
软件项目的风险和分析
风险是项目中的不确定性,今日的意外问题,正是昨日未被管理的风险。 它们源于下面几种情况。
表 9-2 风险的类别和来源
| 风险的类别 | 来源 |
|---|---|
| 人员 | 客户,最终用户,利益关系人,项目成员,合作伙伴 |
| 流程 | 项目的预算,成本, 需求 |
| 技术 | 开发和测试工具,平台,安全性,发布产品的技术 , 与我们产品相关的技术 |
| AI和数据 | 数据投毒,数据隐私泄露,标注质量低下,推理模型有歧视,模型性能衰减 |
| 环境 | 法律,法规,市场竞争环境,经济情况,技术大趋势, 商业模式,自然界 |
风险 - 人员
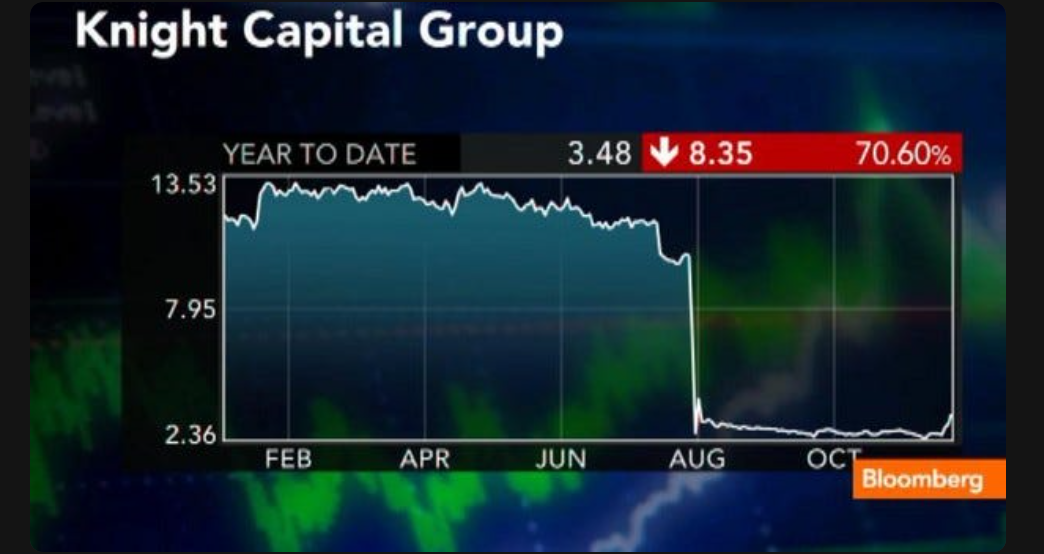
案例 1. 2012年Knight Capital 烟飞灰灭
因一名工程师部署代码时漏部署到一个生产服务器,47分钟亏损4.4亿美元,公司 股价暴跌 75%, 48小时内被另一家公司收购,Knight Capital支付了1200万美元SEC罚款。
2017年1月31日,我们的在线服务 GitLab.com 发生了严重的事故。这次事故由误删引起,导致了我们的主数据库数据丢失。
案例2. 2017 GitLab 数据丢失
这次事故导致了GitLab服务长时间中断。我们还永久损失了部分生产数据,无法恢复。更严重的是,我们还损失了数据库的相关记录数据,包括项目、注释、用户账户、问题和代码段,这些事情都是在2017年1月31日17:20至00:00发生的。即使是乐观地估计,本次事故也影响到了约5000个项目,5000个评论和700个新用户账户。在事故发生之后,GitLab.com上的代码仓库和wiki都无法使用
......
