
基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词。
很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加。系统会因此面临性能和CPU消耗的问题。
一、基于DFA敏感词算法解析
在计算理论中,确定有限状态自动机或确定有限自动机(deterministic finite automaton, DFA)是一个能实现状态转移的自动机,是表示有限个状态及在这些状态间转移和动作等行为的数学模型。
对于一个给定的属于该自动机的状态和一个属于该自动机字母表
1、DFA概念
确定有限状态自动机
- 一个非空有限的状态集合
- 一个输入字母表
- 一个转移函数
(例如:
)
- 一个开始状态
- 一个接受状态的集合



所组成的5-元组。因此一个DFA可以写成这样的形式:
DFA算法特征是:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。

简单点说就是,它是是通过event和当前的state得到下一个state,即event+state=nextstate。理解为系统中有多个节点,通过传递进入的event,来确定走哪个路由至另一个节点,而节点是有限的。
2、敏感词库构造
以王八蛋和王八羔子两个敏感词来进行描述,首先构建敏感词库,该词库名称为SensitiveMap,这两个词的二叉树构造为:
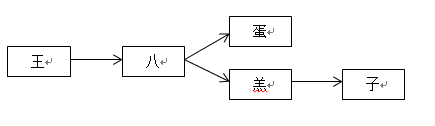
把每个敏感词字符串拆散成字符,再存储到HashMap(其他语言可用字典实现hashmap)中,可以这样保存:
{ "王": { "isend": False, "八": { "isend": False, "蛋": { "isend": True, }, "羔": { "isend": False, "子": { "isend": True, } }, } } }
将每个词的第一个字符作为key,vlue则是另一个HashMap,value对应的HashMap的key为第二个字符,如果还有第三个字符,则存储到以第二个字符为key的value中,当然这个value还是一个HashMap,以此类推下去,直到最后一个字符,当然最后一个字符对应的value也是HashMap,只不过这个HashMap只需要存储一个结束标志就行了。
3、基于敏感词库搜索算法
以上面例子构造出来的SensitiveMap为敏感词库进行示意,假设这里输入的关键字为:王八不好,流程图如下:
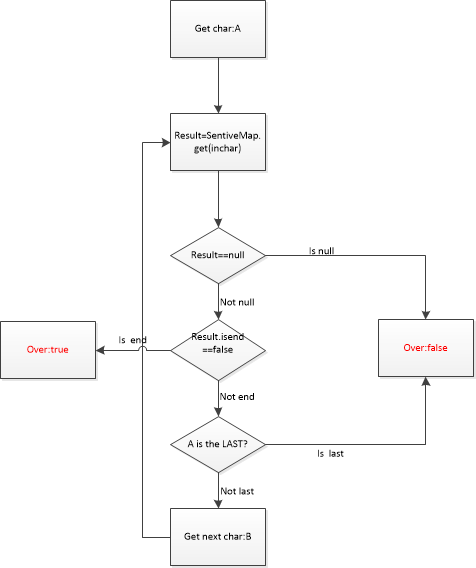
使用HashMap存储的好处:HashMap在理想情况下可以以O(1)的时间复杂度进行查询,所以在遍历待检测字符串的过程中,可以以O(1)的时间复杂度检索出当前字符是否在敏感词库中,大大提升效率。
二、JavaScript RegExp 对象
JavaScript有两种方式创建一个正则表达式:第一种方式是直接通过字面量 /{正则表达式}/{flags} 写出来,第二种方式是通过new RegExp('正则表达式')创建一个RegExp对象。
注意:这两种方法的正则表达式写法是一致的。区别仅仅是字面量的参数不使用引号,而构造函数的参数使用引号。
>var re1 = /ABC\-001/; >re1 /ABC\-001/ >var re2 = new RegExp('ABC\\-001'); >re2 /ABC\-001/ >var re = /^\d{3}\-\d{3,8}$/; >re.test('010-3945') true >re.test('010-3945x') false
1、创建 RegExp 对象语法
new RegExp(pattern [, flags]) RegExp(pattern [, flags])
参数 pattern 是一个字符串,指定了正则表达式的模式或其他正则表达式。
参数 flags 是一个可选的字符串,包含属性 "g"、"i" 和 "m"等,分别用于指定全局匹配、区分大小写的匹配和多行匹配。ECMAScript 标准化之前,不支持 m 属性。如果 pattern 是正则表达式,而不是字符串,则必须省略该参数。
// flags可以为如下值的任意组合 g:全局匹配;找到所有匹配,而不是在第一个匹配后停止 i:忽略大小写 m:多行; 将开始和结束字符(^和$)视为在多行上工作(也就是,分别匹配每一行的开始和结束(由 \n 或 \r 分割),而不只是只匹配整个输入字符串的最开始和最末尾处。 u:Unicode; 将模式视为Unicode序列点的序列 y:粘性匹配; 仅匹配目标字符串中此正则表达式的lastIndex属性指示的索引(并且不尝试从任何后续的索引匹配)。
2、返回值和抛出
(1)返回值
一个新的 RegExp 对象,具有指定的模式和标志。如果参数 pattern 是正则表达式而不是字符串,那么 RegExp() 构造函数将用与指定的 RegExp 相同的模式和标志创建一个新的 RegExp 对象。
如果不用 new 运算符,而将 RegExp() 作为函数调用,那么它的行为与用 new 运算符调用时一样,只是当 pattern 是正则表达式时,它只返回 pattern,而不再创建一个新的 RegExp 对象。
(2)抛出
SyntaxError - 如果 pattern 不是合法的正则表达式,或 attributes 含有 "g"、"i" 和 "m" 之外的字符,抛出该异常。
TypeError - 如果 pattern 是 RegExp 对象,但没有省略 attributes 参数,抛出该异常。
3、RegExp对象方法
(1)test()方法
test()方法用于检测一个字符串是否匹配某个模式,测试当前正则是否能匹配目标字符串。
let RegExpObject = new RegExp(partern, flags) RegExpObject.test('要检测的字符串')
