
强化学习读书笔记 -- 第十四章心理学与强化学习
在前面的章节中,主要从计算机的角度考虑强化学习算法的思想。 在本章中,将从另一个角度来看待这些算法:心理学的角度及其对动物如何学习的研究。 强化学习提供的清晰的体系架构将任务、回报和算法系统化,在理解实验数据、提出新的实验类型、理解可能对控制和测量至关重要的因素方面被证明是非常有用的。 优化长期回报的理念是强化学习的核心,它有助于我们理解动物学习和行为的其他令人困惑的特征。
1.预测和控制
本书中描述的算法分为两大类:预测算法和控制算法。在许多方面,这些类别分别对应于心理学家广泛研究的学习类别:经典条件反射(即巴甫洛夫条件反射)和操作性条件反射。
经典条件反射是动物在得到奖赏(如狗得到食物)时,会自动学习并记住当时环境的重大变化信息,比如当时有铃声响起,或者有一个穿白大褂的人过来。同样的情况重复若干次之后,动物逐渐学会预测,只要听到铃声响起,或来了个穿白大褂的家伙,就意味着有食物要来了。于是自动分泌唾液以便消化食物。
神经科学的研究已经知道,动物建立铃声与食物之间的联结的学习过程是靠多巴胺介导实现的。分泌唾液可以看作是动物看到食物或刺激信号后的一种反应(R)。铃声或白大褂通常被称为条件刺激(conditioned stimulus,CS),它们原本与食物(非条件刺激US(unconditioned stimulus))无关,但由于它们总是一起出现,于是被动物认为两者有关联,于是做出同样的反应(分泌唾液)。
操作性条件反射(也称为工具性条件反射)是动物得到奖赏(比如老鼠得到食物)时,会自动把自己最近所做的行为(如按下杠杆),与奖赏建立起联结,并记忆下来。多次重复后,动物就学会了,见到杠杆就按,按了就会有食物。
从预测的角度考虑经典条件反射,从控制的角度考虑操作性条件反射,这是将强化学习的观点与动物学习联系起来的起点,但实际上,情况比这更复杂。经典条件反射不仅仅是预测,它也涉及行动,是一种控制模式,有时被称为巴甫洛夫控制。此外,经典条件反射和操作性条件反射以有趣的方式相互作用,在大多数实验环境中,这两种学习都可能发生。在心理学中,术语”强化“被用来描述经典条件反射和操作性条件反射中的学习。最初仅指行为模式的加强,它也经常用于行为模式的削弱。
2.经典条件反射
经典条件反射描述的是一种刺激最初是中性的,即它通常不会引起强烈的反应(例如节拍器的声音),当动物知道它预测了非条件性刺激,开始产生条件反应(CR)来响应条件刺激时,它就变成了“条件刺激”(CS)。
