scrapy数据解析与持久化存储
1.数据解析
-使用response.xpath("xpath表达式")
-scrapy封装的xpath和etree中的xpath区别:
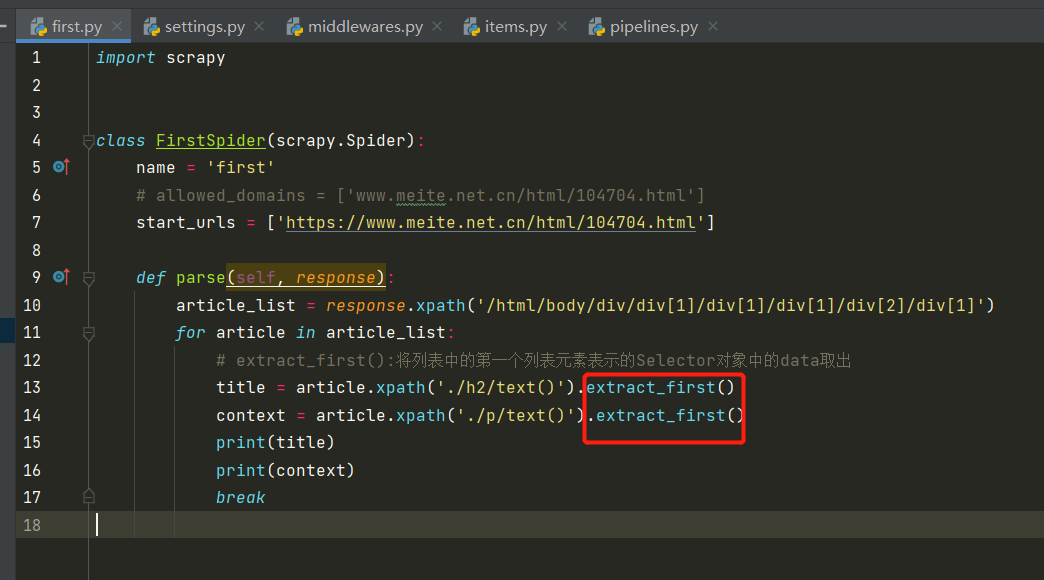
-scrapy中的xpath直接将定位到的标签中存储的值或者属性值取出,返回的Selector对象数据值是存储在Selector对象的data属性,需要调用extract、extract_first()取出
2.基于管道的持久化存储
-基于终端指令的持久化存储
-要求:该种方式只可以将parse方法的返回值存储到本地指定后缀的文本文件中
