

Redis集群
集群的主要作用
- 数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及,例如,如果单机内存太大,
bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出…… - 高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
集群至少需要三主三从,否则无法建立。
Step1:开启6个redis服务,并在各个服务的redis.conf中开启集群功能。
# 为每一个集群节点指定一个 pid_file pidfile ~/Desktop/redis-cluster/redis_7000.pid # 启动集群模式 cluster-enabled yes # 每一个集群节点都有一个配置文件,这个文件是不能手动编辑的。确保每一个集群节点的配置文件不通 cluster-config-file nodes-7000.conf # 集群节点的超时时间,单位:ms,超时后集群会认为该节点失败 cluster-node-timeout 5000
Step2:输入集群指令:
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6379 127.0.0.1:6378 127.0.0.1:6377 127.0.0.1:6376 127.0.0.1:6375 127.0.0.1:6374
Step3:集群成功后任意连接其中一个主机,输入set命令,会发现提示数据转移到集群中的另外一台主机上。
redis-cli -c -p 6379 set name curry -> Redirected to slot [5798] located at 127.0.0.1:6378 OK
一致性哈希分区方案
一致性哈希算法将 整个哈希值空间 组织成一个虚拟的圆环,范围是 [0 , 232-1],对于每一个数据,根据 key 计算 hash 值,确数据在环上的位置,然后从此位置沿顺时针行走,找到的第一台服务器就是其应该映射到的服务器:
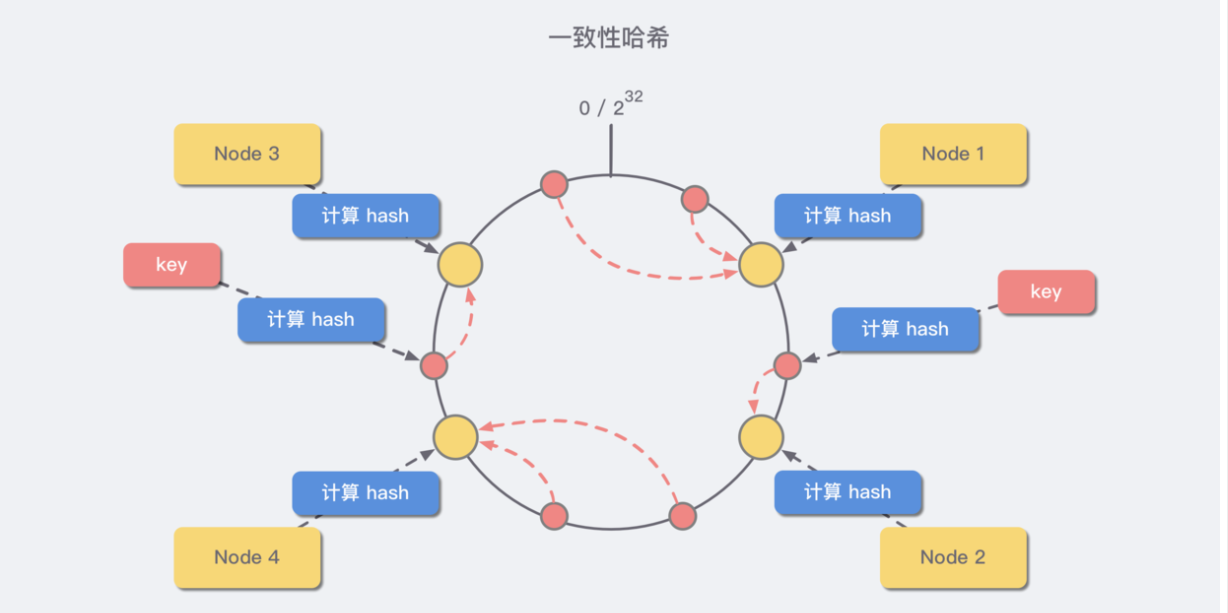
与哈希取余分区相比,一致性哈希分区将 增减节点的影响限制在相邻节点。如果在 node1 和 node2 之间增加 node5,则只有 node2 中的一部分数据会迁移到 node5;如果去掉 node2,则原 node2 中的数据只会迁移到 node4 中,只有 node4 会受影响。
一致性哈希分区的主要问题在于,当 节点数量较少 时,增加或删减节点,对单个节点的影响可能很大,造成数据的严重不平衡。还是以上图为例,如果去掉 node2,node4中的数据由总数据的 1/4 左右变为 1/2 左右,与其他节点相比负载过高。
Redis的数据分区方案是在一致性哈希分区的基础上引入了 虚拟节点 的概念。Redis 集群使用的便是该方案,其中的虚拟节点称为 槽(slot)。槽是介于数据和实际节点之间的虚拟概念,每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽 解耦 了 数据和实际节点 之间的关系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有 4 个实际节点,假设为其分配 16 个槽(0-15);
- 槽 0-3 位于 node1;4-7 位于 node2;以此类推....
如果此时删除 node2,只需要将槽 4-7 重新分配即可,例如槽 4-5 分配给 node1,槽 6 分配给 node3,槽 7 分配给 node4;可以看出删除 node2 后,数据在其他节点的分布仍然较为均衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号