
【猫狗数据集】划分验证集并边训练边验证
数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
进行训练:https://www.cnblogs.com/xiximayou/p/12448300.html
保存模型并继续进行训练:https://www.cnblogs.com/xiximayou/p/12452624.html
加载保存的模型并测试:https://www.cnblogs.com/xiximayou/p/12459499.html
epoch、batchsize、step之间的关系:https://www.cnblogs.com/xiximayou/p/12405485.html
一般来说,数据集都会被划分为三个部分:训练集、验证集和测试集。其中验证集主要是在训练的过程中观察整个网络的训练情况,避免过拟合等等。
之前我们有了训练集:20250张,测试集:4750张。本节我们要从训练集中划分出一部分数据充当验证集。
之前是在windows下进行划分的,接下来我们要在谷歌colab中进行操作。在utils新建一个文件split.py
import random import os import shutil import glob path='/content/drive/My Drive/colab notebooks/data/dogcat' train_path=path+'/train' val_path=path+'/val' test_path=path+'/test' def split_train_test(fileDir,tarDir): if not os.path.exists(tarDir): os.makedirs(tarDir) pathDir = os.listdir(fileDir) #取图片的原始路径 filenumber=len(pathDir) rate=0.1 #自定义抽取图片的比例,比方说100张抽10张,那就是0.1 picknumber=int(filenumber*rate) #按照rate比例从文件夹中取一定数量图片 sample = random.sample(pathDir, picknumber) #随机选取picknumber数量的样本图片 print("=========开始移动图片============") for name in sample: shutil.move(fileDir+name, tarDir+name) print("=========移动图片完成============") split_train_test(train_path+'/dog/',val_path+'/dog/') split_train_test(train_path+'/cat/',val_path+'/cat/') print("验证集狗共:{}张图片".format(len(glob.glob(val_path+"/dog/*.jpg")))) print("验证集猫共:{}张图片".format(len(glob.glob(val_path+"/cat/*.jpg")))) print("训练集狗共:{}张图片".format(len(glob.glob(train_path+"/dog/*.jpg")))) print("训练集猫共:{}张图片".format(len(glob.glob(train_path+"/cat/*.jpg")))) print("测试集狗共:{}张图片".format(len(glob.glob(test_path+"/dog/*.jpg")))) print("测试集猫共:{}张图片".format(len(glob.glob(test_path+"/cat/*.jpg"))))
运行结果:
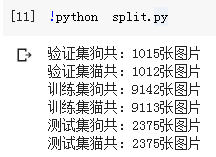
测试集是正确的,训练集和验证集和我们预想的咋不一样?可能谷歌colab不太稳定,造成数据的丢失。就这样吧,目前我们有这么多数据总不会错了,这回数据量总不会再变了吧。
为了方便起见,我们再在train目录下新建一个main.py用于统一处理:
main.py
import sys sys.path.append("/content/drive/My Drive/colab notebooks") from utils import rdata from model import resnet import torch.nn as nn import torch import numpy as np import torchvision import train np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') batch_size=128 train_loader,val_loader,test_loader=rdata.load_dataset(batch_size) model =torchvision.models.resnet18(pretrained=False) model.fc = nn.Linear(model.fc.in_features,2,bias=False) model.cuda() #定义训练的epochs num_epochs=2 #定义学习率 learning_rate=0.01 #定义损失函数 criterion=nn.CrossEntropyLoss() #定义优化方法,简单起见,就是用带动量的随机梯度下降 optimizer = torch.optim.SGD(params=model.parameters(), lr=0.1, momentum=0.9, weight_decay=1*1e-4) print("训练集有:",len(train_loader.dataset)) print("验证集有:",len(val_loader.dataset)) def main(): trainer=train.Trainer(criterion,optimizer,model) trainer.loop(num_epochs,train_loader,val_loader) main()
然后是修改了train.py中的代码
