
强化学习读书笔记 -- 第十五章神经科学
神经科学是对神经系统的多学科研究的总称,主要包括:如何调节身体功能,如何控制行为,随着时间增长而发生的发育、学习和衰老的现象,以及细胞和分子机制如何使这些功能成为可能。强化学习的最令人兴奋的方面之一是来自神经科学的证据越来越多的表明,人类和许多其他动物的神经系统实施的算法和强化学习算法在很多方面是对应的。
强化学习和神经科学之间最显著的联系就是多巴胺,它是一种哺乳动物大脑中与奖励处理机制紧密相关的化学物质。多巴胺的作用就是将TD误差传达给进行学习和决策的大脑结构。这种关系被表示为多巴胺神经元活动的奖励预测误差假说,这是由强化学习和神经科学实验结果提出的一个假设。从脑功能的理论来看,强化学习的一些元素更容易理解。对于“有效循迹”这一概念尤其如此,有效循迹是强化学习的基本机制之一,起源于突触的一个猜想性质(突触是神经细胞与神经元之间相互沟通的结构)。
1.神经科学基础
神经元是神经系统的主要组成部分,是专门用于电子和化学信号的处理及信息传输的细胞。它们以多种形式出现,神经元一般从一端接收信息,再从另一端发出信息。接收传入信号的部分是一些被称为树突(dentrites)的分支纤维,由细胞体向外扩展。树突的基本工作是接收从感受器或其他神经元发出的刺激。神经元的细胞体,或称胞体(soma),含有细胞核和细胞质,以维持细胞的生命。胞体整合从树突接收的刺激(或者在一些情况下胞体直接从另一个神经元接收刺激,不必经过树突)。然后胞体通过一条被称为轴突(axon)的向外延展的纤维将所接收的刺激传递出去。轴突传递信息的长度在脊髓内可达几英尺,而在脑内仅不到一毫米。轴突的末端是个膨大的球状结构,称为终扣(terminal buttons),神经元通过终扣能刺激附近的腺体、肌肉或其他神经元。神经元一般只沿一个方向传递信息:从树突经由胞体到达轴突,再沿轴突传到终扣。神经元的主要结构如下图所示。
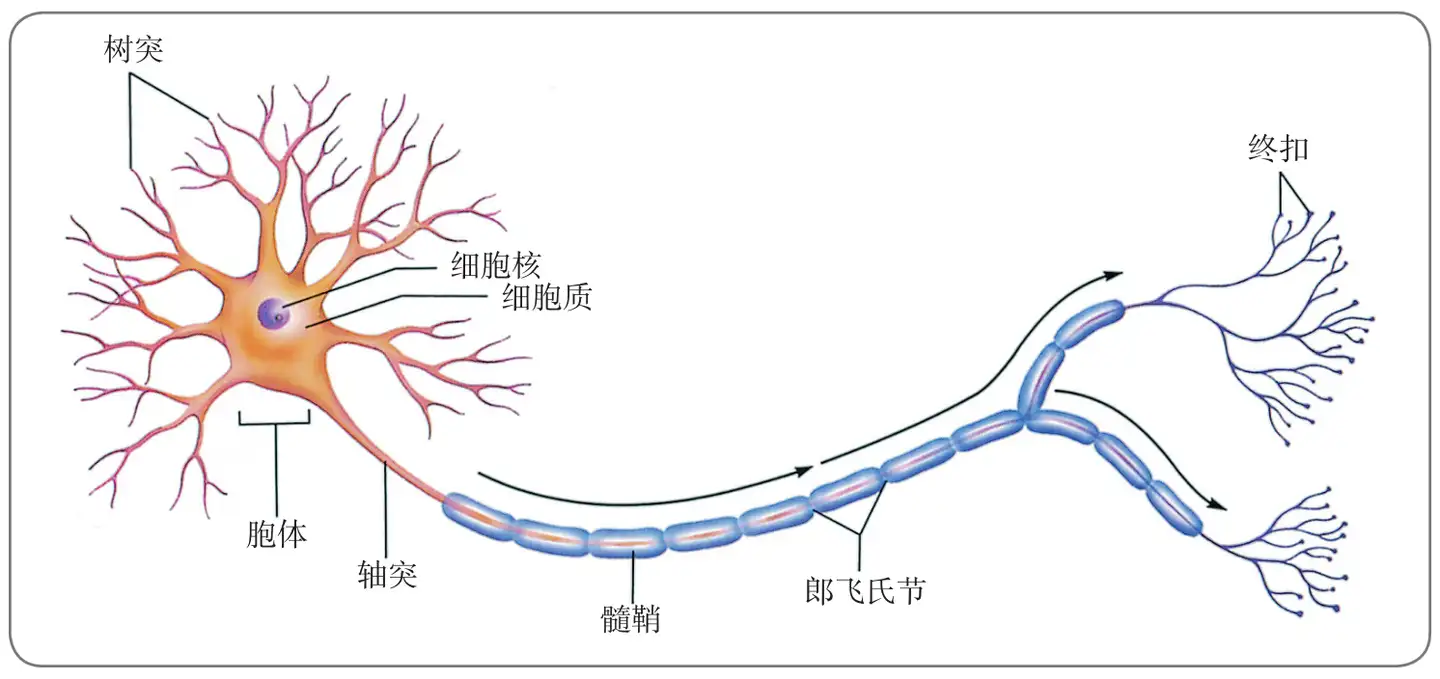
神经元可以分为三个主要类别。感觉神经元(sensory neurons)携带来自感受器细胞的信息向内传至中枢神经系统。感受器细胞是高度特化的细胞,对光线、声音和身体位置非常敏感。运动神经元(motor neurons)携带来自中枢神经系统的信息向外传至肌肉和腺体。脑内的大部分神经元是中间神经元(interneurons),它们从感觉神经元将信息传递到其他中间神经元或运动神经元。身体中每个运动神经元都有多达5000个中间神经元,形成巨大的中介网络,构成脑的计算系统。
突触效能变化的能力被称为突触可塑性。这是学习活动的主要机制之一。突触连接铺好了神经环路的基础“电线”,但是在整个神经系统中,线路关系盘根错节互相影响,可能牵一发而动全脑,因此突触连接并非是一成不变的。大脑的突触连接会随着神级刺激或其他因素的影响而一直在变化。对突触塑造,在塑造时间上跨度很大,短则几毫秒,长则达几年。对突触的短期塑造主要针对神级递质的释放量,神经递质释放量会因为突触前神经元动作电位的时长和程度而增大或减少;长期塑造则可以通过突触后神经元胞内信号分子发挥作用,胞内信号分子可以改变蛋白质翻译后修饰(如磷酸化)或改变基因表达和新蛋白质的合成,以对突触传递产生持久改变,甚至永久性改变大脑功能。
我们的大脑具有将这些相关事件进行编码,并有序关联的能力,这种能力的一个潜在的神经机制就是相位进动(phase precession)。相位进动是一种神经生理过程,指一些种特殊神经元(如大脑海马的空间调整位置细胞)动作电位(放电)与周期性节律场电位(如局域theta振荡)之间的相位关系,相位进动被认为在信息的神经编码中起着重要作用。海马神经元的脉冲时序(spike timing,亦或称尖峰时序)对于学习序列中事件之间的联系至关重要。脉冲时序可以由大规模网络活动的振荡来协调,而这种活动波动可以用局部场电位(local field potential,LFP)进行检测。因此,网络振荡和单个神经元脉冲之间的一致性关系可能有助于编码序列,从而在复杂行为或认知方面(如记忆)发挥作用。
