
强化学习读书笔记 -- 第八章基于列表法的计划和学习
本章主要从一个统一的观点对前面章节的方法进行归纳总结。可以将目前所学的强化学习方法分为两类,一类是基于模型的(model-based)方法,例如有动态规划和启发式搜索(heuristic search);另一类不需要模型的(model-free)方法,例如蒙特卡罗(Monte Carlo,MC)方法和时序差分(Temporal Difference,TD)法。基于模型的算法主要依靠计划(planning),而无模型算法主要依靠学习(learning)。两者之间虽有不同,但也存在很大的相似性。
1.模型和计划
一个环境的模型意味着智能体可以预测环境会如何响应它的动作。给定一个状态和动作,模型可以产生下一时刻的状态和奖励的所有可能性以及它们的概率,这样的模型称为分布模型(distribution model)。而模型只能通过概率分布进行采样生成其中一个状态和奖励,这样的模型称为采样模型(sample model)。例如对掷色子求和进行建模,一个分布模型将提供所有可能的和及其概率,而一个采样模型只能根据概率分布生成一个可能的和。构建一个采样模型往往比构建一个分布模型要容易的多。
模型可以用来模拟环境,产生仿真经验(simulated experience)。我们使用计划来指代以模型为输入,以生成或改进策略为输出的计算过程。状态空间计划是指一类基于状态空间搜索去获得最优策略的方法。将基于模型和无模型的方法结合起来有两个基本的观点:第一是所有的状态空间计划方法都需要先计算状态价值函数,从而帮助改进策略;第二是通过对仿真经验,进行备份操作(更新目标状态价值)或更新计算状态价值函数。

动态规划方法就非常符合这样的模式,它需要遍历空间中所有的状态,生成每个状态的所有可能的转移状态分布。从而计算目标状态价值(target value)估计,并更新状态价值函数的估计。计划方法和学习方法的核心都是通过估计目标状态价值来更新状态价值函数,它们的区别就在于是否利用真实经验。在这样一个架构下,计划方法和学习方法是可以相互转换的。下图展示了一个简单的通过模型来学习的Q-learning算法,它被称为随机采样单步列表Q计划算法。

除了对计划和学习方法的统一看法外,本章的第二个主题是循序渐进地进行计划的好处,对比策略迭代和价值迭代。这使得计划能够在任何时候中断或重定向,而几乎不浪费计算量,这似乎是实现边计划边交互边学习的关键要素。即使在纯粹的计划问题上,如果因为问题太大而无法准确解决,那么逐步进行计划可能是最有效的方法。
2. Dyna:计划、交互和学习的融合
本节介绍Dyna-Q算法,它将计划、交互和学习相融合,从而实现一个在线计划的智能体。对于该智能体而言,交互经验至少有两个作用,第一是用于改进模型使之能够更加准确地匹配真实环境,另一个是用于直接学习价值函数和最优策略。前者称为模型学习(model-learning),后者称为直接强化学习(direct reinforcement learning, direct RL)。交互经验、模型、价值函数和策略的关系图如下图所示。根据仿真经验改进价值函数就被称为间接强化学习,它主要体现在计划过程。
