W_k\)控制第k个视图,并为d维空间的不同维度分配不同的权重。
MPM模型使用四种匹配策略:
(1)Full-Matching: anchor的每个上下文向量与target的最后一个上下文向量比较,后者代表整个目标序列。
(2)Max-Pooling-Matching: 使用多视角余弦相似度anchor的每个上下文向量与target的每个像上下文向量相比较,并且只保留每个维度的最大值。
(3)Attentive-Matching: 计算两个序列中所有上下文向量相似度,然后通过获取target的所有上下文向量的加权和(权重为上面计算的余弦相似度)来计算匹配向量。
(4)Max_Attentive-Matching: 此策略与Attentionive-Matching相似,不同之处在于,它不选择所有上下文向量的加权和作为匹配向量,而是从target中选择具有最大余弦相似度的上下文向量。
聚合模块: 第一步:将两个Bi-LSTM应用于两个匹配向量序列,之后通过将Bi-LSTM模型中的最后一个时间步中的向量进行级联来构造定长匹配向量(一个视图的整体匹配表示)。为了组合来自输入对和实体对的不同视图的匹配结果,在最后具有聚合层,该聚合层从不同视图获取匹配表示或分数,并提取实体对的特征表示,然后构造特征向量以进行关系预测 。
6 实验部分
Dataset:
SimpleQuestions和WebQSP
Experimental Setup:
(1) LSTM: 300 hidden states
(2) learning rate: 0.0001
(3) number of training epochs: 30
词向量:glove
[1] Zhiguo Wang, Wael Hamza, and Radu Florian. 2017. Bilateral multi-perspective matching for natural language sentences. In IJCAI 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号