如果要检测的字符串 string 中含有与 RegExpObject 匹配的文本,则返回 true ,否则返回 false。测试效果如下:
>>var str = "我是大佬"; >>var patt1 = new RegExp("大佬", 'g'); >>var result = patt1.test(str); true
由上例可以看出,可以使用RegExp来检查敏感字段。
(2)exec()方法
exec()方法用于检索字符串中的正则表达式的匹配,在目标字符串中执行一次正则匹配操作。。
RegExpObject.exec(string)
string是要检索的字符串,返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
exec() 方法的功能非常强大,它是一个通用的方法,而且使用起来也比 test() 方法以及支持正则表达式的 String 对象的方法更为复杂。
(3)compile()方法
compile() 方法被用于在脚本执行过程中(重新)编译正则表达式。与RegExp构造函数基本一样。
该特性已经从 Web 标准中删除,虽然一些浏览器目前仍然支持它,但也许会在未来的某个时间停止支持,略。
三、Vue前端项目中实现
1、获取敏感词列表
在github上获取到1w+敏感词库:https://github.com/observerss/textfilter
由于该词库是一行行填写在里面不方便处理,使用python转换为列表格式:
with open('keywords', 'r') as f: word_list = [] obj = f.readlines() for i in obj: i = i.strip("\n") word_list.append(i) print(word_list) f.close() with open('keywords.txt', 'w') as wf: wf.write(str(word_list))
2、对敏感词库处理和查询
选择在vue项目中创建文件:./src/assets/js/sensitiveWord.js
(1)构造敏感词map数据结构
export function makeSensitiveMap() { var result = {}; var count = sensitiveWordList.length; // 依次取字 for (var i = 0; i < count; ++i) { var map = result; var word = sensitiveWordList[i]; // 依次获取字 for (var j = 0; j < word.length; ++j) { var ch = word.charAt(j); // charAt() 方法可返回指定位置的字符。 // 判断是否存在 if (typeof(map[ch]) != "undefined") { map = map[ch]; if (map["empty"]) { break; } } else { if (map["empty"]) { delete map["empty"]; } map[ch] = {"empty":true}; map = map[ch]; } } } return result; }
(2)检查敏感词存在
export function checkSensitiveWord (sensitiveMap, sentence) { let result = []; let count = sentence.length; let stack = []; let point = sensitiveMap; for (var i=0; i<count; i++) { var ch = sentence.charAt(i); var item = point[ch]; if (typeof(item) == "undefined") { i = i - stack.length; stack = []; point = sensitiveMap; } else if (item["empty"]) { stack.push(ch); result.push(stack.join("")); stack = []; point = sensitiveMap; } else { stack.push(ch); point = item; } } return result; }
(3)敏感词列表
export const sensitiveWordList = [各种敏感词内容]
3、使用vee-validate自定义验证敏感词
在vue项目 /src/main.js 添加如下内容:
import VeeValidate, {Validator} from 'vee-validate';
import veeMessage from 'vee-validate/dist/locale/zh_CN';
import {sensitiveWordList, makeSensitiveMap, checkSensitiveWord} from './assets/js/sensitiveWord';
// 添加表单验证
Vue.use(VeeValidate, {
classes: true,
classNames: {
valid: 'is-valid',
invalid: 'is-invalid'
}
});
Validator.localize('zh_CN', veeMessage);
// 自定义敏感词过滤
const sensitiveWordRule = {
getMessage: (field, args) => field + '敏感字段',
validate: (value, args) => {
let sensitiveMap = makeSensitiveMap(sensitiveWordList);
console.log('sensitivemap', sensitiveMap);
