
强化学习读书笔记 -- 第十章基于函数近似的在线策略控制
与第九章相比,第十章考虑的是控制问题即寻找最优策略,那么本章近似的价值函数将是动作价值函数\(q(s,a,w)\)。
1.回合制的半梯度控制
与第九章的基于的梯度下降的参数更新核心方式类似,考虑状态-动作对的映射关系\(S_t,A_t\mapsto U_t\),可得
比如,对单步Sarsa来说,参数更新为
也称为回合制半梯度单步Sarsa。给定一个策略来说,该方法的收敛性与TD(0)一致。TD算法与Sarsa算法的区别在于一个是针对状态价值而另一个是针对动作价值。与广义策略迭代思想一致,在交互过程中,根据动作价值采用随机策略选择动作,并改进策略。该算法是伪代码如下图所示。

2. 半梯度n步Sarsa
根据第七章所学内容,定义\(n\)步回报为
其中,当\(t+n\geq T\)时,\(G_{t:t+n}=G_t\)。对应的Sarsa(n)算法更新式为
Sarsa(n)算法是伪代码如下图所示。

3. 平均奖励:对连续性任务的一个新设定
对于连续性任务或者交互轨迹非常长的任务,平均奖励的设定可以帮助解决强化学习问题,而不用引入折扣系数。给定一个策略\(\pi\),平均奖励定义为
其中,\(\mu_\pi(s)\)为策略\(\pi\)下稳定的状态分布,即\(\mu_\pi(s)=\lim_{t\rightarrow\infin}\Pr\{S_t=s|A_{0:t-1}\sim\pi\}\)。从另一个侧面来看,稳定的状态分布也满足
式(10.1)成立的一个前提要求是交互过程满足各态历经性。在实际应用中,寻找最优策略的目标就是最大化\(r(\pi)\)。在平均奖励的设定下,\(t\)时刻的回报将重新定义为实际奖励与平均奖励差分的累计和,即
它对应的价值函数为差分价值函数,重写如下。
与之对应的差分的TD误差和Sarsa误差分别为