import torch class Trainer: def __init__(self,criterion,optimizer,model): self.criterion=criterion self.optimizer=optimizer self.model=model def loop(self,num_epochs,train_loader,val_loader): for epoch in range(1,num_epochs+1): self.train(train_loader,epoch,num_epochs) self.val(val_loader,epoch,num_epochs) def train(self,dataloader,epoch,num_epochs): self.model.train() with torch.enable_grad(): self._iteration_train(dataloader,epoch,num_epochs) def val(self,dataloader,epoch,num_epochs): self.model.eval() with torch.no_grad(): self._iteration_val(dataloader,epoch,num_epochs) def _iteration_train(self,dataloader,epoch,num_epochs): total_step=len(dataloader) tot_loss = 0.0 correct = 0 for i ,(images, labels) in enumerate(dataloader): images = images.cuda() labels = labels.cuda() # Forward pass outputs = self.model(images) _, preds = torch.max(outputs.data,1) loss = self.criterion(outputs, labels) # Backward and optimizer self.optimizer.zero_grad() loss.backward() self.optimizer.step() tot_loss += loss.data if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(epoch, num_epochs, i+1, total_step, loss.item())) correct += torch.sum(preds == labels.data).to(torch.float32) ### Epoch info #### epoch_loss = tot_loss/len(dataloader.dataset) print('train loss: {:.4f}'.format(epoch_loss)) epoch_acc = correct/len(dataloader.dataset) print('train acc: {:.4f}'.format(epoch_acc)) if epoch%2==0: state = { 'model': self.model.state_dict(), 'optimizer':self.optimizer.state_dict(), 'epoch': epoch, 'train_loss':epoch_loss, 'train_acc':epoch_acc, } save_path="/content/drive/My Drive/colab notebooks/output/" torch.save(state,save_path+"/"+"epoch"+str(epoch)+"-resnet18-2"+".t7") def _iteration_val(self,dataloader,epoch,num_epochs): total_step=len(dataloader) tot_loss = 0.0 correct = 0 for i ,(images, labels) in enumerate(dataloader): images = images.cuda() labels = labels.cuda() # Forward pass outputs = self.model(images) _, preds = torch.max(outputs.data,1) loss = self.criterion(outputs, labels) tot_loss += loss.data correct += torch.sum(preds == labels.data).to(torch.float32) if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(1, 1, i+1, total_step, loss.item())) ### Epoch info #### epoch_loss = tot_loss/len(dataloader.dataset) print('val loss: {:.4f}'.format(epoch_loss)) epoch_acc = correct/len(dataloader.dataset) print('val acc: {:.4f}'.format(epoch_acc))
在训练时是model.train(),同时将代码放在with torch.enable_grad()中。验证时是model.eval(),同时将代码放在with torch.no_grad()中。我们可以通过观察验证集的损失、准确率和训练集的损失、准确率进行相应的调参工作,主要是为了避免过拟合。我们设定每隔2个epoch就保存一次训练的模型。
读取数据的代码我们也要做出相应的修改了:rdata.py