在研究消化系统的活动时,著名的俄罗斯生理学家伊万·巴甫洛夫(Ivan Pavlov)发现,动物对某些触发刺激的先天反应(UR),可能会被与先天触发因素完全无关的其他刺激所触发。他的实验对象是经过小手术的狗,以便精确测量它们的唾液反射强度。在他描述的一个案例中,狗在大多数情况下都不会分泌唾液,但在给它食物大约5秒后,它在接下来的几秒钟内产生了大约6滴唾液。在多次重复另一个与食物无关的刺激,在这个例子中是节拍器的声音,在引入食物前不久,狗对节拍器的声音做出了反应,就像它对食物的反应一样。“唾液腺的活动因此被声音的冲动所调动——一种与食物完全不同的刺激”(巴甫洛夫,1927年,第22页)。
在实验中已经观察到经典条件作用的许多有趣的特性。除了预期结果外,在经典条件反射模型的发展中,还有两个被广泛观察到的特性:阻塞条件反射和高阶条件反射。
阻塞条件反射是指已经建立联结的刺激会阻碍另一种刺激建立联结。例如,在涉及兔子眨眼条件反射阻塞实验 的第一阶段,兔子首先被给出一个声音的CS和向眼晴吹气的US,从而导致利用声音预测接下来的吹气从而眨眼保护,这是条件反应(CR);这个实验的第二阶段中,则在给出声音的同时额外加入第二个刺激,例如光,然后看经过试验后,能否用这个新加入的刺激导致CR,结果发现是不行的,对光这人刺激的响应被先前的声音这个刺激阻塞了。这种阻塞的效果挑战了认为条件反射只依赖时间相近度的想法(US紧跟CS就能使CS引发CR)。经典模型Rescorla-Wagner模型是给出阻塞条件反射的一个很有影响的解释。
高阶条件反射是指一个条件反射连接另一个条件反射。例如把一个先前的已经训练好的引发响应的CS作为US,利用它使另外一个中性的刺激产生同样的UR。巴甫洛夫描述的一个实验中,他的助手首先让狗对节拍器的声音产生条件反射,然后再把节拍器的声音作为US,试图让狗对一人黑色方块也产生条件反射,(此过程即先给狗看黑色方块,然后马上给节拍器的声音,而不给食物)。仅仅经过十次训练后,黑色方块就能引发狗流口水了,这个过程中节拍器的声音起到了US的作用。这就是二阶条件反射,依次类推,还可以产生三阶乃至更高阶的反射。高阶反射的训练是很难的,因为高阶的增强子失去了原始增强子的根本价值。但在适当的条件下,高阶反射也是能训练出来的。经典条件反射的TD模型使用了 bootstrapping思想,这也是Rescorla-Wagner模型的核心,可以同时解释阻塞与高阶条件反射。
3.Rescorla-Wagner模型
Rescorla和Wagner主要针对阻塞条件反射构建了模型。其核心思想是,动物只有在事情与期望偏离时才进行学习。根据Rescorla和Wagner描述,模型调整复合CS中每个成员刺激的连结强度(associative strength),该连结强度代表这个成员对US的预测强度或可靠度。当一个复合CS包含多个成员刺激时,每个成员刺激的连结强度依赖于复合刺激整体的连结强度而变化,而不是仅仅依赖每个成员自身的连结强度,这个整体连结强度叫做聚合连结强度(aggregate associative strength)。