-执行命令:scrapy crawl 爬虫文件名 -0 filePath
-基于管道的持久化存储
-在爬虫文件中进行解析(如上图所示)
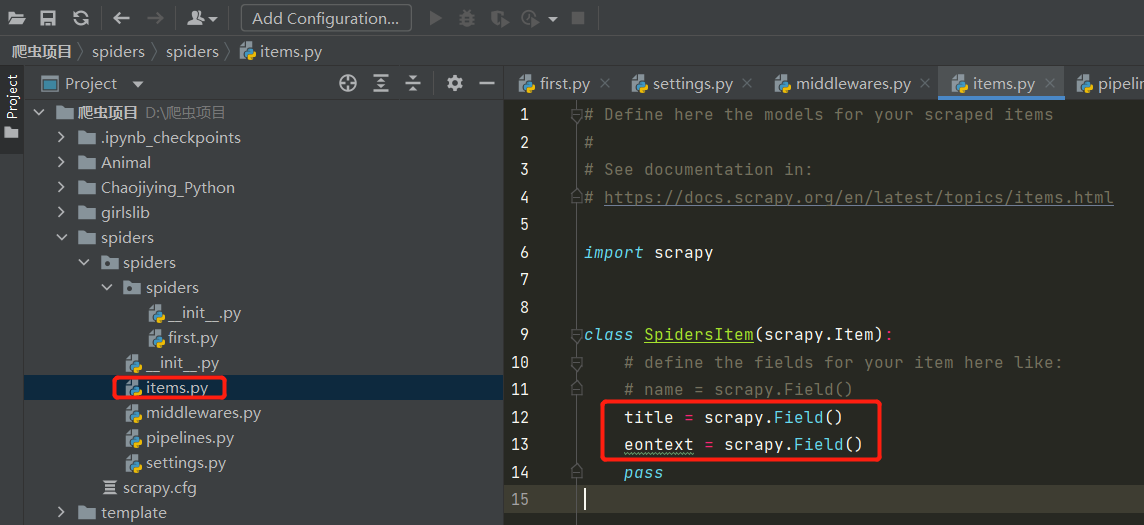
-在item.pyt中定义相关属性
-步骤1中解析了title和context字段数据,那就就定义这两个属性
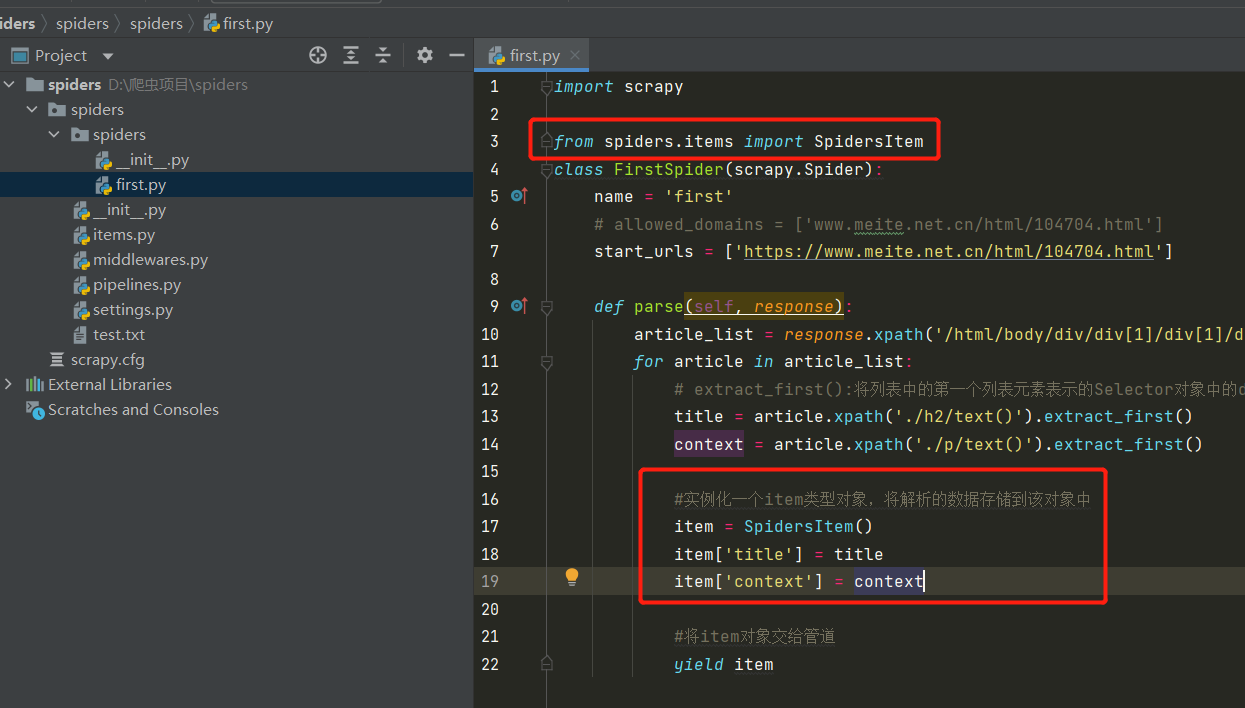
-在爬虫文件中将解析到的数据存储封装到Item类型的对象中
-将Item类型的对象提交给管道
