
应用层2
web和http
首先介绍一些术语
1)一个web页面由很多项目(objects)组成
2)一个项目是一个诸如HTML文件或者一个JPEG图片,一个Java小程序,一个音频文件等
3)一个web页面由一个base HTML文件和若干超链接组成
4)base HTML通过URL(Uniform Resource Locators)打开超链接
5)URL示例:
www.someschool.edu/someDept/pic.gif
---------host name----- ------path name---
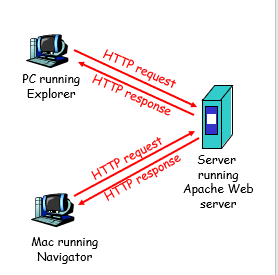
HTTP总览
HTTP: hypertext thansfer protocol 超文本传输协议
1)web的应用层协议
2)采用 客户端/服务器模式
1. 客户端: 发送requests 接收数据 展示内容
2. 服务器:收到requests的时候 resonse 这个 requests
3)HTTP1.0:RFC 1945
4) HTTP 1.1 RFC 2616
HTTP 总览2
使用TCP
1)客户端发起和服务器的TCP连接(创建sockets),使用80端口
2)服务器接受来自客户端的TCP连接
3)HTTP报文(应用层协议报文)在客户端和服务器之间交换
4)关闭TCP连接
HTTP是没有状态的 (HTTP is “stateless”)
1)服务器不保存任何关于客户端的历史信息
备注:保存状态非常复杂
1)状态必须被保存时
2)如果客户端或者服务器崩溃,他们所认为的状态可能不一致,必须得到调和
HTTP连接
非持续的HTTP连接
1)一个object通过一个TCP连接来发送
2)HTTP1.0使用非连续的HTTP连接
持续的HTTP连接
1)单个TCP连接可以发送多个object
2)一个新的web object不需要重新建立TCP连接
3)HTTP1.1 默认使用持续的HTTP连接,但是可以配置为非持续的连接
疑问:一个WEB可能包含多个object ,这些多个object是怎么样建立多个连接的呢
非持续的HTTP连接
假设用户输入有个URL
www.someSchool.edu/someDepartment/home.index 包含 文本以及10张图片的超链接
|
HTTP客户端初始化和服务器(www.someSchool.edu)进程的TCP连接 |
HTT服务器(www.someSchool.edu)等待在端口80上发起连接并接受该连接 |
| HTTP客户端通过TCP建立好的socktes发送HTTP的Request报文(包含URL)。报文指出客户端想要位于 someDepartment/home.index处的objiect | HTTP服务器接受request报文,生成response报文,包含所请求的objiect,并将生成的报文通过这个socket发送出去 |
HTTP客户端接收包含HTML文件的response
报文,展示该HTML文件,寻找这10张图片的
超链接。
重复以上过程获取这10张图片的文件
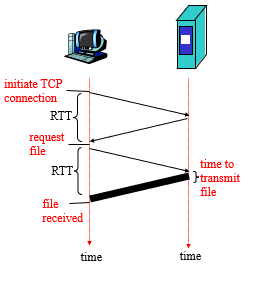
响应时间模型
定义RTT:从客户端发送一个分组到服务器到客户端接收到客户端的往返时间。
响应时间:
1)一个用来初始化TCP连接RTT时间
2)一个用来发送request和HTTP响应的少量bytes
3)文件传输时间
总时间=2*RTT+文件传输时间
持续的HTTP连接
非持续的HTTP连接的问题:
1)每个object都需要2倍的RTT时间
2)系统必须运行并分配固定资源给每个TCP连接
3)但是浏览器经常打开平行的TCP连接用来抓取超链接的内容
持续的HTTP连接
1)服务器在发送response报文后依然保持连接
2)通过一个TCP连接,一系列的HTTP报文在服务器和客户端之间传输
两种版本的持续的链接:
1)非队列的持续连接
1. 客户端在接收到上一个request的报文的response报文后才发送下一个新的request
2. 每个超链接需要用一个RTT时间
2)非队列的持续连接
1.在HTTP1.1上默认使用这种连接
2.当客户端遇到一个超链接的时候就发送request报文
3.所用的时间小于所有的RTT的合计时间
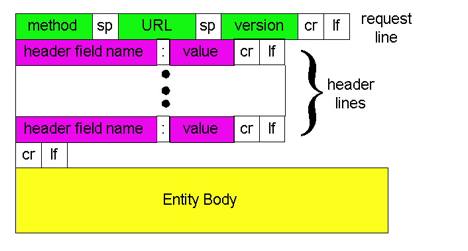
