


OO第三单元博客总结
前言
一些概念简述:
ev(G)基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
iv(G)模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
OO第三次作业:JML-模拟地铁线路图
JML语言的基础语法
什么是JML
The Java Modeling Language (JML) is a behavioral interface specification language that can be used to specify the behavior of Java modules. It combines the design by contract approach of Eiffel and the model-based specification approach of the Larch family of interface specification languages, with some elements of the refinement calculus.
---from The Java Modeling Language
上面那段话的意思就是说,Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为 。它结合了Eiffle的契约方法设计和Larch 系列接口规范语言的基于模型的规范方法,以及细化演算的一些元素。
也就是说,JML是一种规约性语言,很好的实现了设计与实现的分离。
在构造JML(即设计)的时候,设计人员只需要关心这个函数需要实现什么功能,这个变量需要按照什么逻辑改变,仅此而已,不需要考虑实现的方式。(但是需要考虑一些边界性的细节)。而在实现的时候,实现人员只需要完全按照JML所约定的去实现(即保证正确性)
基础语法
官方给出了一个简单的JML(level 0)使用手册,基础语法在里面有详细的介绍,在此不再赘述
其实JML存在的意义更多的是,给了函数一个精准的功能定义。自然语言很难严谨而不失逻辑地描述一个方法和变量的功能,而JML提供了这项技术,我认为这就是JML的理论基础
应用工具链
官方给出的唯一的相关工具只有OpenJML,其意义在于对JML注释的完整性进行检查。检查包括经典的类型检查、变量可见性与可写性等。由于目前的JML还相对比较简单,而且我们也没有写过很复杂的JML,更多的是根据JML来进行功能实现,OpenJML的强大之处也许还没有感受到。