Rescorla-Wagner模型为
其中,\(\alpha_A\beta_Y\)和\(\alpha_X\beta_Y\)是步长因子,依赖CS成员\(\{A,X\}\)和US\(\{Y\}\)的性质,\(R_Y\)则是\(Y\)能提供的连结强度的渐进水平,\(V_A,V_X,V_{AX}\)分别表示条件刺激\(A,X\)和复合条件刺激\(AX\)的各自连结强度。这个模型的关键假设是,聚合连结强度\(V_{AX}=V_{A}+V_{X}\) 。这些连结强度变化\(\Delta V_A,\Delta V_X\)会影响下轮试验中的连结强度。
通过上述模型可以看出,当复合连结强度\(V_{AX}\)低于US强度\(R_Y\),那么通过后面的实验两个条件刺激强度都会得到增加。若在新加入的条件刺激之前,连接强度就已经逼近或者达到\(R_Y\),则新加入的CS就不会再有效果,从而出现了阻塞条件反射现象。这里的连结强度是不可能超过\(R_Y\)。
4.TD模型
将Rescorla-Wagner模型类比TD模型。假设训练类型(状态)\(s\)用一个实数向量描述\(x(s) =[x_1(s),x_2(s),\cdots,x_d(s)]^\Tau\),其中\(x_i(s)\)类比在试验中条件刺激成员\(CS_i\),若某条件刺激成员被采用,那么对应的位置元素为1,否则就是0。连结强度可以表示为一个\(d\)维向量是\(w\),则聚合连结强度为
它可以作为对US的预测。通过不断进行条件反射训练,连结强度向量的更新式为
其中,\(\alpha\)是步长因子,\(\delta_t = R_t - \hat{v}(S_t,w_t)\),\(R_t\)是第\(t\)次试验中的预测目标,US的幅值,或称为连结强度。\(\delta_t\)可以被认为是预测误差,。是惊讶程度的度量,这与动物触发学习的核心思想是一致的。下图展示的是实验过程中的数据,条件刺激B的加入,(这里需要注意的是CSB和CSA是分别出现的),可以对CSA的连结强度起到促进作用。这也可以由Rescorla-Wagner模型来进行解释。
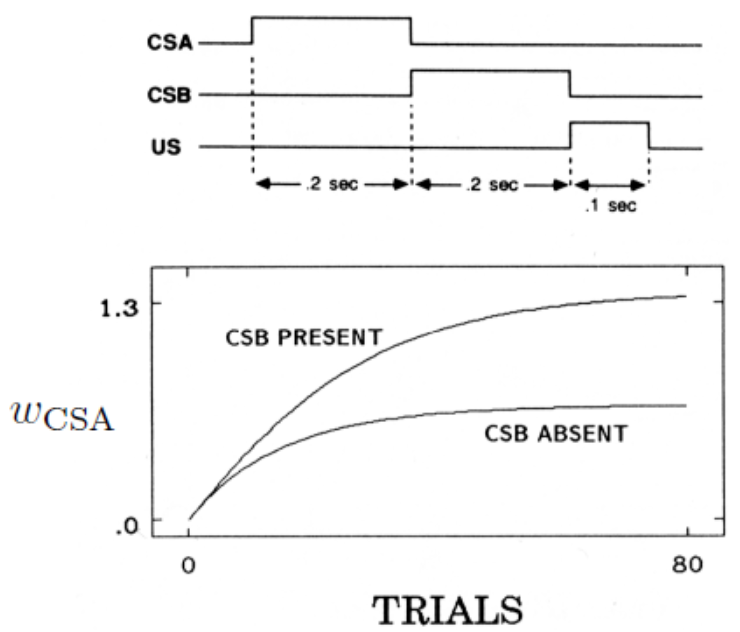
但TD模型具有更广的解释能力。Rescorla-Wagner模型无法将多个条件刺激的时序关系纳入考虑,也无法解释原先的CS被新加入的CS阻塞的情况。例如下面两种情况。
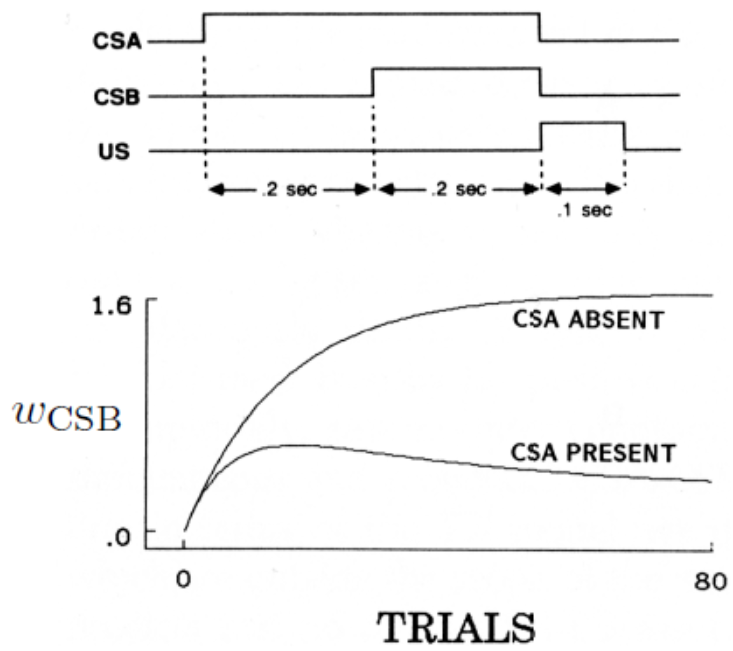
上图展示的是第一种情况,当CSA的作用时间与CSB相重合,CSA的出现对CSB会有明显的抑制作用。
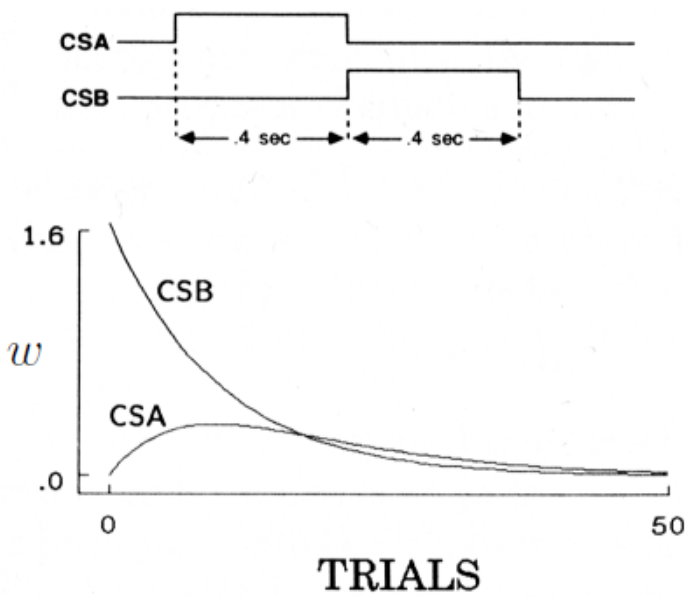