2021年5月11日,在以Phase precession in the human hippocampus and entorhinal cortex为题在线发表在Cell的最新论文中,美国哥伦比亚大学的Salman E. Qasim(文章一作)、Joshua Jacobs(通讯作者)与加州大学洛杉矶分校的Itzhak Fried合作研究了这些科学问题。研究发现了人类大脑神经元以局部网络振荡的节律性脉冲时序来表征空间位置和非空间状态,强调了相位进动作为协调行为和认知过程中脉冲时序的一种普遍的神经元机制。
2 奖励信号、强化信号、价值和预测误差
神经科学和强化学习之间的联系始于大脑信号和在强化学习理论中起重要作用的信号之间的相似性。奖励信号(以及智能体的环境)定义了强化学习中智能体正试图解决的问题。与奖励处理相关的神经活动几乎可以在大脑的每个部分找到,并且很难明确地解释结果,因为不同的奖励相关信号的表示往往彼此高度相关。 实验需要精心设计,以使一种与奖励相关的信号能够在一定程度上与其他信号或与奖励处理无关的大量其他信号区分开来。 尽管存在这些困难,但已经进行了许多实验,目的是调和强化学习理论和算法与神经信号的各个方面,并且已经建立了一些令人信服的联系。
\(R_t\)就像动物大脑中的一个信号,定义奖励在大脑各个部位的初始分布。但是在动物的大脑中不可能存在像\(R_t\)这样的统一的奖励信号。我们最好把\(R_t\)看作一个概括了大脑中许多评估、感知和状态奖惩性质的系统产生的大量神经信号整体效应的抽象。强化学习中的强化信号与奖励信号不同。强化信号的作用是在一个智能体的策略、价值估计或环境模型中引导学习算法做出改变。
状态价值函数或动作价值函数的估计,即\(V\)或\(Q\),指明了在长期视角下对智能体来说什么是好的,什么是坏的。它们是对智能体未来期望累积奖励的预测。智能体做出好的决策,就意味着选择合适的动作以达到最大估计状态价值的状态,或者直接选择具有最大估计动作价值的动作。
预测误差衡量期望和实际信号或感知之间的差异。奖励预测误差(reward prediction errors, RPE)衡量期望和实际收到的奖励信号之间的差异,当奖励信号大于期望时为正值,否则为负值。当神经科学家提到RPE时,他们一般(但不总是)指TD RPE,在本章中我们简单地称之为TD误差。神经科学中的TD误差通常不依赖于动作,不同于在Sarsa和Q学习算法中学习动作价值时的TD误差。
实验证据表明,一种神经递质,特别是多巴胺,表示RPE信号,而且生产多巴胺的神经元的相位活动事实上会传递TD误差。
3 奖励预测误差假说
多巴胺神经元活动的奖励预测误差假说认为,哺乳动物体内产生多巴胺的神经元的相位活动,其中一个功能就是将未来的期望奖励的新旧估计值之间的误差传递到整个大脑的所有目标区域。Montague、Dayan和Sejnowski (1996)首次明确提出了这个假说(虽然没有用这些确切的词语),他们展示了强化学习中的TD误差概念是如何解释哺乳动物中多巴胺神经元相位活动各种特征的。TD误差的定义为\(\delta_{t-1}=R_t+\gamma V(S_t)-V(S_{t-1})\),当然在动物体内不存在负值,因此会在原有的误差上加入神经激活的背景值,即\(\delta_{t-1}+b_t\)。第二个假说是关于每次经典条件反射试验所访问到的状态以及它们作为学习算法的输入量的表示方式的。这种表示方式使得TD误差能够模仿这样一种现象:多巴胺神经元活动不仅能预测未来奖励,也对获得预测线索后,奖励何时可以到达有敏感性。因此,依赖于状态的TD误差对试验中事件发生的时间是敏感的。
基于上述两个假说,TD误差与多巴胺神经元的下列特征是相似的:1)多巴胺神经元的相位反应只发生在奖励事件不可预测时;2)在学习初期,在奖励之前的中性线索不会引起显著的相位多巴胺反应,但是随着持续的学习,这些线索获得了预测值并随即引起了相位多巴胺反应;3)如果存在比已经获得预测值的线索更早的可靠线索,则相位多巴胺反应将会转移到更早的线索,并停止寻找后面的线索;4)如果经过学习之后,预测的奖励事件被删除,则多巴胺神经元的反应在奖励事件的期望时间之后不久就会降低到其基准水平之下。虽然在Schultz等人的实验中,并不是每一个被监测到的多巴胺神经元都有以上这些行为,但是大多数被监测神经元的活动和TD误差之间惊人的对应关系为奖励预测误差假说提供了强有力的支持。然而,仍存在一些情况,基于假设的预测与实验中观察到的不一致。