if (checkSensitiveWord(sensitiveMap, value).length > 0) {
console.log(checkSensitiveWord(sensitiveMap, value))
return false;
} else {
console.log(checkSensitiveWord(sensitiveMap, value))
return true;
}
}
};
Validator.extend('sensitiveWordFilter', sensitiveWordRule);
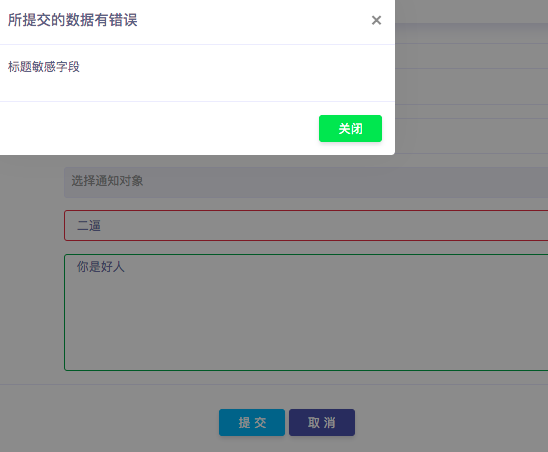
使用自定义验证规则:
<div class="form-group"> <div class="row align-items-center"> <label class="col-sm-3">*标题</label> <div class="col-sm-9"> <input type="text" class="form-control" id="title" v-model="queryInfo.title" v-validate="'required|sensitiveWordFilter'" name="title" data-vv-as="标题"> </div> </div> </div> <div class="form-group"> <div class="row "> <label class="col-sm-3">*内容</label> <div class="col-sm-9"> <textarea rows="10" class="form-control" id="content" v-model="queryInfo.content.text" v-validate="'required|sensitiveWordFilter'" name="content" data-vv-as="内容"></textarea> </div> </div> </div>
显示效果如下所示:
4、在vue单页面组件过滤并替换敏感词
在发帖、发评论等场景,查询到敏感词时替换为”*“。
<template>
<div style="padding-bottom: 30px;">
<textarea class="form-control" placeholder="课堂交流,欢迎大家" v-model="newPosts.content.text"></textarea>
<button type="button" class="btn btn-primary btn-sm pull-right" @click="addPosts"> 发送</button>
</div>
<div style="padding-bottom: 35px;">
<textarea class="form-control" placeholder="输入笔记" v-model="newNote.remark"></textarea>
<button type="button" class="btn btn-primary btn-sm pull-right" @click="addNote"> 记笔记</button>
</div>
</template>
<script>
import {sensitiveWordList, makeSensitiveMap, checkSensitiveWord} from '../../assets/js/sensitiveWord';
export default {
methods: {
wordFilter: function (content) {
// 过滤出敏感词用*替换
console.log(content);
let inputContent = content;
let sensitiveMap = makeSensitiveMap(sensitiveWordList);
let needUpdateWordList = checkSensitiveWord(sensitiveMap, inputContent);
console.log(needUpdateWordList);
for (var i=0; i < needUpdateWordList.length; i++) {
// 创建正则表达式
let r = new RegExp(needUpdateWordList[i], 'ig');
inputContent =inputContent.replace(r, "*")
}
console.log(inputContent);
return inputContent
},
addPosts: function () {
var self = this;
// 检查更新发送的内容
this.newPosts.content.text = this.$options.methods.wordFilter(this.newPosts.content.text); // 调用methods中的另一个方法
this.$httpPost(this.$http, '接口信息', this.newPosts, "", function(ret){});
},
addNote: function () {
var self = this;
// 检查更新发送的内容
this.newNote.remark = this.$options.methods.wordFilter(this.newNote.remark); // 调用methods中的另一个方法
this.$httpPost(this.$http, '接口信息', this.newNote, "", function(ret){});
},
}
}
</script>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号