Python爬虫实例(五) requests+flask构建自己的电影库
目标任务:使用requests抓取电影网站信息和下载链接保存到数据库中,然后使用flask做数据展示。
爬取的网站在这里
最终效果如下:
主页:

可以进行搜索:输入水形物语
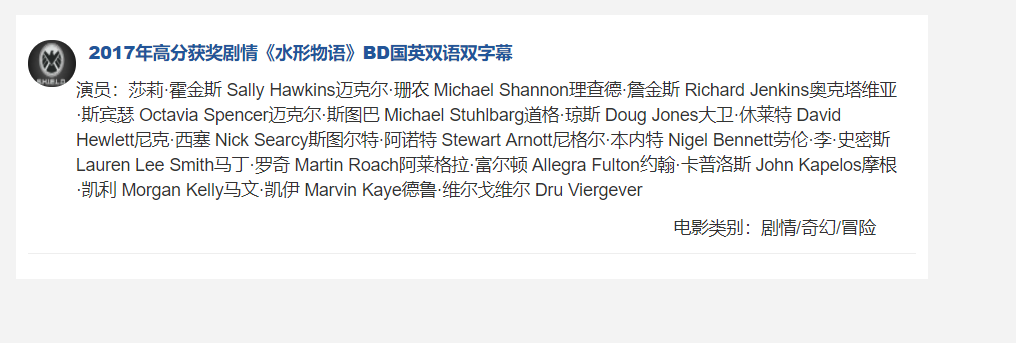
点击标题进入详情页:


爬虫程序
# -*- coding: utf-8 -*- import requests from urllib import parse import pymysql from lxml import etree headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 'Referer': 'http://www.dytt8.net/'} BASE_URL = 'http://www.dytt8.net' movie = {} def crawl_page_list(url): """ 获取列表页标题和详情链接 """ resp = requests.get(url, headers=headers) # replace,用?取代非法字符 html = resp.content.decode('gbk', 'replace') tree = etree.HTML(html) all_a = tree.xpath("//table[@class='tbspan']//a") for a in all_a: title = a.xpath("text()")[0] href = a.xpath("@href")[0] detail_url = parse.urljoin(BASE_URL, href) crawl_detail(detail_url, title) def crawl_detail(url, title): """ 下载并解析详情页 """ response = requests.get(url=url, headers=headers) tree = etree.HTML(response.content.decode('gbk', 'replace')) imgs = tree.xpath("//div[@id='Zoom']//img") # 海报图 cover_img = imgs[0] # 内容截图 screenshot_img = imgs[1] cover_url = cover_img.xpath('@src')[0] screenshot_url = screenshot_img.xpath('@src')[0] download_url = tree.xpath('//div[@id="Zoom"]//td/a/@href') # 迅雷下载链接 thunder_url = download_url[0] # 磁力链接 magnet_url = download_url[1] # 提取文本信息 infos = tree.xpath("//div[@id='Zoom']//text()") for index,info in enumerate(infos): if info.startswith("◎译 名"): translate_name = info.replace("◎译 名", "").strip() movie['translate_name'] = translate_name if info.startswith("◎片 名"): name = info.replace("◎片 名", "").strip() movie['name'] = name if info.startswith("◎年 代"): year = info.replace("◎年 代", "").strip() movie['year'] = year if info.startswith("◎产 地"): product_site = info.replace("◎产 地", "").strip() movie['product_site'] = product_site if info.startswith("◎类 别"): classify = info.replace("◎类 别", "").strip() movie['classify'] = classify if info.startswith("◎主 演"): temp = info.replace("◎主 演", "").strip() actors = [temp] for x in range(index+1, len(infos)): value = infos[x].strip() if value.startswith("◎"): break actors.append(value) movie['actors'] = "".join(actors) if info.startswith("◎简 介"): contents = info.replace("◎简 介 ", "").strip() content = [contents] for x in range(index+1, len(infos)): value = infos[x].strip() if value.startswith("【下载地址】"): break content.append(value) movie['content'] = str(content[1]) movie['title'] = title movie['cover_url'] = cover_url movie['screenshot_url'] = screenshot_url movie['thunder_url'] = thunder_url movie['magnet_url'] = magnet_url save_data(movie) def save_data(data): """ 存储到MySQL """ name = movie['name'] translate_name = movie['translate_name'] year = movie['year'] product_site = movie['product_site'] classify = movie['classify'] actors = movie['actors'] content = movie['content'] title = movie['title'] cover_url = movie['cover_url'] screenshot_url = movie['screenshot_url'] thunder_url = movie['thunder_url'] magnet_url = movie['magnet_url'] connection = pymysql.connect( host='ip', user = 'MySQL用户名', passwd='Mysql密码', db = 'movie', charset = 'utf8mb4', ) cursor1 = connection.cursor() sql ='insert into dytt(name,translate_name,year, product_site,classify,actors, title,content,cover_url,screenshot_url,thunder_url,magnet_url) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)' cursor1.execute(sql,(name,translate_name,year, product_site,classify,actors, title,content,cover_url,screenshot_url,thunder_url,magnet_url)) connection.commit() cursor1.close() connection.close() def main(): base_url = "http://www.dytt8.net/html/gndy/dyzz/list_23_{}.html" for i in range(1, 20): base_url = base_url.format(str(i)) crawl_page_list(base_url) if __name__ == '__main__': main()
Flask项目目录如下:
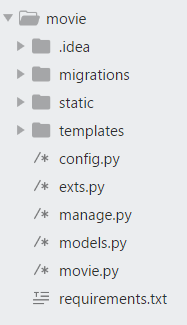
在项目目录下运行如下命令,完成数据库迁移:
python manage.py db init
python manage.py db migrate
python manage.py db upgrade
接着运行爬虫程序将数据写入MySQL,然后启动项目即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号