
更简易的机器学习-pycaret的安装和环境初始化
1、安装
pip install pycaret
在谷歌colab中还要运行:
from pycaret.utils import enable_colab enable_colab()
2、获取数据
(1)利用pandas库加载
import pandas as pd data = pd.read_csv('c:/path_to_data/file.csv')
(2)使用自带的数据
from pycaret.datasets import get_data data = get_data('juice')
数据集列表:
| Dataset | Data Types | Default Task | Target Variable | # Instances | # Attributes |
| anomaly | Multivariate | Anomaly Detection | None | 1000 | 10 |
| france | Multivariate | Association Rule Mining | InvoiceNo, Description | 8557 | 8 |
| germany | Multivariate | Association Rule Mining | InvoiceNo, Description | 9495 | 8 |
| bank | Multivariate | Classification (Binary) | deposit | 45211 | 17 |
| blood | Multivariate | Classification (Binary) | Class | 748 | 5 |
| cancer | Multivariate | Classification (Binary) | Class | 683 | 10 |
| credit | Multivariate | Classification (Binary) | default | 24000 | 24 |
| diabetes | Multivariate | Classification (Binary) | Class variable | 768 | 9 |
| electrical_grid | Multivariate | Classification (Binary) | stabf | 10000 | 14 |
| employee | Multivariate | Classification (Binary) | left | 14999 | 10 |
| heart | Multivariate | Classification (Binary) | DEATH | 200 | 16 |
| heart_disease | Multivariate | Classification (Binary) | Disease | 270 | 14 |
| hepatitis | Multivariate | Classification (Binary) | Class | 154 | 32 |
| income | Multivariate | Classification (Binary) | income >50K | 32561 | 14 |
| juice | Multivariate | Classification (Binary) | Purchase | 1070 | 15 |
| nba | Multivariate | Classification (Binary) | TARGET_5Yrs | 1340 | 21 |
| wine | Multivariate | Classification (Binary) | type | 6498 | 13 |
| telescope | Multivariate | Classification (Binary) | Class | 19020 | 11 |
| glass | Multivariate | Classification (Multiclass) | Type | 214 | 10 |
| iris | Multivariate | Classification (Multiclass) | species | 150 | 5 |
| poker | Multivariate | Classification (Multiclass) | CLASS | 100000 | 11 |
| questions | Multivariate | Classification (Multiclass) | Next_Question | 499 | 4 |
| satellite | Multivariate | Classification (Multiclass) | Class | 6435 | 37 |
| asia_gdp | Multivariate | Clustering | None | 40 | 11 |
| elections | Multivariate | Clustering | None | 3195 | 54 |
| Multivariate | Clustering | None | 7050 | 12 | |
| ipl | Multivariate | Clustering | None | 153 | 25 |
| jewellery | Multivariate | Clustering | None | 505 | 4 |
| mice | Multivariate | Clustering | None | 1080 | 82 |
| migration | Multivariate | Clustering | None | 233 | 12 |
| perfume | Multivariate | Clustering | None | 20 | 29 |
| pokemon | Multivariate | Clustering | None | 800 | 13 |
| population | Multivariate | Clustering | None | 255 | 56 |
| public_health | Multivariate | Clustering | None | 224 | 21 |
| seeds | Multivariate | Clustering | None | 210 | 7 |
| wholesale | Multivariate | Clustering | None | 440 | 8 |
| tweets | Text | NLP | tweet | 8594 | 2 |
| amazon | Text | NLP / Classification | reviewText | 20000 | 2 |
| kiva | Text | NLP / Classification | en | 6818 | 7 |
| spx | Text | NLP / Regression | text | 874 | 4 |
| wikipedia | Text | NLP / Classification | Text | 500 | 3 |
| automobile | Multivariate | Regression | price | 202 | 26 |
| bike | Multivariate | Regression | cnt | 17379 | 15 |
| boston | Multivariate | Regression | medv | 506 | 14 |
| concrete | Multivariate | Regression | strength | 1030 | 9 |
| diamond | Multivariate | Regression | Price | 6000 | 8 |
| energy | Multivariate | Regression | Heating Load / Cooling Load | 768 | 10 |
| forest | Multivariate | Regression | area | 517 | 13 |
| gold | Multivariate | Regression | Gold_T+22 | 2558 | 121 |
| house | Multivariate | Regression | SalePrice | 1461 | 81 |
| insurance | Multivariate | Regression | charges | 1338 | 7 |
| parkinsons | Multivariate | Regression | PPE | 5875 | 22 |
| traffic | Multivariate | Regression | traffic_volume | 48204 | 8 |
3、设置环境
(1)第一步:导入模块
pycaret提供以下6种模块,当你导入相应的模块之后,就将环境切换到了该环境下。
| S.No | Module | How to Import |
| 1 | Classification | from pycaret.classification import * |
| 2 | Regression | from pycaret.regression import * |
| 3 | Clustering | from pycaret.clustering import * |
| 4 | Anomaly Detection | from pycaret.anomaly import * |
| 5 | Natural Language Processing | from pycaret.nlp import * |
| 6 | Association Rule Mining | from pycaret.arules import * |
(2)第二步:初始化设置
对于PyCaret中的所有模块都是通用的,设置是开始任何机器学习实验的第一步,也是唯一的必需步骤。 除默认情况下执行一些基本处理任务外,PyCaret还提供了广泛的预处理功能,这些功能在结构上将普通的机器学习实验提升为高级解决方案。 在本节中,我们仅介绍了设置功能的必要部分。 可以在此处找到所有预处理功能的详细信息。 下面列出的是初始化设置时PyCaret执行的基本默认任务:
数据类型推断:在PyCaret中执行的任何实验都始于确定所有特征的正确数据类型。 设置函数执行有关数据的基本推断,并执行一些下游任务,例如忽略ID和Date列,分类编码,基于PyCaret内部算法推断的数据类型的缺失值插补。 执行设置后,将出现一个对话框(请参见以下示例),其中包含所有特征及其推断的数据类型的列表。 数据类型推断通常是正确的,但是一旦出现对话框,用户应查看列表的准确性。 如果正确推断了所有数据类型,则可以按Enter键继续,否则,请键入“ quit”以停止实验。