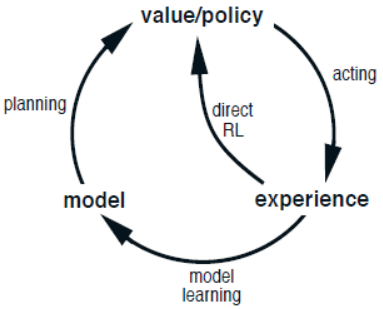
直接或间接强化学习都有其优缺点。间接方法优势在于充分利用有限的交互经验生成或改进模型,例如仿真经验学习策略,缺陷在于学习得到的模型是有偏的。直接方法优势在于直接从和环境的交互经验中学习策略,缺点在于需要大量的交互经验。Dyna-Q算法的架构如下图所示。
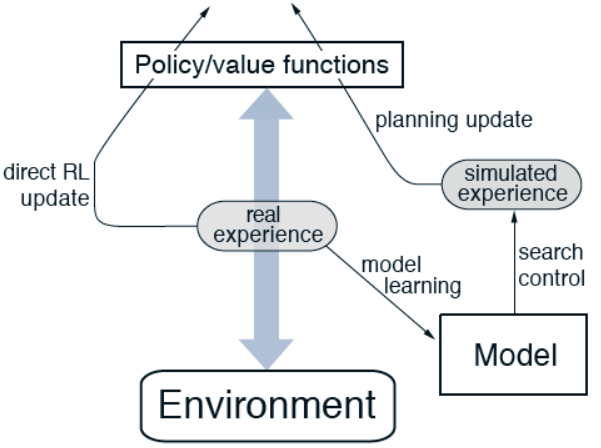
图中间代表了智能体于环境的交互,得到一系列交互经验;左边的箭头代表利用交互经验进行直接RL学习;右边的箭头是基于模型的学习,模型通过交互经验学习模型并产生仿真经验。我们使用术语搜索控制(search control)来指代模型生成的模拟体验选择起始状态和动作的过程。最后,通过将强化学习方法应用于模拟体验来实现计划,就好像它们真的发生了一样。通常,与Dyna-Q一样,相同的强化学习方法既用于从真实交互经验中学习,也用于从仿真经验中计划。因此,强化学习方法是学习和计划的“最终共同路径”。学习和计划是深度融合的,因为它们几乎共享所有相同的机制,只在经验来源上有所不同。
下面给出了Dyna-Q算法的伪代码。其中\(Model(s,a)\)表示用于预测下一时刻的状态和奖励模型。步骤(d)为直接RL部分,而步骤(e-f)为模型学习和计划部分。

需要注意的是这里的环境是确定性环境,意味着给定状态和动作就可以确定下一时刻的状态和奖励。因此,伪代码中模型学习就是记录所有交互的状态转移信息。Dyna-Q算法的仿真实验请参考实验1迷宫。
3. 当模型错误
在实际过程中,模型可能时错误的,因为环境具有随机性并且只有有限的学习样本。当模型错误时,规划过程很可能收敛于非最优策略。这个问题也可以看作是探索与挖掘矛盾。在计划过程中,探索意味着尝试不同的动作从而改善模型,挖掘意味着根据给定模型学习最优策略。
Dyna-Q+算法利用启发式搜索解决这一问题。对于迷宫问题,Dyna-Q+算法对每一个状态-动作对进行持续追踪,记录该状态-动作对最近的访问的时间。这个时间的意义在于,若一个状态-动作对的最近访问时刻距离当前时刻的间隔越长,意味着该状态-动作对的状态转移信息越有可能不准确,即模型存在错误的概率越大。因此,在计划过程中,为了鼓励探索,在模拟经验的奖励中引入额外奖励(bonus reward),令\(r\)表示实际的状态转移奖励,\(\tau\)表示状态转移未被访问过的时间间隔,\(\kappa\)表示权重,可得\(r+\kappa\sqrt{\tau}\)。通过这样的方式可以鼓励智能体尽可能地去探索所有的状态转移。Dyna-Q+算法的仿真实验请参考实验2和实验3。
4. 优先级扫描(prioritized sweeping)