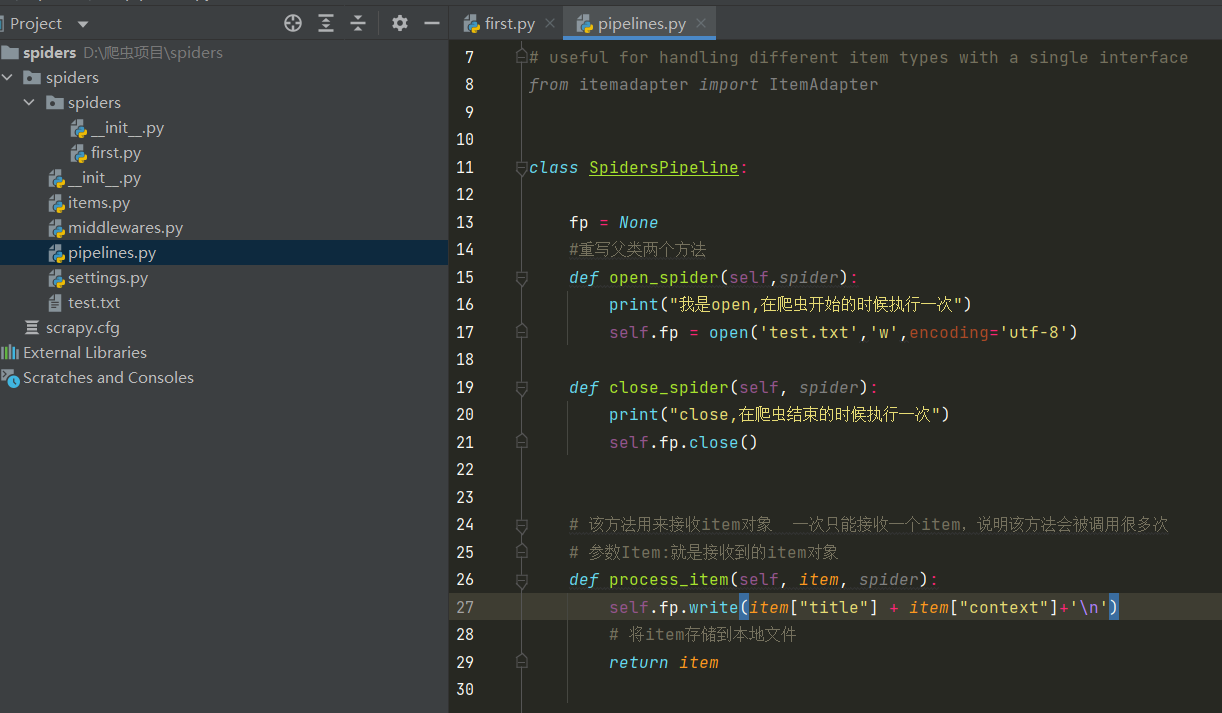
-在管道文件(pipelines.py)中,接收爬虫文件提交过来的Item类型对象,且对其进行任意形式的持久化操作
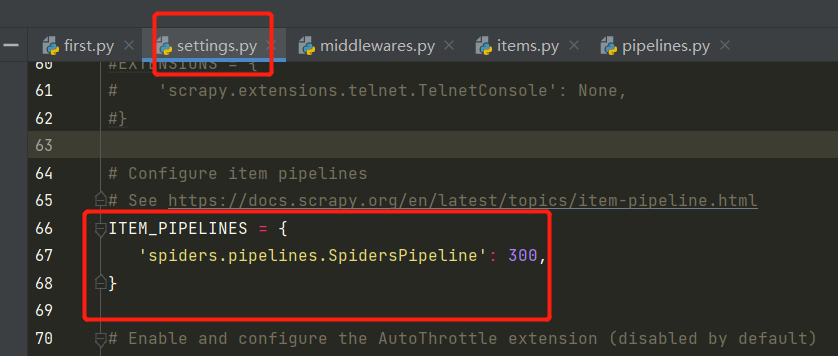
-在配置文件中开启管道机制
300表示:管道嘞优先级,数值越小,优先级越高
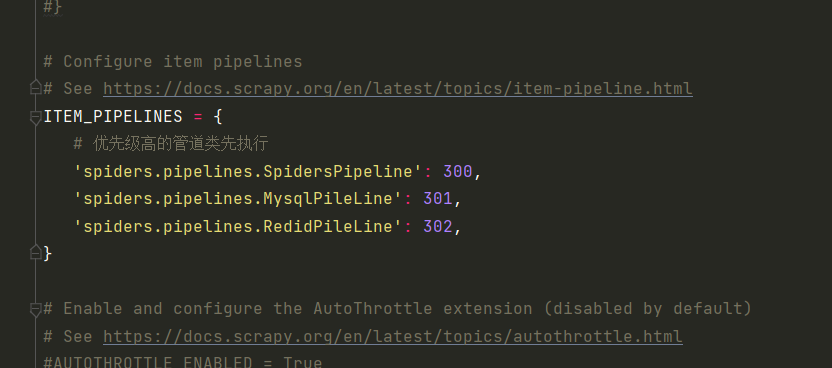
3.基于管道实现数据备份
将爬取到的数据存储到不同载体中
-将数据分别存储到mysql和redis中
-管道类文件中的一个管道类表示怎样的一组操作?