上图展示的是第二种情况,这是一种高阶条件反射现象。生物反射系统会调控两种条件刺激的连结强度,最后趋于一致。
5.操作性条件反射
在操作性条件反射(instrumental conditioning)实验中,学习依赖于行为的结果。不同于经典条件反射实验,非条件性刺激(US)的传递依赖于动物的行为而产生变化。操作性条件反射这个术语来表示增强因行为而变化的实验,其起源于美国心理学家Edward Thorndike一百多年前做的实验。
Thorndike在实验中观察了放入带有逃出开关的盒子的猫,如下图所示。逃出的动作可根据需要设置,例如猫可以通过执行包含三个动作的序列的盒子:压下盒子后的平台、用爪子拉一根绳子、把门闩从水平状态调整到竖直状态。第一次放入盒子时,在盒子的外面放置能看到的食物,只有一小部分的猫表现出了“不舒服的明显表现”以及“特别活跃的试图逃出盒子的活动”。
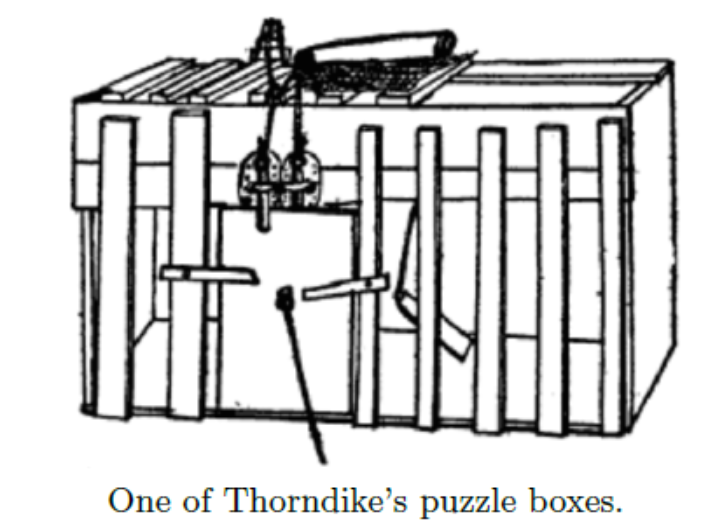
在使用不同的猫以及具有不同逃出机制的实验中,Thorndike记录下了每只猫在多次实验中逃出去所需要的时间。他观察到成功逃出的经验能让猫明显地缩短之后的逃出时间(300s到6~7s)。他这样描述盒子中猫的行为:
猫会在盒子中不断地用爪子四处乱抓,会偶然地碰到设置的绳子、环和按钮。逐渐的,所有对那些不成功位置的抓的动作就会减少,而成功的那些则会增加。最后,经过多次训练后,只要一把 猫放入盒子中,它就能立刻去执行设定好的逃出动作。
这些实验使得Thorndike总结出了一系列学习的规律,最有影响力的当属"效果法则(Law of Effect)” 这个法则描述了反复试验的中的学习过程。这与强化学习的思想相一致,效果法则描述了将搜索和存储结合的基本方法:在每个情形下尝试各种动作以找到最好的动作,并记录下状态与最佳动作的映射关系。搜索和存储是所有RL算法中必需的部分,其中存储又可以表现为策略、值函数,或者环境模型等形式。
著名的动物学习研究者Clark Hull和B.F.Skinner也受到了效果法则的影响。他们研究的核心即基于结果的行为选择。强化学习与Hull的理论具有共同的特征,包括有效循迹机制和用来解释在动作和其强化刺激之间存在较长时间间隔的学习能力的二阶增强。随机性在Hull的理论中也存在,他称之为行为震荡,这用来引入探索性行为。
例如,Skinner通过持续的递进的强化训练动物使其达到期望的行为,他把这个过程叫做shaping。他和同事尝试通过训练鸽子用嘴拍打木球来投球。在等待很久都没发现增强鸽子击打现象后,他们决定增强任何与击打有一些相似的响应,首先是仅仅看着这个球,然后选择和最终形式更相似的一些响应。结果让人很吃惊,鸽子能够很好的打球了。shaping是强化学习系统中强有力的技巧。当对于智能体接收非零的回报信号有困难时(要么是由于回报的稀疏性,要么是由于难解的初始行为),从一个简单的问题开始,逐渐增加其难度会显得很有效,甚至是不可缺少的策略。