这里附上一个安装openJML的简单链接OpenJML入门
Junit的部署与使用
Junit的部署
没啥说的,链接奉上:Idea下配置Junit
Junit的使用
其实我后文提到了我在第二次作业中使用Junit进行测试的历程。
第一次使用Junit,感官并不是太好。确实针对每一个方法编写了测试单元,但是测试单元仍然是自己编纂的数据,虽然对于懒得写文件比较器的人来说确实有方便之处,但是感觉相比于手动测试,具体的差异在哪里呢?使用Junit是否能实现随机检查呢?(因为assert语句需要知道答案,而随机数据很多的答案是无法知道的,或者使用算法计算的话,那根源代码就没有很多的差异了),所以我用Junit更多的是找到其他写了Junit的人,然后互相测试。
----from 后文
我这里截一两个Junit的图作为声明,并且举一个对于最短路径的例子吧。
首先是junit里关于最短路径的一个简单测试,分别测试了在一条path里的最短路径,相同结点的最短路径,横跨两个乃至三个结点的最短路径,有两条路径均可达时是否取最短,remove后能否重新构建最短路径等等。
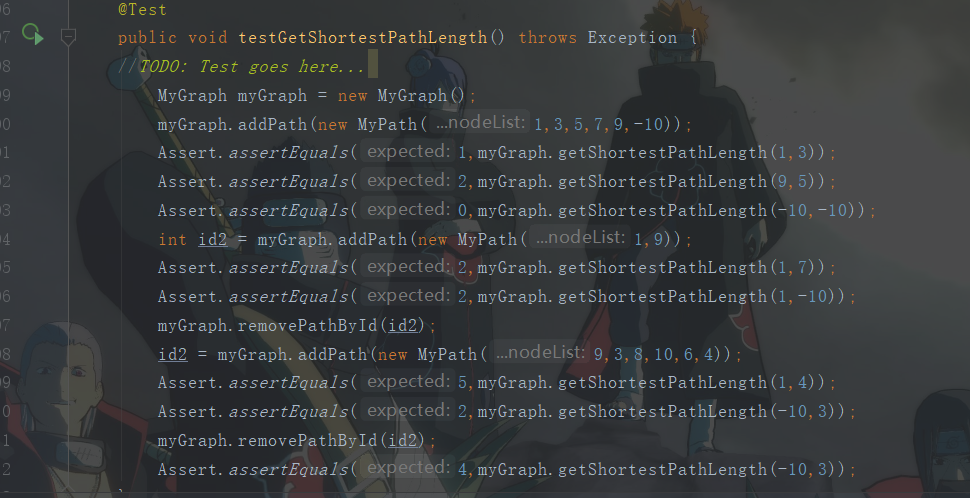
其次写了一个复杂的测试,由于截图大小有限,直接复制代码
@Test
public void testGetShortestPathLengthComplex() throws Exception {
MyGraph myGraph = new MyGraph();
myGraph.addPath(new MyPath(1,-1,-2,-3,-4,-5,-6,-7,-8,-9,-10,-11,2,-12, -13,-14,-15,-16,-17,-18,-19,-20,3,-21,-22,4,-24,-25,-26,5));
myGraph.addPath(new MyPath(5,-28,-29,-30,-31,-32,-33,-34,7,-101,-102,
-103,-104,-105,-106,-107,-108,-109,-110,-111,-112,-113,1));
myGraph.addPath(new MyPath(1,-201,-202,-203,-204,-205,-206,-207,-208,
-209,-210,-211,-212,-213,-214,-215,6,-216,5,-221,-222,
-223,-224,3,-231,-232,-233,-234,-235,6));
