


DS博客作业03--树
0.PTA得分截图

1.本周学习总结
1.1 总结树及串内容
串
1.串的知识点
- 头文件是#include< string >,C++的string不必担心内存是否足够、字符串长度等等,集成了大部分常用函数
下面是常用函数
string类常用的构造函数有:
string str; //生成一个空字符串
string str ("ABC") //等价于 str="ABC"
string str ("ABC", n) // 将"ABC"存到str里,最多存储前n个字节
string s("ABC",a,b) //将"ABC"的a位置,做为字符串开头,存到str里.且最多存储b个字节.
string s(n, 'A') //存储n个'A'到str里
string类常用的成员函数有:
str.length(); //获取字符串长度
str.size(); //获取字符串数量,等价于length()
str.swap(str2); //替换str1 和 str2 的字符串
str.puch_back ('A'); //在str1末尾添加一个'A'字符,参数必须是字符形式
str.append ("ABC"); //在str1末尾添加一个"ABC"字符串,参数必须是字符串形式
str.insert (2,"ABC"); //在str1的下标为2的位置,插入"ABC"
str.erase(2); //删除下标为2的位置,比如: "ABCD" --> "AB"
str.erase(2,1); //从下标为2的位置删除1个,比如: "ABCD" --> "ABD"
str.clear(); //删除所有
str.replace(2,4, "ABCD"); //从下标为2的位置,替换4个字节,为"ABCD"
str.empty(); //判断为空, 为空返回true
函数参考自别处,详细见[https://www.cnblogs.com/lifexy/p/8642163.html]
2.串的BF算法(又称古典的、经典的、朴素的、穷举的)
Brute-Force算法
简称为BF算法,亦称简单匹配算法,其基本思路是:
1.从目标串s=“s0s1…sn-1”的第一个字符开始和模式串t=“t0t1…tm-1”中的第一个字符比较
2.若相等,则继续逐个比较后续字符;
3.否则从目标串s的第二个字符开始重新与模式串t的第一个字符进行比较。
4.依次类推,若从模式串s的第i个字符开始,每个字符依次和目标串t中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,函数返回-1。

- 实现的具体代码:
int index(SqString s, SqString t)
{
int i = 0, j = 0;
while (i < s.length && j < t.length)
{
if (s.data[i] == t.data[j]) //继续匹配下一个字符
{
i++; //主串和子串依次匹配下一个字符
j++;
}
else //主串、子串指针回溯重新开始下一次匹配
{
i = i - j + 1; //主串从下一个位置开始匹配
j = 0; //子串从头开始匹配
}
}
if (j >= t.length)
return(i - t.length); //返回匹配的第一个字符的下标
else
return(-1); //模式匹配不成功
}
3.串的KMP算法,相较于BF算法的改进之处:1.主串不需回溯i指针2.将模式串向右“滑动”尽可能远的一段距离



- next数组例题
![]()
![]()
- 由模式串t求出next值

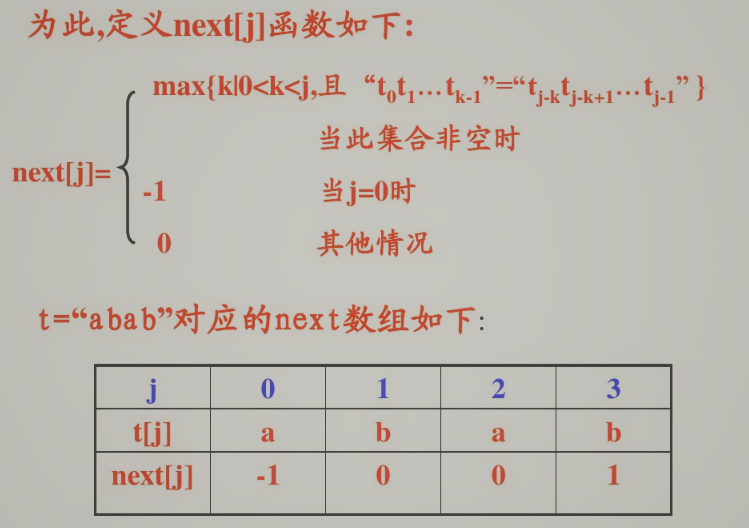
void GetNext(SqString t, int next[])
{
int j, k;
j = 0;k = -1;next[0] = -1;
while (j < t.length - 1)
{
if (k == -1 || t.data[j] == t.data[k])
{
j++;k++;
next[j] = k;
}
else k = next[k];
}
}
- 匹配例题
![]()
![]()
- KMP算法实现:


int KMPIndex(SqString s, SqString t)
{
int next[MaxSize], i = 0, j = 0;
GetNext(t, next);
while (i < s.length && j < t.length)
{
if (j == -1 || s.data[i] == t.data[j])
{
i++;
j++; //i,j各增1
}
else j = next[j]; //i不变,j后退
}
if (j >= t.length)
return(i - t.length); //匹配模式串首字符下标
else
return(-1); //返回不匹配标志
}
- next数组缺陷:(这三次匹配字符都是a,j可一次滑到0)
![]()
- 将next数组修改为nextval数组,由模式串求出nextval数组:

void GetNextval(SqString t, int nextval[])
{
int j = 0, k = -1;
nextval[0] = -1;
while (j < t.length)
{
if (k == -1 || t.data[j] == t.data[k])
{
j++;k++;
if (t.data[j] != t.data[k])
nextval[j] = k;
else
nextval[j] = nextval[k];
}
else
k = nextval[k];
}
}
- 改良后的KMP算法:
int KMPIndex1(SqString s, SqString t)
{
int nextval[MaxSize], i = 0, j = 0;
GetNextval(t, nextval);
while (i < s.length && j < t.length)
{
if (j == -1 || s.data[i] == t.data[j])
{
i++;
j++;
}
else
j = nextval[j];
}
if (j >= t.length)
return(i - t.length);
else
return(-1);
}
二叉树
1.二叉树基本知识点
- 定义:是n(n>=0)个结点的有限集合,它或为空树(n=0),或由一个根结点和至多两棵称为根的左子树和右子树的互不相交的二叉树组成。
- 注:二叉树中不存在度大于2的结点,并且二叉树的子树有左子树和右子树之分。
- 满二叉树:如果所有分支结点都有双分结点;并且叶结点都集中在二叉树的最下一层。
- 完全二叉树:深度为k 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应,没有单独右分支结点
- 二叉树性质:1.非空二叉树上叶节点数等于双分支节点数加1:n0=n2+1。2.在二叉树的第 i 层上至多有2的i-1次方个结点(i≥1)。3.高度为h的二叉树至多有2的h次方-1个节点(h≥1)4.具有n个结点的完全二叉树的深度必为log⒉n + 1
2.二叉树存储结构
- 顺序存储
![]()
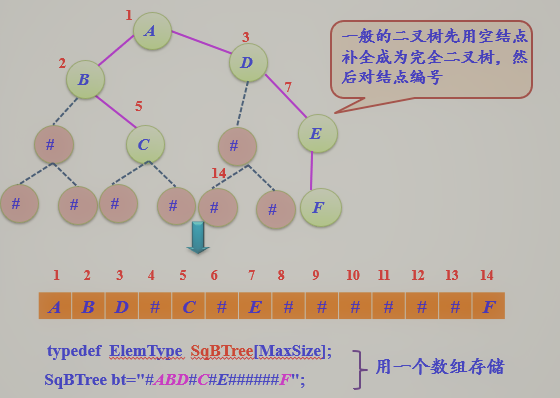
typedef ElemType SqBTree[MaxSize];
SqBTree bt="ABCDEF#####";
-
顺序存储缺点:
对于完全二叉树来说,其顺序存储是十分合适
在最坏的情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却需要2k-1的一维数组。空间利用率太低
数组,查找、插入删除不方便。 -
链式存储
![]()
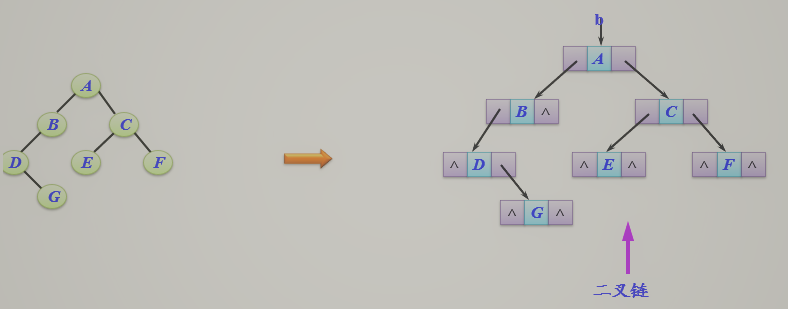
typedef struct node
{ ElemType data;
struct node *lchild, *rchild;
} BTNode;
typedef BTNode *BTree;
n个节点,2n个指针域
非空指针域有n-1个,空指针域有n+1个
3.二叉树的建法
- 二叉树的顺序存储结构转成二叉链
![]()
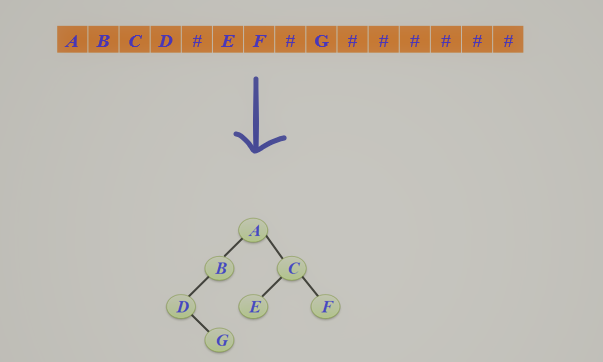
BTree CreateBTree(string str,int i)
{
int len;
BTree bt;
bt=new TNode;
len=str.size();
if(i>len || i<=0) return NULL;
if(str[i]=='#') return NULL;
bt->data =str[i];
bt->lchild =CreateBTree(str,2*i);
bt->rchild =CreateBTree(str,2*i+1);
return bt;
}
- 先序遍历递归建树
![]()
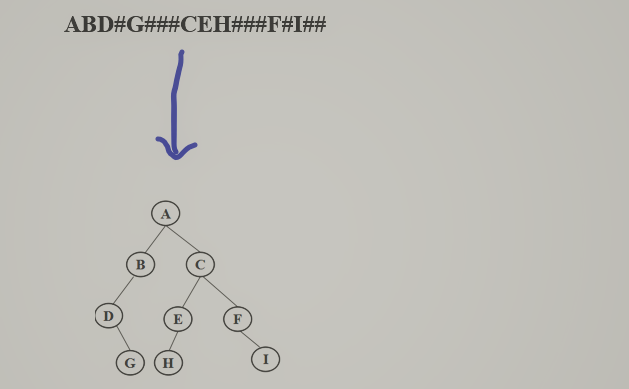
BTree CreatTree(string str, int &i)
{
BTree bt;
if (i > len - 1) return NULL;
if (str[i] == '#') return NULL;
bt = new BTNode;
bt->data = str[i];
bt->lchild = CreatTree(str, ++i);
bt->rchild = CreatTree(str, ++i);
return bt;
}
- 层次法建树
![]()
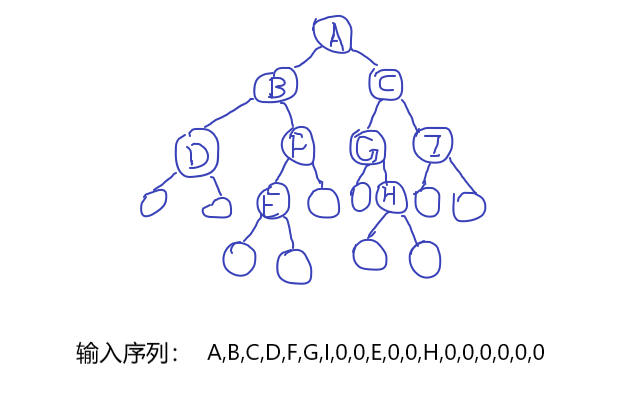
void CreateBTree(BTree &BT,string str)
{ BTree T;int i=0;
queue<BTree> Q;//队列
if( str[0]!='0' ){ /*分配根结点单元,并将结点地址入队*/