4 多巴胺
多巴胺是神经元产生的一种神经递质,其细胞质主要位于哺乳动物大脑的两个神经元群中:黑质致密部(SNpc)和腹侧被盖区(VTA)。多巴胺不是参与奖励处理的唯一神经调节剂,其在厌恶情况下的作用(惩罚)仍然存在争议。多巴胺也可以在非哺乳动物中发挥作用。但是在包括人类在内的哺乳动物的奖励相关过程中,多巴胺起到的重要作用毋庸置疑。
一个早期的传统观点认为,多巴胺神经元会向涉及学习和动机的多个大脑区域广播奖励信号。这种观点来自James Olds和Peter Milner,他们在1954年论文中描述了电刺激对老鼠大脑某些区域的影响。他们发现,对特定区域的电刺激对控制老鼠的行为方面有极强的作用。后来的研究表明,这些对最敏感的位点的刺激所激发的多巴胺通路,通常就是直接或间接地被自然奖励刺激所激发的多巴胺通路。在人类被试者中也观察到了与老鼠类似的效应。这些观察结果有效表明多巴胺神经元活动携带了奖励信息。
但是,如果奖励预测误差假说是正确的,即使它只解释了多巴胺神经元活动的某些特征,那么这种关于多巴胺神经元活动的传统观点也不完全正确:多巴胺神经元的相位反应表示了奖励预测误差,而非奖励本身。在强化学习的术语中,时刻\(t\)的多巴胺神经元相位反应对应于\(δ_{t-1} = R_t + \gamma V(S_t) - V(S_{t-1})\),而不是\(R_t\)。
强化学习的理论和算法有助于一致性地解释"奖励-预测-误差"的观点与传统的信号奖励的观点之间的关系。在本书讨论的许多算法中,\(\delta\)作为一个强化信号,是学习的主要驱动力。\(\delta\)的动作相关形式是Q学习和Sarsa的强化信号。奖励信号\(R_t\)是\(\delta_{t-1}\)的重要组成部分,但不是这些算法中强化效应的完全决定因素。附加项\(\gamma V(S_t) - V(S_{t-1})\)是\(\delta_{t-1}\)的次级强化部分,即使有奖励(\(R_t\neq 0\))产生,如果收益可以被完全预测,则TD误差也可以是没有任何影响的。事实上,仔细研究Olds和Milner 1954年的论文可以发现,这主要是工具性条件反射任务中电刺激的强化效应。电刺激不仅能激发老鼠的行为——通过多巴胺对动机的作用,还导致老鼠很快学会通过按压杠杆来刺激自己,而这种刺激会长时间频繁进行。电刺激引起的多巴胺神经元活动强化了老鼠的杠杆按压动作。
多巴胺神经元特别适合于向大脑的许多区域广播强化信号。如果多巴胺神经元像强化学习中的\(\delta\)是一个标量信号,那么SNpc和VTA中的所有多巴胺神经元会按照预期以相同的方式激活,并以近似同步的方式发送相同的信号到所有轴突的目标位点。尽管人们普遍认为多巴胺神经元确实能够像这样一起行动,但最新证据指出,多巴胺神经元的不同亚群对输入的响应取决于它们向其发送信号的目标位点和结构,以及信号对目标位点结构的不同作用方式。多巴胺具有传导RPE以外的功能。而且即使是传导RPE信号的多巴胺神经元,多巴胺也会将不同的RPE发送到不同的结构去,这个发送过程是根据这些结构在产生强化行为中所起的作用来进行的。
5 奖励预测误差假说的实验支持
多巴胺神经元以激烈、新颖或意想不到的视觉、听觉刺激来触发眼部和身体的运动,但它们的活动很少与运动本身有关。这非常令人惊讶,因为多巴胺神经元的功能衰退是帕金森病的一个原因,其症状包括运动障碍,尤其是自发运动的缺陷。
Romo和Schultz (1990)通过记录猴子移动手臂时多巴胺神经元和肌肉的活动开始向奖励预测误差假说迈出第一步。他们训练了两只猴子,当猴子看见并听到门打开的时候,会把手从静止的地方移动到一个装有苹果、饼干或葡萄干的箱子里。然后猴子可以抓住食物并吃到嘴里。当猴子学会这么做之后,它又接受另外两项任务的训练。第一项任务的目的是看当运动是自发时多巴胺神经元的作用。箱子是敞开的,但上面被覆盖着,猴子不能看到箱子里面的东西,但可以从下面伸手进去。预先没有设置触发刺激,当猴子够到并吃到食物后,实验者通常(虽然并非总是)在猴子没看见的时候悄悄将箱中的食物粘到一根坚硬的电线上。