HTTP request报文
1)两种类型的HTTP报文:request response
2)HTTP request报文:
1.ASCII(人类可读的形式)

一个实例的解释

HTTP request报文: 报文格式
方法种类
HTTP1.0
1)GET:返回一个object
2)POST:发送信息存储在服务器中
3)HEAD:仅仅返回object的描述信息,比如 how old it is, 但是不返回这个object本身
HTTP1.1
1)GET POST HEAD
2)PUT:为URL指定的已经存在的文件重载一个新的副本
3)DELETE:删除URL指定的object
HTTP response报文
一个HTTP的response报文由以下内容组成:
1. 一个状态行,指示request报文请求成功或者失败
2. Header行:对response报文消息的简单描述
3. 响应报文的实际内容
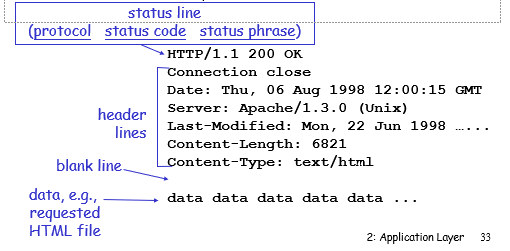
HTTP 的response报文的状态码
位于服务器response报文的第一行。
一些简单的例子如下:
200 OK
request成功,请求的内容在报文的数据部分
301 Moved Permanently
request的object已经被移除,新的位置位于报文的数据部分
400 Bad Request
服务器看不懂request报文的内容
404 Not Found
request的内容在服务器中找不到
505 HTTP Version Not Supported
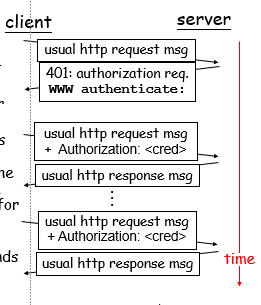
用户-服务器交互:授权
授权:控制接入服务器内容
1)典型的授权方法:账号和密码
2)无状态的情况:客户端必须在每个request报文中都包含授权信息
1. 包含授权信息:在每个request报文的头部行
2. 当浏览器保持打开状态且用户名和密码都被缓存的时候,用户不用每个request报文都提交用户名和密码。(相当于用户输入一次账户和密码之后浏览器将账号和密码缓存起来,这样下一个request报文的时候就不用用户重复输入账号和密码)
3.如果没有授权:服务器将拒绝访问
用户--服务器状态:cookies
许多的主要的web使用cookie技术
cookie技术的4个主要构成
1)和cookie相关的内容放在HTTP的response报文的头部行中
2)和cookie相关的内容放在request报文的头部行中
3)cookie文件保存在用户的host中并且被用户的浏览器管理
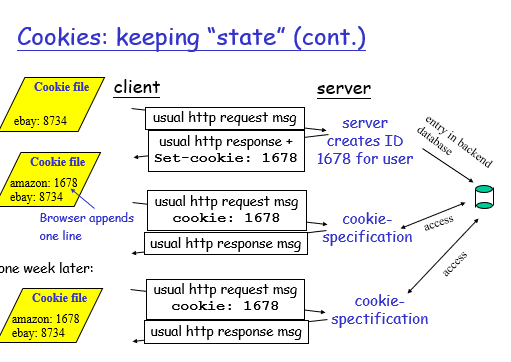
cookie的作用:
1)授权
2)购物记录
3)推荐
4)用户的浏览记录
WEB缓存 (proxy服务器 代理服务器)
回应客户端的request报文而不用涉及源服务器
1)用户设置浏览器:通过cache访问Web
2)浏览器发送所有的request到cache
1)object在cache中:cache返回该object
2)cache request这个object从源服务器,然后才返回这个object
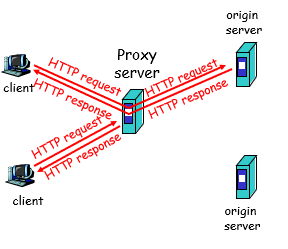
疑问:必须要用户设置通过cache访问吗
关于cache的更多知识:
1)cache即作为客户端又作为服务器
2)典型的cache是ISP安装的
为什么需要cache:
1)减少客户端的request报文的响应时间
2)减少机构的接入网的流量
3)密集的cache部署可以使得 “poor” 的内容提供商可以更加有效的交付内容(就像是P2P模式)
cache的例子:
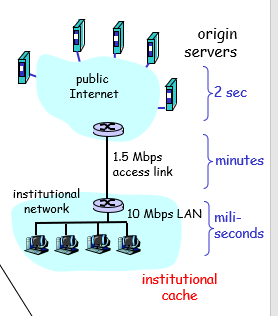
假设:
1)平均的object大小:100000bits
2)平均的request速率:从机构的浏览器到源服务器 = 15/sec
3)机构接入的核心网路由器到任何一个源服务器的延时:2sec
结果:
1)LAN的利用率:15%
2)接入网利用率:100%
3)总时延:Internet delay + access delay + LAN delay = 2s + minutes + millisecnds
minutes :因为接入网已经满载所以需要的时间比较长
可能的减小时延的方法:
1)增大接入网的带宽 郑重方法成本很高
2)安装cache