BT =new BTNode;
BT->data = str[0];
BT->lchild=BT->rchild=NULL;
Q.push(BT);
}
else BT=NULL; /* 若第1个数据就是0,返回空树 */
while( !Q.empty())
{
T = Q.front();/*从队列中取出一结点地址*/
Q.pop();
i++;
if(str[i]=='0' ) T->lchild = NULL;
else
{ /*生成左孩子结点;新结点入队*/
T->lchild = new BTNode;
T->lchild->data = str[i];
T->lchild->lchild=T->lchild->rchild=NULL;
Q.push(T->lchild);
}
i++; /* 读入T的右孩子 */
if(str[i]=='0') T->rchild = NULL;
else
{ /*生成右孩子结点;新结点入队*/
T->rchild = new BTNode;;
T->rchild->data = str[i];
T->rchild->lchild=T->rchild->rchild=NULL;
Q.push(T->rchild);
}
} /* 结束while */
}
- 括号法建立二叉树
![]()
1.广义表表示树结构
2.左括号表示左孩子
3.逗号表示右孩子
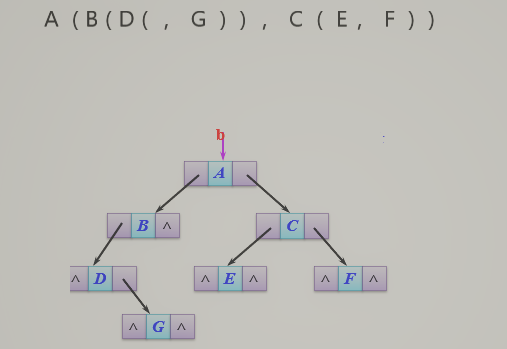
void CreateBTNode(BTNode * &b,char *str)
{ //由str 二叉链b
BTNode *St[MaxSize], *p;
int top=-1, k , j=0;
char ch;
b=NULL; //建立的二叉链初始时为空
ch=str[j];
while (ch!='\0') //str未扫描完时循环
{ switch(ch)
{
case '(': top++; St[top]=p; k=1; break; //可能有左孩子结点,进栈
case ')': top--; break;
case ',': k=2; break; //后面为右孩子结点
default: //遇到结点值
p=(BTNode *)malloc(sizeof(BTNode));
p->data=ch; p->lchild=p->rchild=NULL;
if (b==NULL) //p为二叉树的根结点
b=p;
else //已建立二叉树根结点
{ switch(k)
{
case 1: St[top]->lchild=p; break;
case 2: St[top]->rchild=p; break;
}
}
}
j++; ch=str[j]; //继续扫描str
}
}
4.二叉树的遍历
- 先序遍历:访问根结点,访问根结点,先序遍历左子树,先序遍历右子树
![]()
void PreOrder(BTree bt)
{
if (bt!=NULL)
{ printf("%c ",bt->data); //访问根结点
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
- 中序遍历:中序遍历左子树,访问根结点,中序遍历右子树
![]()
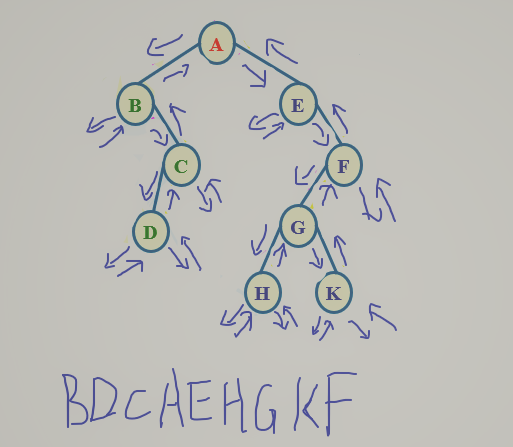
void InOrder(BTree bt)
{
if (bt!=NULL)
{ InOrder(bt->lchild);
printf("%c ",bt->data); //访问根结点
InOrder(bt->rchild);
}
}
- 后序遍历:后序遍历左子树,后续遍历右子树,访问根结点
![]()
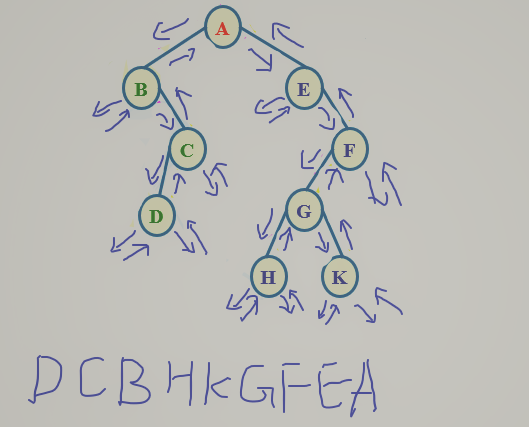
void PostOrder(BTree bt)
{ if (bt!=NULL)
{ PostOrder(bt->lchild);
PostOrder(bt->rchild);
printf("%c ",bt->data); //访问根结点
}
}
- 层次遍历,一层一层从左到右访问
![]()
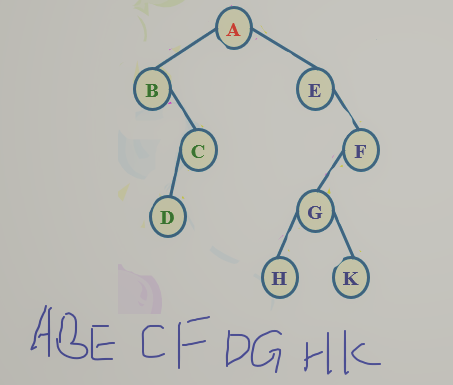
void LevelOrder(BTree bt)
{
queue<BTree> q; //初始化队列,元素为树节点
BTree p; //树指针p
if (bt != NULL) q.push(bt); //根节点入队列
while (!q.empty())
{
p = q.front();
q.pop();
cout << p->data;
if (p->lchild)q.push(p->lchild);
if (p->rchild)q.push(p->rchild);
}
}
5.二叉树的应用:表达式树
伪代码:
建表达式树函数
定义两个栈// 一个放树,一个放符号