前面几节中,Dyna-Q算法模拟过程的起始点是通过从曾经出现过的状态-动作对中均匀采样产生的,但是均匀采样通常不是最佳选择,如果将重点放在某些状态-动作对上,计划过程会更有效率。如果我们从目标状态(goal state)反向搜索的话会更有帮助,这个思路就是反向关注(backward focusing)。当环境变化时,一些状态的价值可能会变化很大,与之相关的一些状态价值也会相应发生改变,而另一些可能不变。在这些剧烈变化状态价值之前的状态-动作对可能也会有很大变化。因此,根据状态价值更新的紧迫性来确定状态价值更新的优先级,并按优先级顺序执行更新,这就是优先级扫描(prioritized sweeping)的思想。维护一个状态-动作对的队列,根据其价值变化的大小进行优先度排序。当队列顶端的价值更新时,该状态-动作对的所有前一对都被重新计算,如果变化值大于一个阈值,就插入队列。因此,还需要维护一个检索列表(例如字典),保存队列中的状态-动作对所对应的前状态-动作对。整个算法的伪代码如下图所示,仿真实验请参考实验4。

对于随机环境来说,模型需要统计每个状态-价值对出现的次数,以及状态转移的信息。优先级扫描算法就不选择用最大值而是用期望值来更新价值函数。这也是优先级扫描算法的一个缺点,计算了期望值需要增加大量计算。
5. 期望vs.采样更新
在本节中会讨论期望和采样更新这两种方式的相对优势。以单步更新为例,其更新方式主要有三个维度,1. 是更新状态价值还是动作价值函数;2. 是学习最优策略的价值函数还是任意给定策略的价值函数;3. 是采用期望更新还是采样更新。其分类结果如下图所示。
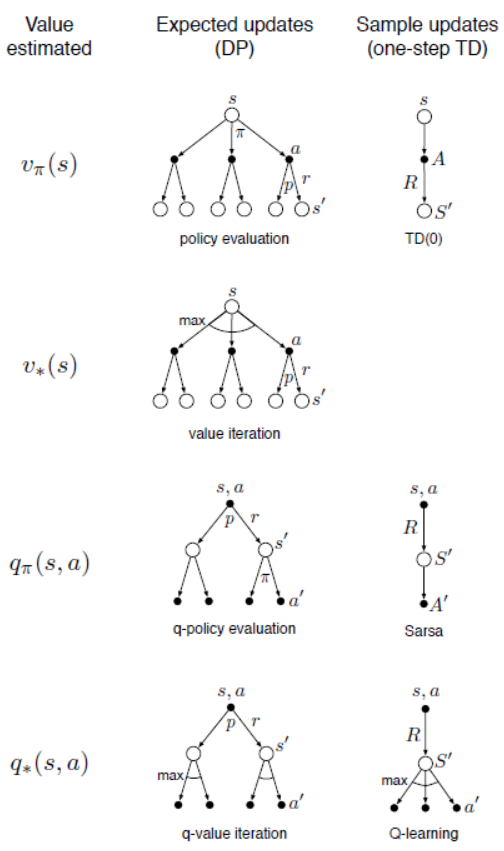
通常而言,期望更新方式会产生更好的估计,因为它不受采样误差的影响,但它需要更多的计算,而计算往往是计划过程中的有限资源。相比之下,采样更新方式却更加简单,它不需要考虑状态转移的所有可能。尤其在大型复杂环境下,相比于期望更新方式,采样更新方式需要较少的交互数据就能让价值估计误差大幅下降。期望更新与采样更新的比较可以参考实验5。
6. 轨迹采样(trajectory sampling)
一般而言,动态规划算法试图去扫描整个状态空间,对于大型任务而言,扫描整个状态空间都是无法完成的。事实上,扫描整个状态空间也是没有必要的。对状态空间进行有针对性的探索,这才是强化学习的优势所在。可以利用已有的策略分布来进行采样,即与环境交互生成交互轨迹,也称为轨迹采样(trajectory-sampling)。
均匀采样方式即等概率的选择状态-动作对作为起点与环境进行交互,可以只交互一次,类似于Dyna-Q算法中的计划过程。相比于均匀采样方式,轨迹采样更具针对性,它会忽略不感兴趣的部分,当然弊端就是只会关注某一区域的状态,这又回到了探索和挖掘的权衡问题。当问题规模较小时,随着交互次数的不断增加,轨迹采样方式还是不如均匀采样的方式效果好。轨迹采样与均匀采样的性能比较可以参考实验6。
7. 实时动态规划(Real-time Dynamic Programming, RTDP)