Sarsa半梯度算法的伪代码如下图所示。

值得注意的是,平均奖励\(\bar{R}\)采用逐步更新的方式而非直接计算得到,其原因主要在于,1.随着交互次数的不断增加,策略\(\pi\)会不断改进,先前的\(\bar{R}\)将不再适用,逐步更新方式可以使得\(\bar{R}\)逐渐逼近于真实值。2.在初期探索阶段,奖励的采样值的随机性较大,使得直接计算平均奖励存在较大波动,导致算法收敛变慢。
平均奖励更新的增量由误差\(\delta\)决定,而不是\((R-\bar{R})\),一开始让我觉得费解,后来发现在期望的角度上它们是一致的。但是采用误差\(\delta\),平均奖励估计值的变化更加平稳。下面做一个不是很严谨的展示。
由此可以看出,当奖励的预测(状态价值函数的预测)越准确时,平均奖励的估计值越平稳。但是如果采用奖励的采样数据进行更新,平均奖励的估计值会不断的在期望值上下波动,因为实时奖励与平均奖励可以不相等。
4. 折扣系数的设定
折扣系数的设定对于蒙特卡洛采样是具有积极意义的。对于交互轨迹过长或连续任务,折扣系数可以有效降低回报采样的方差。但是基于函数近似方法,折扣系数的设定与平均奖励的设定是一致的,都是以提高平均奖励为目标改进策略。
对于函数近似方法,会存在不同的状态得到相近甚至相同的特征向量,而当对真实环境并不是完全清楚的情况下,不同于马尔可夫决策过程中知道所有的状态,会存在隐藏状态的情况(多个特征向量相同的状态归为一个观察状态)。这时基于列表法的强化学习控制方法的策略改进性质(参考第三章针对每一个状态价值求其最大值)将不适用于基于函数近似的策略改进。Singh,Jaakkola和Jordan(1994)的文献中给出了相应的例子,如下图所示,图中只有一个观测状态1,但是实际却是包含两个不同状态,若根据状态价值函数\(q(s_1,a)\)选择贪婪动作,无论是选择动作A还是动作B,最终都只能得到一连串的\(-R\)奖励。这便是函数近似方法可能会导致的问题。