6.延迟的强化
这个标题可能比较奇怪,它表达意思的是,在某些情况下,给予条件刺激后,直到激发非条件刺激,它们之间是存在延迟的,例如前面所提到的狗分泌唾液。而在这段延迟的时间段内,可以在添加新的条件刺激,这也意味着可以再学习。强化学习算法包含了这两个问题的解决机制,对于存在延迟的情况,TD方法能够有效的学习价值函数,从而为动作的选择提供可以预测的目标;对于再学习的情况,可以使用有效循迹,可以给一串动作的轨迹实现信用分配。
巴甫洛夫指出,每个刺激都会在神经系统中留下轨迹,而这些轨迹在刺激消失后也会持续一段时间。他还提在CS结束和US开始之存在时间间隔时,刺激轨迹使得学习成为可能。到今天为止,这些条件下的条件反射被称为轨迹条件反射。假设当US到达时,CS的轨迹还没消失,那么就能产生学习作用。
7.认知映射
动物是否利用环境模型?如果可以利用的话这些模型是什么样的?它们是怎么被学到的?在动物学习研究的历史中,这些问题是很有影响的。研究者提出了潜在学习(latent learning)的观点,这对学习和行为的刺激-响应观点(即策略学习的最简单的model-free架构)构成了挑战。在最早的潜在学习研究中,人们研究了在迷宫中奔跑的两组小鼠,对于实验组,最初是没有任何回报(食物)的(第一阶段),但是到了第二阶段则突然把食物放到目标盒子中:对控制组,食物则在两个阶段都在盒子。问题是,实验组中的小鼠在第一阶段(没有回报)能学习到一些东西吗?结果表明,虽然实验组小鼠在第一阶段看起来没学到什么,但是进入第二阶段后其表现会迅速追上控制组,也就是说,在无回报阶段,小鼠进行了潜在学习,这些学习在有必要的时候就会发挥作用。
心理学家EdwardTolman认为上述小鼠迷宫实验或类似实验表明,动物能在没有回报和惩罚时学习“环境的认知映射”,当动物收到激励去前往目标时,它们就可以利用这些认知映射。认知映射甚至能让小鼠规划一条与最初探索阶段不同的路线。关于这个结果的解释引发了心理学中行为学与认知学两个角度的长期争议。在现代术语中,认知映射不局限于时空布局的模型上,也指更一般的环境模型,或者说动物的任务空间。认知模型对潜在学习的解释就好像是说动物也使用基于模型的算法一样,且即使在没有明显的回报和惩罚时,该模型仍然能得到学习,而一旦出现回报和惩罚,则动物就能利用模型进行规划。博主觉得在强化学习中实现认知映射,可以引入内驱力(例如,好奇)作为奖励信号,从而在有限时间内探索环境。
8.习惯和目标引导的行为