from torch.utils.data import DataLoader import torchvision import torchvision.transforms as transforms import torch def load_dataset(batch_size): #预处理 train_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.ToTensor()]) val_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()]) test_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()]) path = "/content/drive/My Drive/colab notebooks/data/dogcat" train_path=path+"/train" test_path=path+"/test" val_path=path+'/val' #使用torchvision.datasets.ImageFolder读取数据集指定train和test文件夹 train_data = torchvision.datasets.ImageFolder(train_path, transform=train_transform) train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=6) val_data = torchvision.datasets.ImageFolder(val_path, transform=val_transform) val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=True, num_workers=6) test_data = torchvision.datasets.ImageFolder(test_path, transform=test_transform) test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=6) """ print(train_data.classes) #根据分的文件夹的名字来确定的类别 print(train_data.class_to_idx) #按顺序为这些类别定义索引为0,1... print(train_data.imgs) #返回从所有文件夹中得到的图片的路径以及其类别 print(test_data.classes) #根据分的文件夹的名字来确定的类别 print(test_data.class_to_idx) #按顺序为这些类别定义索引为0,1... print(test_data.imgs) #返回从所有文件夹中得到的图片的路径以及其类别 """ return train_loader,val_loader,test_loader
这里我们将batch_size当作参数进行传入,同时修改了num_works=6(难怪之前第一个epoch训练测试那么慢),然后对于验证和测试,数据增强方式与训练的时候就会不一致了,为了保持原图像,因此不能进行切割为224,而是要讲图像调整为224×224.。最后返回三个dataloader就行了,因为可以从dataloader.dataset可以获取到数据的容量大小。
最终结果:
为了再避免数据丢失的问题,我们开始的时候就打印出数据集的大小:
训练集有: 18255 验证集有: 2027 Epoch: [1/2], Step: [2/143], Loss: 2.1346 Epoch: [1/2], Step: [4/143], Loss: 4.8034 Epoch: [1/2], Step: [6/143], Loss: 8.4806 Epoch: [1/2], Step: [8/143], Loss: 3.1965 Epoch: [1/2], Step: [10/143], Loss: 1.9405 Epoch: [1/2], Step: [12/143], Loss: 1.8245 Epoch: [1/2], Step: [14/143], Loss: 1.0050 Epoch: [1/2], Step: [16/143], Loss: 0.7030 Epoch: [1/2], Step: [18/143], Loss: 0.8176 Epoch: [1/2], Step: [20/143], Loss: 0.7163 Epoch: [1/2], Step: [22/143], Loss: 1.1955 Epoch: [1/2], Step: [24/143], Loss: 0.7395 Epoch: [1/2], Step: [26/143], Loss: 0.8374 Epoch: [1/2], Step: [28/143], Loss: 1.0237 Epoch: [1/2], Step: [30/143], Loss: 0.7225 Epoch: [1/2], Step: [32/143], Loss: 0.7724 Epoch: [1/2], Step: [34/143], Loss: 1.0290 Epoch: [1/2], Step: [36/143], Loss: 0.8630 Epoch: [1/2], Step: [38/143], Loss: 0.6931 Epoch: [1/2], Step: [40/143], Loss: 0.8261 Epoch: [1/2], Step: [42/143], Loss: 0.6834 Epoch: [1/2], Step: [44/143], Loss: 0.7619 Epoch: [1/2], Step: [46/143], Loss: 0.6832 Epoch: [1/2], Step: [48/143], Loss: 0.7108 Epoch: [1/2], Step: [50/143], Loss: 0.9719 Epoch: [1/2], Step: [52/143], Loss: 0.8093 Epoch: [1/2], Step: [54/143], Loss: 0.8441 Epoch: [1/2], Step: [56/143], Loss: 0.9111 Epoch: [1/2], Step: [58/143], Loss: 0.6936 Epoch: [1/2], Step: [60/143], Loss: 0.8592 Epoch: [1/2], Step: [62/143], Loss: 0.7161 Epoch: [1/2], Step: [64/143], Loss: 0.6975 Epoch: [1/2], Step: [66/143], Loss: 0.6932 Epoch: [1/2], Step: [68/143], Loss: 1.1292 Epoch: [1/2], Step: [70/143], Loss: 0.8269 Epoch: [1/2], Step: [72/143], Loss: 0.7343 Epoch: [1/2], Step: [74/143], Loss: 0.6779 Epoch: [1/2], Step: [76/143], Loss: 0.8384 Epoch: [1/2], Step: [78/143], Loss: 0.7054 Epoch: [1/2], Step: [80/143], Loss: 0.7532 Epoch: [1/2], Step: [82/143], Loss: 0.7620 Epoch: [1/2], Step: [84/143], Loss: 0.7220 Epoch: [1/2], Step: [86/143], Loss: 0.8249 Epoch: [1/2], Step: [88/143], Loss: 0.7050 Epoch: [1/2], Step: [90/143], Loss: 0.7757 Epoch: [1/2], Step: [92/143], Loss: 0.6918 Epoch: [1/2], Step: [94/143], Loss: 0.6893 Epoch: [1/2], Step: [96/143], Loss: 0.7105 Epoch: [1/2], Step: [98/143], Loss: 0.7681 Epoch: [1/2], Step: [100/143], Loss: 0.7826 Epoch: [1/2], Step: [102/143], Loss: 0.6986 Epoch: [1/2], Step: [104/143], Loss: 0.7252 Epoch: [1/2], Step: [106/143], Loss: 0.6829 Epoch: [1/2], Step: [108/143], Loss: 0.6872 Epoch: [1/2], Step: [110/143], Loss: 0.6776 Epoch: [1/2], Step: [112/143], Loss: 0.7574 Epoch: [1/2], Step: [114/143], Loss: 0.7412 Epoch: [1/2], Step: [116/143], Loss: 0.6889 Epoch: [1/2], Step: [118/143], Loss: 0.7476 Epoch: [1/2], Step: [120/143], Loss: 0.6999 Epoch: [1/2], Step: [122/143], Loss: 0.6735 Epoch: [1/2], Step: [124/143], Loss: 0.6929 Epoch: [1/2], Step: [126/143], Loss: 0.6859 Epoch: [1/2], Step: [128/143], Loss: 0.6791 Epoch: [1/2], Step: [130/143], Loss: 0.6922 Epoch: [1/2], Step: [132/143], Loss: 0.7641 Epoch: [1/2], Step: [134/143], Loss: 0.6894 Epoch: [1/2], Step: [136/143], Loss: 0.7030 Epoch: [1/2], Step: [138/143], Loss: 0.6968 Epoch: [1/2], Step: [140/143], Loss: 0.7000 Epoch: [1/2], Step: [142/143], Loss: 0.7290 train loss: 0.0087 train acc: 0.5054 Epoch: [1/1], Step: [2/16], Loss: 0.6934 Epoch: [1/1], Step: [4/16], Loss: 0.6854 Epoch: [1/1], Step: [6/16], Loss: 0.6950 Epoch: [1/1], Step: [8/16], Loss: 0.6894 Epoch: [1/1], Step: [10/16], Loss: 0.6976 Epoch: [1/1], Step: [12/16], Loss: 0.7385 Epoch: [1/1], Step: [14/16], Loss: 0.7118 Epoch: [1/1], Step: [16/16], Loss: 0.7297 val loss: 0.0056 val acc: 0.5067 Epoch: [2/2], Step: [2/143], Loss: 0.7109 Epoch: [2/2], Step: [4/143], Loss: 0.7193 Epoch: [2/2], Step: [6/143], Loss: 0.6891 Epoch: [2/2], Step: [8/143], Loss: 0.6872 Epoch: [2/2], Step: [10/143], Loss: 0.7610 Epoch: [2/2], Step: [12/143], Loss: 0.7611 Epoch: [2/2], Step: [14/143], Loss: 0.7238 Epoch: [2/2], Step: [16/143], Loss: 0.7438 Epoch: [2/2], Step: [18/143], Loss: 0.7789 Epoch: [2/2], Step: [20/143], Loss: 0.7210 Epoch: [2/2], Step: [22/143], Loss: 0.8573 Epoch: [2/2], Step: [24/143], Loss: 0.7694 Epoch: [2/2], Step: [26/143], Loss: 0.7205 Epoch: [2/2], Step: [28/143], Loss: 0.7020 Epoch: [2/2], Step: [30/143], Loss: 0.7191 Epoch: [2/2], Step: [32/143], Loss: 0.7582 Epoch: [2/2], Step: [34/143], Loss: 0.7804 Epoch: [2/2], Step: [36/143], Loss: 0.6864 Epoch: [2/2], Step: [38/143], Loss: 0.6800 Epoch: [2/2], Step: [40/143], Loss: 0.7184 