Linux统计文件内容重复行
需求:在一个文件中,如下文件内容有许多乱序的重复值,那我们想要快速知道哪些是重复值怎么办?试问你能靠眼里10秒内找到吗?哈哈哈
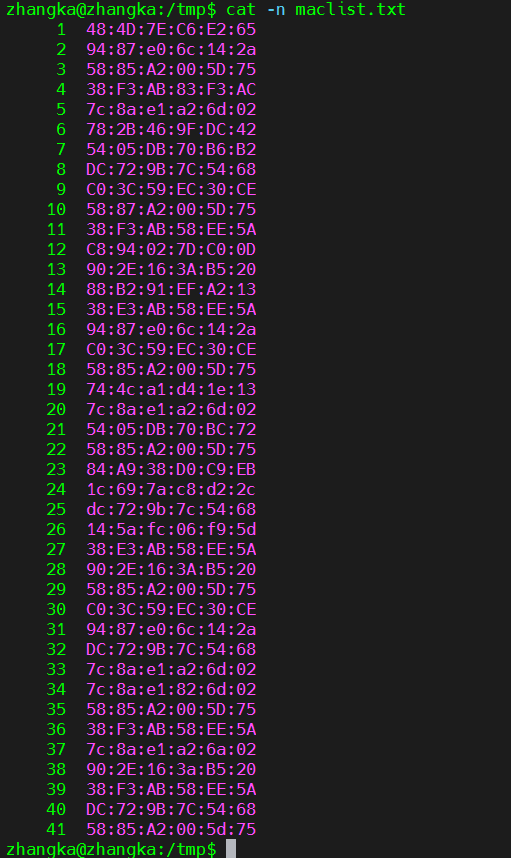
解决方案:先使用 sort 命令将文件内容进行排序,再使用 uniq 命令进行统计重复值
uniq 常用参数
-c #在每行前统计重复的次数
-d #只输出重复的行,每个重复值只输出一次
-i #不区分大小写
-u #只显示没有重复的行
sort maclist.txt | uniq -c
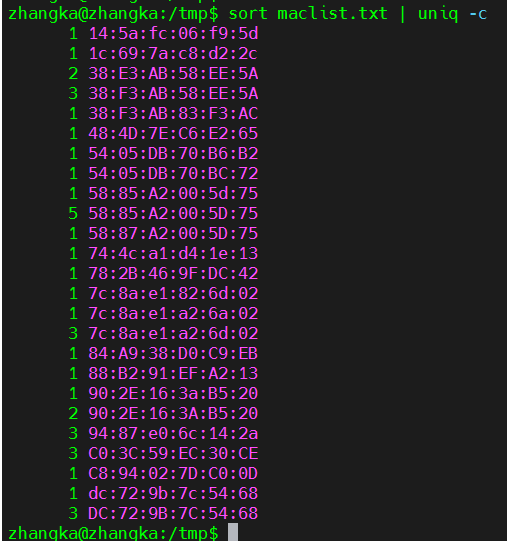
* 删除重复值
sort maclist.txt | uniq >mac.txt #sort文件内容排序后,使用uniq删除重复行并将输出结果写入新文件mac.txt
或者用 sort -u maclist.txt >mac.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号