model-free和model-based RL算法的区别对应着心理学家所谓的学到行为模式的习惯控制和目标导向控制的别。习惯就是受到适当的刺激激发自接下来能或多或少地自动执行的行为模式;目标导向行为,则是受到目标价值与行动及其结果之关系的知识控制的。有时候习惯也被称为受到以前的刺激所控制;目标引导行为则被称为受其结果的控制。目标导向控制是有优势的,当环境改变了对动物动作的回应时,它能快速地改变动物的行为。而习惯行为则对环境的响应很快,但是无法对环境的变化快速调整。目标导向行为控制的发展可能是动物智力进化的一大进步。
在小鼠迷宫任务中,小鼠需要在有不同目标盒子的迷宫中穿行,每个目标盒子都有不同程度的回报。下图示意了实验场景的设置以及model-free和model-based决策策略的差别。从状态\(S_1\)出发,小鼠可选的动作为左或者右,然后到达状态\(S_2\)或者\(S_3\),在新状态上再次选择动作,最终得到不同程度的回报,得到回报后该episode就结束了。model-free策略依赖于存储的状态-动作对的值,这些动作值表示小鼠在该获态执行某动作后能得到的最大回报的期望,是通过多次尝试得到的。当值变得足够好的时候,小鼠就可以不探索了,直接在每个状态下选择最大值的那个动作就可以了;model-free也可以直接存储一个策略(策略梯度思想)。但是无论哪种model-free方法,都是不依赖环境模型的,没必要去查询状态转移模型,也不需要学习目标盒子的特征与其能带来的回报之间的关联。
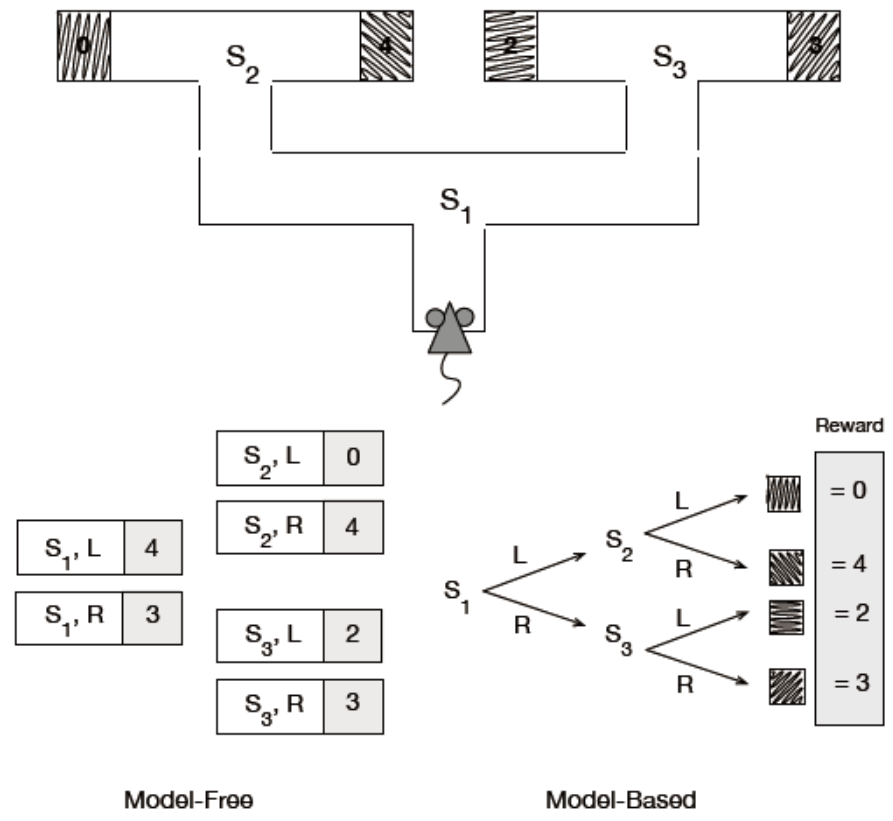
当model-free智能体的环境对其动作的反馈发生变化时。例如,改变上述小鼠实验中一个目标盒子中的回报,那么小鼠就不得不重新遍历这个迷宫多次从而发现这个变化,然后据此修正其策略或者值。也就是,对于model-free的智能体来说,如果要改变策略中某个状态/动作的值,它必须去访问那个状态/状态动作对,从而得到改变行为之后的值。
而model-based智能体则好很多,能容忍环境的变化。模型的变化会自动地改变策略。规划能确定出环境变化导致的后果,而与智能体自身的经验没有关联。例如,对于上述小鼠实验,如果我们把\(S_2\)右侧的回报值改为1,那么由于在之前的模型中这个值是最好的,小鼠还是会前往这个位置,但是会立刻发现这个值变化,从而更新了回报模型,并在下一轮中会基于新的模型改变自身行动。
以上逻辑是动物的结果贬值实验(outcome-devaluation experiments)的基础。这些实验的结果从侧面解释了动物到底是基于目标导引控制学习的还是仅仅学习了一个习惯。结果贬值实验就像潜在学习实验一样,都是在实验阶段变化的时候使回报也变化。