在这里,Romo和Schultz观察到的多巴胺神经元活动与猴子的运动无关,但是当猴子首先接触到食物时,这些神经元中的大部分会产生相位反应。当猴子碰到电线或碰到没有食物的箱子时这些神经元没有响应。这是表明神经元只对食物,而非任务中的其他方面有反应的很好的证据。第二个任务的目的是看看当运动被刺激触发时会发生什么。这个任务使用了另外一个有可移动盖子的箱子。箱子打开的画面和声音会触发朝向箱子的移动。在这种情况下,Romo和Schultz发现,经过一段时间的训练后,多巴胺神经元不再响应食物的触摸,而是响应食物箱开盖的画面和声音。这些神经元的相位反应已经从奖励本身转变为预测奖励可获得的刺激。在后续研究中,Romo和Schultz发现,他们所监测的大多数多巴胺神经元对行为任务背景之外的箱子打开的视觉和声音没有反应。这些观察结果表明,多巴胺神经元既不响应于运动的开始,也不响应于刺激的感觉特性,而是表示奖励的期望。
上述研究的观察结果使Schultz和他的小组得出结论:多巴胺神经元对不可预测的奖励,最早的奖励预测因子做出反应,如果没有发现奖励或者奖励的预测因子,那么多巴胺神经元活性会在期望时间内降低到基准之下。熟悉强化学习的研究人员很快就认识到,这些结果与时序差分算法中时序差分强化信号的表现非常相似。
6 TD误差/多巴胺对应
当动物学习任务时,TD误差与多巴胺神经元的相位活动有着共同的关键特征。但是并非多巴胺神经元的相位活动的所有性质都能与\(\delta\)的性质完美对应起来。最令人不安的一个差异是,当奖励比预期提前发生时会发生什么。我们观察到一个预期奖励的缺失会在奖励预期的时间产生一个负的预测误差,这与多巴胺神经元降至基准以下相对应。如果奖励在预期之后到达,它就是非预期奖励并产生一个正的预测误差。这在TD误差和多巴胺神经元反应中同时发生。但是如果奖励提前于预期发生,则多巴胺神经元与TD误差的反应不同--至少在Montague等(1996)使用的CSC表示与上述例子不同。多巴胺神经元会对提前的奖励进行反应,反应与正的TD误差一致,因为奖励没有被预测会在那时发生。然后,在后面预期奖励出现却没有出现的时刻,TD误差将为负,但多巴胺神经元的反应却并没有像负的TD误差的那样降到基准以下(Hollerman和Schultz, 1998)。在动物的大脑中发生了相比于简单的用CSC表示的TD学习更加复杂的事情。
一些TD误差与多巴胺神经元行为的不匹配可以通过选择对时序差分算法合适的参数,并利用其他刺激表示来解决。Pan、Schmidt、Wickens和Hyland (2005)发现使用CSC表示的同时,引入延迟的资格迹可以改进TD误差与多巴胺神经元活动的某些方面的匹配情况。一般来说,TD误差的许多行为细节取决于资格迹、折扣和刺激表示之间微妙的相互作用。这些发现在不否认多巴胺神经元的相位行为被TD误差信号很好地表征的核心结论下,细化了奖励预测误差假说。
值得一提的是,与多巴胺系统的性质如此契合的强化学习算法和理论完全是从一个计算的视角开发的,没有考虑到任何多巴胺神经元的相关信息--TD学习和它与最优化控制及动态规划的联系,是在任何揭示类似TD误差的多巴胺神经元行为本质的实验进行前很多年提出的。这些意外的对应关系,尽管还并不完美,却也说明了TD误差和多巴胺的相似之处抓住了大脑奖励过程的某些关键环节。
7 神经"演员-评论家"
"演员-评论家(Actor-Critic,AC)"算法同时对策略和价值函数进行学习。演员是算法中智能体学习策略的组件,评论家是算法中用于学习对演员的动作进行"评价"的组件,这个"评价"是基于演员所遵循的策略来进行的,无论这个策略是什么。评论家采用TD算法来学习演员当前策略的状态价值函数。价值函数允许评论家通过向演员发送TD误差\(\delta\)来评价一个演员的动作。根据这个评价,演员会持续更新其策略。
"演员-评论家"算法有两个鲜明特征让我们认为大脑也许采用了类似的算法。第一个是,AC算法的两个部分(演员和评论家)代表了纹状体的两部分(背侧和腹侧区)。对于基于奖励的学习来说,这两部分都非常重要。暗示大脑的实现是基于"演员-评论家"算法的第二个特征是,TD误差有着同时作为演员和评论家的强化信号的双重作用。这与神经回路的一些性质是吻合的:多巴胺神经元的轴突同时以纹状体背侧和腹侧区为目标;多巴胺对于调节两个结构的可塑性都非常重要;且像多巴胺一样的神经调节器如何作用在目标结构上取决于目标结构的特征而不仅取决于调节器的特征。下图展示了AC算法与大脑学习过程的类比结果。
