
走向更好的指令伴随的汉语语言模型:研究训练数据和评估的影响
Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation
论文地址:https://arxiv.org/pdf/2304.07854v1.pdf
Part1介绍
研究了训练数据因素对模型性能的影响,包括数量、质量和语言分布。 评估数据集由1,000个中文指令样本组成,横跨9个真实的用户场景。 扩展了LLaMA的词汇量,并在中文语料库上进行了预训练,以提高其处理中文数据的效率,从而在不影响性能的情况下,减少了60%的训练和推理时间。
Part2相关工作
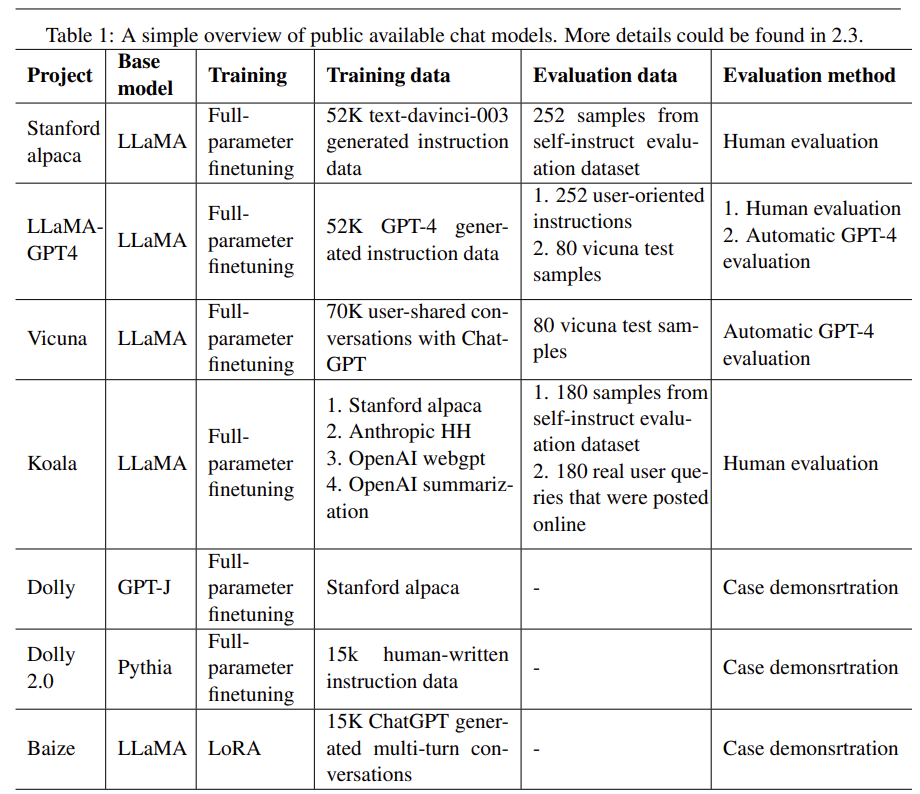
主要介绍了:LLM(大语言模型)、Instruction tuning(指令微调)、公开的可使用的聊天模型、评估大语言模型。感兴趣的可以去看看这部分,这里不作介绍了。
Part3收集对话数据
要求ChatGPT生成多轮对话数据,它需要在用户和人工智能助手之间产生跨越多个轮次 的对话。由于ChatGPT倾向于产生有限的和重复的对话场景,如天气查询和飞机票预订,我们用第一轮提示ChatGPT在对话中确定对话的主题,然后让ChatGPT继续进行相应的对话。
数据清洗:虽然ChatGPT能够以相对较低的成本生成高质量的数据,但生成的数据仍然存在重复和逻辑不一致等问题。为了提高生成数据的质量,我们首先在标记级和语义级上选择高质量的数据,并通过检查词频分布确保数据的多样性。
Part4评价数据
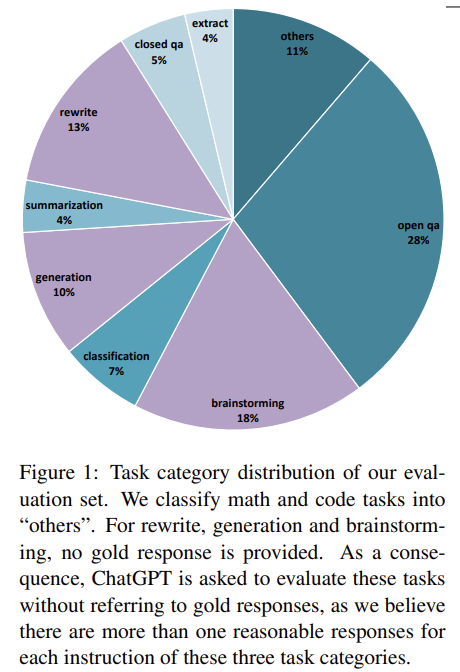
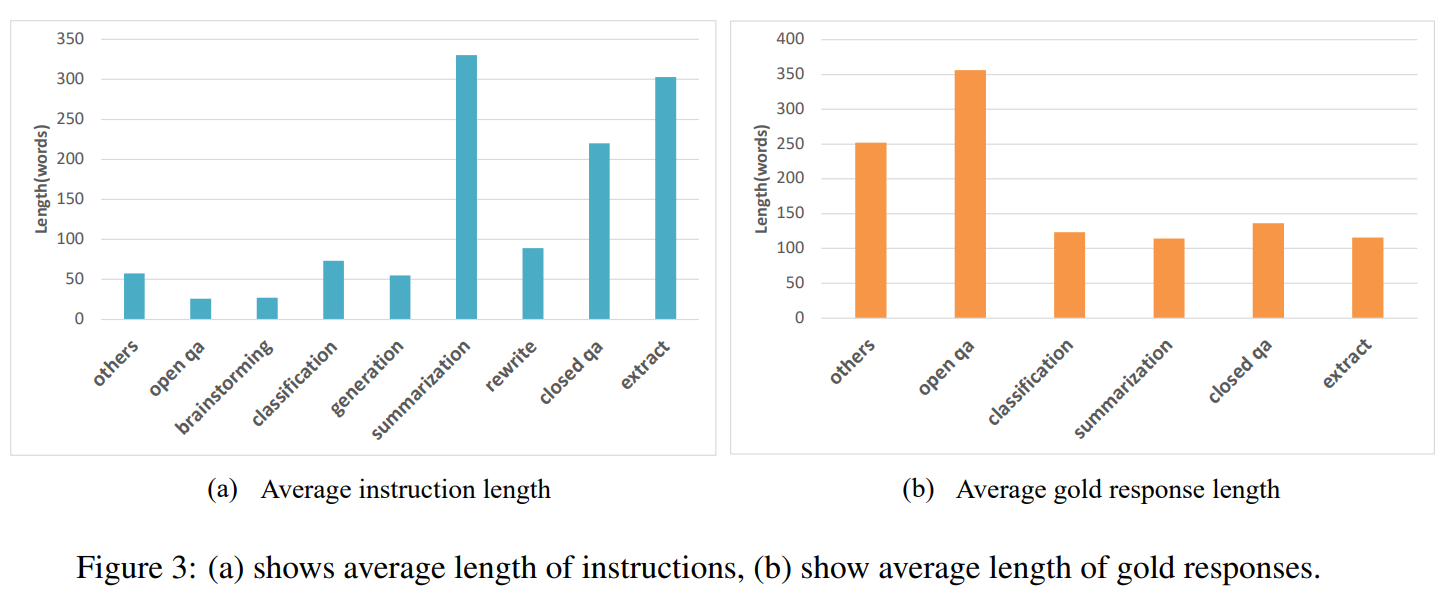
