
5 决策树
决策树
决策树模型与学习
决策树模型
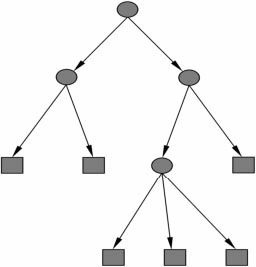
决策树与if-then规则
决策树与条件概率分布
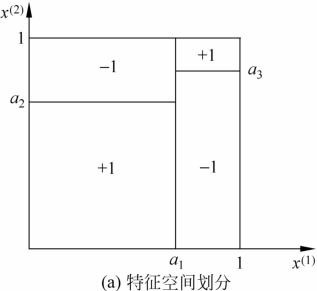
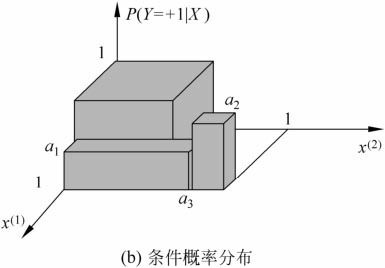
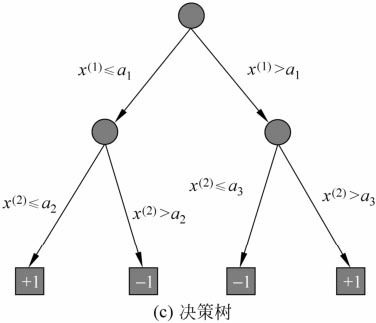
决策树学习
特征选择
信息增益
熵(entropy)是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为 P(X=xi)= pi,则随机变量X的熵定义为:
![]()
熵越大,随机变量的不确定性就越大。从定义可验证 0 ≤ H(P)≤ logn
条件熵 H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,定义为X给定条件下Y的条件概 率分布的熵对X的数学期望:
![]()
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条 件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。
信息增益(information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。其定义如下:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即: g(D,A)= H(D)- H(D|A)
一般地,熵 H(Y)与条件熵 H(Y|X)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
信息增益比
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据集的经验熵大的时候,信息增益值会偏大。反之,信息增益值会偏小。使用信息增益比(information gain ratio)可以对这一问题进行校正。信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验熵H(D)之比:
![]()
决策树的生成
ID3算法
ID3算法的核心是在决策树各个结点上用信息增益准则选择特征,递归地构建决策树。ID3相当于用极大似然法进行概率模型的选择。
ID3算法只有树的生成,所以该算法生成的树容易产生过拟合。
C4.5的生成算法
C4.5在生成的过程中,用信息增益比来选择特征。
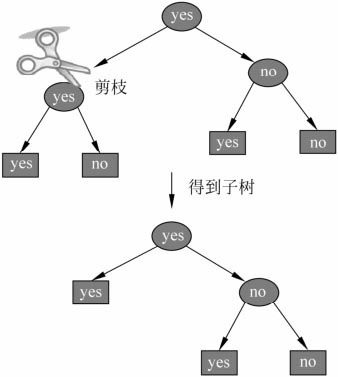
决策树的剪枝
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数 (cost function)来实现。
设树T的叶结点个数为T,t是树T的叶结点,叶结点有Nt个样本点,其中k类的样本点有Ntk个,Ht(T)为叶结点t上的经验熵,a≥0为参数,则决策树学习的损失函数可以定义为:
![]()
CART算法
CART同样由特征选择、树的生成及剪枝组成, 既可以用于分类也可以用于回归。以下将用于分类与回归的树统称为决策树。
CART生成
决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
回归树的生成
选择第j个变量x(j)和它的取值s,作为切分变量(splitting variable)和切分点(splitting point),并定义两个区域:
![]()
用平方误差最小的准则求解每个单元上的最优输出值。易知,单元Rm上的cm的最优值是Rm上的所有输入实例xi对应的输出yi的均值(假设一个区域中有两组数据,y1=0,y2=a,相当于平方误差 y = x²+(a-x)²,通过求导易得x为 a/2,也就是均值),即
通过寻找最小均方误差点,实现切分:
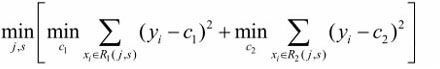
遍历所有输入变量,找到最优的切分变量j,构成一个对(j,s)。依此将输入空间划分为两个区域。接着,对每个区域重复上述划分过程,直到满足停止条件为止。这样就生成一棵回归树。这样的回归树通常称为最小二乘回归树(least squares regression tree)。(其实就是一种暴力解法)
分类树的生成
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点。
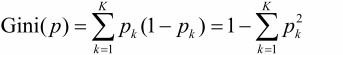
对于二类分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为 Gini(p) = 2p(1-p)
如果样本集合D根据特征A是否取某一可能值a被分割成D1和D2两部分,则在特征A的条件下,集合D的基尼指数定义为
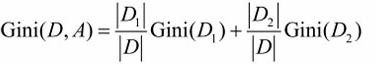
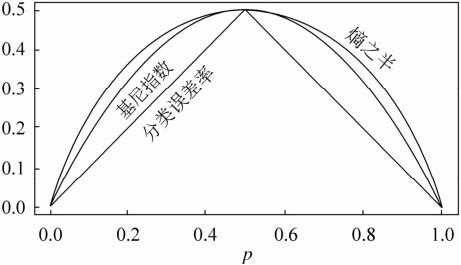
下图显示二类分类问题中基尼指数Gini(p)、熵之半 0.5H(p)和分类误差率的关系。横坐标表示概率p,纵坐标表示损失。可以看出基尼指数和熵之半的曲线很接近,都可以近似地代表分类差率。
回归树用平方误差选择最优特征,分类树用基尼指数选择最优特征,除此之外基本流程基本相同。
CART剪枝
CART剪枝算法从“完全生长”的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更准确的预测。
对固定的a,一定存在使损失函数Ca(T)最小的子树,将其表示为Ta。Ta在损失函数Ca(T)最小的意义下是最优的。容易验证这样的最优子树是唯一的。当a大的时候,最优子树Ta偏小;当a小的时候,最优子树Ta偏大。极端情况,当a=0时,整体树是最优的。当a→ ∞时,根结点组成的单结点树是最优的。设对a递增的序列,对应的最优子树序列为Tn,子树序列第一棵包含第二棵,依次类推。
具体地,从整体树T0开始剪枝。对T0的任意内部结点t,以t为单结点树的损失函数是 Ca(t)= C(t)+ a
以t为根结点的子树Tt的损失函数是 Ca(Tt)= C(Tt)+ a|Tt|
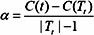 ,
,对此子树序列,应用独立的验证数据集交叉验证,平方误差或基尼指数最小的决策树被认为是最优的决策树,在子树序列中,每棵子树T1,T2,…,Tn都对应于一个参数a1,a2,…,an,所以,当最优子树Tk确定时,对应的ak也确定了,即得到最优决策树Ta。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号