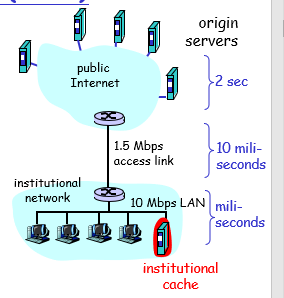
安装 cache
1)假设命中率为0.4
结论:
1)40%的request可以立即得到响应
2)60内容需要从源服务器获取
3)接入网利用率减少到60%,结果就是直接减少了时延(大概10msec)
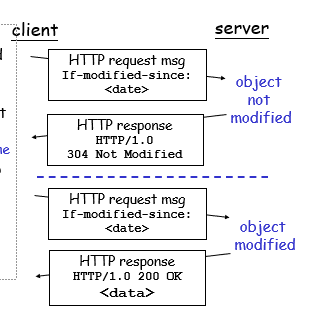
有条件的GET:客户端的caching
1)目标:不发送object如果客户端已更新了cache的版本
2)客户端:指定已经在客户端cache的request的副本。If-modified-since:<data>(a header line)
3)服务器:如果object已经是最新版本,response中不包含object
HTTP/1.0 304 Not Modified
FTP : 文件传输协议
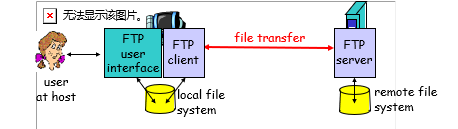
1)和远程主机之间传输文件
2)客户端/服务器模型
1.客户端:这一端发起传输(上传或者下载)
2.服务器:远程主机
3)ftp:RFC959
4)ftp服务器:port 21
FTP 分离控制和数据传输
1)FTP客户端在port21上和服务器联系,指定TCP为传输协议
2)客户端通过控制连接,传输用户名和密码 取得认证
3)客户端浏览器远程获取文件夹通过利用控制连接发送命令
4)当服务器接收到一个文件传输命令时,服务器为客户端打开一个用于传输数据的TCP连接
5)当传输完一个文件后,服务器关闭连接
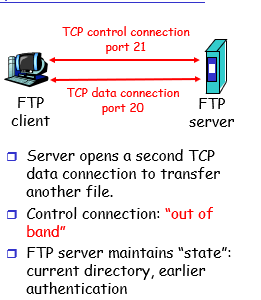
1)服务器打开第二个TCP数据连接用来传输另一个文件
2)控制连接和数据传输的链接是分开的
3)FTP服务器维持 状态:当前的文件夹 之前的认证
FTP的命令和响应
简单的命令:
通过控制连接发送ASCII形式的控制命令文本
1)USER username
2)PASS password
3)LIST -- 返回当前文件夹的所有文件
4)RETR filename -- 获取(get)文件
5)STOR filename -- 存储文件
简单的返回码
返回的代码和短语
1)311 Username OK, password required
2)125 data connection already open; transfer starting
3)425 Cant open data connection
4)452 Error writing file
电子邮件
邮件系统的三个主要部件
1)用户代理
2)邮箱服务器
3)简单的邮件传输协议 :SMTP
用户代理:
1)也叫作 “邮件阅读器”
2)生成,编辑,阅读邮件 是一个PC端的软件
3)发送和接收的邮件存储在邮件服务器上
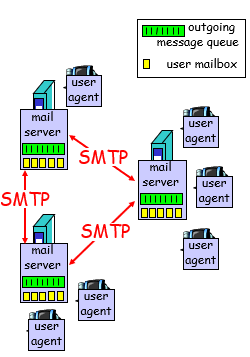
电子邮件:邮件服务器
邮件服务器:
1)mailbox 为用户保存接收到的邮件
2)message queue :存储发送的邮件
SMTP 协议
客户端:发送邮件到服务器
服务器:接收邮件的服务器
SMTP服务器
simple mail transfer protocol
1)使用TCP协议保证客户端和服务器之间的可靠传输,使用25端口
2)直接传输:从发送服务器发到接收服务器
3)传输的三个阶段:
1)握手 建立TCP连接
2)传输报文
3)结束
4)命令和响应
1)commands : ASCII文本
2)response:状态码和短语
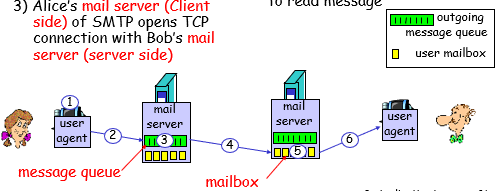
实际场景 : Alice 发送邮件给 Bob
1)Alice使用用户代理来生成邮件并且发送给 bob@someschool.edu
2)Alice 的用户代理 发送邮件到他的邮件服务器,邮件服务器将邮件放入 message queue
3)Alice的邮件服务器(此时是客户端)的SMPT打开TCP和Bob的邮件服务器的链接(此时充当服务器)
4)SMTP的客户端通过TCP连接发送Alice的邮件
5)Bob的邮件服务器将接收到的邮件放入mailbox
6)Bob通过他的客户端代理软件阅读邮件
简单的SMTP交互
下面的副本当TCP连接建立好之后开始


 浙公网安备 33010602011771号
浙公网安备 33010602011771号