TCP/IP协议栈在Linux内核中的运行时序分析
1. 网络模型
OSI模型,即开放式通信系统互联参考模型(Open System Interconnection Reference Model),是国际标准化组织(ISO)提出的一个试图使各种计算机在世界范围内互连为网络的标准框架。它提供给开发者一个必须的、通用的概念以便开发完善,可以用来解释连接不同系统的框架。
TCP/IP协议(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。与OSI模型不同,TCP/IP模型并不仅是理论上的网络标准,而是现有的事实模型,它在一定程度上参考了OSI模型,并根据当时的现存网络发展而来。
OSI模型及TCP/IP协议如下图所示:

2. Linux网络模型
Linux的协议栈其实是源于BSD的协议栈,它向上以及向下的接口以及协议栈本身的软件分层组织的非常好。
Linux的协议栈基于分层的设计思想,总共分为四层,从下往上依次是:物理层,链路层,网络层,应用层。
物理层主要提供各种连接的物理设备,如各种网卡,串口卡等;链路层主要指的是提供对物理层进行访问的各种接口卡的驱动程序,如网卡驱动等;网路层的作用是负责将网络数据包传输到正确的位置,最重要的网络层协议当然就是IP协议了,其实网络层还有其他的协议如ICMP,ARP,RARP等,只不过不像IP那样被多数人所熟悉;传输层的作用主要是提供端到端,即应用程序之间的通信;应用层,顾名思义,当然就是由应用程序提供的,用来对传输数据进行语义解释的“人机界面”层了,比如HTTP,SMTP,FTP等等,其实应用层还不是人们最终所看到的那一层,最上面的一层应该是“解释层”,负责将数据以各种不同的表项形式最终呈献到人们眼前。
Linux网络核心架构Linux的网络架构从上往下可以分为三层,分别是:用户空间的应用层,内核空间的网络协议栈层,物理硬件层。 其中最重要最核心的是内核空间的协议栈层:
Linux网络协议栈结构Linux的整个网络协议栈都构建与Linux Kernel中,整个栈也是严格按照分层的思想来设计的,整个栈共分为五层,分别是 :
(1)系统调用接口层,实质是一个面向用户空间应用程序的接口调用库,向用户空间应用程序提供使用网络服务的接口。
(2)协议无关的接口层,就是SOCKET层,这一层的目的是屏蔽底层的不同协议(更准确的来说主要是TCP与UDP,当然还包括RAW IP, SCTP等),以便与系统调用层之间的接口可以简单,统一。简单的说,不管我们应用层使用什么协议,都要通过系统调用接口来建立一个SOCKET,这个SOCKET其实是一个巨大的sock结构,它和下面一层的网络协议层联系起来,屏蔽了不同的网络协议的不同,只吧数据部分呈献给应用层(通过系统调用接口来呈献)。
(3)网络协议实现层,毫无疑问,这是整个协议栈的核心。这一层主要实现各种网络协议,最主要的当然是IP,ICMP,ARP,RARP,TCP,UDP等。这一层包含了很多设计的技巧与算法。
(4)与具体设备无关的驱动接口层,这一层的目的主要是为了统一不同的接口卡的驱动程序与网络协议层的接口,它将各种不同的驱动程序的功能统一抽象为几个特殊的动作,如open,close,init等,这一层可以屏蔽底层不同的驱动程序。
(5)驱动程序层,这一层的目的是建立与硬件的接口层。

3. socket 通信
linux中的网络编程通过socket接口实现,socket既是一种特殊的IO,也是一种文件描述符。socket是通过IP+端口号进行匹配的,匹配之后可以通过socket进行数据的发送与接收(socket本质是文件描述符fd)。具体流程(TCP)如下:
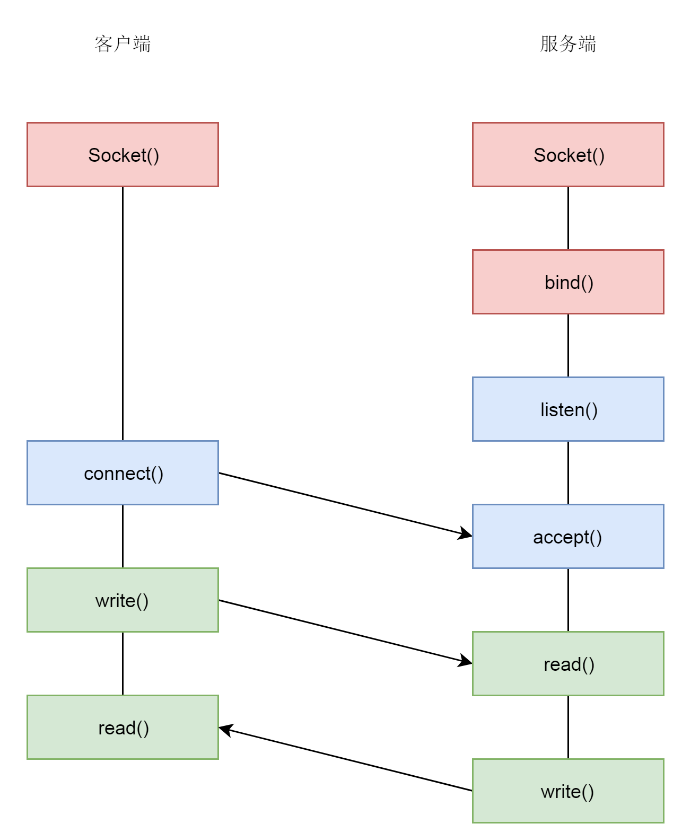
3.1 socket 创建
调用socket函数:
int socket(int domain, int type, int protocol);
socket函数用于创建一个socket的文件描述符,唯一标识一个socket,这里叫作文件描述符是因为在内核中,会创建类似文件系统的数据结构,并且后续的操作都有用到它。socket函数有三个参数:
(1)domain表示使用什么IP层协议,AF_INET表示IPv4,AF_INET6表示IPv6;
(2)type表示socket类型,SOCK_STREAM就是TCP面向流的,SOCK_DGRAM就是UDP面向数据报的,SOCK_RAW可以直接操作IP层,或者非TCP和UDP的协议,例如 ICMP;
(3)protocol表示协议,包括IPPROTO_TCP、IPPTOTO_UDP。
通信结束后,还要像关闭文件一样关闭socket。
socket系统调用:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
......
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
......
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
......
return retval;
}
Socket系统调用会调用sock_create创建一个struct socket结构,然后通过sock_map_fd和文件描述符对应起来。在创建Socket的时候有三个参数,一个是family表示地址族,不是所有的Socket都要通过IP进行通信,还有其他的通信方式,例如下面的定义中,domain sockets就是通过本地文件进行通信的,不需要IP地址,只不过通过IP地址是最常用的模式,所以这里着重分析这种模式:
#define AF_UNIX 1/* Unix domain sockets */ #define AF_INET 2/* Internet IP Protocol */
第二个参数是type即Socket的类型,类型比较少。第三个参数是protocol是协议,协议数目是比较多的,也就是说多个协议会属于同一种类型。常用的Socket类型有三种,分别是SOCK_STREAM、SOCK_DGRAM和SOCK_RAW,如下所示:
enum sock_type { SOCK_STREAM = 1, SOCK_DGRAM = 2, SOCK_RAW = 3, ...... }
SOCK_STREAM是面向数据流的,协议IPPROTO_TCP属于这种类型。SOCK_DGRAM是面向数据报的,协议IPPROTO_UDP属于这种类型。如果在内核里面看的话,IPPROTO_ICMP也属于这种类型。SOCK_RAW是原始的IP包,IPPROTO_IP属于这种类型。这里重点看SOCK_STREAM类型和IPPROTO_TCP协议。为了管理family、type、protocol这三个分类层次,内核会创建对应的数据结构。接下来打开sock_create函数看一下,它会调用__sock_create:
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; ...... sock = sock_alloc(); ...... sock->type = type; ...... pf = rcu_dereference(net_families[family]); ...... err = pf->create(net, sock, protocol, kern); ...... *res = sock; return 0; }
这里先是分配了一个struct socket结构,接下来要用到family参数,这里有一个net_families数组,可以以family参数为下标,找到对应的struct net_proto_family,如下所示:
/* Supported address families. */ #define AF_UNSPEC 0 #define AF_UNIX 1 /* Unix domain sockets */ #define AF_LOCAL 1 /* POSIX name for AF_UNIX */ #define AF_INET 2 /* Internet IP Protocol */ ...... #define AF_INET6 10 /* IP version 6 */ ...... #define AF_MPLS 28 /* MPLS */ ...... #define AF_MAX 44 /* For now.. */ #define NPROTO AF_MAX struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
这里可以找到net_families的定义,每一个地址族在这个数组里面都有一项,里面的内容是net_proto_family。每一种地址族都有自己的net_proto_family,IP地址族的net_proto_family定义如下,里面最重要的就是create函数指向 inet_create:
//net/ipv4/af_inet.c static const struct net_proto_family inet_family_ops = { .family = PF_INET, .create = inet_create,//这个用于socket系统调用创建 ...... }
回到函数__sock_create,接下来在这里面,这个inet_create会被调用,如下所示:
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern) { struct sock *sk; struct inet_protosw *answer; struct inet_sock *inet; struct proto *answer_prot; unsigned char answer_flags; int try_loading_module = 0; int err; /* Look for the requested type/protocol pair. */ lookup_protocol: list_for_each_entry_rcu(answer, &inetsw[sock->type], list) { err = 0; /* Check the non-wild match. */ if (protocol == answer->protocol) { if (protocol != IPPROTO_IP) break; } else { /* Check for the two wild cases. */ if (IPPROTO_IP == protocol) { protocol = answer->protocol; break; } if (IPPROTO_IP == answer->protocol) break; } err = -EPROTONOSUPPORT; } ...... sock->ops = answer->ops; answer_prot = answer->prot; answer_flags = answer->flags; ...... sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern); ...... inet = inet_sk(sk); inet->nodefrag = 0; if (SOCK_RAW == sock->type) { inet->inet_num = protocol; if (IPPROTO_RAW == protocol) inet->hdrincl = 1; } inet->inet_id = 0; sock_init_data(sock, sk); sk->sk_destruct = inet_sock_destruct; sk->sk_protocol = protocol; sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv; inet->uc_ttl = -1; inet->mc_loop = 1; inet->mc_ttl = 1; inet->mc_all = 1; inet->mc_index = 0; inet->mc_list = NULL; inet->rcv_tos = 0; if (inet->inet_num) { inet->inet_sport = htons(inet->inet_num); /* Add to protocol hash chains. */ err = sk->sk_prot->hash(sk); } if (sk->sk_prot->init) { err = sk->sk_prot->init(sk); } ...... }
在inet_create中,先会看到一个循环list_for_each_entry_rcu,在这里第二个参数type开始起作用,因为循环查看的是inetsw[sock->type],这里的inetsw也是一个数组,type作为下标,里面的内容是struct inet_protosw是协议,即inetsw数组对于每个类型有一项,这一项里面是属于这个类型的协议,如下所示:
static struct list_head inetsw[SOCK_MAX]; static int __init inet_init(void) { ...... /* Register the socket-side information for inet_create. */ for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r) INIT_LIST_HEAD(r); for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q) inet_register_protosw(q); ...... }
inetsw数组是在系统初始化的时候初始化的,就像上面代码里面实现的一样。首先,一个循环会将inetsw数组的每一项都初始化为一个链表。前面说了一个type类型会包含多个protocol,因而需要一个链表。接下来一个循环,是将inetsw_array注册到inetsw数组里面去,inetsw_array的定义如下,这个数组里面的内容很重要,后面会用到它们:
static struct inet_protosw inetsw_array[] = { { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &inet_stream_ops, .flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_UDP, .prot = &udp_prot, .ops = &inet_dgram_ops, .flags = INET_PROTOSW_PERMANENT, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_ICMP, .prot = &ping_prot, .ops = &inet_sockraw_ops, .flags = INET_PROTOSW_REUSE, }, { .type = SOCK_RAW, .protocol = IPPROTO_IP, /* wild card */ .prot = &raw_prot, .ops = &inet_sockraw_ops, .flags = INET_PROTOSW_REUSE, } }
回到inet_create的list_for_each_entry_rcu循环中,到这里就好理解了,这是在inetsw数组中,根据type找到属于这个类型的列表,然后依次比较列表中的struct inet_protosw的protocol是不是用户指定的protocol;如果是就得到了符合用户指定的family->type->protocol中三项的struct inet_protosw *answer对象。
接下来struct socket *sock的ops成员变量,被赋值为answer的ops,对于TCP来讲就是inet_stream_ops。后面任何用户对于这个socket的操作,都是通过 inet_stream_ops 进行的。接下来,我们创建一个 struct sock *sk 对象。这里比较让人困惑。socket 和 sock 看起来几乎一样,容易让人混淆,这里需要说明一下,socket 是用于负责对上给用户提供接口,并且和文件系统关联。而 sock,负责向下对接内核网络协议栈。
在sk_alloc函数中,struct inet_protosw *answer结构的tcp_prot赋值给了struct sock *sk的sk_prot成员。tcp_prot的定义如下,里面定义了很多的函数,都是sock之下内核协议栈的动作:
struct proto tcp_prot = { .name = "TCP", .owner = THIS_MODULE, .close = tcp_close, .connect = tcp_v4_connect, .disconnect = tcp_disconnect, .accept = inet_csk_accept, .ioctl = tcp_ioctl, .init = tcp_v4_init_sock, .destroy = tcp_v4_destroy_sock, .shutdown = tcp_shutdown, .setsockopt = tcp_setsockopt, .getsockopt = tcp_getsockopt, .keepalive = tcp_set_keepalive, .recvmsg = tcp_recvmsg, .sendmsg = tcp_sendmsg, .sendpage = tcp_sendpage, .backlog_rcv = tcp_v4_do_rcv, .release_cb = tcp_release_cb, .hash = inet_hash, .get_port = inet_csk_get_port, ...... }
在inet_create函数中,接下来创建一个struct inet_sock结构,这个结构一开始就是struct sock,然后扩展了一些其他的信息,剩下的代码就填充这些信息,这一幕会经常看到,将一个结构放在另一个结构的开始位置,然后扩展一些成员,通过对于指针的强制类型转换,来访问这些成员。socket的创建至此结束。
3.2 bind 函数
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address); if (err >= 0) { err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen); } fput_light(sock->file, fput_needed); } return err; }
在bind中,sockfd_lookup_light会根据fd文件描述符找到struct socket结构。然后将sockaddr从用户态拷贝到内核态,然后调用struct socket结构里面ops的bind函数。根据前面创建socket时候的设定,调用的是inet_stream_ops 的bind函数,也即调用inet_bind,如下所示:
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *addr = (struct sockaddr_in *)uaddr; struct sock *sk = sock->sk; struct inet_sock *inet = inet_sk(sk); struct net *net = sock_net(sk); unsigned short snum; ...... snum = ntohs(addr->sin_port); ...... inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr; /* Make sure we are allowed to bind here. */ if ((snum || !inet->bind_address_no_port) && sk->sk_prot->get_port(sk, snum)) { ...... } inet->inet_sport = htons(inet->inet_num); inet->inet_daddr = 0; inet->inet_dport = 0; sk_dst_reset(sk); }
bind里面会调用sk_prot的get_port函数,即inet_csk_get_port来检查端口是否冲突,是否可以绑定。如果允许则会设置struct inet_sock的本方地址inet_saddr和本方端口inet_sport,对方地址inet_daddr和对方端口inet_dport都初始化为0。bind的逻辑相对比较简单,就到这里了。
3.3 listen 函数
SYSCALL_DEFINE2(listen, int, fd, int, backlog) { struct socket *sock; int err, fput_needed; int somaxconn; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn; if ((unsigned int)backlog > somaxconn) backlog = somaxconn; err = sock->ops->listen(sock, backlog); fput_light(sock->file, fput_needed); } return err; }
在listen中还是通过sockfd_lookup_light根据fd文件描述符,找到struct socket结构。接着调用struct socket结构里ops的listen函数。根据前面创建socket时的设定,调用的是inet_stream_ops的listen函数,即调用inet_listen,如下所示:
int inet_listen(struct socket *sock, int backlog) { struct sock *sk = sock->sk; unsigned char old_state; int err; old_state = sk->sk_state; /* Really, if the socket is already in listen state * we can only allow the backlog to be adjusted. */ if (old_state != TCP_LISTEN) { err = inet_csk_listen_start(sk, backlog); } sk->sk_max_ack_backlog = backlog; }
如果这个socket还不在TCP_LISTEN状态,会调用inet_csk_listen_start进入监听状态,如下所示:
int inet_csk_listen_start(struct sock *sk, int backlog) { struct inet_connection_sock *icsk = inet_csk(sk); struct inet_sock *inet = inet_sk(sk); int err = -EADDRINUSE; reqsk_queue_alloc(&icsk->icsk_accept_queue); sk->sk_max_ack_backlog = backlog; sk->sk_ack_backlog = 0; inet_csk_delack_init(sk); sk_state_store(sk, TCP_LISTEN); if (!sk->sk_prot->get_port(sk, inet->inet_num)) { ...... } ...... }
这里面建立了一个新的结构 inet_connection_sock,这个结构一开始是struct inet_sock,inet_csk其实做了一次强制类型转换扩大了结构,这里又是这个层层套嵌的套路。struct inet_connection_sock结构比较复杂,如果打开它能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼,TCP是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。这里先不详细分析里面的变量,因为太多了,后面遇到一个分析一个。
首先遇到的是icsk_accept_queue,它是干什么的呢?在TCP的状态里面有一个listen状态,当调用listen函数之后就会进入这个状态,虽然写程序的时候,一般要等待服务端调用accept后,等待在那的时候让客户端发起连接。其实服务端一旦处于listen状态不用accept,客户端也能发起连接。
其实TCP的状态中,没有一个是否被accept的状态,那accept函数的作用是什么呢?在内核中为每个Socket维护两个队列,一个是已经建立了连接的队列,这时候连接三次握手已经完毕处于established状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成处于syn_rcvd的状态,服务端调用accept函数,其实是在established队列中拿出一个已经完成的连接进行处理,如果还没有完成就阻塞等待。上面代码的icsk_accept_queue就是第一个队列。
初始化完之后,将TCP的状态设置为TCP_LISTEN,再次调用get_port判断端口是否冲突。至此listen的逻辑就结束了。
3.4 accept 函数