实时动态规划算法也是一种轨迹采样方法。RTDP是将期望更新与轨迹采样相结合的阐述。其特点在于,对于某些特定的问题(例如迷宫问题),RTDP能保证不频繁访问空间中某个状态或是遍历空间中所有状态,甚至根本不访问某些状态的情况下,找到最优的策略。事实上,在某些问题上,也只有一小部分的状态需要被访问。
8. 决策时计划(概念)
计划有两种方式,一种是如上面所提到的,根据交互经验更新价值函数并改进策略,这样的计划不是针对当前的状态,称为背景计划(background planning)。另一种计划是在面临一个新的状态后再计划接下来的动作,评估和预测下面的交互轨迹,计划过程中创建的价值函数和策略可能会在选择当前动作后被丢弃,这种计划称为决策时计划(decision-time planning)。在许多应用中,丢弃计划过程中创建的价值函数和策略并不是一个很大的损失。因为状态空间很大,我们不太可能在很长一段时间内回到同一状态。一般来说,人们可能希望这两种计划兼而有之:将重点放在当前状态的计划上,并存储计划的结果进行背景计划,以便在以后返回到同一状态时能够更加准确。
决策时计划方法适用于在不需要快速响应的应用程序。例如,在下棋程序中,每一步都可以进行几秒或几分钟的计算,而强大的程序可以在这段时间内提前计划几十步。但是,如果要求低延的响应,那么通常最好在后端提前进行计划得到最优策略,以便对遇到的新状态进行快速响应。
9. 启发式搜索
启发式搜索是决策时计划方法的一种。在启发式搜索中,以当前状态为根节点,不同状态-动作对生成不同的分支,最后构成一棵树。在叶节点会使用近似价值函数的方式来计算该节点的价值,然后采样期望更新的方式反馈到树的根节点。当状态价值计算完成后,价值最高的动作被选择为当前动作,最后丢弃所有计算结果。
启发式搜索可以往前看很多步,类似于下棋的高手在落子前会预判后面的情况。向前深入搜索的目的是为了获得更好的动作选择。假设我们拥有一个完美的模型,但目前的动作价值函数却不完善,事实上,深入搜索通常会产生更好的策略。当然,如果能搜索一直到一轮交互结束,那么价值函数是否完善对于最优动作的选择将不产生影响。当然,要做到这样需要大量的计算,在许多对响应速度有要求的应用中难以实现。
当然启发式搜索的搜索方式并不是漫无目的的,可以根据状态价值函数的分布去关注有较大可能的后续状态。例如下图所示的是利用启发式搜索的方法来构建搜索树,然后自下而上执行逐步更新。如果以这种方式对状态更新的优先级进行排序并使用表格表示,其架构与深度优先启发式搜索是完全相同的。
事实上,任何状态空间搜索方法都可以被视为是大量单步更新的组合。因此,向前深入搜索对策略学习的性能改进并不是因为使用了多步更新。而是,由于对当前状态的下游状态-动作对的更新的关注和聚焦。通过对相关的候选动作投入大量计算,决策时计划方法可以产生比随意更新更好的决策。
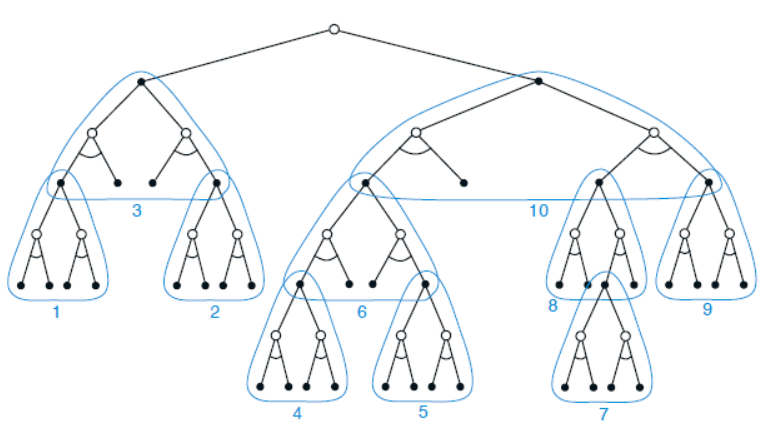
10. Rollout算法