while(是表达式元素)
if 元素为数字 建树节点,入栈
else
if 栈顶符号优先级小于当前字符
将当前符号入栈
end if
if 等于
将栈顶符号出栈
end if
if 大于
建树节点,将栈内最上面两个树根结点出栈,分别作为树节点的右子树和左子树
将新建树节点入栈,栈顶符号出栈
end if
end while
while(符号栈不空)
重复上个while里if大于的操作
end while
计算函数
if 是叶节点 返回节点的值
end if
两个操作数进行递归调用
判断相应的符号,进行相应的运算 //注意除数为0的情况
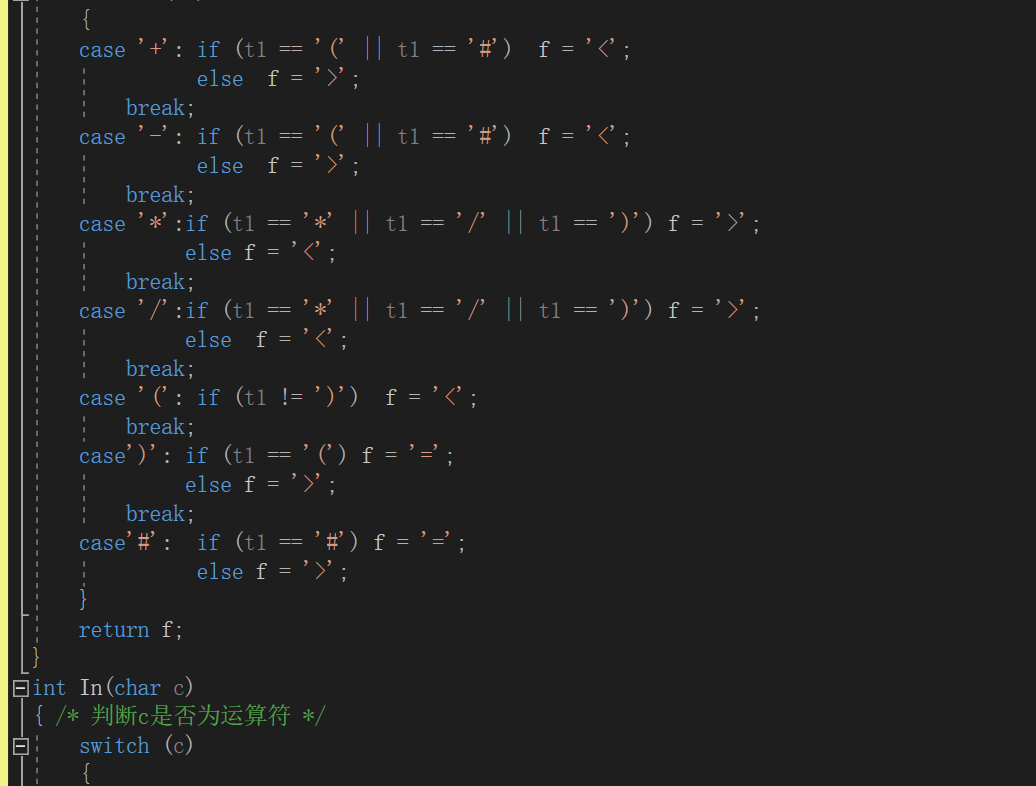
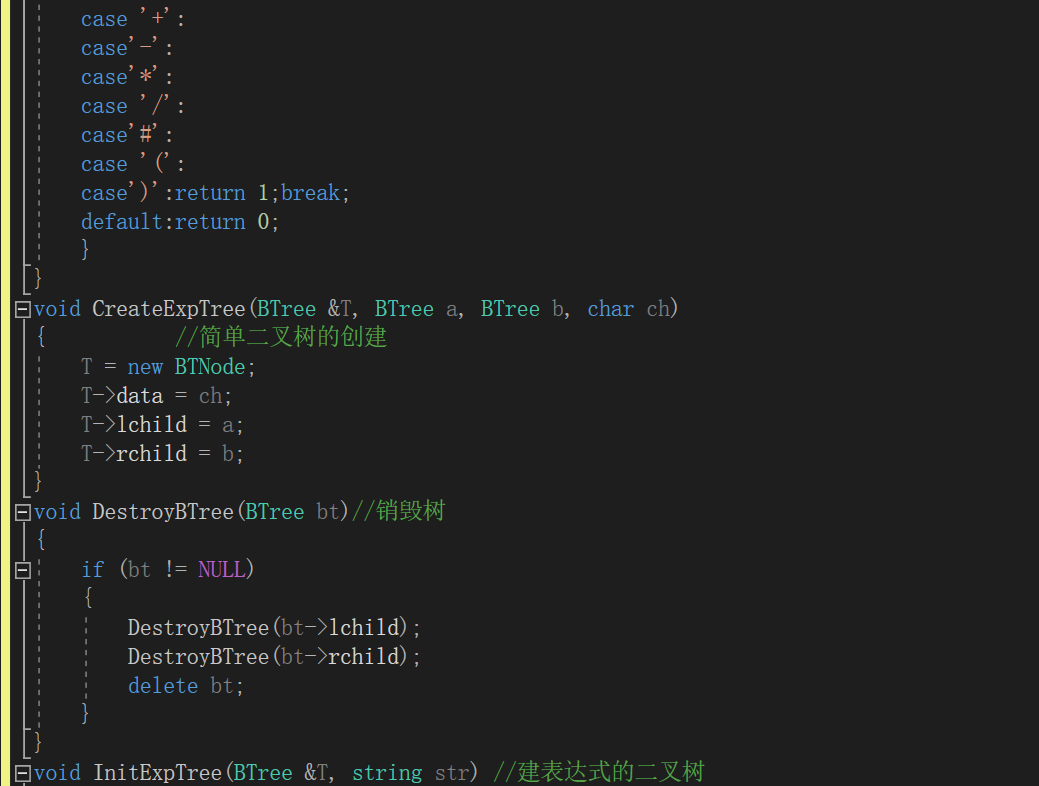
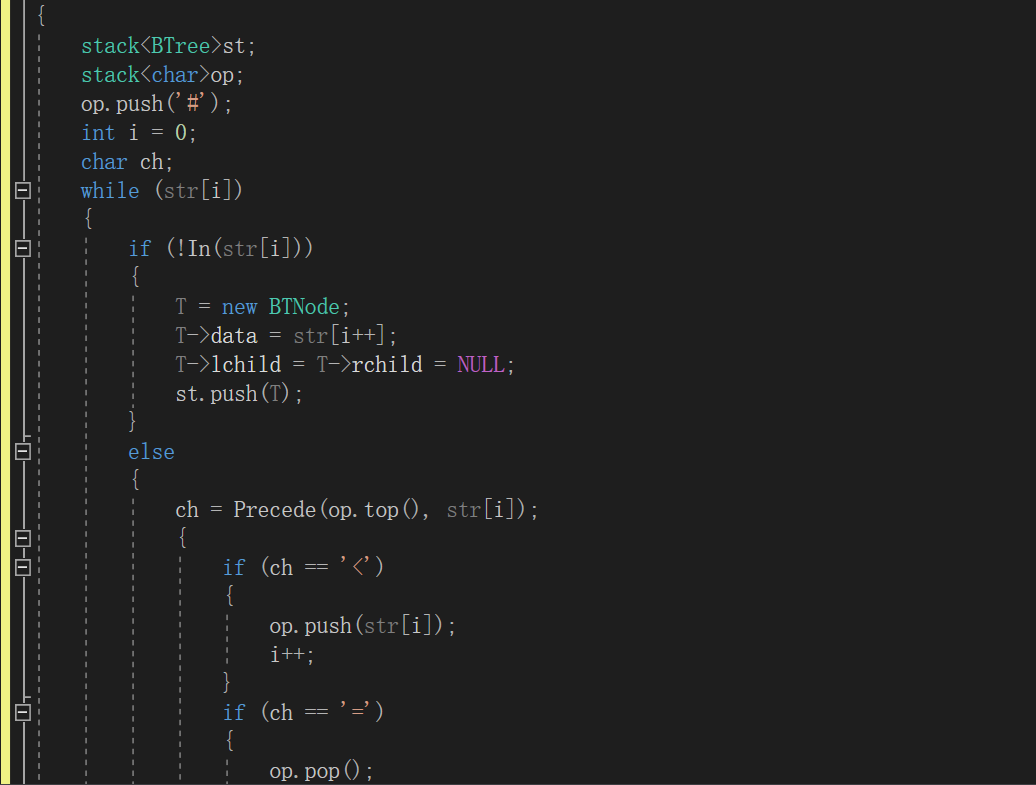
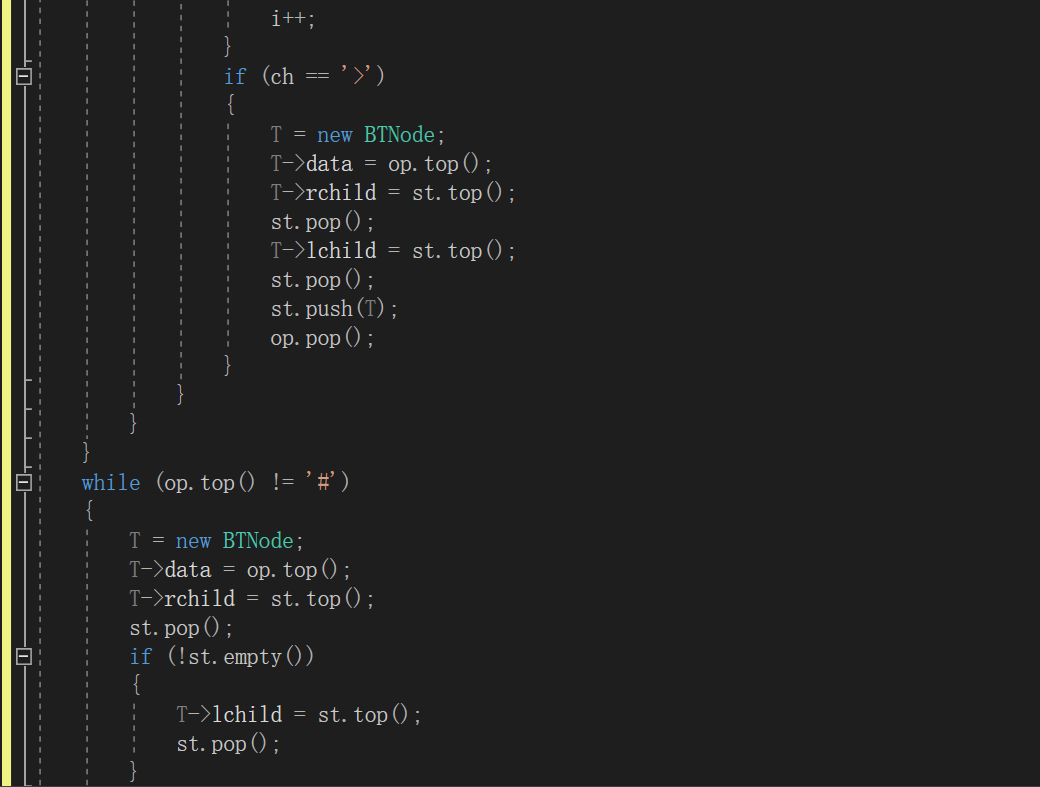
树
- 树的性质:1.树中的结点数等于所有结点的度数之和加1。2.度为m的树中第i层上至多有mi-1个结点(i≥1)。
1.树的存储结构
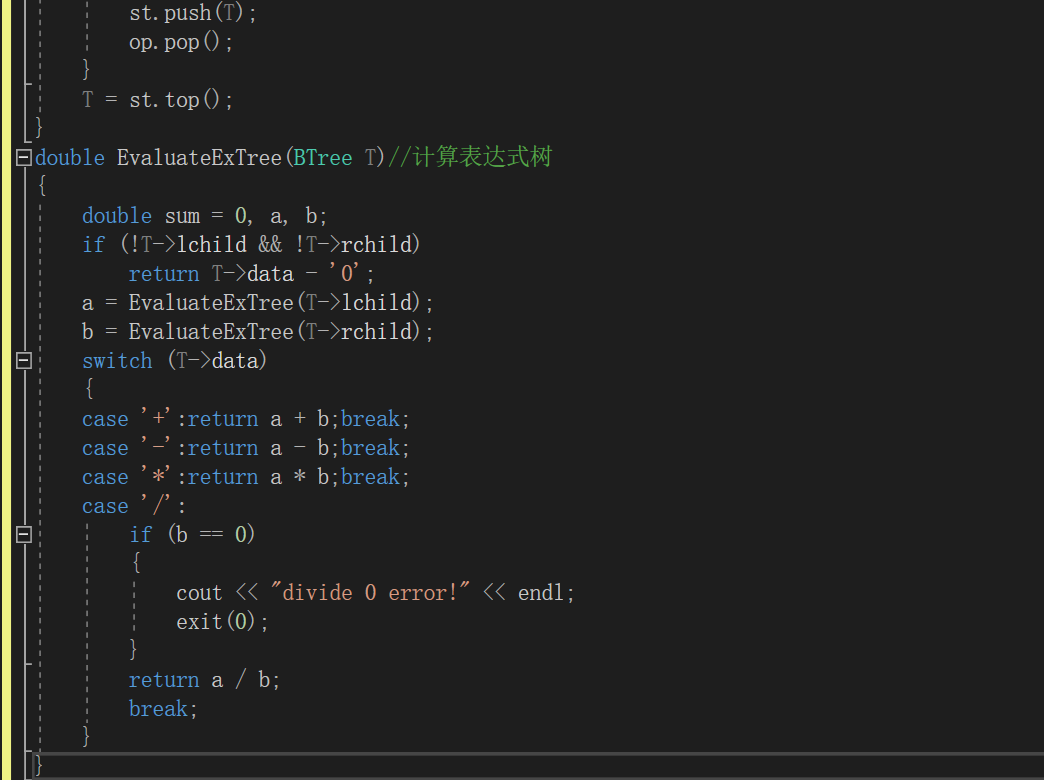
- 双亲存储结构
![]()
树中任何结点只有唯一的双亲结点,缺点是找父亲容易,找孩子不容易
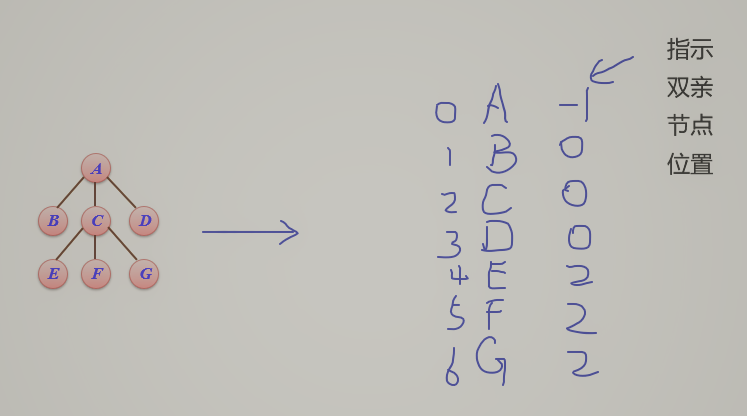
typedef struct
{ ElemType data; //结点的值
int parent; //指向双亲的位置
} PTree[MaxSize];
- 孩子链存储结构
![]()
缺点:1.空指针太多2.找父亲不容易
typedef struct node
{ ElemType data; //结点的值
struct node *sons[MaxSons]; //指向孩子结点
} TSonNode;
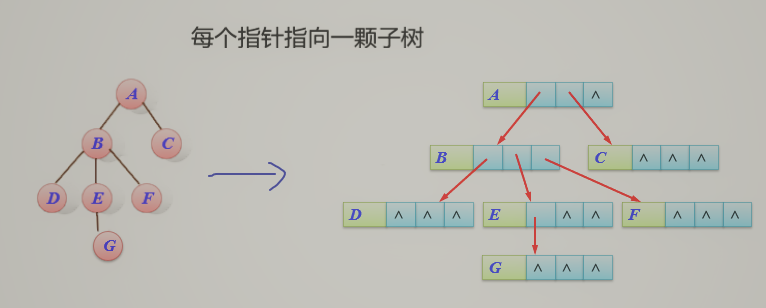
- 孩子兄弟链存储结构
![]()
每个结点固定只有两个指针域,类似二叉树,缺点是找父亲不容易。
typedef struct tnode
{ ElemType data; //结点的值
struct tnode *son; //指向兄弟
struct tnode *brother; //指向孩子结点
} TSBNode;
在一棵树T中最常用的操作是查找某个结点的祖先结点,采用双亲存储结构
如最常用的操作是查找某个结点的所有兄弟,采用孩子链存储结构或者孩子兄弟链存储结构
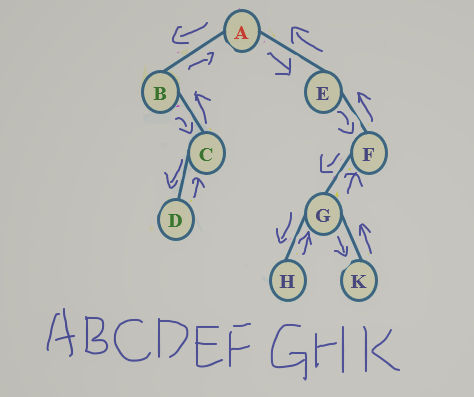
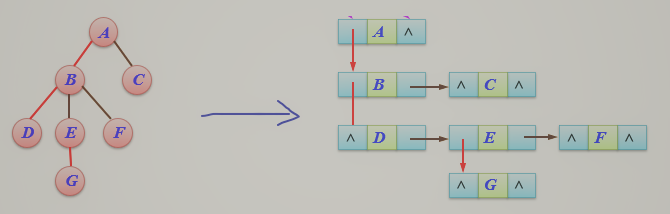
2.树的遍历:先根遍历,后根遍历,层次遍历
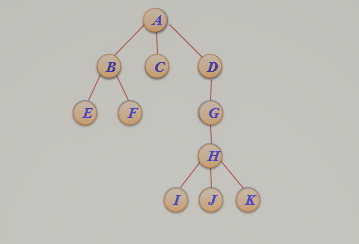
对于上图树的遍历:
1.先根遍历:A,B,E,F,C,D,G,H,I,J,K
2.后根遍历:E,F,B,C,I,J,K,H,G,D,A
3.层次遍历:A,B,C,D,E,F,G,H,I,J,K
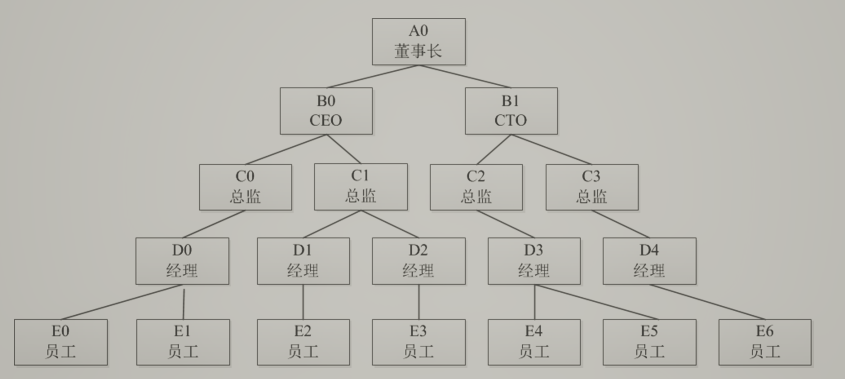
3.树的应用
树的应用有很多,例如代码查重,公司管理关系等。
代码查重依据代码生成代码树,比较树的相似度,公司管理关系如图:
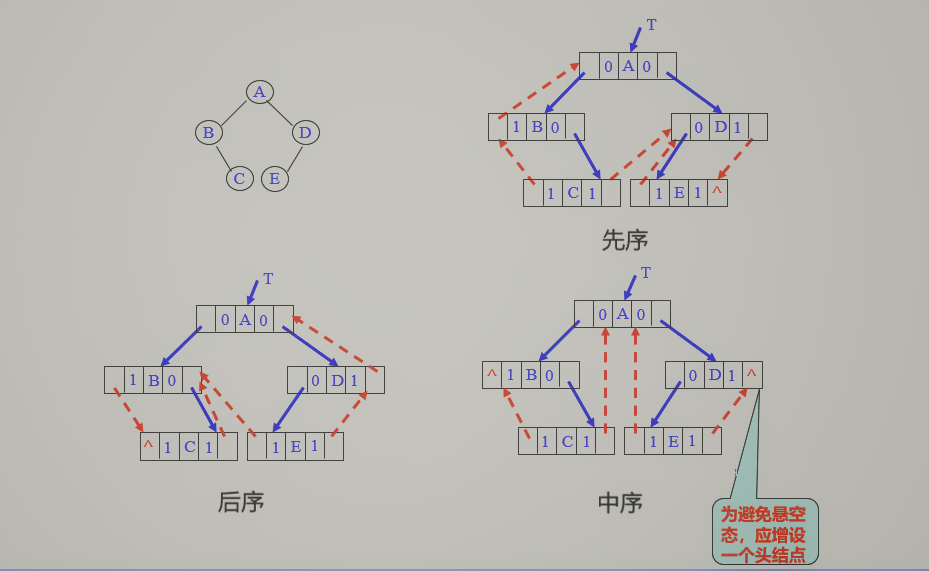
线索二叉树
概念:二叉链存储结构时,每个节点有两个指针域,总共有2n个指针域。有效指针域:n-1(根节点没指针指向)空指针域:n+1利用这些空链域,指向该线性序列中的“前驱”和“后继”的指针,称作线索。
1.线索二叉树存储结构
typedef struct node
{ ElemType data; //结点数据域
int ltag,rtag; //增加的线索标记
struct node *lchild; //左孩子或线索指针
struct node *rchild; //右孩子或线索指针
} TBTNode; //线索树结点类型定义
2.线索二叉树的操作
- 若结点有左子树,则lchild指向其左孩子,没有则指向它的前驱(线索);
- 若结点有右子树,则rchild指向其右孩子,没有则指向其后继(线索) 。
3.根据遍历方法的不同,分为先序线索二叉树、中序线索二叉树、后序线索二叉树。
哈夫曼树、并查集
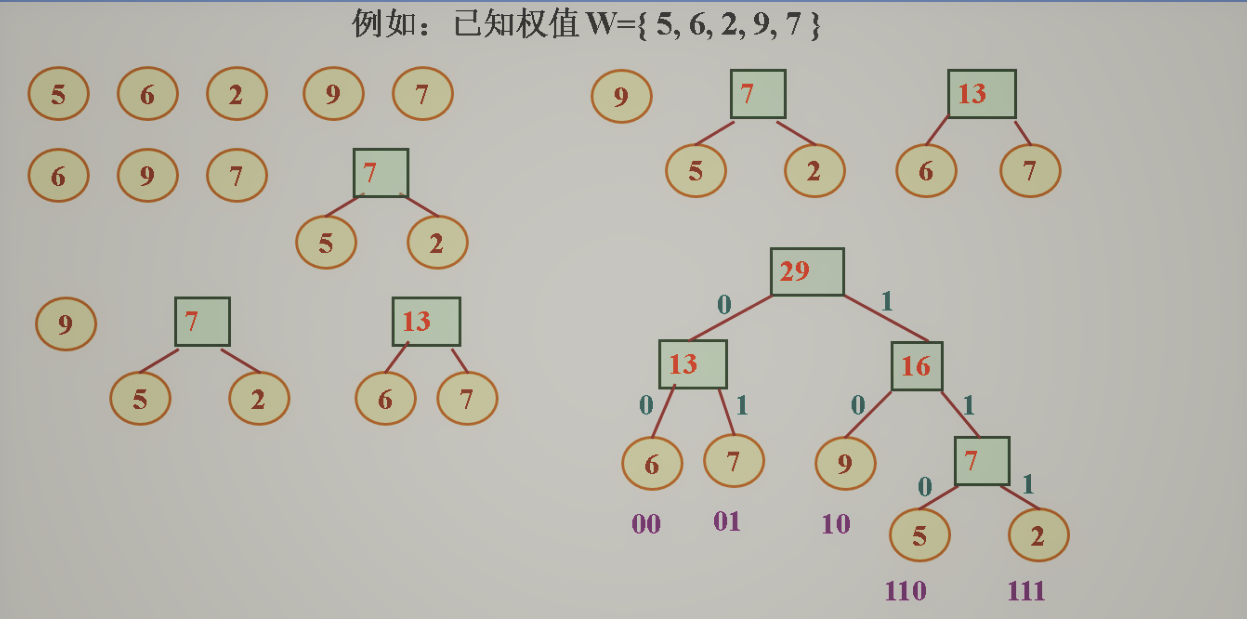
1.哈夫曼树
- 定义:定义:给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。
- 带权路径长度:设二叉树具有n个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积的和,叫做二叉树的带权路径长度。
- 原则:权值越大的叶结点越靠近根结点。权值越小的叶结点越远离根结点。
