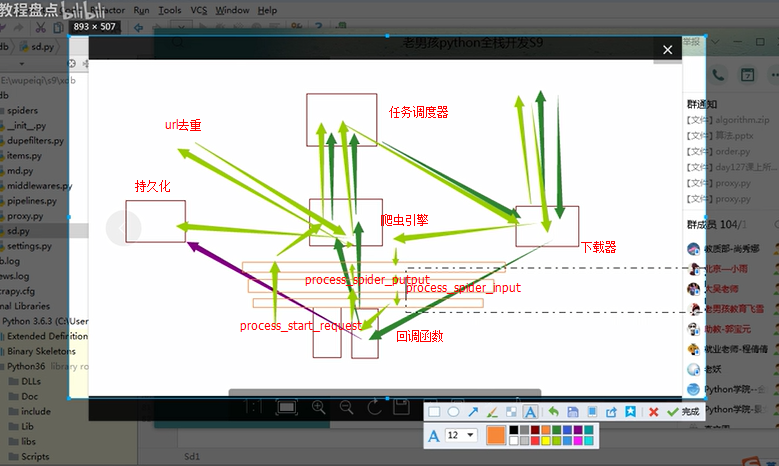
组件以及执行流程
-引擎找到要执行爬虫,并执行爬虫的start_requests 方法, 并得到一个迭代器。
-迭代器循环时会获取Request对象,而Request对象中封装了要访问的URL和回调函数。
-将所有的Request对象(任务)放到调试器中,用于以后被下载器下载
-下载器云调试器中获取要下载任务(就是Request对象),下载完成后就执行回调函数。
- 回到spider的回调函数中,
回调函数中可以返回:
yield Request() ---> 放到调试器中,用于以后被下载器下载
yield Item() ---> 调用Pipeline做持久化
下载中间件, (本质上就是一个类)
process_request
process_response
process_exception
代理
环境变量
meta
自定义下载中间件
下载中间件具体实现
class XdbDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
# 1、返回Response
# import requests
# result = requests.get(request.url)
# return HtmlResponse(url=request.url, status=200, headers=None, body=result.content)
# 2、返回Request
# return Request('https:xxxxx')
# 3、抛出异常
# from scrapy.exceptions import IgnoreRequest
# raise IgnoreRequest
# 4、对请求进行加工
# 内置了对请求加工的中间件 UserAgentMiddleware:
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
对请求进行加工的文件useragent.py
from scrapy import signals
class UserAgentMiddleware:
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
配置文件settings.py
DOWNLOADER_MIDDLEWARES = {
# 'xdb.middlewares.XdbDownloaderMiddleware': 543,
# 'xdb.proxy.XdbProxyMiddleware': 751,
# 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
爬虫中间件具体实现:
class XdbSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request, dict
# or Item objects.
pass
# 只在爬虫启动时,执行一次
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
# 上面start_requests就是下面函数返回值
# def start_requests(self):
# 方式一:
# for url in self.start_urls:
# yield Request(url=url, callback=self.parse)
# 方式二:
# req_list = []
# for url in self.start_urls:
# req_list.append(Request(url=url))
# return req_list
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
配置文件settings.py
#SPIDER_MIDDLEWARES = {
# 'xdb.middlewares.XdbSpiderMiddleware': 543,
#}
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号