-一个管道类对应一种形式的持久化存储操作。如果将数据存储到不同的载体中就需要使用多个管道类
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter import pymysql from redis import Redis class SpidersPipeline: fp = None #重写父类两个方法 def open_spider(self,spider): print("我是open,在爬虫开始的时候执行一次") self.fp = open('test.txt','w',encoding='utf-8') def close_spider(self, spider): print("close,在爬虫结束的时候执行一次") self.fp.close() # 该方法用来接收item对象 一次只能接收一个item,说明该方法会被调用很多次 # 参数Item:就是接收到的item对象 def process_item(self, item, spider): self.fp.write(item["title"] + item["context"]+'\n') # 将item存储到本地文件 return item #将数据存储到mysql中 class MysqlPileLine(object): conn = None cursor = None def open_spider(self,spider): self.conn = pymysql.Connect(host='127.0.0.1',port='3306',user='root',password='123456',db='testdb',charset='utf-8') def process_item(self,item,spider): self.cursor = self.conn.cursor() sql = 'insert into test02 values ("%s","%s")'%(item['title'],item['context']) #事物处理 try: self.cursor.execute(sql) # 执行sql self.conn.commit() #提交 except Exception as e: self.conn.rollback() # 回退 return item def close_spider(self,spider): self.cursor.close() # 关闭游标 self.conn.close() # 关闭连接 #将数据写入redis class RedidPileLine(object): conn = None def open_spider(self,spider): self.conn = Redis(host="127.0.0.1",port=6379) print(self.conn) def process_item(self,item,spider): # 报错:将redis模块版本指定为2.10.6 pip install -U redis==2.10.6 self.conn.lpush("testdb",item)
4.scrapy手动请求发送实现全站数据爬取
-yield scrapy.Requests(url,callback):get
-yield scrapy.FromRequests(url,callback,formdata):post
为什么start_url列表的url会被自动进行get请求发送?
-因为列表中的url其实是start_requests这个父类方法实现的get请求发送
def start_requests(self): dor u in self.start_urls: yield scrapy.Request(url=u,callback=self.parse)
如何将start_urls中的url默认进行post请求的发送?
#重写start_requests方法即可 def start_requests(self): for u in self.start_urls: yield scrapy.FormRequest(url=u,callback=self.parse)
5.scrapy手动请求传参数
-实现方式
-scrappy.Requests(url,callback,meta)
-meta是一个字典,可以将meta传递给callback
-claaback取出meta:
-response.meta
import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.4567tv.tv/index.php/vod/show/id/5.html'] #定义一个通用的url模板 url = 'http://www.4567tv.tv/index.php/vod/show/id/5/page/%d.html' pageNum = 2 def parse(self, response): li_list = response.xpath('//ul[@class="stui-vodlist clearfix"]/li') for li in li_list: title = li.xpath('./div/a/@title').extract_first() detail_url = 'https://www.4567tv.tv' + li.xpath('./div/a/@href').extract_first() #实例化 item = MovieproItem() item['title'] = title # 对详情页url发起请求 #meta作用:可以将字典传递给callback yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item}) if self.pageNum < 5: new_url = format(self.url%self.pageNum) self.pageNum += 1 yield scrapy.Request(url=new_url,callback=self.parse) # 被作用于解析详情页的数据 def parse_detail(self,response): #接收传递过来的item item = response.meta['item'] desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]').extract_first() item['desc'] = desc yield item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号