- 特点:1.没有单分支节点。2.n=2n0-1。
- 构造过程:1.在二叉树集合F中选取根结点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根结点的权值为其左、右子树根结点权值之和。
2.在集合F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到集合F中。
3.重复以上操作直到集合剩余一颗树。 - 如图
![]()
- 存储结构
typedef s truct
{
char data;//节点值
float weight;// 权重
int parent;//双亲节点
int lchild;//左孩子节点
int rchild;//右孩子节点
}HTNode;
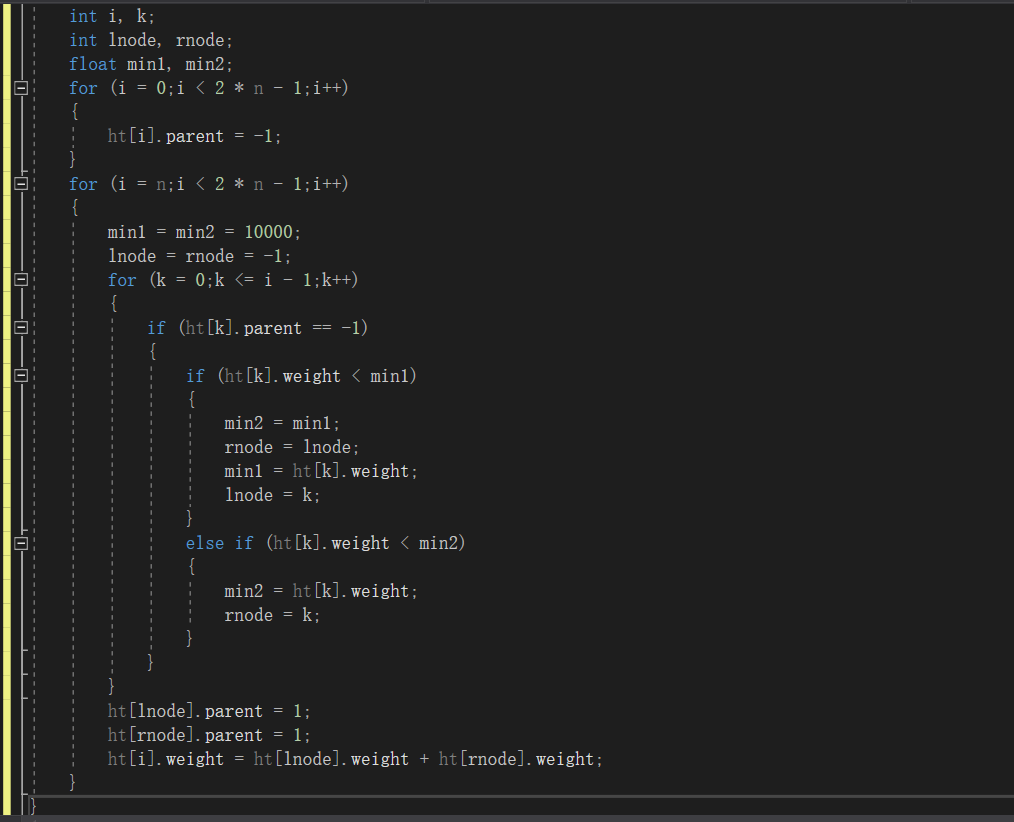
- 建哈曼夫树算法
![]()
2.并查集
- 概念:并查集是一种树型的数据结构,常用于处理一些不相交集合的合并及查询问题。
- 结构体定义
typedef struct node
{
int data; //结点对应人的编号
int rank; //结点秩,大致为树的高度
int parent; //结点对应双亲下标
} UFSTree; //并查集树的结点类型
- 并查集的初始化
void MAKE_SET(UFSTree t[],int n)/*初始化并查集树*/
{
int i;/*循环计数*/
for (i = 1; i <= n; i++)
{
t[i].data = i;/*数据为该人的编号*/
t[i].rank = 0;/*秩初始化为0*/
t[i].parent = i;/*双亲初始化指向自已*/
}
}
- 查找一个元素所属集合
int FIND_SET(UFSTree t[],int x) //在x所在子树中查找集合编号
{ if (x!=t[x].parent) //双亲不是自已
return(FIND_SET(t,t[x].parent)); //递归在双亲中找x
else
return(x); //双亲是自已,返回x
}
- 两个元素各自所属的集合的合并
void UNION(UFSTree t[],int x,int y)/*将x和y所在的子树合并*/
{
x = FIND_SET(t,x);/*查找x所在分离集合树的编号*/
y = FIND_SET(t,y);/*查找y所在分离集合树的编号*/
if (t[x].rank > t[y].rank)/*y结点的秩小于x结点的秩*/
{
t[y].parent = x; /*将y连到x结点上,x作为y的双亲结点*/
}
else/*y结点的秩大于等于x结点的秩*/
{
t[x].parent = y; /*将x连到y结点上,y作为x的双亲结点*/
if (t[x].rank == t[y].rank)/*x和y结点的秩相同*/
{
t[y].rank++;/*y结点的秩增1*/
}
}
}
1.2对树的认识及学习体会
刚开始了解到树的概念,感觉理解起来不难,但随着学习发现,只是树的模型易于理解,在写算法的时候非常复杂。树结构最常用递归算法,而我本来递归就不是很好,在学树的时候就十分茫然。老师上课将的感念什么的,可以理解,但是自己编程时候却感到无从下手,树的编程十分容易出错,从开始到完全通过要花很长时间。我也从pta题目中对树的理解更深了一层,但还不是很熟练,树的学习的的确确需要仔细钻研,而我没有做到这一点。实验课看到同学们的算法,也感到有所收获,老师的代码很简洁也易懂,现在还只是稍浅显的二叉树,到后面就会越来越复杂了。树的学习还有很长的路要走。
2.阅读代码
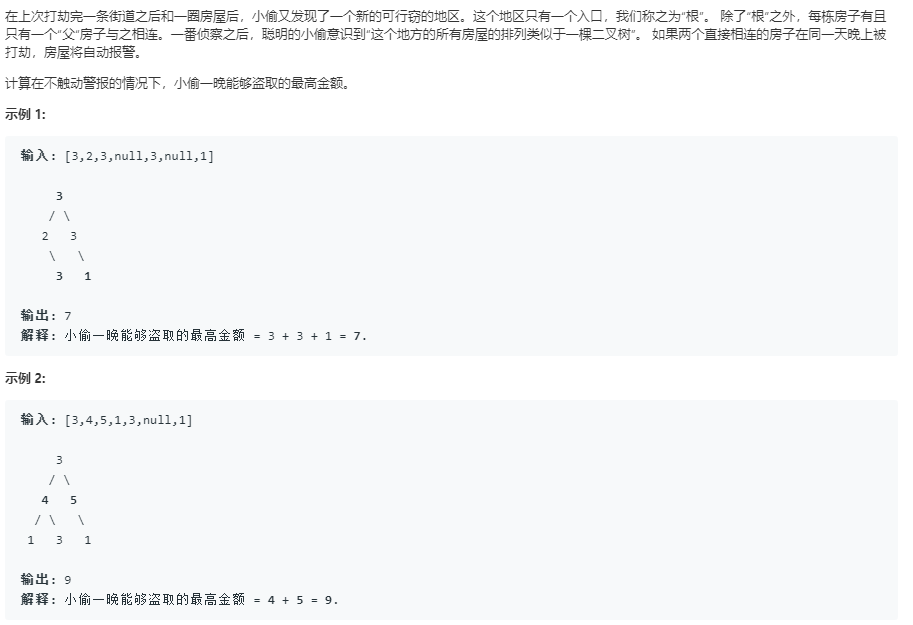
2.1题目及解析代码
- 题目
![]()
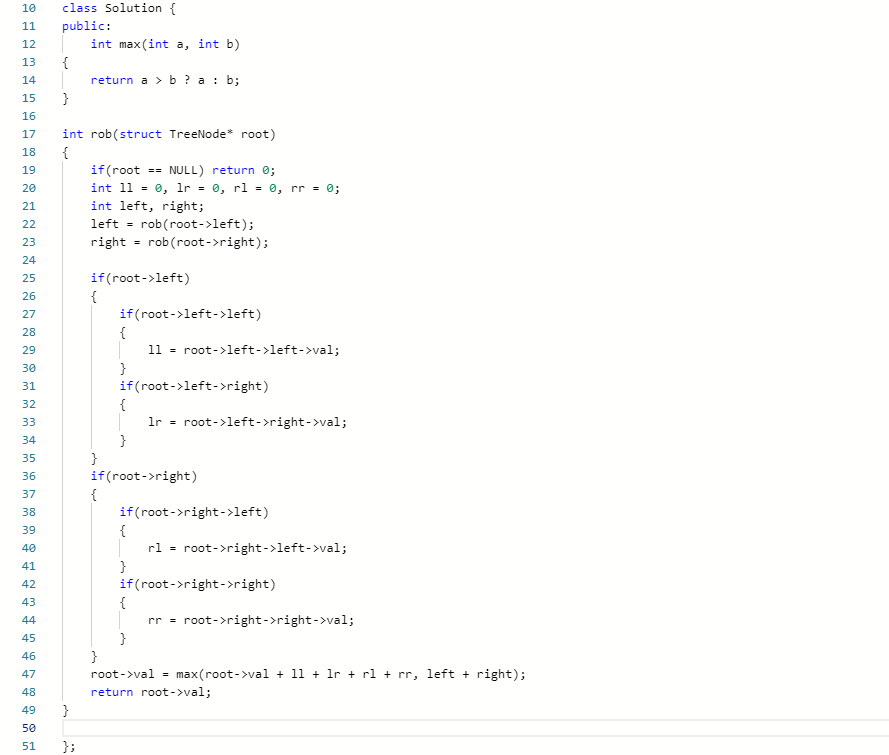
- 代码
![]()
2.1.1 该题的设计思路
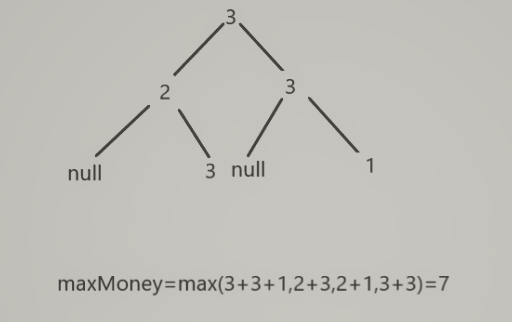
- 能盗取的最高金额为 抢劫该节点+抢劫该节点的左孩子的左右子树+抢劫该节点的右孩子的左右子树 与 抢劫该节点的左子树+抢劫该节点的右子树的和 的最大值
![]()
时间复杂度为O(n)
空间复杂度为O(n)
2.1.2该题的伪代码
int rob(struct TreeNode* root)
{
if 根结点为空 返回0
end if
递归遍历左、右子树 保存返回值left、right
if左(右)孩子不空
if左(右)孩子的左、右孩子不空 保存该节点的值ll、lr(rl、rr)
end if
end if
返回 抢劫该节点+抢劫该节点的左孩子的左右子树+抢劫该节点的右孩子的左右子树(根结点值+ll+lr+rl+rr)
与
抢劫该节点的左子树+抢劫该节点的右子树的和(left+right)
的最大值
}
2.1.3运行结果

