

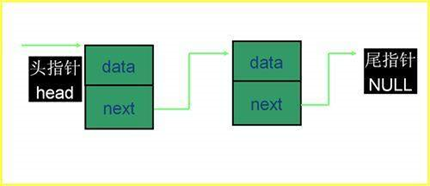
链表定义形式:
struct note
{
int data; /*数据成员可以是多个不同类型的数据*/
struct note *next; /*指针变量成员只能是一个*/
};
每个结点的数据可用一个结构体表示,该结构体由两部分成员组成:数据成员与结构指针变量成员。
链表的长度是动态的,当需要建立一个结点,就向系统申请动态分配一个存储空间,如此不断地有新结点产生,直到结构指针变量指向为空(NULL)。
申请动态分配一个存储空间的表示形式为: (struct note*) malloc(sizeof(struct note))
链表的建立:在链表建立过程中,首先要建立第一个结点,然后不断地在其尾部增加新结点,直到不需再有新结点,即尾指针指向NULL为止。
设有结构指针变量 struct note *p,*p1,*head;
Head:用来标志链表头;
P:在链表建立过程中,p总是不断先接受系统动态分配的新结点地址。
p1->next:存储新结点的地址。
双向链表在插入、删除、查找方面时间复杂度更小,更有优势。
如何基于链表实现最近最少使用策略 LRU(Least Recently Used)缓存淘汰算法?
我们维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。
当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
1. 如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2. 如果此数据没有在缓存链表中,又可以分为两种情况:
如果此时缓存未满,则将此结点直接插入到链表的头部;
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next=q。这行代码是说,p 结点中的 next 指针存储了 q 结点的内存地址。
p->next=p->next->next。这行代码表示,p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
注意:
插入结点时,一定要注意操作的顺序,防止内存泄漏
删除链表结点时,也一定要记得手动释放内存空间
用带头结点的链表能够规避:空链表的插入(p=new_node)和链表最后一个节点的删除(p=null),需单独处理


 浙公网安备 33010602011771号
浙公网安备 33010602011771号