python面试题(实时更新)
1.以下代码输出为:
list1 = {'1':1,'2':2}
list2 = list1
list1['1'] = 5
sum = list1['1'] + list2['1']
print(sum)
解析:10
print('HelloWorld!') print('__name__value: ', __name__) def main(): print('This message is from main function') if __name__ =='__main__': main()
print_module.py的代码如下:
import print_func print("Done!")
运行print_module.py程序,结果是:
Hello World! __name__ value: print_module Done!
解析:
A _foo 不能直接用于’from module import *’ B __foo解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名 C __foo__代表python里特殊方法专用的标识 D __foo 可以直接用于’from module import *’
编码:decode()
解码:encode()
url编码:urllib.quote()
解码过程(与编码过程相反):
解码 url -> utf-16 -> gbk
A 使用recvfrom()接收TCP数据
B 使用getsockname()获取连接套接字的远程地址
C 使用connect()初始化TCP服务器连接
D 服务端使用listen()开始TCP监听
解析:
sk.recv(bufsize[,flag]):接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.connect(address):连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.listen(backlog):开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
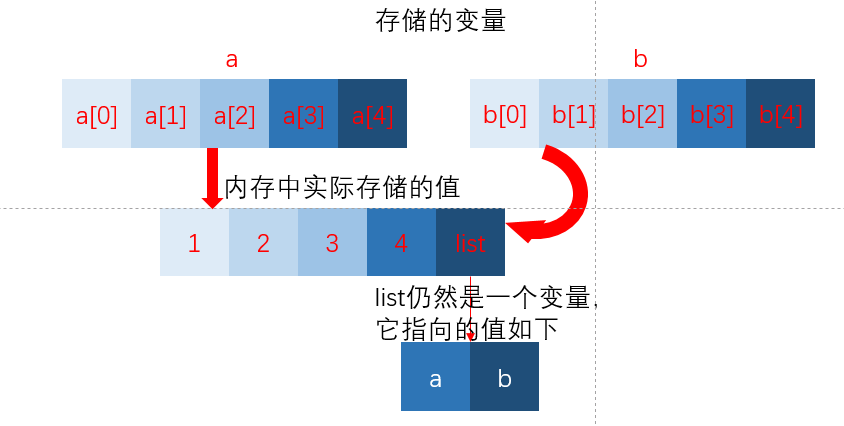
import copy
a = [1, 2, 3, 4, ['a', 'b']]
b = a
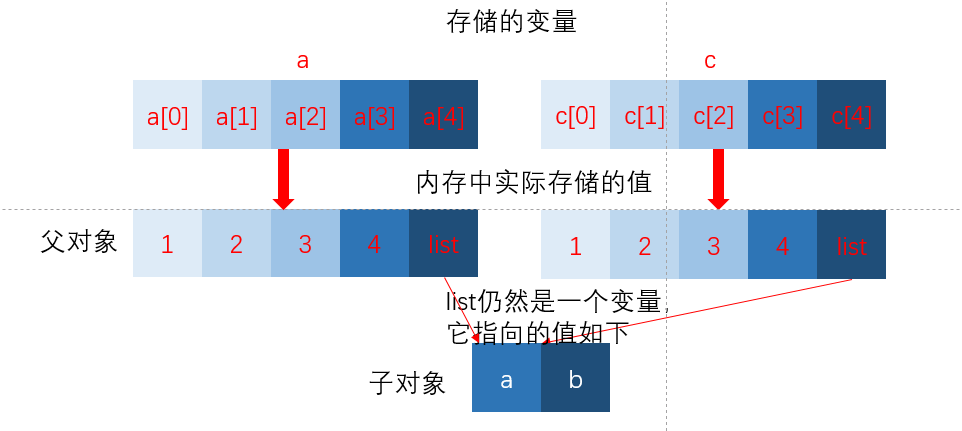
c = copy.copy(a)
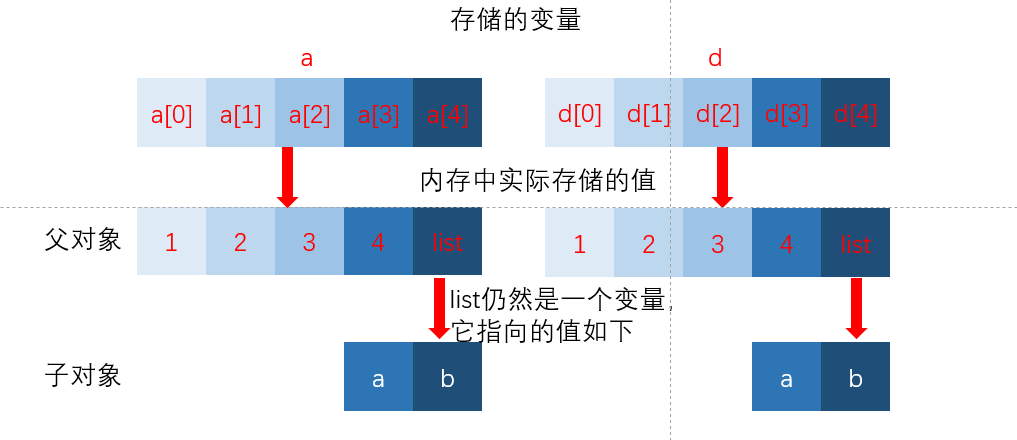
d = copy.deepcopy(a)
a.append(5)
a[4].append('c')
a == [1,2, 3, 4, ['a', 'b', 'c'], 5]
b == [1,2, 3, 4, ['a', 'b', 'c'], 5]
c == [1,2, 3, 4, ['a', 'b', 'c']]
d == [1,2, 3, 4, ['a', 'b', ‘c’]]
解析:

首先我们看看看b的情况,b实际上和a指向的是同一个值,就好比人的大名和小名,只是叫法不同,但还是同一个人
接下来再看看c的情况,c的情况和a.copy()的情况是一样的,都是我们所谓的浅拷贝(浅复制),浅拷贝只会拷贝父对象,不会拷贝子对象,通俗的说就是只会拷贝到第二层
8.请说明装饰器的作用?
装饰器的本质上是一个python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象,他经常用于有切面需求的场景,比如,插入日志,性能测试,事务处理,缓存,权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用,概括的讲,装饰器的作用就是为了已经存在的对象添加额外的功能。
常见的装饰器:类装饰器,函数装饰器
类装饰器,相比函数装饰器,类装饰器具有灵活度大,高内聚,封装性等优点。
9.乐观锁和悲观锁的区别?