2.1.4该题目解题优势及难点
优点:虽然解法不是最优,但对于初学者来说比较简单,明了,易懂,就是相较于递归遍历加上一些难度后的形式。
难点:有一点很容易忽略,就是第一想法都会是隔层加和就可以了,但是相邻两层之间也可能有不相邻的节点。
2.2题目及解题代码
- 题目
![]()
- 代码
![]()
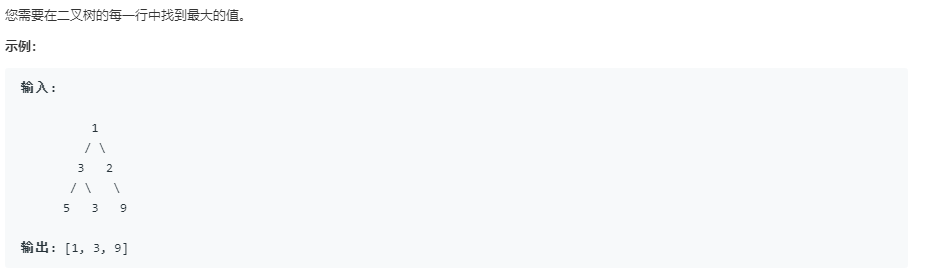

2.2.1该题的设计思路
- 运用层次遍历法,寻找到每层最大的数,依次放入vector数组中
![]()
时间复杂度为O(n²)
空间复杂度为O(n²)