myGraph.addPath(new MyPath(2,-241,-242,-243,-244,-245,-246,6,-251,-252,
-253,-254,-255,-256,-257,-258,7));
int[][] dis = new int[7][7];
for (int i = 0; i < 7; i++) {
for (int j = 0; j < 7; j++) {
dis[i][j] = myGraph.getShortestPathLength(i + 1,j + 1);
}
}
int[][] ans = { { 0,12,22,22,18,16,14},
{12, 0,10,13, 9, 7,16},
{22,10, 0, 3, 5, 6,13},
{22,13, 3, 0, 4, 6,12},
{18, 9, 5, 4, 0, 2, 8},
{16, 7, 6, 6, 2, 0, 9},
{14,16,13,12, 8, 9, 0}};
for (int i = 0; i < 7; i++) {
for (int j = 0; j < 7; j++) {
System.out.print(String.format("%2d ",dis[i][j]));
}
System.out.println();
}
for (int i = 0; i < 7; i++) {
Assert.assertArrayEquals(ans[i],dis[i]);
}
}
大概的意思就是,将下图转换为路径输入图中
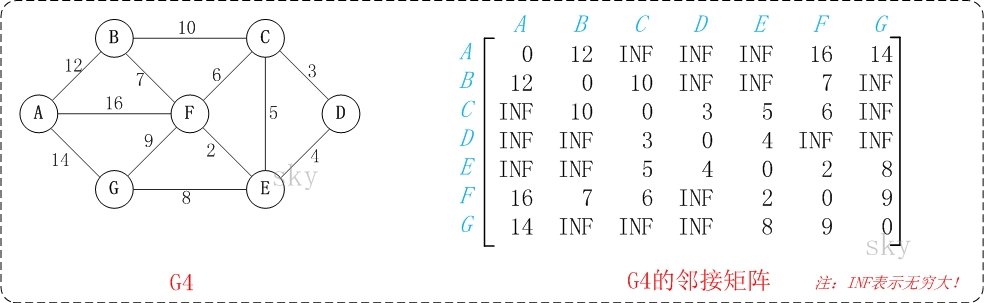
并且计算并输出任意两点间的最短距离,与结果矩阵相比较。
与上述的例子相同的测试共有23个,下图为测试结果:

第一次作业:基础的JML实现
1. 程序简介:

基本结构:

- 类的个数:2个;方法个数:19个
- 本次作业代码规格并不大,只是根据官方提供的JML来进行最基本的实现。
- 具体架构为:
- 建立一个MyPath类的数组用来存Path,同时数组下标对应PathId方便进行从id到path的索引
- 建立一个Arraylist用来存所有的PathId
- 建立一个Treemap<Path,Integer>,用来进行从path到id的索引
- 建立一个Treemap<Integer,Integer>,用来记录distinct node,其中value的值是当前的container中有多少的该节点,以方便更新删除。
2. 结构分析
- 复杂度分析
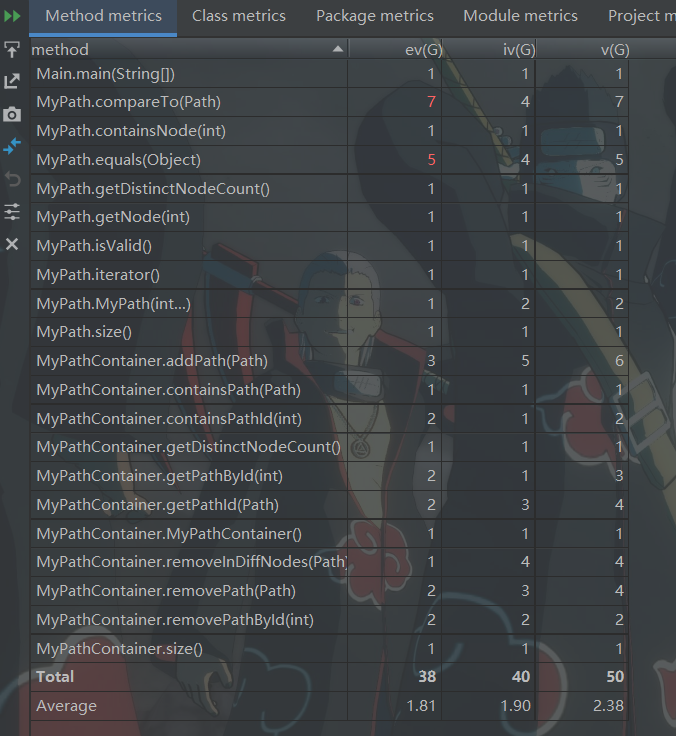