.assets/https://images.cnblogs.com/cnblogs_com/blogs/736079/galleries/2406070/o_240625055340_image-20240116185546929.png)
采用折扣系数的设定,其平均状态价值与平均奖励成正比,\(J(\pi)=r(\pi)/(1-\gamma)\)。假设给定策略\(\pi\)状态分布趋于稳定,可得
其中,\(v_\pi^\gamma\)表示折扣系数下的状态价值。由此可以看出,引入折扣系数并不会改变其目标。
5.差分半梯度n步Sarsa
将差分形式引入第2节的半梯度n步Sarsa算法中,可得其回报:
其中,\(\bar{R}\)是\(r(\pi)\)的估计,当\(t+n\geq T\)时,那么\(G_{t:t+n}=G_t\)。同样,可得差分形式下的\(n\)步TD误差为
由此可得,差分形式下的半梯度\(n\)步Sarsa算法的伪代码如下图所示。

具体的实现效果可以参考实验2。
6.实验
实验1:汽车爬坡任务
考虑驾驶一辆动力不足的汽车沿着陡峭的山路行驶的任务,如下图所示。困难在于,由于动力不足,即使油门踩到底的情况下,汽车也无法爬上陡坡。唯一的解决方案是首先向左侧相反的斜坡移动。然后,开足马力,使得汽车得到足够的惯性,即使速度不断衰减也能将到达目标位置。这是一个连续控制任务的简单例子,但其特别之处在于,事情必须在某种意义上变得更糟(离目标更远),然后才能变得更好。除非有设计者的明确帮助,否则许多控制方法在处理这类任务中都有很大困难。
为了简化问题,小车的动作有三种行为\(A_t\),分别是向前(\(+1\)),向后(\(-1\))和不踩油门(0)。汽车在达到目标位置之前的每一步的奖励都是\(R=-1\)。爬坡任务的状态包含汽车的位置\(x_t\)和车速\(\dot{x}_t\),其更新方式为