Rollout算法(全程探索式算法,不清楚怎么翻译合适)也是一种决策时计划算法,它基于蒙特卡洛(MC)的思想,从当前状态开始,与模型进行模拟交互直至交互结束,根据MC采样计算回报,即关于当前状态价值的样本。Rollout算法通过平均许多模拟轨迹(simulated trajectory)的回报来估计给定策略下的状态-动作价值。当状态-动作价值的估计足够准确或是到达时间限制时,选择具有最高价值的动作作为当前状态的执行动作。执行完动作后,先前的计算过程同样会被丢弃。相比启发式搜索,Rollout算法实现更为简单,它不需要去估计状态-动作价值函数,也不需要遍历整个空间(根据Rollout策略搜索)。本质上,Rollout算法是基于给定策略的搜索算法,它通过MC控制来不断提升 Rollout 策略,而非寻找一个全局最优的策略。
通常认为Rollout算法不属于学习类算法,其本质在于它并不会维护一个价值函数。然而,它却利用了强化学习的一些特征,例如它采用MC控制中的轨迹采样,通过平均轨迹样本的回报来估计状态-动作价值,采集的样本是独立同分布的,一方面避免了动态规划那样的穷举,另一方面避免模型有偏带来的影响。
11. 蒙特卡洛树搜索
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)算法也是一种Rollout算法,但与前面介绍的Rollout算法有所不同。MCTS算法并不是从当前状态开始模拟,而是经过选择和扩展后,对叶节点进行轨迹采样,从而寻找获得更高回报的轨迹。MCTS算法并不需要保存状态价值函数或者策略,不过在需要应用中,它会保存可能对其下一次执行有用的动作价值。MCTS算法的搜索过程入下图所示。
MCTS算法的一次迭代包含四个步骤,我们以对弈为例描述这四个步骤的目的和实现。
(1)选择:从根节点开始,树策略(tree policy)基于动作价值选择一个比较有希望的动作,给树添加叶节点。在对弈过程中,更新动作价值函数
其中,\(Q(a)\)表示动作价值,由训练过的状态价值函数提供;\(\eta\)为权重,需要调参;\(\pi(a|S_t)\)由训练过的策略函数提供;\(N(a)\)表示当前状态下,动作\(a\)被模拟的次数。这样的动作价值函数均衡了探索和挖掘的问题。
(2)扩展:树从选择的叶节点处扩展,加入一个或多个子节点。对弈过程中,这些子节点对应于对手可能的落子。利用策略函数来模拟对手的动作,选择一个或多个动作,\(a' \sim \pi(\cdot|S'_t)\),从而获得下一时刻的状态\(S_{t+1}\)。
(3)模拟:从选择的节点或新生成的节点开始,利用Rollout策略模拟完整的交互轨迹,模拟通常多轮交互。在对弈过程中,基于状态\(S_{t+1}\)进行模拟直至游戏结束,模拟可以进行很多次。
(4)备份:将模拟轨迹的采样回报反馈回去并更新节点的动作价值函数。并不会保存树之外的动作-状态价值。下图显示了从模拟轨迹的终止状态直接备份到Rollout策略开始的树中的状态-动作节点来说明这一点。在对弈过程中,根据模拟轨迹计算回报(我方获胜则\(r=+1\),输则\(r=-1\))。然后,更新价值函数