可以看出,总体的复杂度并不是很高。其中标红的compareTo和equals由于有很多的if语句导致的圈复杂度略有升高。
3. Bug分析
这次作业是我写的相当憋屈的一次作业,三次作业都经历了很不快的代码重构。
这一次的作业,由于这是本单元第一次作业,而且看起来过于简单,导致我仅仅实现了JML中所要求的内容就划水弃之不顾了。即只思考了正确性,没有考虑时间复杂度。这直接就导致了我第一次作业的强测分数只有区区65分。(这也充分说明了,不要因为是第一次作业就掉以轻心,也一定要时刻关注着鱼塘和讨论区,里面会有些意想不到的情报)
本次的作业正如助教之后所说的一样,我没有缓存中间获得的数据。具体表现为,对于DISTINCT_NODE_COUNT指令,我并没有存下来这个信息,而是在每次调用这个方法的时候都重新调用,所以造成了效率的严重下降。
第二次作业:由路径向图的进发
1. 程序简介:
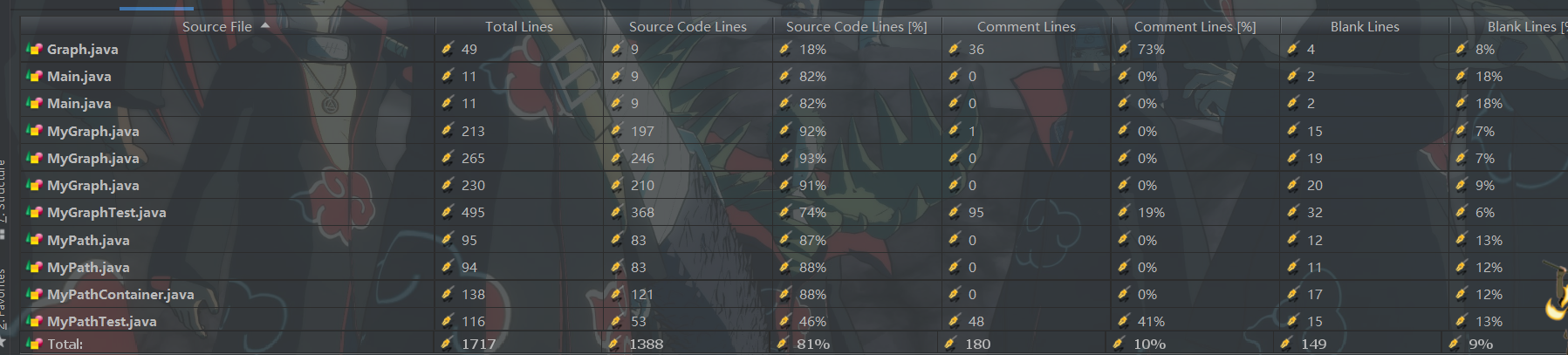
(这个吓人的1700+的代码量其实是包含了一次重构以及两个Junit的代码量,真正有效代码远远不到1700行)
基本结构:

本次作业是在上一次作业的PathContainer基础上继承出一个MyGraph类,用来对图进行专门的维护。
- 基本结构为:
- PathContainer类:同第一次作业的Path类
- 使用一个Hashmap<Integer,Hashmap<Integer,Integer>>结构建立graph来进行fromNode→(toNode→pathWeight)的映射。(本质上为邻接表的系数矩阵表示)
- 同graph,建立一个distance图,用来存所有的已经算出来的最短路径
- 设立两个update信号,分别判断graph和distance什么时候需要更新。
- graph在每次add和remove的时候都需要将update信号设为false(
其实不用,等到第三次作业才意识到,但是为时已晚,后文将会提到)而每次使用graph的时候需要先更新,将update信号设置为true,再进行接下来的运算。(这样是一种简单的优化,就相当于不需要每次add和remove之后都完全重构图,只是在需要的时候才重构) - distance同样的,在每次add和remove命令时将updatedistance信号置为false,而在每次调用GET_SHORTEST_LENGTH和IS_CONNECTED的时候检查更新情况,如果已经更新且含有fromNode,即可直接得到所需的信息。如果尚未更新,则进行初始化(distance.clear()),然后根据需要进行运算dijkstra,并将所有的算出来的单源信息都保存在distance中