其中,位置范围限制在\([-1.2,0.5]\)和速度范围限制在\([-0.07,0.07]\)。加速系数\(force=0.001\),重力系数\(gravity=0.0025\)。每一轮游戏开始,小车的速度为0,随机位置\(x_0\in[-0.6,-0.4]\)。采用瓦片编码方式近似状态-动作价值函数,利用Sarsa(n)算法估计最优策略。超参数选择\(\gamma=1\),瓦片数量\(=8\),学习率\(\alpha=0.3\)。动作选择采用\(\epsilon\)-greedy方式\(\epsilon=0.1\)。当然因为这个任务的环境是确定性(静态)的,可以在动作价值函数的初始化阶段采用过估计方式,例如将所有动作价值设置为0。因为奖励为\(-1\),所以真实的动作价值都是小于0的。过估计方式可以促进智能体去探索环境,这时\(\epsilon=0\)也可以。其原理可以查阅第二章中的动作价值估计小节的讨论。
在代码实现过程中,首先定义了IHT类实现hash表,hash表的大小表示每一块瓦片分割的子区域的数量。然后分别定义了hash_coords()和tiles()函数,第一个函数实现给定状态在当前瓦片中的坐标信息计算得到在当前瓦片中的索引号,第二个函数实现给定瓦片数量,获得状态特征,即状态在所有瓦片中的索引号的组合。同时代码中采用了面向对象的编程理念,定义了ValueFunction类用来封装价值函数,使得算法的实现更加灵活,具体代码参照随书代码第十章mountain_car.py。实验结果如下图所示。
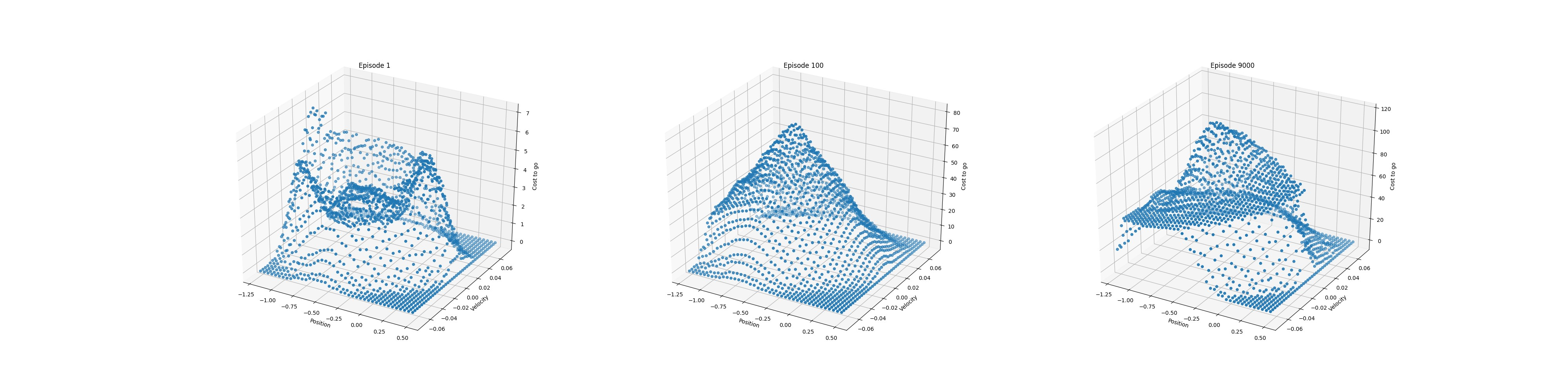