从而更新动作价值
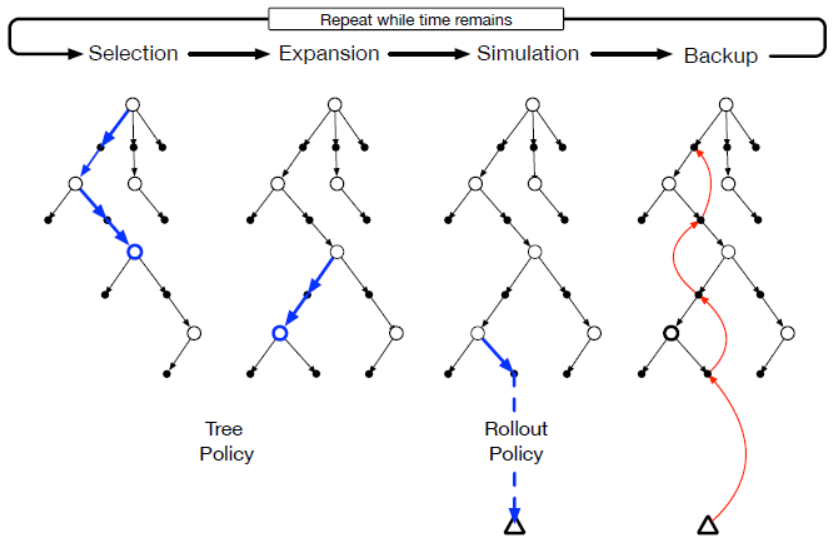
MCTS算法是基于模拟轨迹的结果来增量式地添加看起来有希望的状态节点来扩展树。任何模拟的轨迹都将穿过树,并在在某个叶节点停止。在树之外,其他叶节点处也会进行Rollout算法,但通常树内的状态可能会有更好的选择。对于这些状态,至少对其中一些动作进行价值估计,往往可以使用树策略(训练过的策略)来进行选择,该策略平衡探索和挖掘的问题。
经过MCTS算法搜索后,最后可以采用动作价值最高的动作最为当前状态所实施的动作,或是选择被访问次数最多的动作作为实际动作,这样做的好处是可以避免选择步骤中存在异常值。
12. 小结
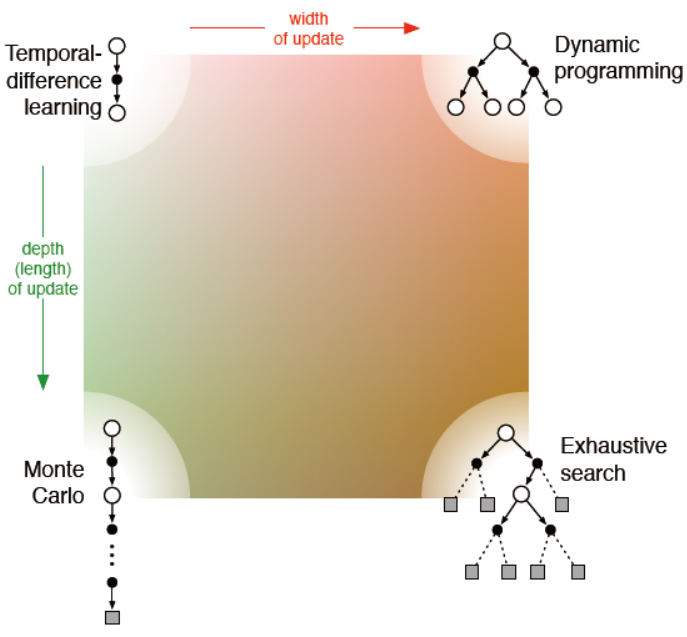
本节主要用一个统一的观点去描述到目前为止介绍的所有算法,可以用下图进行描述。在这些算法中有三个共性的思想,第一它们都寻求估计价值函数的方法,第二它们都通过交互轨迹或模拟估计更新价值,第三它们都采用广义策略迭代的架构,通过近似价值函数和最优策略,不断相互改进从而逼近或者收敛于最优解。从更新方式的宽度和深度可以对算法进行很好的归纳,例如TD(0)算法采用单步更新,且采用样本更新,其更新宽度和深度都是最小的。当然还有一些别的维度,列举如下。
- 估计状态价值还是状态-动作价值
- 回报的定义方式,是否有折扣,是否是存在终止状态。
- 动作价值、状态价值和后状态价值
- 动作选择方式
- 同步更新或异步更新
- 真实交互或模拟交互
- 是否存储更新数据
13.实验
实验1:迷宫
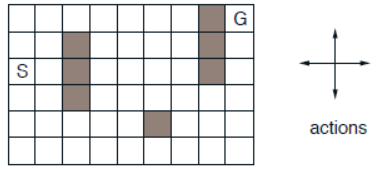
考虑一个静态的迷宫,如下图所示。该迷宫共有47个状态,灰色部分为阻隔墙体,标记S为起始点,标记G为目标点。智能体可以选择四个动作,分别为上下左右。每一次移动一格,当撞倒边界或者墙体时,则留在原地。令达到目标状态时,获得奖励\(r=+1\),其他状态转移奖励为0。
现采用第2节的Dyna-Q算法,采用\(\epsilon\)-greedy策略探索迷宫。测试计划迭代次数\(n\)对迷宫探索的影响。超参数折扣系数\(\gamma=0.95\);学习率\(\alpha=0.1\);探索率\(\epsilon=0.1\)。在实现的过程中,采用面向对象的编程方式,分别构建了Maze类用于封装与迷宫相关的数据和方法;TrivalModel类用于封装近似环境的数据和方法;DynaParams类用于封装Dyna-Q算法的参数。还定义了两个方法,choose_action()基于\(\epsilon\)-greedy策略选择动作;dyna_q()实现Dyna-Q算法。具体代码参照随书代码maze.py。总共进行50轮交互,为了保证实验结果的一般性,共进行了30次重复实验取均值,实验结果如下图所示。
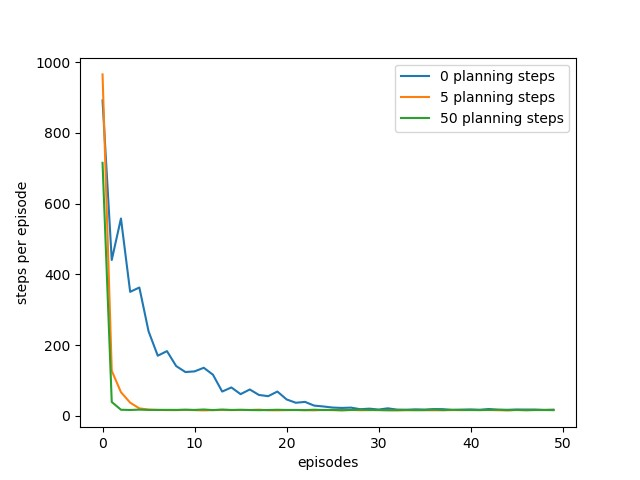