本文中使用的评价数据是从Ji等人(2023)中提炼出来的。我们对原始评价数据进行了语义上的删减,并将数学和代码任务重新分类为其他任务。原因有二:首先,这些任务相对较难,目前的开源模型在这些任务上表现 不佳,这可能会影响我们对其他能力的评价;其次,ChatGPT在评价这两项任务时不够可靠,这可能会导致有偏见的实验结果。针对于数据分布不平衡,在计算总分时,我们采用宏观平均法。
Part5扩展词表
由于LLaMA的词汇构建缺乏对中文的优化,一个汉字可能会被分割成2到3个字节的标记,这严重影响了模型的微调和对中文数据的推理速度(Cui and Yang, 2023)。为了解决这个问题,我们在1200万行的中文文本上使用句柄(Kudo and Richardson, 2018)训练一个基于字节对编码(BPE)算法的标记器,并将其词汇量设置为50K。我们将训练好的新词汇与原来的LLaMA词汇合并,得到了79458个新词汇。之后,我们调整了词嵌入的大小,并在其他参数固定的情况下,在34亿中文词汇上进一步预训练LLaMA。我们在5000行中文文本上测试了扩展标记器和原始标记器,一行的平均标记数从733个减少到291个。
Part6实验
LLaMa-7B LLaMa-7B-EXT:扩展vanillaLLaMA的词汇量,并在34亿中文词汇上进一步预训练得到的,其中只更新了词嵌入。 8个A100 GPU,每个80G显存,= =!。
1数据集
实验采用了六个数据集,其中五个是公开的,一个是专业的。
Alpaca-3.5-en(Taori et al., 2023):由52K个带指令的样本组成,这些样本是由text-davinci-003生成的。 Alpaca-3.5-zh(Cui and Yang, 2023):是lpaca-3.5-en的中文翻译版本。 Alpaca-4-en, Alpaca-4-zh(Peng等人, 2023):这是由LLaMA-GPT4发布的,都包含52K指令的后续样本。这些样本是由GPT-4生成的。为了获得alpaca-4-zh,Peng等人(2023)首先使用ChatGPT将52K指令翻译成中文,然后要求GPT-4用中文回答。 