从实验结果可以看出,当小车位置靠近目标位置且小车速度较大时,其最优动作价值比较高(在图中表示为靠近0)。另外可以看到在靠近目标位置且车速向后非常大,其最优动作价值也靠近0,其原因在于并未探索到该状态。这里需要注意的是,因为采用哈希编码形式的瓦片编码,当哈希表的大小无法满足环境状态的数量时,会出现哈希冲突,导致完全不同状态的会得到相同的特征向量,即动作价值一样。这样又会导致,动作价值函数的估计不准确。在经过多次实验发现,在当前瓦片编码下共出现1926个不同特征向量,因此将哈希表大小设置为2048比较合理。另外,所有瓦片共享一组参数,参数的大小与hash表的大小是一致的。
若将哈希表大小设置为1024,得到的实验结果如下图所示。
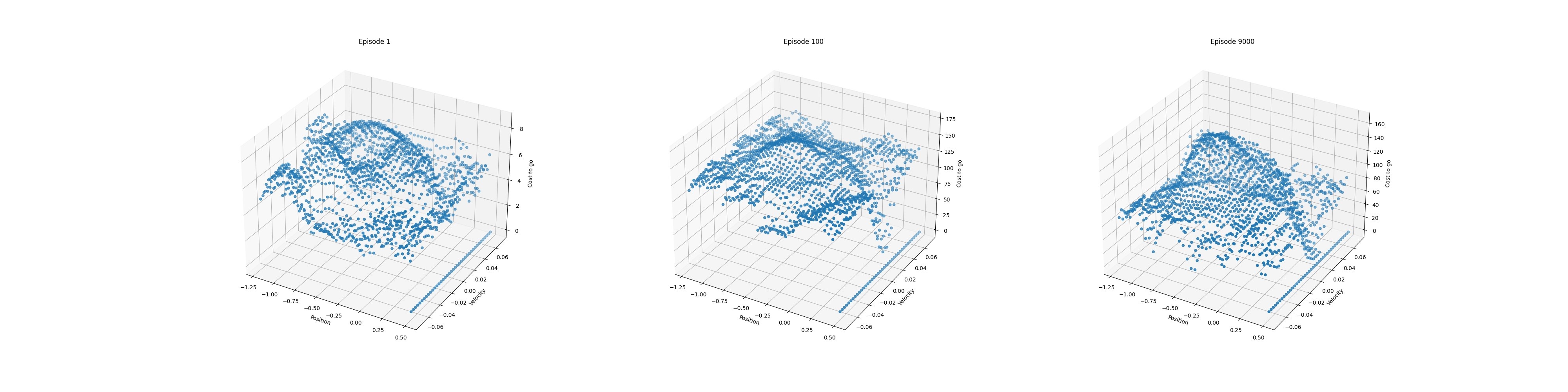
从实验结果可以看出,当哈希表存在哈希冲突时,导致动作价值函数不再准确,智能体探索了几乎所有可能的状态-动作对。
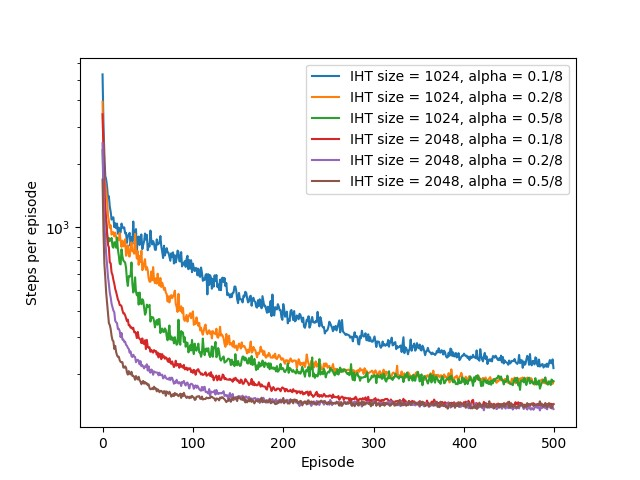
下面考察汽车爬坡任务随着游戏轮数的不断增加,每轮游戏的交互次数变化。同时采用不同的学习率\(\alpha = [0.1,0.2,0.5]\)和不同大小的哈希表\(size\_HT=[1024,2048]\)。为了保证实验结果的一致性,共进行100轮实验取均值,实验结果如下图所示。
下面考察Sarsa(n)的步数对于汽车爬坡任务学习情况的影响。超参数选择步长\(n=1\)对应的学习率为\(\alpha=0.5\),步长\(n=8\)对应的学习率为\(0.05/8\)。哈希表的大小为2048,瓦片数量为8。为了保证实验的一致性,共进行100轮重复实验。实验结果如下图所示。
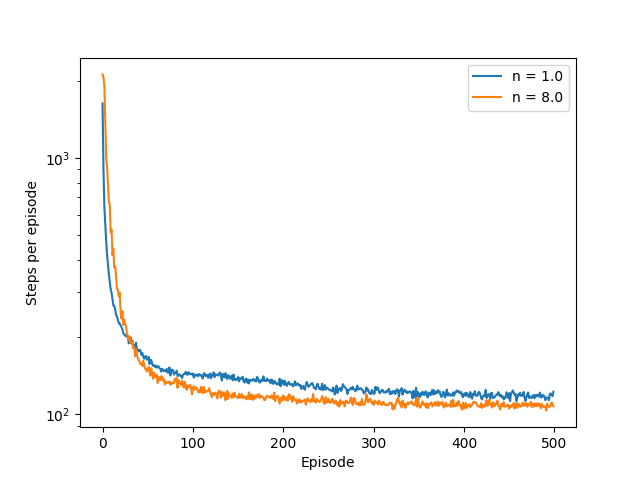
从图中可以看出,在交互初期步长小的学习速度较快,原因在于学习率较大。但是随着交互次数的逐渐增加,多步长的优势就逐渐明显起来。
下面考察Sarsa(n)算法的不同步数不同在不同学习率下的初期表现(进行50轮交互)。通用超参数选择与上面一致。为了保证实验的一致性,共进行50轮重复实验。实验结果如下图所示。