从实验结果可以看出,基于模型的间接强化学习方法可以在更少的交互次数的情况下找到最优策略。
实验2:阻隔变化的迷宫
考虑一个动态的迷宫,如下图所示。开始时,迷宫右端存在一条路径从起始点到目标点。时间过去1000步之后,右侧的道路被阻塞,左端的道路开通,即从左侧迷宫变成右侧的迷宫。分别采用Dyna-Q算法和Dyna-Q+算法探索该迷宫,比较这两个算法的性能。
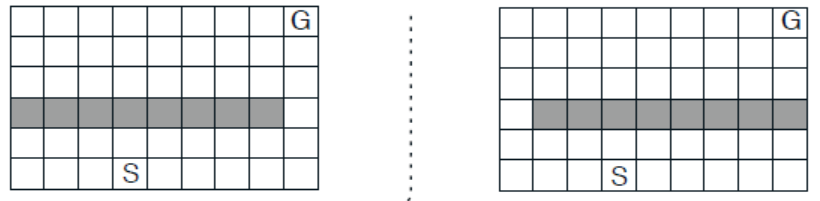
相比于Dyna-Q算法,Dyna-Q+算法在计划过程中引入了启发式机制,1引入了额外奖励方式;2将状态出现过但动作未被选择过的状态-动作对同样纳入考虑,做了一个假设,该状态-动作的对的转移状态仍然是相同的状态,奖励为0。Dyna-Q算法与Dyna-Q+算法的唯一区别在于计划过程的实现不同。因此,在具体实现的过程中,新定义了TimeModel类用于实现Dyna-Q+的计划过程。具体代码参照随书代码maze.py。总共进行3000次交互,横轴为时间轴,纵轴为累积奖励,为了保证实验结果的一般性,共进行了100次重复实验取均值,实验结果如下图所示。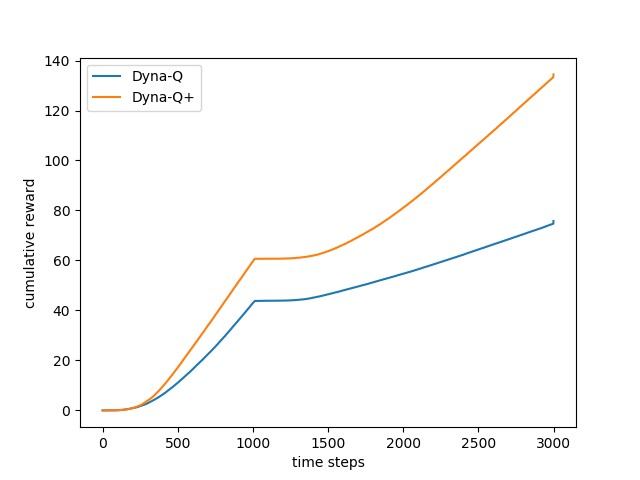
从实验结果看,Dyna-Q+算法能够更快速的找到最优策略(根据曲线的梯度)。同时,当迷宫发生变化后,两个算法都出现了停滞的情况(因为原先的路不通了),Dyna-Q+算法能够更快的反应并再次找到最优路径。启发机制与强化学习的结合能让智能体更聪明。
实验3:最短路径变化的迷宫
考虑一个动态的迷宫,如下图所示。开始时,迷宫左端存在一条路径从起始点到目标点。时间过去3000步之后,右侧出现一条更短的路径,即从左侧迷宫变成右侧的迷宫。分别采用Dyna-Q算法和Dyna-Q+算法探索该迷宫,比较这两个算法的性能。
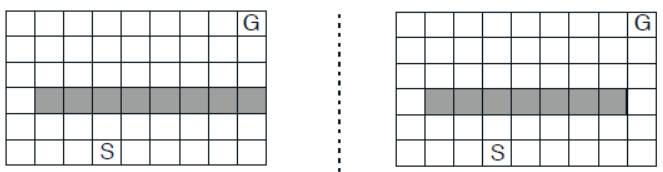
超参数的选择与实验2保持一致,即两个算法的探索和学习能力不变。总共进行6000次交互,横轴为时间轴,纵轴为累积奖励,为了保证实验结果的一般性,共进行了50次重复实验取均值。具体代码参照随书代码maze.py,实验结果如下图所示。
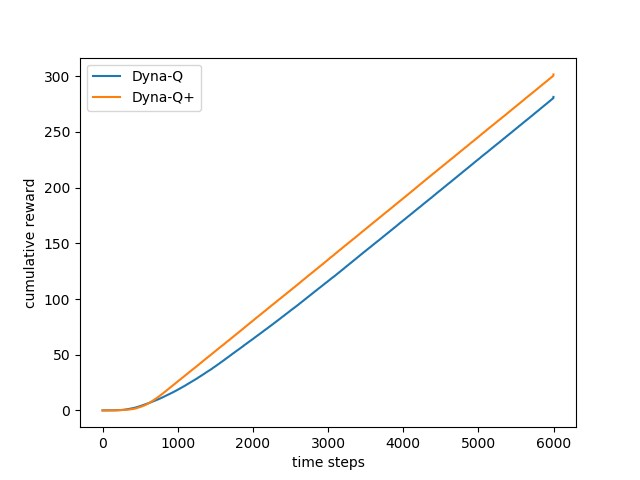
调整超参数由\(\kappa=10^{-4}\)调整为\(\kappa=10^{-3}\),实验结果如下图所示。
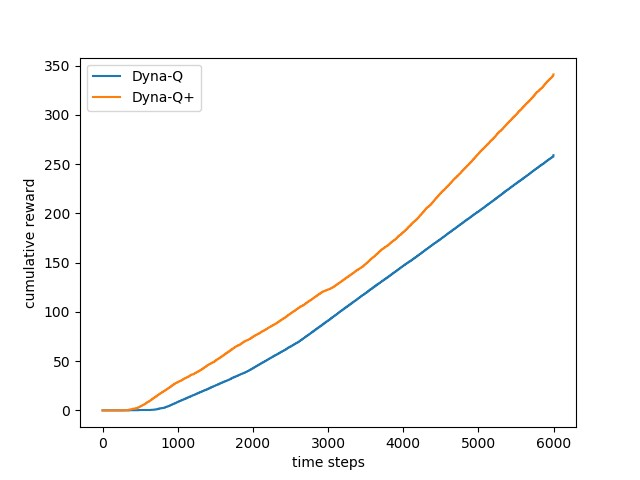
从实验结果可以看出,Dyna-Q+算法的探索能力还是比较强的。但是对超参数\(\kappa\)非常敏感,\(\kappa\)值过高会导致智能体的学习能力不足;\(\kappa\)值过低,智能体很难发现最短路径。为了降低对\(\kappa\)的敏感性,博主认为可以追加任务,例如可以让智能体定期执行探索任务。
实验4:基于优先级扫描的迷宫