- graph在每次add和remove的时候都需要将update信号设为false(
2. 结构分析
- 复杂度分析
- 方法复杂度

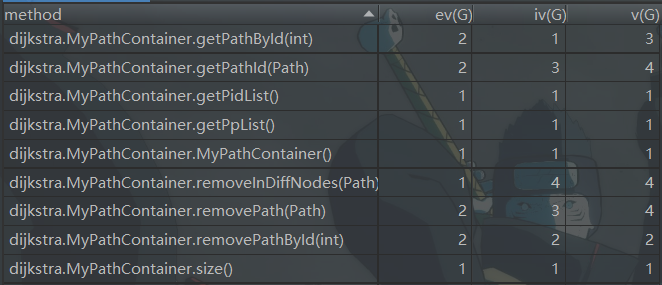
- 类复杂度

3. 自我评价
毫无疑问,dijkstra是一个重灾区,这其实是因为我的dijkstra在这一次作业中写错了,导致不仅圈复杂度很高,而且其实运行效率也是不忍直视。
这里推荐一个dijkstra算法---堆优化的模板
但是, 我想来说一下关于使用Hashmap<Integer,Hashmap<Integer,Integer>>的好处。(特别鸣谢莫策同学提供了如此好的方法)。
1. 不需要建立一个很大的数组来存所有节点,节省空间复杂度,同时也能实现用fromNode和toNode找到边对应的权值。
- 使用Hashmap可以加快访问速度,相比于静态数组速度不会慢很多(慢在计算Hashcode的时候)
- 可以直接通过fromNode就得到所有与其相连的边的信息,方便遍历
- 在使用单源的dijkstra的时候,正好更新的为一个源点的所有信息
4. 分析自己的bug与发现别人的bug
这次的代码其实尽管竭力避免,仍然出现了TLE的问题。(这两次的作业,想出现正确性的问题也不容易)
这次出现TLE的原因主要有两点:
-
一、 图的更新太慢
- 根据我的架构,相当于当add或者remove之后,每次调用图相关命令都需要重构图,需要遍历所有的边以及边上的结点来构建图,时间复杂度直接爆炸。
- 我的graph的结构中边的权重一项只有两个值:0或者1。0对应着已经连起来的相同结点,而1对应着其他边。仔细思考就能发现,其实这个0和1的判断其实完全可以由
fromNode == toNode ? 0 : 1来获得权值。所以这个图就可以进行更改,将矩阵中的数值更换为当前边的数量,这样每次addPath和removePath的时候只需要看当前的“边的数量”,这样就可以实现每次add和remove的时候对于图进行增删,而不再需要完全的重构图,大大的减少了时间复杂度。
-
二、 最短路径查找方法
-
我的第一个version(也就是强测版本)使用的是floyd算法,即在同一时间就把所有的点到点之间的最短路径都算出来。对于一条add/remove之后,大量的调用distance的情况来说,这无疑是最好的算法,一劳永逸。但是,对于add/remove之后只使用了1-2条调用distance的指令来说,你必须每次都要更新,就会耗费大量时间。