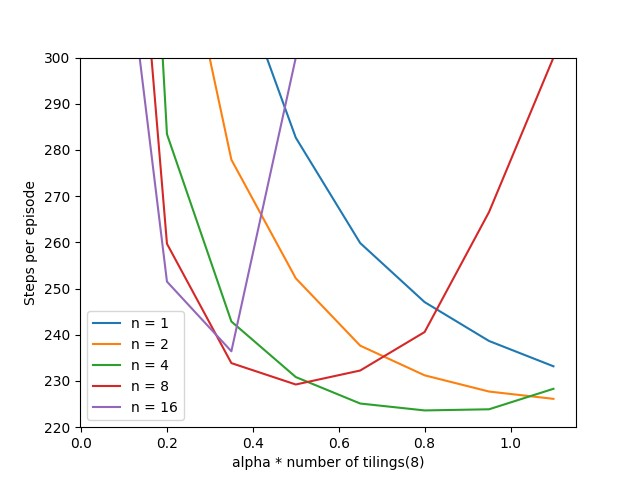
这与前几章的结论是一致的。当步长增加,学习率需要大大减小,否则算法难以收敛。从图上看,似乎步长小的瞬时表现更好一些。这主要是因为对于更大步长,选择的学习率还是不够小的缘故。
实验2:访问控制队列任务
考虑一个决策任务,实现对一组10台服务器的访问控制。假设存在四种不同优先级的客户排在一个队列中。如果被授予访问服务器的权限,客户将根据其优先级向服务器支付1、2、4或8的奖励,优先级越高的客户支付越多。在每一步中,队列顶端的客户要么被分配给一台空闲的服务器,要么被拒绝,即从队列中删除,相应的奖励为零。无论上述哪种情况,在下一时刻会考虑队列中的下一个客户。
队列从不为空,且队列中客户的优先级是均匀分布的。当然,如果没空闲的服务器,则无法为客户提供服务;在这种情况下,客户总是被拒绝。每个繁忙的服务器变为空闲的概率\(p=0.06\)。尽管刚刚对这个任务进行了明确的描述,但实验过程中假设客户到达和离开的统计数据是未知的。任务就是根据客户的优先级和空闲服务器的数量,决定是接受还是拒绝他,从而实现长期回报的最大化,任务不引入折扣系数。
这个任务本身是非常适合列表法的,但依然可以采用瓦片编码方式。在每轮任务开始时,初始状态为所有服务器均空闲,第一个客户的优先级服从均匀分布。利用差分半梯度Sarsa(n)算法寻找最优策略。超参数选择\(\gamma=1\),\(\alpha=0.01\),\(\beta=0.01\),\(\epsilon=0.1\)。动作价值和平均奖励都初始化为0。
具体代码参照随书代码第十章access_control.py。首先采用差分半梯度Sarsa(0)算法需按照最优策略,并给出不同优先级不同状态下的价值函数。实验结果如下图所示。