本实验根据实验1的迷宫结构,等比例扩大迷宫的规模。比较Dyna-Q算法和基于优先级扫描的Dyna-Q算法的性能。在实现过程中,定义了PriorityModel类,用于封装基于优先级扫描的计划过程。基于优先级扫描的方法实现,需要维护两个队列,一个是状态-动作对的优先级队列,另一个是状态-动作对映射到与其相关的前一个或多个状态-动作对和奖励。在更新模型的时候需要同步更新这两个队列,程序实现上还是很考验编程能力的,值得好好研究。具体代码参照随书代码maze.py,为了保证实验的一般性,进行了50次重复实验,实验结果如下图所示。
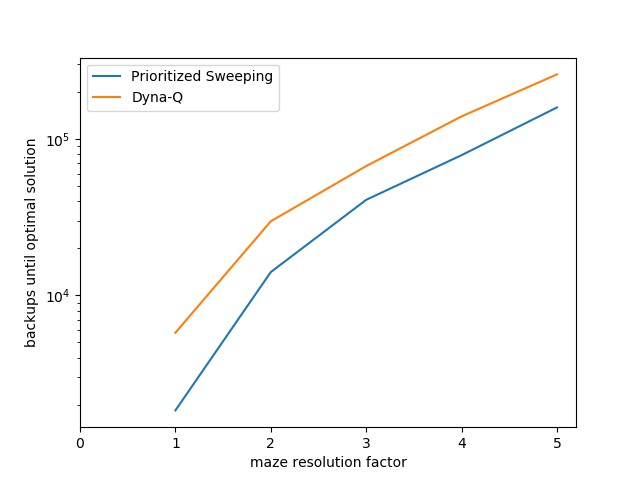
从实验结果可以看出随着模型复杂度的增加,需要计划的次数也增加。在同等条件下,基于优先级扫描的Dyna-Q算法比一般的Dyna-Q算法要好很多。
实验5:期望更新与采样更新估计期望
假设一个状态\(s\)存在\(b\)个分支,即\(Q(s,a_i),\ i=1,2,\cdots,b\)。若采样期望更新需要遍历所有分支,然后计算期望\(\bar{V}(s)=\frac{1}{b}\sum_i Q(s,a_i)\)。若采用采样更新的方式,则逐步逼近真实期望\(\bar{V}(s)=\bar{V}(s)+\alpha(Q(s,a)-\bar{V}(s))\)。实验过程中采样的学习率采用\(\alpha=1/t\),\(t\)为交互次数即采样的次数。具体代码参照随书代码expectation_vs_sample.py,为了保证实验的一般性,进行了100次重复实验,实验结果如下图所示。
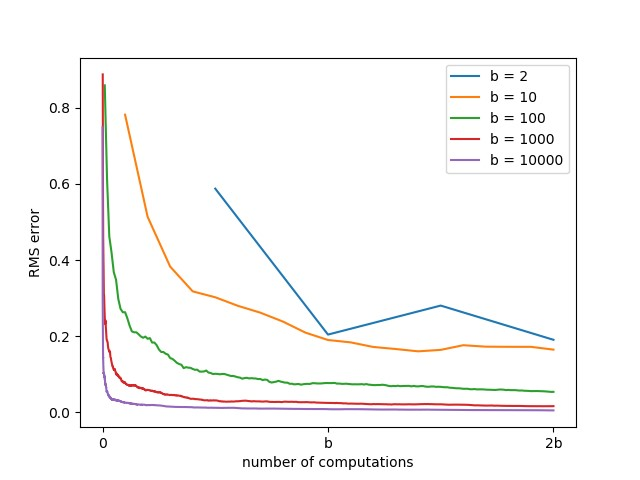
可以看出随着分支数量的增加,通过远小于\(b\)次的交互就可以逼近真实期望。这也从侧面说明了在大型问题中,采样更新方法优于期望更新方法。值得注意的是,该实验假设每条分支的概率是相同的。若分支的分布是有偏的,即每条分支的概率不同,当缺乏环境信息的情况下,那么可以判断出来,采样更新方式将更具优势,因为期望更新只能假设分布是均匀的,导致其估计期望是有偏的。
实验6:轨迹采样与均匀采样估计状态价值
假设存在\(|S|\)个状态,每个状态有两个可选动作,每个动作有0.1的概率会转移到终止状态,奖励为0;若没有转移到终止状态,则会等概率的转移到\(b\)个分支状态中的一个,并获得奖励\(r\)(确定值)。\(r\)是通过均值为0方差为1 的高斯函数生成的。智能体总是从固定起点出发,直到到达终止状态。现在分别采用轨迹采样方法和均匀采样方法估计在最优策略下的初始状态的价值。
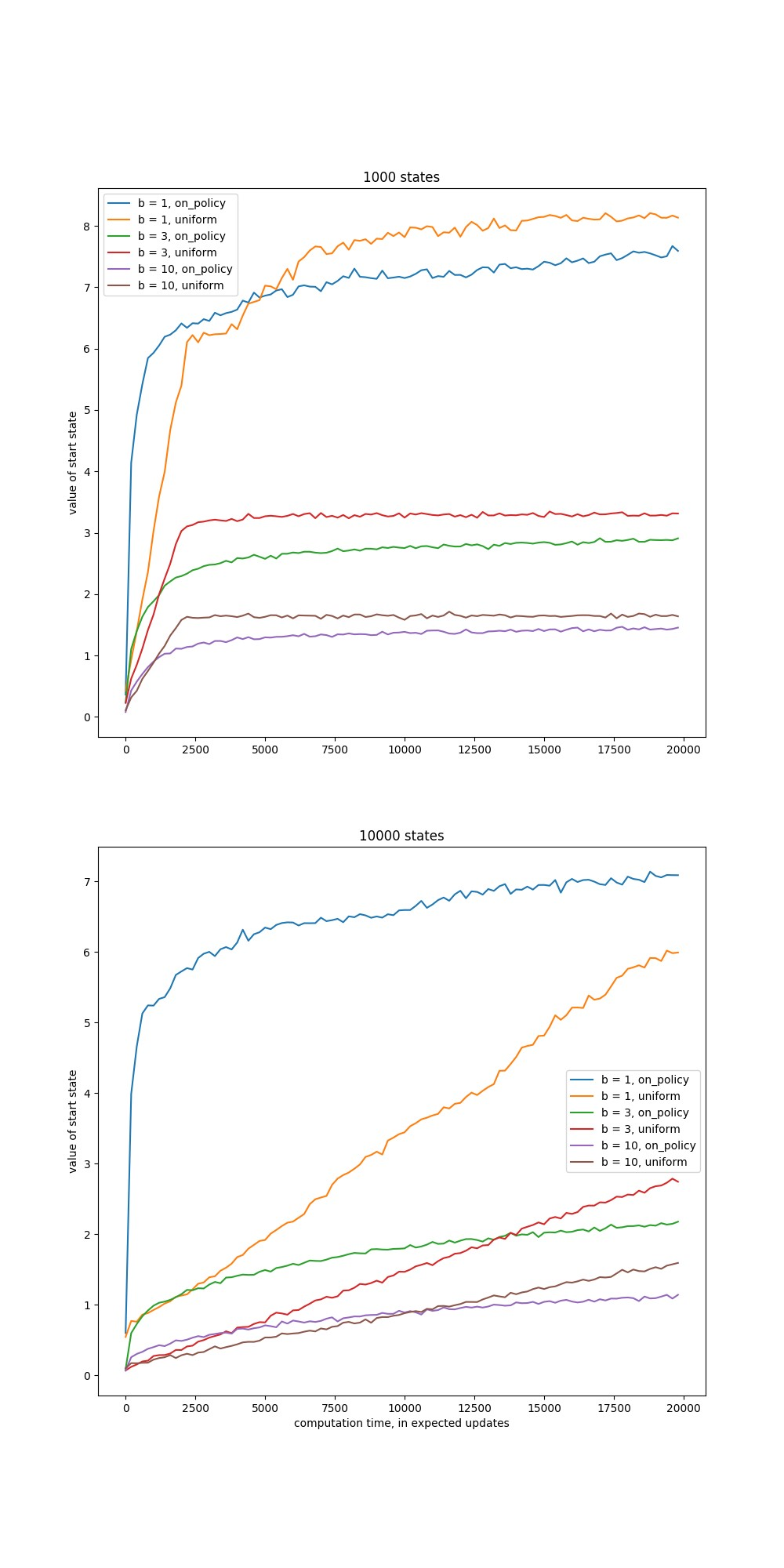
从实验结果可以看出,基于策略的轨迹采样方式具有更快的估计速度,但是在长远角度看,均匀采样会更加准确。但是当状态空间特别大,且分支较小的情况下,基于策略的轨迹采样方式具备非常好的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号