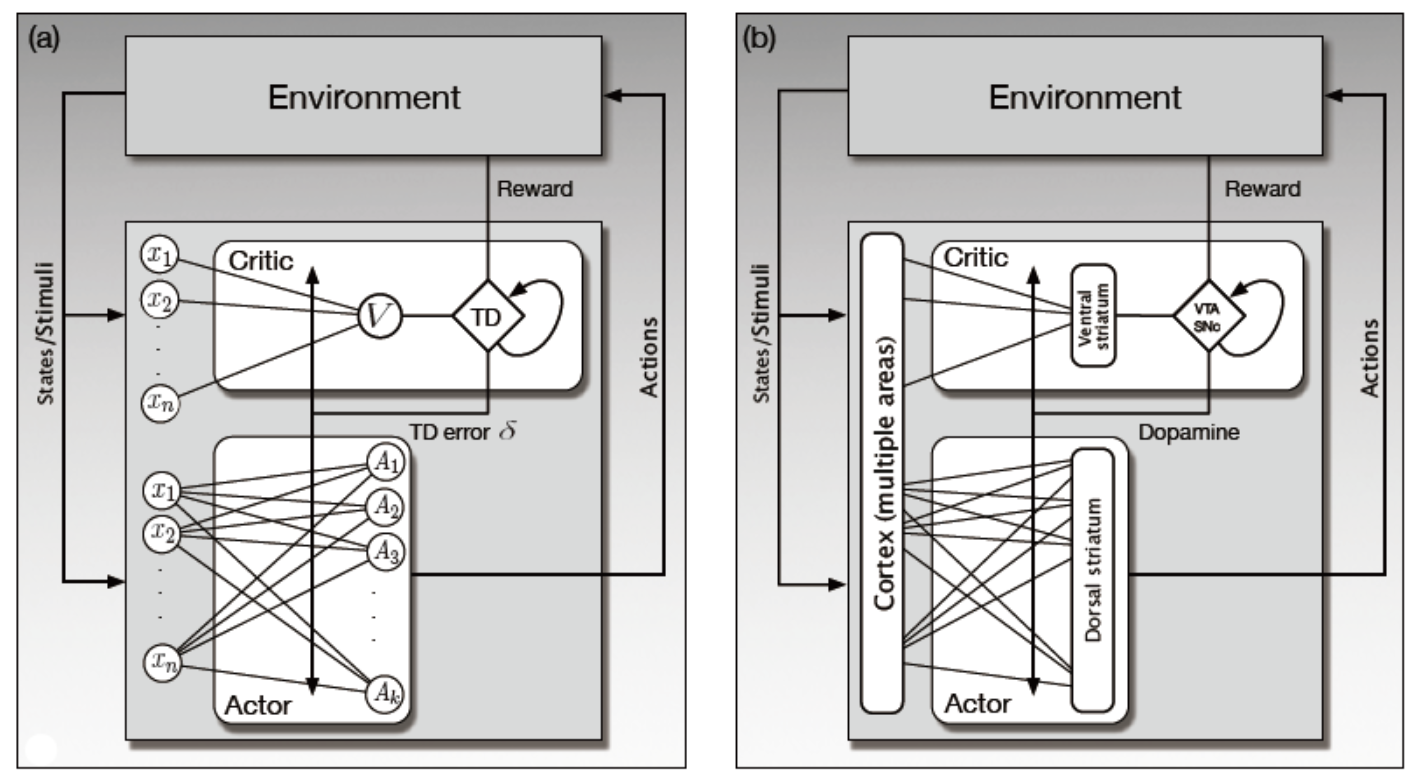
评论家和演员网络都可以接收多个特征,它们表示了智能体所在的环境的状态。从每个特征\(x_i\)到评论家单元\(V\)的连接,以及它们到每个动作单元\(A_i\)的连接都有一个对应的权重参数,表示突触的效能。通过评论家网络中的权重参数化价值函数,演员网络中的权重参数化策略函数。网络根据"演员-评论家"学习规则来改变权重进行学习。
在评论家神经回路产生的TD误差是改变的评论家和演员网络权重的增强信号。在上图的右图中展示了假设的一个重要的含义是:多巴胺信号不是像强化学习中\(R_t\)这样的奖励信号。事实上,这个假设暗示了人们并不一定能探测大脑并从任何单个神经元的活动中找出类似\(R_t\)的信号。奖励相关的信息是由许多相互联系的神经系统产生的,并根据不同的奖励采用不同的结构。多巴胺神经元从许多不同的大脑区域收集信息,所以对SNpc和VTA的输入应该被认为是从多个输入通道一起到达神经元的奖励相关信息的向量。理论上的奖励标量信号值\(R_t\)应该与对多巴胺神经活动有关的所有奖励相关信息的贡献相联系。这是横跨不同大脑区域的许多神经元的综合活动模式的结果。
8 演员与评论家学习规则
如果大脑真的实现了类似于"演员-评论家"的算法,并且假设大量的多巴胺神经元广播一个共同的强化信号到背侧和腹侧纹状体的皮质突触处,那么这个强化信号对于这两种结构的突触的影响是不同的。演员和评论家的学习规则使用的是同样的强化信号,即TD误差\(\delta\),但是这两个部分对学习的影响是不同的。TD误差(与有效循迹结合)告诉动物如何更新动作的概率以到达具有更高价值的状态。演员的学习有些类似于采用效应定律的工具性条件反射,演员的目标是使得\(\delta\)尽可能为正。另一方面,TD误差(当与有效轨迹结合时)告诉评论家价值函数参数改变的方向与幅值以提高其预测准确性。评论家致力于减小\(\delta\)的幅值,采用类似于经典条件反射中的TD模型的学习规则使幅值尽量接近于零。演员和评论家学习规则之间的区别相对简单,但是这个区别对于"演员-评论家"算法本质上如何起作用有着显著的影响,区别仅仅在于这两者学习规则使用的有效循迹的类型。下面给出针对连续性问题的AC算法。假设从状态\(S_t\)到状态\(S_{t+1}\)的转移过程中,智能体选取动作\(A_t\),并且得到奖励值\(R_{t+1}\),计算TD误差,然后更新有效循迹向量(\(z_t^w\)和\(z_t^\theta\)),和评论家与演员的参数(\(w\)和\(\theta\)),更新式为
其中,\(\gamma\in[0, 1)\)是折扣系数,\(\lambda^w\in[0, 1]\)和\(\lambda^\theta\in[0, 1]\)分别是评论家与演员的衰减率。\(\alpha^w > 0\)和\(\alpha^\theta > 0\)是步长。
从神经方面来说,这意味着每一个突触有着自己的有效循迹,并且是向量\(z^w_t\)的一个分量。一个突触的有效循迹,根据到达突触的活动水平,不断地累积,在这里由到达突触的特征向量\(x(S_t)\)的分量所表示。此外,这个有效循迹由参数\(\lambda^w\)所支配的速率向零衰减。当一个突触的有效循迹非零时,称其为可修改的。突触的功效如何被修改取决于突触可修改时到达的强化信号。我们称这些评论家单元的突触的有效循迹为非偶发有效循迹,这里因为它们仅仅依赖于前突触活动并且不以任何方式影响后突触活动。
与评论家突触只累积前突触活动的非偶发有效循迹不同,演员单元的有效循迹还取决于演员单元本身的活动,称其为偶发有效循迹。其强度在每个突触都会持续衰减,但是会根据前突触活动以及后突触神经元活动决定是否增加或减少。偶发有效循迹允许产生的奖励(正\(\delta\))或者接受的惩罚根据策略参数进行分配,其依据是这些参数对之后的\(\delta\)值的贡献。偶发有效循迹标记了这些突触应该如何修改才能更有效地导向正值的\(\delta\)。