ShareGPT(ShareGPT,2023):用户与 ChatGPT共享的对话,包括 8.3K样本。我们进行三个步骤的数据清理( Chiang等人,2023)。只保留英文和中文的对话。此外,对话被划分为更小的片段,最大长度为2048个标记。最后,我们去掉了120,009条对话。 Belle-3.5:这是我们自己的数据集,包括跟随指令的样本和多轮对话。这个数据集包含500,000个样本,是用第3节中提到的清洗方法从230万个原始数据中过滤出来的。为了简化数据集的名称,同时在不同的数据设置下进行实验,我们定义了两个函数来识别给定数据集的语言。zh(d)表示中文版本的,而en(d)是指英语的。
Part7结果
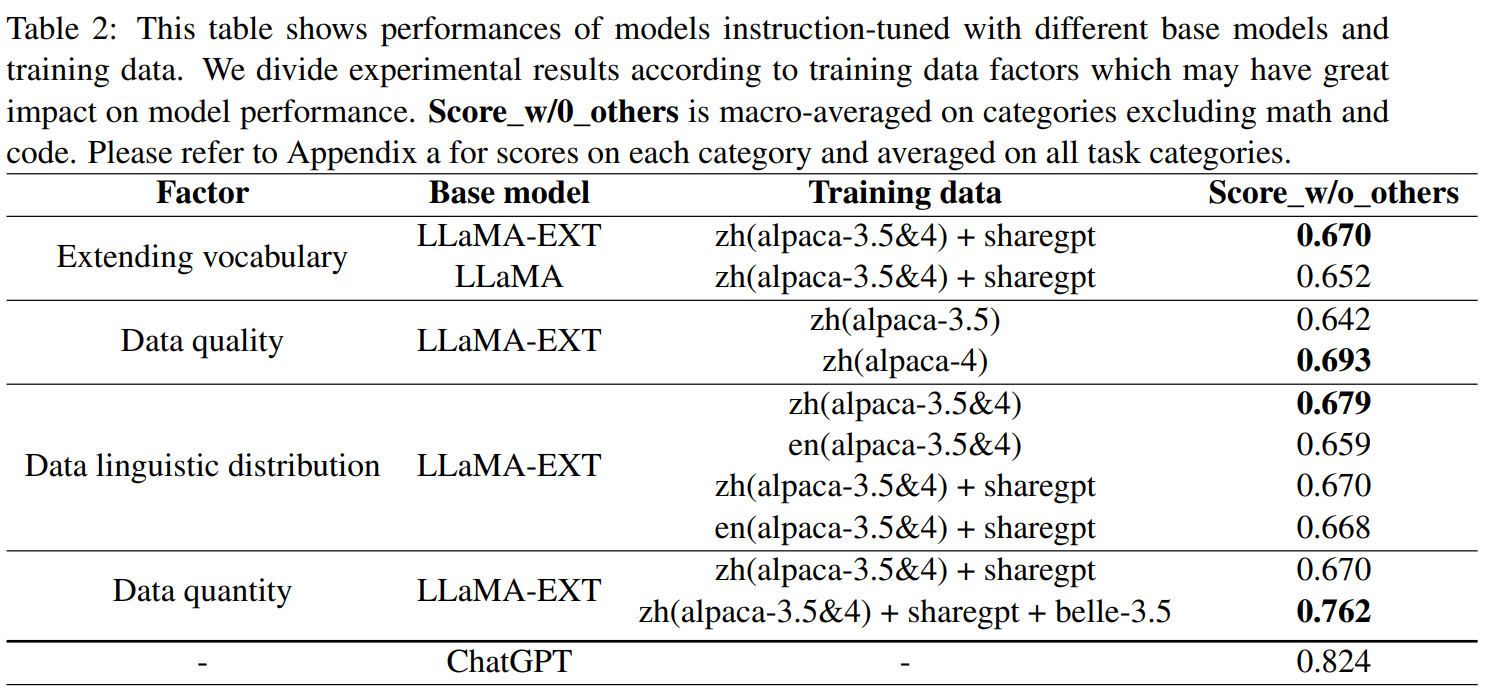

该模型和ChatGPT之间存在相当大的性能差距。考虑到ChatGPT有限的评估能力和我们评估数据的不完整性,预计这些差距可能比在评估集中观察到的分数差异还要大。这也是我们坚持改进我们模型的动力。
总之,本研究通过研究各种训练数据因素的影响,如数量、质量和语言分布,来满足对开源对话模型全面评估的日益增长的需求。通过利用可公开获取的高质量的内部结构数据集和中文多轮转换,我们在9个真实世界场景的1000个样本的评估集上评估了不同的模型。我们还总结了建立一个综合评价数据集的几个挑战,并论证了优先发展这种评价集的必要性。此外,本研究扩展了LLaMA的词汇量,并使用34亿中文词汇进行了二次预训练,以提高其在中文领域的性能和效率。这使得训练和推理的时间减少了60%,而没有牺牲性能。通过公开提供模型、数据和代码,这项研究为开源社区正在进行的努力做出了贡献,特别是为中文开发了更多可获得的、高效的对话模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号