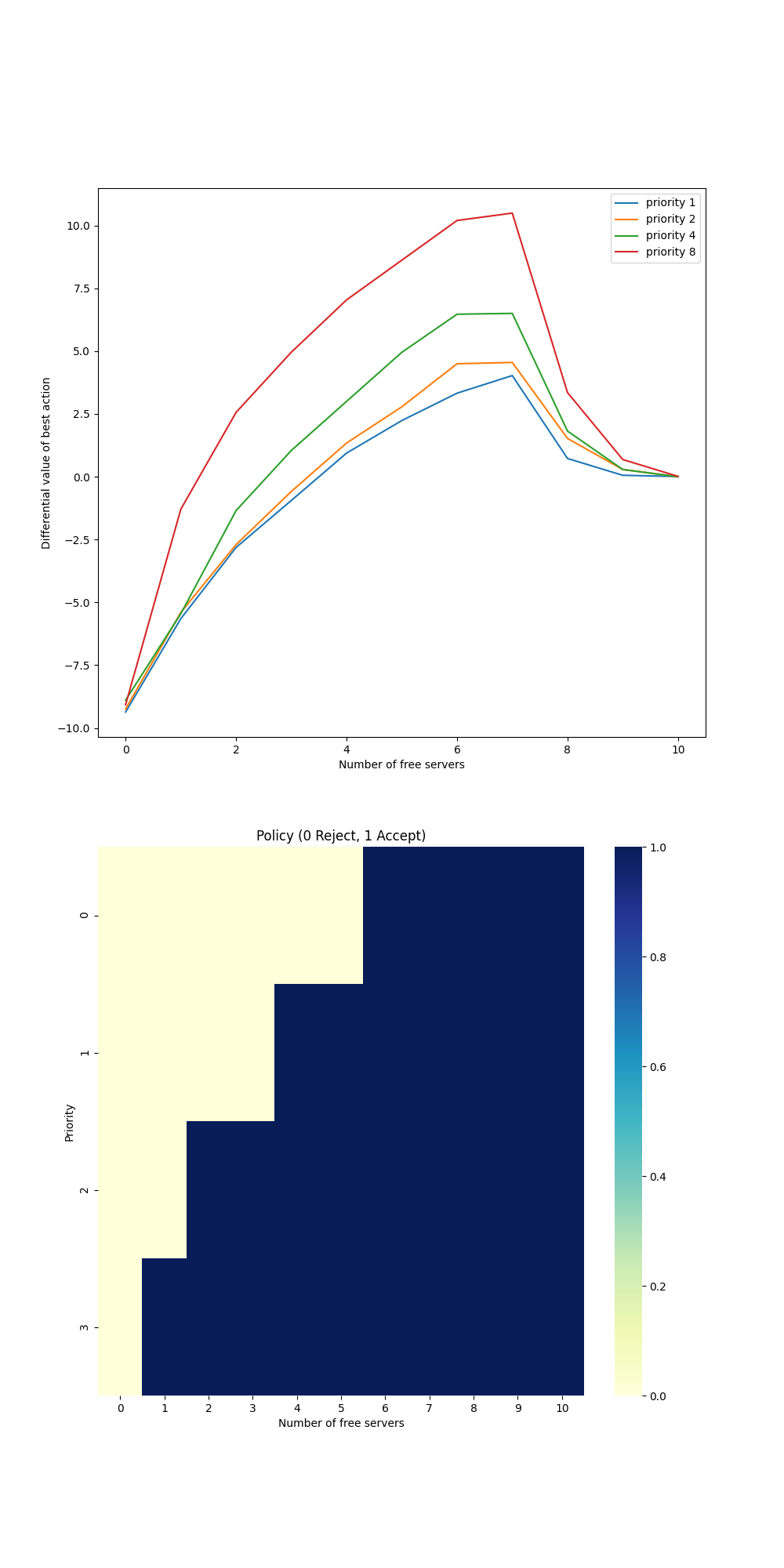
实验结果是符合预期的,优先级高的用户的价值函数优于优先级低的用户的价值函数。当空闲服务器较少的适合优先满足优先级高的用户,因为不同优先级的用户是满足均匀分布的且优先级高的用户的奖励高。
下面考察不同步长下Sarsa(n)算法在学习过程中平均奖励的变化过程。因为本任务没有终止状态,因此限定了交互的最大次数为10万次,分别采用\(n=1,4,8,16\)的步长。根据以往的经验,步长越大对应的学习率应该越小,因此学习率分别为\(\alpha=0.01,0.005,0.001,0.0005\),平均奖励的学习率与其对应的学习率保持一致。为了保证实验的一致性,共进行100轮重复实验,实验结果如下图所示。
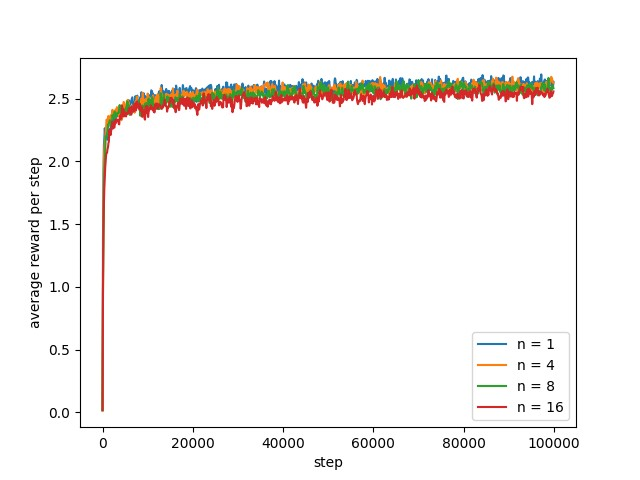
结果让人有些意外,步长越小学习到的策略反而越好,平均奖励越高。让人怀疑是因为学习率的差异导致,步长越长学习的速度越慢,因此,第二次尝试所有步长采用相同的学习率。实验结果如下图所示。
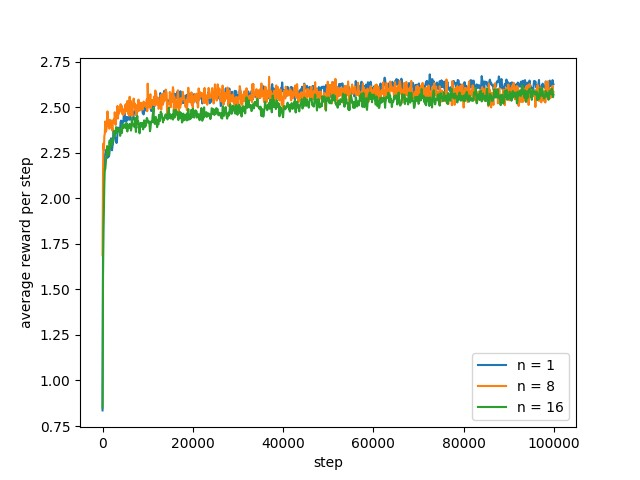
从学习结果来看,似乎还是步长小的学习效果更好。但是这次步长\(n=16\)最后的学习效果似乎可以追上\(n=8\)的效果。让人怀疑是否是交互次数偏少,另外平均奖励的学习率过低。因此,将最大交互次数提高为100万次,采用步长\(n\)=16,但\(\beta=[0.0001,0.001,0.01]\)。看一下相同步长下,不同平均奖励学习率的学习效果。
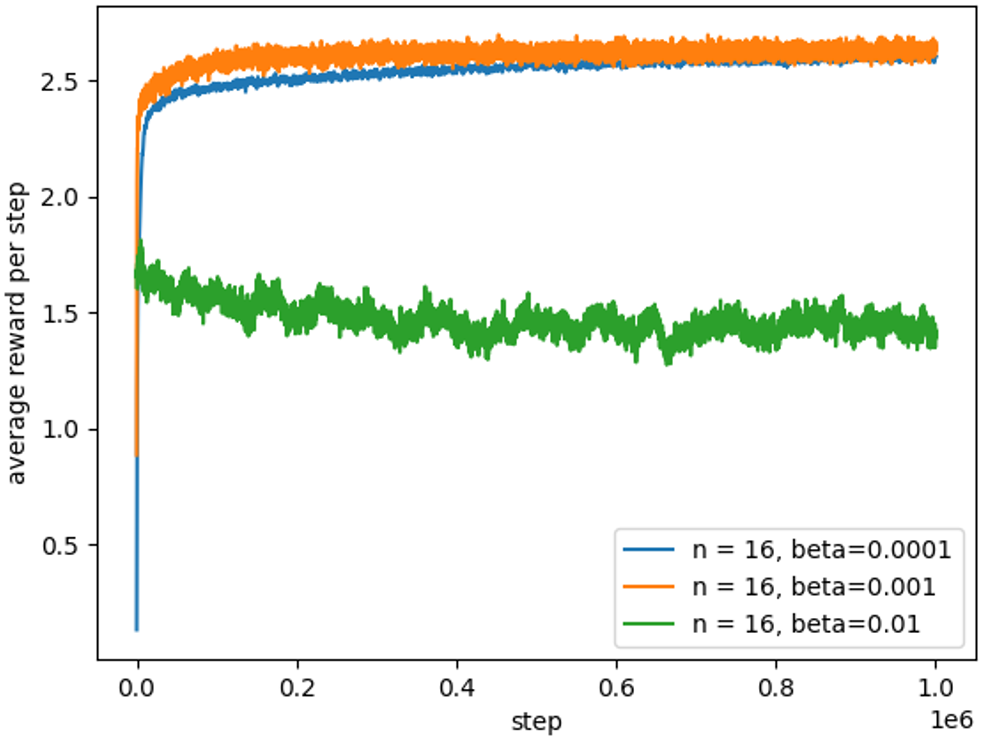
从实验结果看,平均奖励的学习率\(\beta\)对Sarsa(n)的性能影响还是比较明显的,学习率\(\beta\)过大会导致算法性能大大降低,学习率\(\beta\)越小,算法的学习曲线越平稳,但不是学习率\(\beta\)越小学习效果越好。\(\beta\)也是需要手工调节的超参数。