最早由Adams和Dickinson做了这个类型的实验,他们通过工具性条件反射训练小鼠,直到小鼠能积极地按压获得糖丸的按钮。然后把按钮去掉并放置非偶然性的食物,使得糖丸与小鼠的动作脱钩。在15分钟后,将小鼠分成两组,对其中一组注射使之恶心的氯化锂。以上过程重复三轮,发现被注射的小鼠不再去吃非偶然性的食物了,这意味看糖丸的回报值降低了。下一阶段则在一天后进行,再次把小鼠放到腔中,并进行一次消失性训练:把按钮放回去,但是按下按钮不再出现食物。 结果表明,被注射过的小鼠的反应降低了很多。注意,虽然小鼠被注射过,但是其并不是针对按下按键获得食物这个情形进行的,但是仍然造成了影响。
Adams和Dickinson总结到,被注射的小鼠把按下按键与恶心结合了起来,即通过认知映射把按下按键和糖丸联系,再把糖丸和恶心联系。因此,在消失实验中,小鼠能够意识到按下按钮会出现不希望发生的事情。这其中的要点是,小鼠并没有直接经历按下按钮导致恶心的经验!小鼠看起来是能够把行为性选择导致结果的知识和结果引发的回报的知识结合起来,并能因此改变自身的行为。不是每个心理学家者都同意这种实验的认知角度的解释,这也不是解释这个现象的唯一方式,但是model-based的规划解释被广泛接受。
可以同时使用model-free和model-based算法,如果有足够的重复,目标导向的行为就会趋向于转变为习惯。实验表明,小鼠也会出现目标导向控制向习惯行为的转变。Adams做了一个实验,以研究长期的训练是会把目标导引的行为转变为习惯性行为。Adams在对小鼠进行结果贬值实验的第一阶段对小鼠进行不同时间的训练,如果训练时间更长的小鼠的结果衰减效果与其他相比差,那就说明了确实有转换为习惯性行为的趋势。结果表明,在注射氯化锂使之恶心阶段,两组小鼠都降低了糖丸的回报值;在消失实验中,则过训练的小鼠明显地减弱了衰减效果,实际上虽然注射氯化锂,但是仍然去按键。结果表明,没有过训练的小鼠是受目标导向驱动的,而过训练的小鼠则是受习惯导向的。
从计算的视角看待这个现象以及其他类似的结果很有启发性。例如,为什么有时候希望动物受习惯驱动,有时侯希望其受目标驱动呢?为什么通过更长时间的学习会导致驱动方式发生变化呢?计算神经科学家Daw,Niv和Dayan提出,动物实际上是同时使用model-free和model- based过程的。每个过程都给一个动作,然后根据两个过程的置信度确定到底使用哪个。在学习的早期,model-based的规划过程更可信,因为它实际上是将一系列短期预测串联起来,而短期预测只需要很少的经验信息就能很准确;但是随着继续训练,model-free过程则变得越来越可信,这是因为规划过程依赖模型,而模型总是有误差的,并且模型也会因剪枝作用被简化,以便于高速的规划。根据这个思想,随着训练加深,指导动物行为的则会从自标导引过度为习惯导引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号