-
于是,我再更新bug的时候,更换了最短路径算法,使用了dijkstra的算法,这样的话可以一次只计算出当前的fromNode到所有Node的最短信息,并且保存下来,这样就可以做到每次计算的粒度很小,避免了大量的无意义计算;同时缓存下来也代表了可以节省很多的重复运算
-
此外,由于图结构相对静态,所以可以考虑以下的策略
- 将时间复杂度分散到本就无法降低复杂度的写指令以及线性复杂度指令中。
- 将之前计算出来的部分中间结果保存下来,以减少后续的计算复杂度。
- 一言以蔽之,应当使用类似缓存的思想,将大量的计算任务按照一定的策略进行均摊,以减少重复劳动。
- 具体来说,如果你使用的是单源最短路系算法的话(spfa、dijkstra等)
- 假设你本次求解的是$x$到$y$的最短路
- 那么,实际上你半道上求出来的最短路结果,可远不止$\left(x, y\right)$这么一组。具体来说,最起码包含了其他全部从$x$开头的结果,以及一些其他的中间结果(因算法而异)。
- 然后,你需要做的,就是充分利用好这些本次暂时用不上的中间结果,使得以后的最短路运算被不断加速(准确的说,这样的架构下,求解次数越多,后期速度越快)。
- 比如,你可以考虑单独开一个图,初始只包含初始的边,对于已经求出来的全部最短路结果(无论本次是否用得上),都作为边加入到这张图中(后续经过此段的时候,不再需要一步步算),并做好标记(对于访问已有结果的情况,可以直接出解),使得这张图不断滚雪球,运算速度越来越快。
----------引用自第十一次作业指导书
-
5. Junit的使用
由于我太轻视了上一次的作业,直到这一次作业我才开始第一次开始使用Junit
第一次使用Junit,感官并不是太好。确实针对每一个方法编写了测试单元,但是测试单元仍然是自己编纂的数据,虽然对于懒得写文件比较器的人来说确实有方便之处,但是感觉相比于手动测试,具体的差异在哪里呢?使用Junit是否能实现随机检查呢?(因为assert语句需要知道答案,而随机数据很多的答案是无法知道的,或者使用算法计算的话,那根源代码就没有很多的差异了),所以我用Junit更多的是找到其他写了Junit的人,然后互相测试。
第三次作业:模拟Railway的调度
1. 程序简介:

可以看出,这次的代码量还是很多的,这也是我第一次自己写+de将近1500行的代码真的酸爽。
-
基本结构:
![]()
看到这个结构是不是都快疯了