2.2.2该题的伪代码
定义vector容器和结构体队列
if 根结点不空 把根结点入队
end if
while 队不空
for i=0 to 队列长度
出队一个节点,保存该节点
if 节点值>max 更新max值 end if
if 左、右节点不空 入队左、右节点 end if
end for
将最大值放入vector数组
end while
返回vector数组
2.2.3运行结果

2.2.4该题目解题优势及难点
优势:我们学过层次遍历,所以这题借助队列求值很容易可以看懂,且借助了vector容器,使代码更精简
难点:难点是方法,但我们学过了与之相关的内容,所以整体并无特别难的地方
2.3题目及解题代码
- 题目
![]()
- 代码
![]()
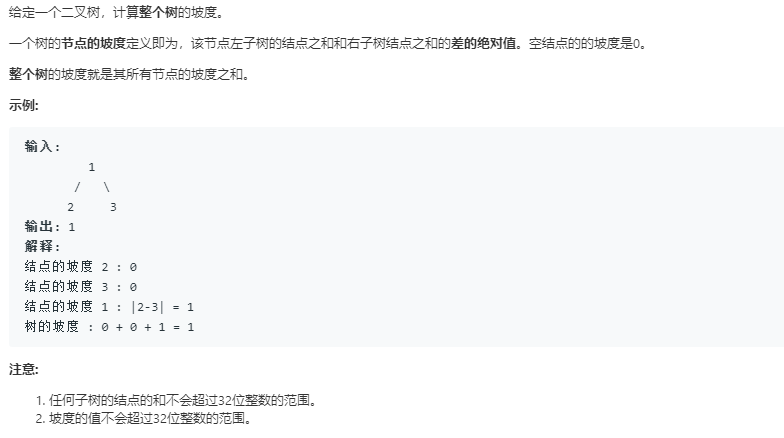