Epoch: [2/2], Step: [42/143], Loss: 0.7476 Epoch: [2/2], Step: [44/143], Loss: 0.6939 Epoch: [2/2], Step: [46/143], Loss: 0.7176 Epoch: [2/2], Step: [48/143], Loss: 0.6927 Epoch: [2/2], Step: [50/143], Loss: 0.7282 Epoch: [2/2], Step: [52/143], Loss: 0.7118 Epoch: [2/2], Step: [54/143], Loss: 0.6974 Epoch: [2/2], Step: [56/143], Loss: 0.7058 Epoch: [2/2], Step: [58/143], Loss: 0.6776 Epoch: [2/2], Step: [60/143], Loss: 0.7171 Epoch: [2/2], Step: [62/143], Loss: 0.7013 Epoch: [2/2], Step: [64/143], Loss: 0.7390 Epoch: [2/2], Step: [66/143], Loss: 0.7126 Epoch: [2/2], Step: [68/143], Loss: 0.6957 Epoch: [2/2], Step: [70/143], Loss: 0.6995 Epoch: [2/2], Step: [72/143], Loss: 0.7181 Epoch: [2/2], Step: [74/143], Loss: 0.7340 Epoch: [2/2], Step: [76/143], Loss: 0.6885 Epoch: [2/2], Step: [78/143], Loss: 0.7061 Epoch: [2/2], Step: [80/143], Loss: 0.6859 Epoch: [2/2], Step: [82/143], Loss: 0.6821 Epoch: [2/2], Step: [84/143], Loss: 0.6963 Epoch: [2/2], Step: [86/143], Loss: 0.6836 Epoch: [2/2], Step: [88/143], Loss: 0.6870 Epoch: [2/2], Step: [90/143], Loss: 0.6957 Epoch: [2/2], Step: [92/143], Loss: 0.6804 Epoch: [2/2], Step: [94/143], Loss: 0.7612 Epoch: [2/2], Step: [96/143], Loss: 0.7005 Epoch: [2/2], Step: [98/143], Loss: 0.7481 Epoch: [2/2], Step: [100/143], Loss: 0.7385 Epoch: [2/2], Step: [102/143], Loss: 0.6914 Epoch: [2/2], Step: [104/143], Loss: 0.7161 Epoch: [2/2], Step: [106/143], Loss: 0.6914 Epoch: [2/2], Step: [108/143], Loss: 0.6862 Epoch: [2/2], Step: [110/143], Loss: 0.7161 Epoch: [2/2], Step: [112/143], Loss: 0.6887 Epoch: [2/2], Step: [114/143], Loss: 0.6848 Epoch: [2/2], Step: [116/143], Loss: 0.6850 Epoch: [2/2], Step: [118/143], Loss: 0.6952 Epoch: [2/2], Step: [120/143], Loss: 0.6888 Epoch: [2/2], Step: [122/143], Loss: 0.7002 Epoch: [2/2], Step: [124/143], Loss: 0.7047 Epoch: [2/2], Step: [126/143], Loss: 0.7086 Epoch: [2/2], Step: [128/143], Loss: 0.6939 Epoch: [2/2], Step: [130/143], Loss: 0.7021 Epoch: [2/2], Step: [132/143], Loss: 0.6865 Epoch: [2/2], Step: [134/143], Loss: 0.6872 Epoch: [2/2], Step: [136/143], Loss: 0.7039 Epoch: [2/2], Step: [138/143], Loss: 0.6865 Epoch: [2/2], Step: [140/143], Loss: 0.6881 Epoch: [2/2], Step: [142/143], Loss: 0.6984 train loss: 0.0056 train acc: 0.5085 Epoch: [1/1], Step: [2/16], Loss: 0.6790 Epoch: [1/1], Step: [4/16], Loss: 0.6794 Epoch: [1/1], Step: [6/16], Loss: 0.6861 Epoch: [1/1], Step: [8/16], Loss: 0.8617 Epoch: [1/1], Step: [10/16], Loss: 0.7011 Epoch: [1/1], Step: [12/16], Loss: 0.6915 Epoch: [1/1], Step: [14/16], Loss: 0.6909 Epoch: [1/1], Step: [16/16], Loss: 0.8612 val loss: 0.0059 val acc: 0.5032
只训练了2个epoch,现在的目录结构如下:


通过验证集调整好参数之后,主要是学习率和batch_size。 然后就可以利用调整好的参数进行边训练边测试了。下一节主要就是加上学习率衰减策略以及加上边训练边测试代码。在测试的时候会保存准确率最优的那个模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号