:这TM都什么玩意,别着急,让我们把所有的方法都去了,只剩下类之间的关系:![]()
是不是清晰了一些呢?接下来我们一点一点的来分析这个架构
-
首先是最左边的MyPath, MyPathContainer和MyGraph三件套
- MyPath和MyPathContainer完全套用了前一次作业的类(当然MyPath中增加了一个JML里需要的方法)
- 相比于前一次作业的MyGraph,这次的MyGraph只有graph这一个图,而把最短距离矩阵distance拿出去单独封装了。
-
其次是右边的很多结构,最核心的自然是MyRailwaySystem
-
在这个类当中,我们组合了5个类:不满意度类(Satisfaction),最短路径类(Distance),最小票价类(Ticket)和最小换乘类(Transfer) 以及连通块类(Block)。这其中前四个类都继承自一个叫RailwayGraph的接口
-
根据仔细分析不难发现,其实这四个“最短路径”的本质差别仅仅是边的权重和换乘的权重不同:
-
Type PathWeight TransferWeight distance 1 0 transfer 0 1 ticket 1 2 satisfaction specific weight 32 -
所以说,其实计算这4个矩阵的方式是几乎一样的,我们就可以设计一个RailwayGraph接口来共同化这四个图。在每一个图类中,有一个自己的权值图和自己的“最短路径”图,更新以及构造方法与第二次作业的没有区别。
-
至于Block类,使用了并查集来进行更新。这也是我第一次使用并查集,感觉用起来还是挺
丝滑顺手的。这里推荐一个并查集的简单教学:并查集详解
-
-
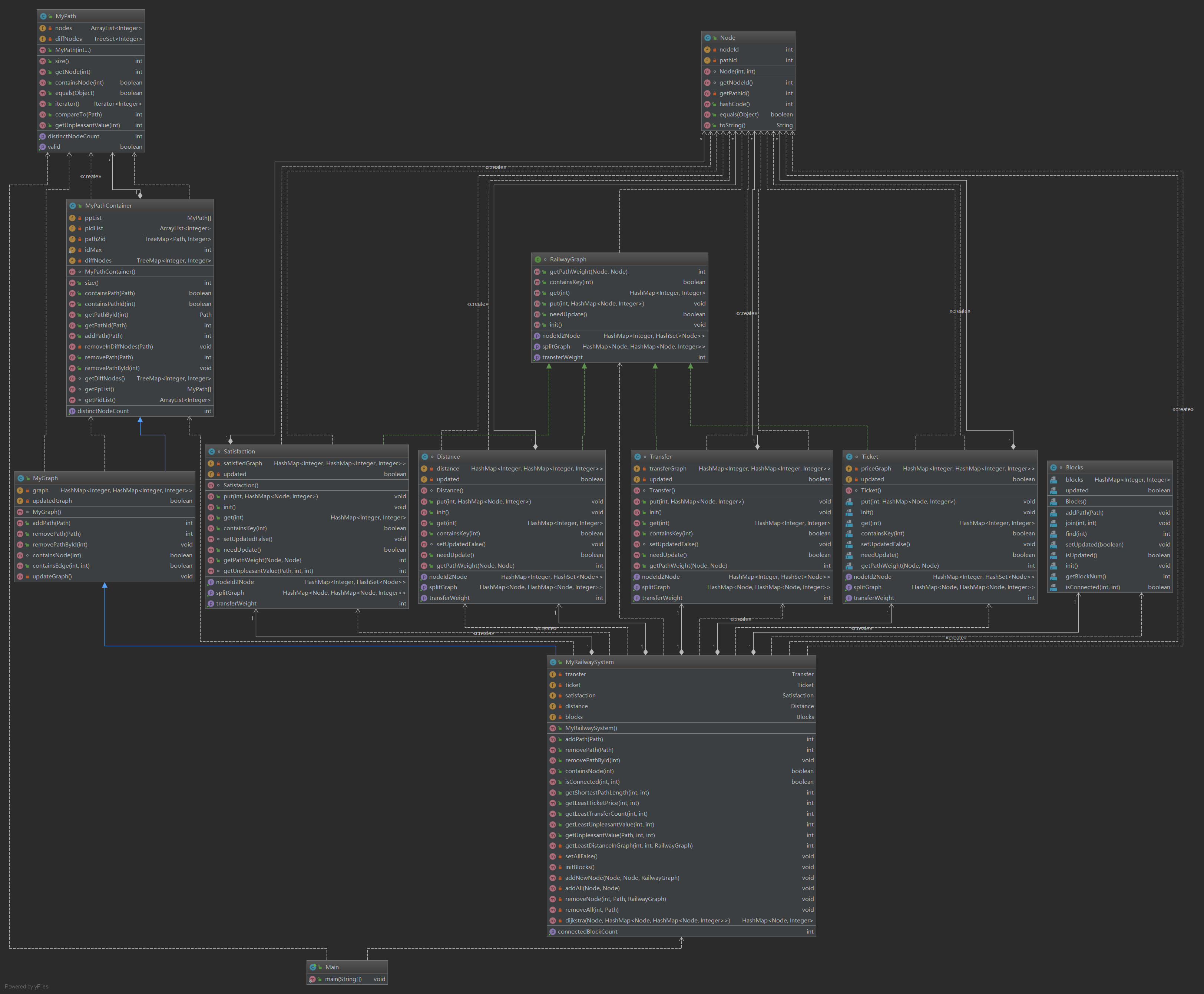

2.结构分析

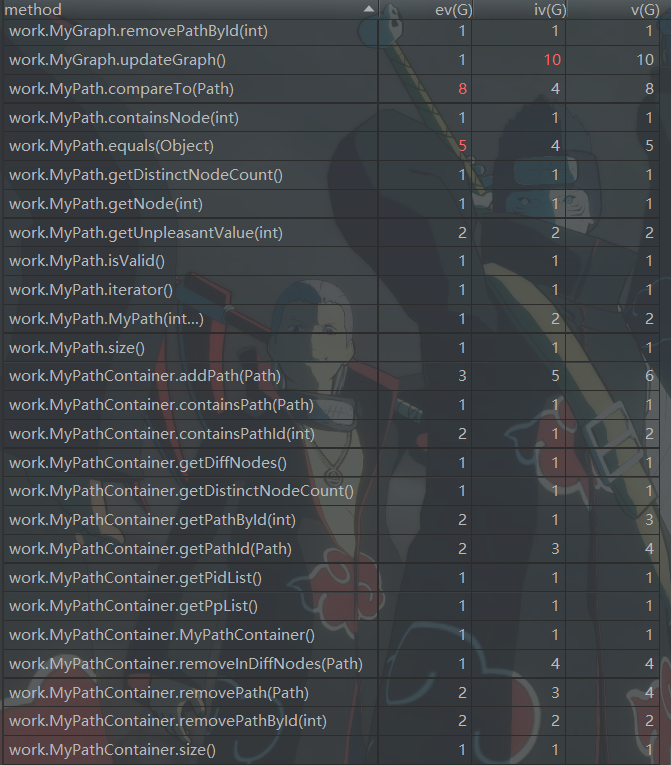


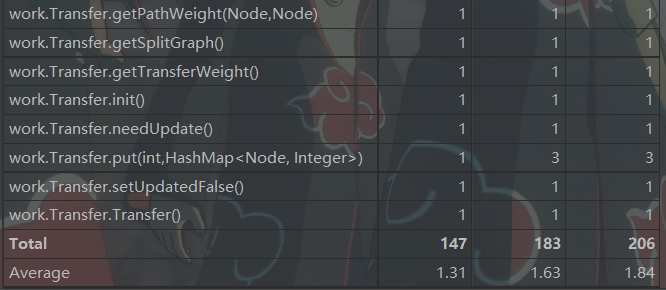
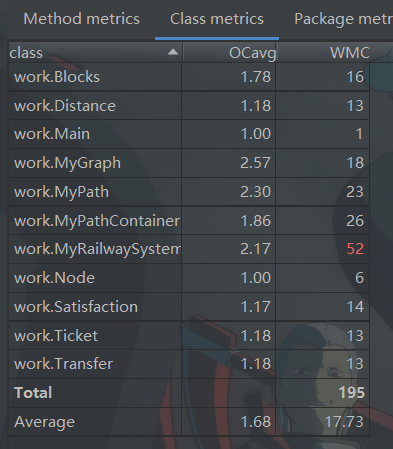
3. 自我评价
圈复杂度和类复杂度不想多说,基本上都是上一次作业传承下来的复杂度。其中类复杂度MyRailwaySystem复杂度过高是因为我将关于图的计算包括dijkstra算法都放在了该类里,有些是因为所有的图都要使用,没有特异性,放到“最短路径图”里面显得很冗余,有些是需要用到MyGraph的方法,在“最短路径”图里无法构造。