评论家与演员的学习规则是如何改变皮质突触的功效的呢?两个学习规则都与Donald Hebb的经典推论相关,即当一个前突触信号参与激活一个后突触神经元时,突触的功效应该增加(Hebb, 1949)。评论家和演员的学习规则与Hebbian的推论共同使用了这么一个观点,那就是突触的功效取决于几个因素的相互作用。在评论家学习规则中,这种相互作用是在强化信号\(\delta\)与只依赖于前突触信号的有效循迹之间的。神经科学家称其为双因素学习规则。另一方面,演员学习规则是三因素学习规则,这是因为除了依赖于\(\delta\),其有效循迹还同时依赖于前突触和后突触活动。然后,与Hebb的推论不同的是,不同因素的相对发生时间对突触功效的改变是至关重要的,有效循迹的介入允许强化信号影响最近活跃的突触。
评论家与演员学习规则的信号之间的一些细微之处更加值得关注。在定义类神经评论家与演员单元时,我们忽略了突触的输入需要少量的时间来影响真正的神经元的放电。当一个前突触神经元的动作电位到达突触时,神经递质分子被释放并跨越突触间隙到达后突触神经元,并与后突触神经元表面上的受体结合;这会激活使得后突触神经元放电的分子机制(或者在抑制突触输入情况下抑制其放电)。这个过程可能持续几十毫秒。但是,AC算法对评论家与演员单元进行输入,会瞬间得到单元的输出。更加真实的模型则必须要将激活时间考虑进去。
神经科学已经提示了这个过程是如何在大脑中起作用的。神经科学家发现了一种被称为脉冲时序依赖可塑性(STDP)的赫布式可塑性,这似乎有助于解释类演员的突触可塑性在大脑中的存在。STDP是一种Hebbian式可塑性,但是其突触功效的变化依赖于前突触与后突触动作电位的相对时间。这种依赖可以采取不同的形式,但是最重要的研究发现,如果脉冲通过突触到达且时间在后突触神经元放电不久之前,则突触强度会增加。如果时间顺序颠倒,那么突触的强度会减弱。STDP是一种需要考虑神经元激活时间的Hebbian式可塑性,这是类演员学习所需要的一点。
STDP的发现引导神经科学家去研究一种可能的STDP的三因素形式,这里的神经调节输入必须遵循适当的突触前和突触后脉冲时间。这种形式的突触可塑性,被称为奖励调节STDP,其与演员学习规则十分类似。常规的STDP产生的突触变化,只会发生在一个突触前脉冲紧跟着突触后脉冲的时间窗口内神经调节输入的时候。越来越多的证据证明,基于奖励调节的STDP发生在背侧纹状体的中棘神经元的脊髓中,这表明演员学习在"演员-评论家"算法的假想在神经实现中确实发生了。实验已经证明基于奖励调节的STDP中,皮质纹状体突触的功效变化只在神经调节脉冲在前突触脉冲以及紧跟着的后突触脉冲之间的10 s的时间窗口内到达才会发生(Yagishita et al., 2014)。尽管证据都是直接的,但这些实验指出了偶发有效循迹的存在延续了时间的进程。产生这些迹的分子机制以及可能属于STDP的迹都要短得多,而且尚未被理解,但是侧重于时间依赖性以及神经调节依赖性的突触可塑性的研究依然在继续。
9 享乐主义神经元
在享乐主义神经元假说中,Klopf (1972, 1982)猜测,每一个独立的神经元会将突触的输入作为奖励和惩罚,并尽可能最大化它们之间的差异,这种最大化是通过调整它们的突触功效来实现的。他的假说包含这样的思想:奖励或者惩罚通过相同的突触被输入到神经元,并且会激发或者抑制神经元的脉冲释放活动。Klopf推断突触功效通过如下方式变化。当一个神经元发放出一个动作电位时,它的所有促进这个动作电位的突触有资格来获得其功效的变化。例如,如果一个动作电位在奖励值在一个适当的时间内被触发提升,那么所有有资格的突触的功效都会提升。对应地,如果一个动作电位在惩罚值在一个适当时间内被触发提升,那么所有有资格的突触功效都会下降。
Klopf理论中有效循迹的形状与时间因素反映了神经元所处的许多反馈回路的持续时间,其中的一些完全位于机体的大脑和身体内,而另一些则通过运动与感知系统延伸到机体外部的环境中。本书中的算法使用的有效循迹是Klopf原始想法的一个简化版本,通过由参数\(\lambda\)和\(\gamma\)控制的指数下降的函数实现。