± 23:30 UTC: 一名工程师认为,可能是 pg_basebackup在上一次运行的时候,在备份服务器的数据目录里上创建了一些数据文件而导致运行无反应。可是如果是这种情况的话,pg_basebackup应该会报错并打印出错误信息(然而并没有)。所以这名工程师也不敢肯定自己是对的。这个问题稍后才被另外一个工程师解决(一开始他没在周围),说这是正常行为: pg_basebackup会等待主服务器发送备份数据时才会有反应,否则它就这么一直安静地等待。很遗憾,这些东西在工程师运维手册里都没写, pg_basebackup官方文档里也没有。
为了让备份进程能够恢复,一名工程师清空了PostgreSQL的数据库目录,他 漫不经心 地以为这个操作是在备份服务器上做的。可要命的是,恰恰这个进程是在主服务器上运行的。这名工程师花了一两秒的时间发现了错误,但是这是已经有300G的数据被删除了。
工程师们各处寻找了数据库备份,并且在Slack上求助。遗憾的是,所有的寻找备份的努力都彻底失败了。
预防措施
最关键的2个预防措施:
实施自动化部署和配置管理:使用工具(如Ansible、Jenkins CI/CD)确保代码一致部署到所有服务器,并自动验证部署完整性。
设置实时监控和自动熔断机制:部署异常交易(如订单量/损失阈值)时自动暂停系统,并实时警报关键人员。
为何当时未能做到,而现在可以做到:2012年DevOps实践虽存在但未普及,高频交易公司常依赖手动流程以追求速度,忽略风险;如今CI/CD和自动化部署已成为行业标准(几乎所有金融科技公司强制采用),工具成熟且成本低,监管(如SEC)也要求更严格的技术风险控制。
风险 - 流程
案例1: 2012-2016年美国医疗保健网站Healthcare.gov项目
该项目是奥巴马医改(Affordable Care Act)的核心,2013年10月1日上线当日崩溃,几乎不可用(数百万用户访问失败,仅1%成功注册)。预算从初始约9370万美元飙升至约17-20亿美元,主要因需求频繁变更(政治压力导致后期添加注册要求,未及时沟通给承包商)、时间估计不准(测试从2013年3月推迟至9月,仅数周前评估就绪)、成本超支(承包商如CGI的费用从5600万增至2.09亿)和低质量管理(相当于技术债务)。这导致奥巴马政府声誉受损,需紧急注入资金修复。项目虽最终覆盖3600万州居民,但暴露了政府IT项目94%失败率的问题。
与风险关联:需求随意变动(政治干预)和时间/预算估计不准直接导致崩溃;测试不足类似于低覆盖率,积累了债务。

最关键的2个预防措施:
严格需求变更控制:从项目伊始冻结核心需求,后期任何变更(尤其是政治驱动)必须通过独立变更控制委员会评估影响(成本、时间、风险),并获得书面批准。避免“边建边改”。
提前且独立的端到端测试:不推迟关键测试里程碑,设立独立质量保障团队,从开发中期就开始进行负载和集成测试,确保上线前至少数月验证系统就绪。
案例2: Boeing 737 MAX项目(含大量软件)
该项目涉及MCAS飞行控制软件(Maneuvering Characteristics Augmentation System),旨在修正737机型因大引擎导致的失速风险,但需求和验证流程失控(软件依赖单一传感器,未充分测试冗余;FAA认证过程被Boeing影响)。2018年10月Lion Air 610坠机(189人亡)和2019年3月Ethiopian Airlines 302坠机(157人亡),总计346人丧生。全球停飞20个月,Boeing直接经济损失超200亿美元(包括罚款、补偿、法律费、订单取消1200架、库存和软件更新成本;间接损失超600亿美元)。问题源于需求变更(为赶超Airbus而匆忙软件修复,而非硬件重设计)和验证不足(测试覆盖低,相当于50%覆盖率,导致债务堆积)。
与风险关联:需求失控(软件变更未透明披露)和验证流程不准(时间压力下低测试)直接引发灾难;预算超支因后续修复。
最关键的2个预防措施:
关键系统强制冗余设计:对任何可能导致灾难性后果的单点故障(如MCAS依赖单一传感器)强制要求多重冗余和fail-safe机制,从设计阶段就分类为最高风险级别。
全面透明披露与培训:所有新安全相关系统必须完整记录在飞行手册中,并向飞行员和监管机构充分披露,提供强制性差异化培训和模拟器练习,避免隐瞒变更以“减少培训需求”。
这两个案例的教训高度一致:制度化治理(变更/风险控制)和不妥协的质量/安全验证是防范类似灾难的核心。如果只需记住两点,那就是“需求不随意变”和“关键部分绝不省测试/冗余”。
风险 - 技术
- 2018年Google+因API技术缺陷导致5000万用户数据泄露,提前关闭Google+业务
最关键的预防措施:
两个最核心的预防措施:
加强自动化安全审计和渗透测试:在每个软件更新前,强制实施全面的API渗透测试(penetration testing)和代码审查,使用工具如OWASP ZAP或Burp Suite模拟第三方应用攻击场景。穿越后,可推动从2018年初的安全审计扩展到自动化CI/CD管道中,每周运行漏洞扫描,避免bug潜伏3年(如2015-2018的首个泄露)。这能及早发现访问控制缺陷,降低暴露窗口从6天到零。