悲观锁:顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其他线程阻塞,用完再把资源转让给其他线程),传统的关系型数据库里边就用到很多这种锁机制,比如行锁,表锁,读锁,写锁等,都是在操作之前先上锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都会认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐率。
两种锁的使用场景:
从上边两种锁的介绍,我们知道两种锁各有优缺点,乐观锁适用于多读的场景,这样可以省去锁的开销,加大系统整个的吞吐率,但是如果是多写的情况下,一般会产生冲突,这就会导致上层应用会不断的进行重试,这样反倒是降低了性能,所以一般多写的场景下使用悲观锁就比较合适。
补充:
CAS算法:
就是一种无锁算法,无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量同步,所以也叫非阻塞同步。
CAS算法涉及到的三个操作数:
- 需要读写的内存值V
- 进行比较的值A
- 拟写入的新值B
当且仅当V的值等于A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作,一般情况下是一个自旋操作,即不断的重试。
乐观锁的缺点:
- ABA问题
- 自选时间CP开销大
10.什么是协程?与进程和线程有什么区别?
协程是一种用户态的轻量级线程,协程的调度完全由用户控制,具有对内核来说不可变的特性。
因为是自主开辟的异步任务,所以也可以叫做纤程,正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程的目的:在传统的系统中都是基于每个请求占用一个线程去完成整个的业务逻辑(包括事务),所以系统的吞吐能力取决于每个线程的操作耗时,如果遇到很耗时的IO行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底。而协程的目的就是当出现长时间的IO操作的时候,通过让出目前 的协程调度,执行下一个任务的方式,来消除上下文切换上的开销。
协程的特点:
线程的切换由操作系统负责调度,协程由用户自己调度,因此减少了上下文切换,提高了效率。
线程的默认栈大小是1M,而协程更轻量,接近1K,因此可以在相同的内存中开启更多的协程。
由于在同一个线程上,因此可以避免竞争关系而使用锁。
适用于被阻塞的,且需要大量开发并发的场景,但是不适用于大量计算的多线程,遇到此种情况,更好使用线程去解决。
协程和进程线程的区别:
- 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
- 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是这样的)。
- 协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
- 一个应用程序一般对应一个进程,一个进程一般有一个主线程,还有若干个辅助线程,线程之间是平行运行的,在线程里面可以开启协程,让程序在特定的时间内运行。
- 协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。
11.python的zip()函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
实例:
1 a = [1,2,3] 2 b = [4,5,6] 3 c = [4,5,6,7,8] 4 zipped = zip(a,b) # 打包为元组的列表 5 [(1, 4), (2, 5), (3, 6)] 6 zip(a,c) # 元素个数与最短的列表一致 7 [(1, 4), (2, 5), (3, 6)] 8 zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式 9 [(1, 2, 3), (4, 5, 6)]
12.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号