一个被充分研究的单细胞寻求某些刺激而避免其他刺激的例子是大肠杆菌。 这种单细胞生物的运动受到环境中化学刺激的影响,这种行为被称为趋化性。 它在液体环境中游动,靠的是附着在体表的毛发状结构——鞭毛。 (是的,它会旋转它们!) 细菌环境中的分子与细菌表面的受体结合。 根据环境调节细菌逆转鞭毛旋转的频率。 每次逆转都会导致细菌在原地翻滚,然后朝着一个随机的新方向前进。 一点点的化学记忆和计算会改变鞭毛逆转的频率,使得细菌在其生存所需的高浓度分子(引诱剂)时频率减少,而当细菌在高浓度有害分子(驱虫剂)时频率增加。 结果就是,细菌倾向于游向引诱剂浓度高的地方,并倾向于避免游向驱虫剂浓度高的地方。
Klopf的享乐主义神经元假说超出了单个神经元是强化学习智能体的观点。他认为智能的许多方面可以被理解为是具有自私享乐主义的神经元群体的集体行为的结果,这些神经元在构成动物神经系统的巨大的社会和经济系统中相互作用。无论这个观点对神经系统是否有用,强化学习智能体的集体行为对神经科学是有影响的。
10 集体强化学习
强化学习智能体群体的行为与社会以及经济系统的研究高度相关。如果Klopf的享乐主义神经元假设是正确的,则其与神经科学也是相关的。上文描述的人类大脑实现"演员-评论家"算法的假说,仅仅在狭窄的范围内契合了纹状体的背侧与腹侧的细分。根据假说,它们分别对应演员与评论家,每一个都包括数以百万计的中棘神经元,这些中棘神经元的突触改变是由多巴胺神经元活动的相位调制引起的。
当强化学习智能体群体的所有成员都根据一个共同的奖励信号学习时,强化学习理论可以告诉我们什么?在多智能体强化学习(以及博弈论)中,所有的智能体会尝试最大化一个同时收到的公共奖励信号,这种问题一般被称为合作游戏或者团队问题。
团队问题有趣且具有挑战性的原因是送往每个智能体的公共奖励信号评估了整个群体产出的模式,即评估整个团队的集体动作。这意味着每个单独的智能体只有有限的能力来影响奖励信号,因为任何单个的智能体的贡献仅仅是公共奖励信号评估的集体动作的一个部分。在这个情境下,有效的学习需要解决一个结构化功劳分配问题:哪些团队成员,或者哪组团队成员,值得获得对应于有利的奖励信号的功劳,或者受到对应于不利的奖励信号的惩罚?这是一个合作游戏,或者说是团队问题,因为这些智能体联合起来尝试增加同一个奖励信号:智能体之间是没有冲突的。竞争游戏的情境则是不同的。智能体收到不同的奖励信号,然后奖励信号在一起评估群体的集体动作,且每一个智能体的目标是增加自己的奖励信号。在这种情况下,可能会出现有冲突的智能体,这意味着对于一些智能体有利的动作可能对其他智能体是有害的。甚至决定什么是最好的集体动作也是博弈论的一个重要问题。这种竞争的设定也可能与神经科学相关(例如,多巴胺神经元活动异质性的解释),但是在这里我们只关注合作或者说团队配合的情况。
在强化学习中,团队的每个智能体如何学会“做正确的事”,从而使团队的集体行动得到最高奖励? 一个有趣的结果是,如果每个智能体能够有效地学习,尽管其奖励信号被大量噪声所破坏,尽管其无法获得完整的状态信息,但是智能体将学会产生集体行动,并根据共同的奖励信号进行评估,即使在智能体无法相互通信的情况下。 每个智能体都面临着自己的强化学习任务,在这个任务中,它对奖励信号的影响深埋在其他智能体影响产生的噪声中。 事实上,对于任何智能体,所有其他智能体都是其环境的一部分,因为它的输入,包括传递状态信息的部分和奖励部分,都取决于所有其他智能体的行为。 此外,由于无法访问其他智能体的操作,实际上也无法决定其策略的参数,每个智能体只能部分地观察其环境的状态。 这使得每个团队成员的学习任务变得非常困难,但如果每个智能体都能够使用强化学习算法在这些困难条件下增加奖励,那么可以学习到集体行动,并提高团队的奖励。
在团队环境中,使用非偶发有效循迹进行学习根本不起作用,因为它没有提供一种将行为与奖励信号的后续变化联系起来的方法。 非偶发有效循迹对于学习预测是足够的,就像AC算法的评论家组件所做的那样,但是它们不支持学习控制,就像演员组件必须做的那样。 像评论家群体中的成员可能仍然会接收到一个共同的强化信号,但它们都将学会预测相同的数值(在行为-批评方法的情况下,这将是当前策略的预期回报)。 群体中的每一个成员在学习预测预期收益方面的成功程度将取决于它收到的信息,而对于群体中的不同成员来说,这些信息可能是非常不同的。