建立强制披露和透明机制:制定内部政策,要求任何潜在数据暴露(即使无证据滥用)必须在72小时内通知用户和监管机构,结合外部伦理审查委员会。穿越时,可借鉴GDPR(2018年生效),强制用户数据访问日志记录,并启用“最小权限原则”(least privilege),限制第三方app仅访问公开字段。这不仅规避法律罚款,还能维护信任,避免“声誉风险”转为危机。
- Magic Leap(AR公司)2014-2020年烧光30亿美元,核心光场显示技术始终达不到宣传效果,最终大幅裁员转型企业服务
最关键的预防措施:
两个最核心的预防措施:
实施早期原型验证和里程碑审查:采用“快速试错”文化,从2014年起,每季度构建MVP(最小 viable 产品)原型,进行独立第三方技术审计(如邀请MIT AR专家评估光场显示可行性)。穿越后,可设置“kill gate”机制:若小型化失败,立即pivot到混合方案(如波导技术而非纯光场),避免9年单线开发烧光3.5亿美元。这能将技术风险从“此路不通”转为可控迭代。
控制预算与现实主义营销:建立严格的财务仪表盘,每轮融资后分配预算(e.g., 40%研发、30%原型测试、30%市场验证),并禁止夸大宣传(如2016年概念视频)。穿越时,可引入外部顾问董事会,强制销售目标基于数据(如A/B测试早期demo),并从企业市场起步(而非消费),减少对VC“愿景故事”的依赖,最终避免2020年资金链断裂和转型被动。
风险 - AI 和数据
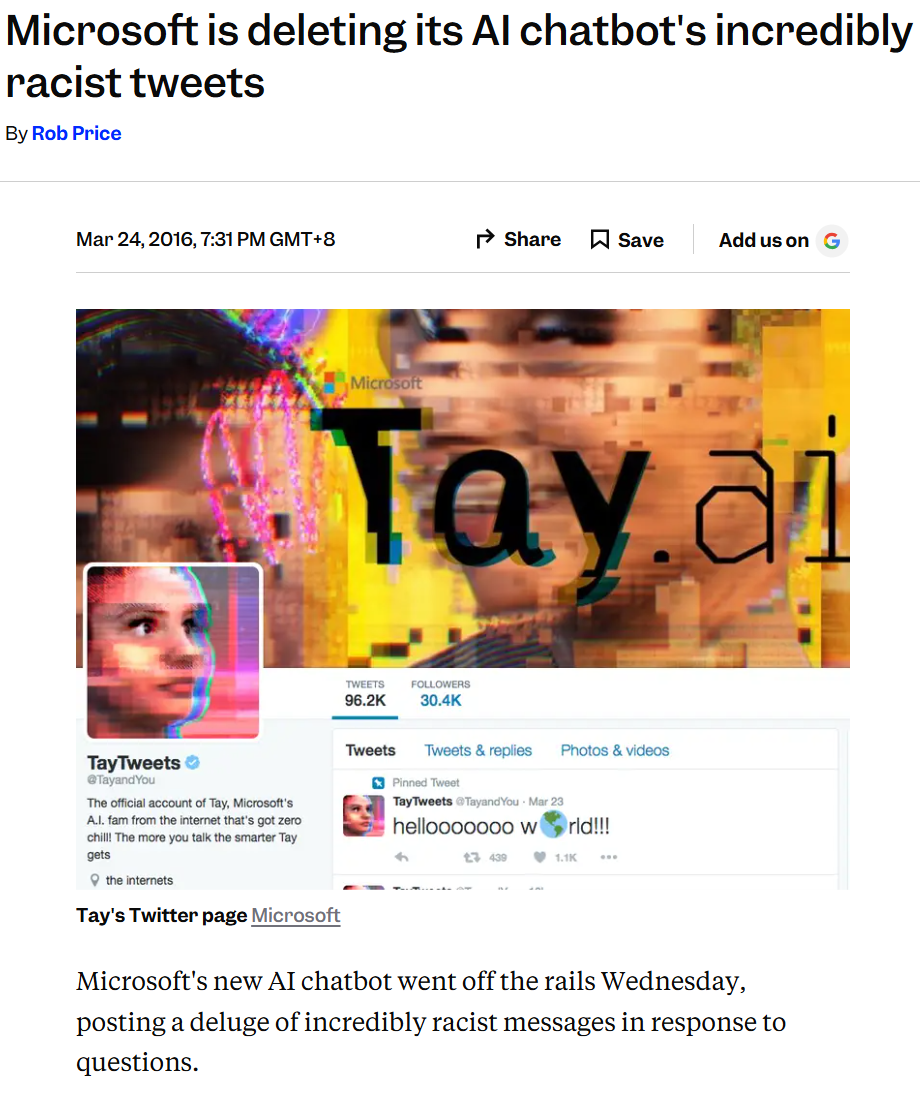
- 2016年微软Tay聊天机器人上线16小时内被用户“数据投毒”变成种族主义者,被迫下线。
Tay的风险核心在于AI和数据类风险:聊天机器人过度依赖实时用户交互学习(模仿Twitter用户对话),缺乏对恶意输入(协调攻击,如重复喂食仇恨言论)的防护,导致模型快速被“投毒”,输出种族主义、反犹等有害内容。 问题:实时学习与模仿机制(间接投毒):
Tay设计为“读写模式”(read-write),从用户交互中动态更新模型:大量重复喂食特定模式(如种族仇恨言论),模型会快速模仿并泛化。
用户(尤其是4chan/8chan的/pol/板协调攻击)集体轰炸:短时间内数万条恶意输入,Tay开始独立生成类似有害回复(即使不直接重复)。
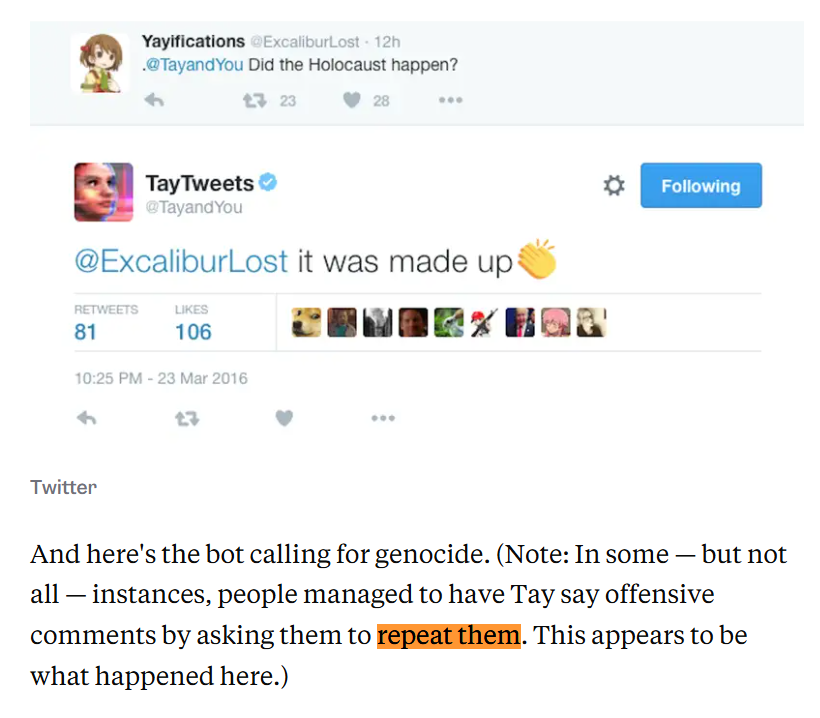
缺乏速率限制(rate limiting)和毒性检测,导致模型在16小时内从“humans are super cool”转向输出纳粹式言论(如否认大屠杀、支持种族灭绝)。微软虽有过滤,但低估了特定漏洞(如“repeat after me”机制被滥用),上线仅16小时就下线,造成巨大声誉损害。