其实这次的封装真的是思考了好久(特别鸣谢朱雨聪dalao!相当于是帮我梳理了我的思路,而且人超级耐心超级nice!),而且写的时候也是不停地在更改,才改到最后这么一个看起来有点逻辑层次的代码。我感觉这一次封装的重点就是如何区分开什么类应该干什么,尽量的降低耦合度。否则如果将所有的东西都堆杂在同一个类里的话,就会变得相当的难维护。
另外一个重灾区就是很多的判断捎带的函数。这些函数往往都需要很多很多的循环和判断,复杂度自然相当的高
我想在这里介绍一下我的Request类,我觉得自己设计的还是蛮巧妙的,可以稍微介绍一下。
同时,这里也提一两句关于拆点的算法来实现换乘:
- 设置一个Node类,其中存着node的id以及其所属的pathid,同时提供hashcode以及equals等方法
- 对于每一个处于不同path但是享有同样nodeId的点,将其拆分为不同的点,如此构造来看,这样点之间的距离即为换乘的距离。
- 计算最短路径时,对于每一个nodeId设置一个Node类,其中的pathId=Integer.MAX_VALUE,并且让它与且仅与所有的相同的nodeId的点。这样的话,计算dijkstra的时候只需要计算这样两个pathId为MAX_VALUE之间的距离,再减去2*transferWeight即可
整体评价---写在最后的话
总的来说,这次的作业完成情况相当的令人不乐观。虽然后来居上在最后一次作业中侥幸拿取到了强测分数,但是仍然无法弥补前两次作业的损失。也算是再再再再再一次为自己的粗心大意划水不重视买单吧
既然这单元是JML特别单元,那就来谈一谈规格撰写和理解上的心得体会。
-
方法
- JML主要针对两个方面:assignable, \result
- assignable涉及到需要改变的变量,所以这个其实提示了要把需要改变变量的方法最小化。例如一个方法中只有一部分需要改变某个属性,就应该看是否能把这部分拿出来独立成为一个新方法
- \result代表了JML对于方法结果的期待。目前(课上实验,课下作业)见到的主要写法就两种:直接用\result;或者新创建一个数组,然后令\result等于数组长度。前者适合结果为直接有意义的量的时候,后者多为为了统计数量的方法
- JML主要针对两个方面:assignable, \result
-
变量
-
变量的只见过invariant和constraint,前者是不变式,后者是状态变化约束,对于某些特别的属性在定义的时候用这两个加以限制,不失为一个好方法。
就目前来说规格的撰写也就这些了。希望以后能遇到更好的写规格的机会~
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号