下面考察采用无偏的学习率技巧(unbiased constant-step-size trick)提升算法性能。无偏的学习率技巧的优点在于可以消除初始值的影响,并且随着\(n\)的增加\(\beta_n\)逐渐趋向于\(\alpha\):
采用无偏的学习率技巧的实验结果如下。
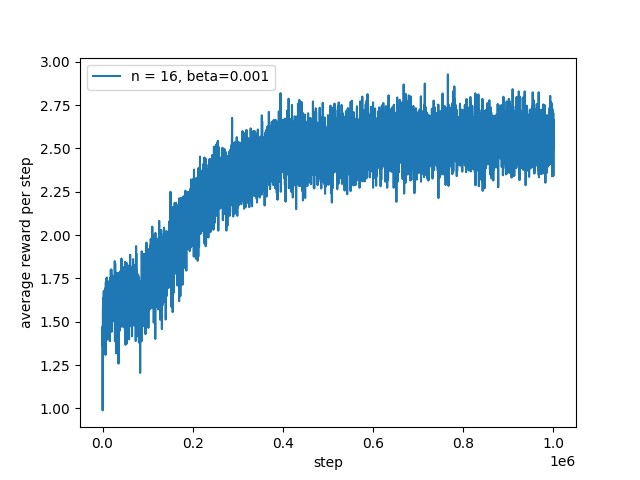
采用一般的学习率,将平均奖励的初始值设置为5。从第二章可以得知,乐观的初始值设定有助于智能体更广的探索环境。实验结果如下。
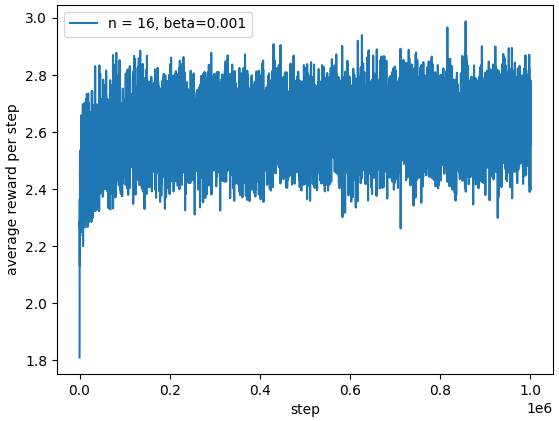
可以看出提高初始值一样可以起到不错的学习效果。因此,提高智能体的探索能力,可以有效提升学习效果。
7. 小结
本章主要学习了基于动作价值函数近似的在线策略控制算法。与列表法的Sarsa(n)算法相比,函数近似方法具有更强大的数据压缩能力,利用线性或者非线性函数近似方法通过交互样本学习近似函数的权重,更加适用于复杂空间下的强化学习任务。但函数近似方法也有其固有的困难,首先是不同状态的区分能力,函数近似可能会出现对不同状态得到相同或相近的特征向量的情况,即状态聚集的情况;然后函数近似方法学习得到的是确定性的价值函数,对于存在隐藏状态的情况难以进行有效的应对。本章还讨论了平均奖励设定和折扣设定的关系,在实验部分采用线性的函数近似方法(瓦片编码)。借助哈希化的方法可以大大扩展瓦片编码的实用性,但瓦片编码的精度并没有一个完善的评价方式,另外基于交互轨迹的学习方式,有些状态相对聚集需要更细粒度的区分,而有些状态相对分散只需要粗区分就可以,但瓦片编码无法针对性的进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号