在集体学习问题中的第二个要求是,团队成员的行动必须具有可变性,以便团队探索集体行动的空间。 对于一个强化学习智能体团队来说,最简单的方法是让每个成员通过其输出的持续变化来独立探索自己的行动空间。 这将导致团队作为一个整体改变其集体行动。
11 大脑中的基于模型的算法
对强化学习中无模型和基于模型的算法进行区分已经被证明对于研究动物的学习和决策过程是有用的。14章第8节讨论了如何区分动物的习惯导向行为与目标导向行为。上文讨论的关于大脑可能如何使用"演员-评论家"算法的假说仅仅与动物的习惯性行为模式有关,这是因为基础的"演员-评论家"算法是无模型的。那么怎样的神经机制负责产生目标导向行为,又是如何与潜在的习惯行为相互作用的呢?
研究与这些行为模式有关的大脑结构问题的一种方法是使老鼠大脑的某个区域失活,然后在结果贬值实验中观察老鼠的行为。 这些实验的结果表明,上面描述的演员-评论家假说过于简单,将演员部分置于背纹状体。 背侧纹状体(DLS)的一部分失活会损害习惯学习,导致动物更多地依赖于目标导向的过程。 另一方面,背内侧纹状体(DMS)的失活会损害目标导向过程,要求动物更多地依赖习惯学习。 这些结果支持了啮齿动物的DLS更多地参与无模型过程,而DMS更多地参与基于模型的过程的观点。 使用功能性神经影像对人类的研究以及对非人灵长类动物的研究结果都支持类似的观点:大脑的不同结构分别对应于习惯性和目标导向的行为模式。其他的研究确定了目标导向的活动与大脑前额叶皮质有关,这是涉及包括规划与决策在内的执行功能的额叶皮质的最前部分。具体涉及的部分是眶额皮质(OFC),为前额叶皮质在眼睛上部的部分。
另一个涉及基于模型的行为的结构是海马体,它对记忆与空间导航非常重要。一些发现直接揭示了海马体在规划过程中起到重要的作用,这里的“规划过程”就是指在进行决策时引入外部环境模型的过程。这些结果表明,海马体对于动物的环境模型的状态转移非常重要,而且它是用于模拟将来可能的状态序列以评估可能的动作方案的系统的一部分,这就是一种"规划"过程。
12 成瘾
了解药物滥用的神经基础是神经科学的一个高度优先的目标,有可能为这一严重的公共卫生问题产生新的治疗方法。 一种观点认为,药物渴望是同样的动机和学习过程的结果,这些动机和学习过程导致我们寻求满足我们生物需求的自然奖励体验。 使人上瘾的物质通过强烈的强化作用,有效地吸收了我们学习和决策的自然机制。 鉴于许多(尽管不是所有)滥用药物直接或间接地增加纹状体多巴胺神经元轴突末梢周围区域的多巴胺水平,这是合理的,纹状体是与正常的基于奖励的学习密切相关的大脑结构(第15.7节)。 但与药物成瘾相关的自我毁灭行为并不是正常学习的特征。 当奖励是成瘾药物的结果时,多巴胺介导的学习有什么不同? 在我们的进化史上,这些物质在很大程度上是不可获得的,因此进化无法选择对抗它们的破坏性影响,而成瘾是正常学习对这些物质的反应的结果吗? 或者成瘾物质会以某种方式干扰正常的多巴胺介导的学习?
多巴胺活动的奖励预测误差假说及其与TD学习的联系是Redish (2004)提出的包括部分成瘾特征的模型的基础。基于对该模型的观察。可卡因和一些成瘾药物的使用会导致多巴胺的短暂增加。在模型中,这种多巴胺激增被认为是增加了TD误差,其中\(\delta\)是不能被价值函数变化抵消的。换句话说,虽然\(\delta\)被降低到可以通过预测正常奖励的程度(第15.6节),但由于成瘾刺激对\(\delta\)的贡献并不会随着奖励信号被预测而减少:药物奖励不能被预测所减小。当奖励信号是由成瘾药物引起时,该模型通过防止\(\delta\)变为负值来实现这一点,从而消除了与药物管理相关的TD学习状态的纠错功能。 结果是,这些状态的值无限制地增加,使得导致这些状态的行为优先于所有其他状态。成瘾行为比Redish模型得出的结果要复杂得多,但该模型的主要思想可能显示了这个难题中的一个侧面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号