如果您由于无法正确推断一种或多种数据类型而选择输入“退出”,则可以在setup命令中覆盖它们,方法是传递categorical_feature参数以强制分类类型,而numeric_feature参数则强制数字类型。 同样,为了忽略某些功能以成为实验的一部分,您可以在设置程序中传递ignore_features参数。
注意:如果您不希望PyCaret显示确认数据类型的对话框,则可以在设置过程中以“ True”(静默)方式传递为True,以执行无人看管的实验。 我们不建议您这样做,除非您完全确定推断是正确的,或者您之前已经进行过实验,或者正在使用numeric_feature和categorical_feature参数覆盖数据类型。
数据清理和准备:设置功能会自动执行缺失值插补和分类编码,因为它们对于任何机器学习实验都是必不可少的。 默认情况下,平均值用于数字特征的插补,而最频繁使用的值或模式用于分类特征。 您可以使用numeric_imputation和categorical_imputation参数来更改方法。 对于分类问题,如果目标不是数字类型,则安装程序还将执行目标编码。
数据采样:如果样本量大于25,000,PyCaret会根据不同的样本量自动构建初步的线性模型,并提供可视化效果,以根据样本量显示模型的性能。 然后可以使用该图来评估模型的性能是否随样本数量的增加而增加。 如果不是,您可以选择较小的样本量,以提高实验的效率和性能。 请参见下面的示例,在该示例中,我们使用了pycaret存储库中的“银行”数据集,其中包含45,211个样本。
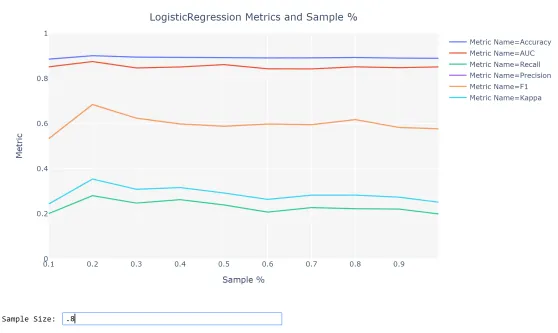
训练测试拆分:设置功能还执行训练测试拆分(针对分类问题进行了分层)。 默认的分割比例为70:30,但是您可以在设置程序中使用train_size参数进行更改。 仅在Train set上使用k倍交叉验证,才能对PyCaret中已训练好的机器学习模型和超参数优化进行评估。
将会话ID分配为种子:如果未传递session_id参数,则会话ID是默认生成的伪随机数。 PyCaret将此id作为种子分发给所有函数,以隔离随机效应。 这样可以在以后在相同或不同的环境中实现可重现性。
以下是一些例子:
分类:
from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable')

回归:
from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv')

聚类:
from pycaret.datasets import get_data jewellery = get_data('jewellery') # Importing module and initializing setup from pycaret.clustering import * clu1 = setup(data = jewellery)

异常检测:
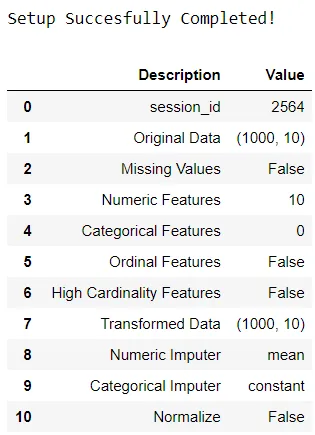
from pycaret.datasets import get_data anomalies = get_data('anomaly') # Importing module and initializing setup from pycaret.anomaly import * ano1 = setup(data = anomalies)
自然语言处理:
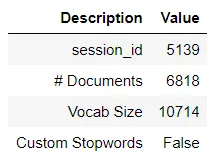
from pycaret.datasets import get_data kiva = get_data('kiva') # Importing module and initializing setup from pycaret.nlp import * nlp1 = setup(data = kiva, target = 'en')
关联规则挖掘:
from pycaret.datasets import get_data france = get_data('france') # Importing module and initializing setup from pycaret.arules import * arules1 = setup(data = france, transaction_id = 'InvoiceNo', item_id = 'Description')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号