2.3.1该题的设计思路
- 递归计算相应左右子树节点值之差,即为该节点的坡度,设立全局变量累加坡度,返回左右子树与根结点的加和
![]()
时间复杂度为O(n)
空间复杂度为O(n)

2.3.2该题的伪代码
定义全局变量title
if 节点为空 返回0
end if
递归遍历左、右子树
坡度相加title+=abs(left-right)
返回左、右节点以及根结点值之和
2.3.3运行结果

2.3.4该题目解题优势及难点
优势:该题采用递归求和,设立全局变量计算坡度,我看其他算法还有传参数地址,也可以实现
难点:该题思路容易想出来,但是不容易编程实现,如果递归比较弱,不容易写出来
2.4题目及解题代码
- 题目
![]()
- 代码
![]()


2.4.1该题的设计思路
- 将复杂的着色游戏转化为节点数叠加的算法,对于玩家2的染色节点可以分为三个部分,玩家一选择的节点的左子树或右子树或除以该节点作为根结点的树之外的所有节点,节点数最多的即为玩家一可以最多染色的节点,与n/2比较,若大于,则胜出
![]()
时间复杂度为O(n)
空间复杂度为O(n)
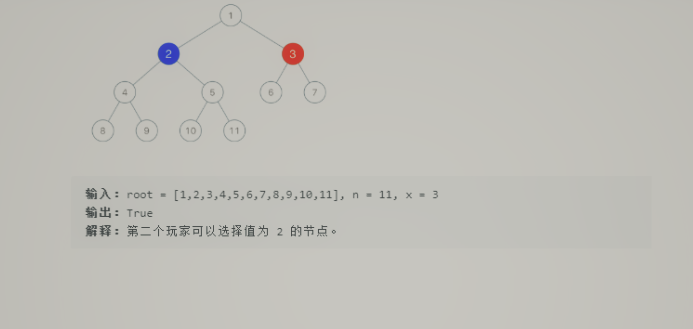
2.4.2该题的伪代码
定义全局变量max
if 根结点为空 返回0
end if
递归遍历左、右子树,记录节点数left、right
if 找到x节点
将三种选择(左子树、右子树、切掉当前子树以后剩下的全部)取最大值赋给max
end if
返回 左、右子树节点与根结点树之和(left+right+1)
2.4.3运行结果

2.4.4该题目解题优势及难点
优势:代码将复杂的问题简单化,本来无从下手的题目,变为递归算法,且相较于其他算法更加简洁,可读性好
难点:思路不好想,题目看着很复杂,刚看完会完全不知道怎么写,本题更考验思维。不能够较好地处理两个玩家的所涂色节点数之间的关系,所以处理这类题要仔细琢磨思路,然后再答题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号