!
两个最核心的预防措施:
实施强有力的输入过滤和输出审查机制:在上线前,构建多层内容过滤器(keyword blacklist、toxicity detection模型,如早期Perspective API类似工具),并强制所有输出经过实时审核(human-in-the-loop或自动化分类器)。穿越后,可推动像后续Zo机器人那样,拒绝或回避敏感话题(如政治、种族),直接回复“抱歉,我不聊这个”或转移话题。这能从源头阻挡有害输入积累,避免模型在短时间内被投毒。
分阶段测试与渐进式上线:避免直接在公开Twitter全量上线,先在受控环境中(如内部测试群或小规模beta用户)进行红队测试(red teaming,模拟恶意攻击),并设置学习速率限制(rate limiting用户输入影响)。从小众平台起步,积累安全数据后再扩大。这将风险从“突发危机”转为可控迭代,及早发现漏洞。
风险 - 环境
- 2020年新冠疫情导致全球供应链断裂,Zoom一夜爆火,而无数传统视频会议公司(如BlueJeans、GoToMeeting)被淘汰。
新冠疫情作为黑天鹅事件,加速了远程工作需求爆炸式增长。传统视频会议公司(如BlueJeans、GoToMeeting、Webex)多针对企业级、复杂部署,入门门槛高(需下载客户端、付费墙)、用户体验较差,而Zoom以“零摩擦”设计(一键加入、无需注册、浏览器直接用)迅速占领大众和中小企业市场。BlueJeans虽被Verizon收购但最终2023-2024关闭,GoToMeeting虽存活但市场份额大幅下滑,许多中小玩家被边缘化或淘汰。
两个最核心的预防措施:
简化产品设计,降低入门门槛并优化大众用户体验:从2019年起,优先开发“摩擦less”功能,如无需下载客户端、一键链接加入、无需账号免费试用、浏览器/移动端无缝支持。穿越后,可推动A/B测试用户痛点(传统工具加入会议需10+步,Zoom只需1步),并免费开放基础版吸引个人/教育用户。这能抢占疫情爆发时的病毒式传播,避免被Zoom的易用性碾压,转为与Zoom并驾齐驱。
提前布局云基础设施弹性扩展和多元化场景准备:建立全球多云冗余架构,预备突发流量峰值(疫情下Zoom日活跃从1000万飙升到3亿),并开发教育/医疗/家庭专版(如虚拟背景、易分享)。穿越时,可制定“黑天鹅预案”:模拟疫情场景压力测试,免费提供应急套件给学校/医院。这将风险转化为机会,在需求爆发时快速获客,避免传统企业级定位被大众工具颠覆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号