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen) { return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0); } SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen, int, flags) { struct socket *sock, *newsock; struct file *newfile; int err, len, newfd, fput_needed; struct sockaddr_storage address; ...... sock = sockfd_lookup_light(fd, &err, &fput_needed); newsock = sock_alloc(); newsock->type = sock->type; newsock->ops = sock->ops; newfd = get_unused_fd_flags(flags); newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name); err = sock->ops->accept(sock, newsock, sock->file->f_flags, false); if (upeer_sockaddr) { if (newsock->ops->getname(newsock, (struct sockaddr *)&address, &len, 2) < 0) { } err = move_addr_to_user(&address, len, upeer_sockaddr, upeer_addrlen); } fd_install(newfd, newfile); ...... }
accept函数的实现印证了socket原理中说的那样,原来的socket是监听socket,这里会找到原来的struct socket,并基于它去创建一个新的newsock,这才是连接socket。除此之外还会创建一个新的struct file和fd,并关联到socket,这里面还会调用struct socket的sock->ops->accept,即会调用inet_stream_ops的accept函数,也就是inet_accept,如下所示:
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern) { struct sock *sk1 = sock->sk; int err = -EINVAL; struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern); sock_rps_record_flow(sk2); sock_graft(sk2, newsock); newsock->state = SS_CONNECTED; }
inet_accept会调用struct sock的sk1->sk_prot->accept,即tcp_prot的accept函数,就是inet_csk_accept函数,如下所示:
/* * This will accept the next outstanding connection. */ struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) { struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock_queue *queue = &icsk->icsk_accept_queue; struct request_sock *req; struct sock *newsk; int error; if (sk->sk_state != TCP_LISTEN) goto out_err; /* Find already established connection */ if (reqsk_queue_empty(queue)) { long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); error = inet_csk_wait_for_connect(sk, timeo); } req = reqsk_queue_remove(queue, sk); newsk = req->sk; ...... } /* * Wait for an incoming connection, avoid race conditions. This must be called * with the socket locked. */ static int inet_csk_wait_for_connect(struct sock *sk, long timeo) { struct inet_connection_sock *icsk = inet_csk(sk); DEFINE_WAIT(wait); int err; for (;;) { prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE); release_sock(sk); if (reqsk_queue_empty(&icsk->icsk_accept_queue)) timeo = schedule_timeout(timeo); sched_annotate_sleep(); lock_sock(sk); err = 0; if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) break; err = -EINVAL; if (sk->sk_state != TCP_LISTEN) break; err = sock_intr_errno(timeo); if (signal_pending(current)) break; err = -EAGAIN; if (!timeo) break; } finish_wait(sk_sleep(sk), &wait); return err; }
inet_csk_accept的实现印证了上面讲的两个队列的逻辑。如果icsk_accept_queue为空,则调用inet_csk_wait_for_connect进行等待;等待的时候调用schedule_timeout让出CPU,并且将进程状态设置为TASK_INTERRUPTIBLE即可被信号量打断。如果再次CPU醒来会接着判断icsk_accept_queue是否为空,同时也会调用signal_pending看有没有信号可以处理,一旦icsk_accept_queue不为空,就从inet_csk_wait_for_connect中返回,在队列中取出一个struct sock对象赋值给newsk。
3.5 三次握手
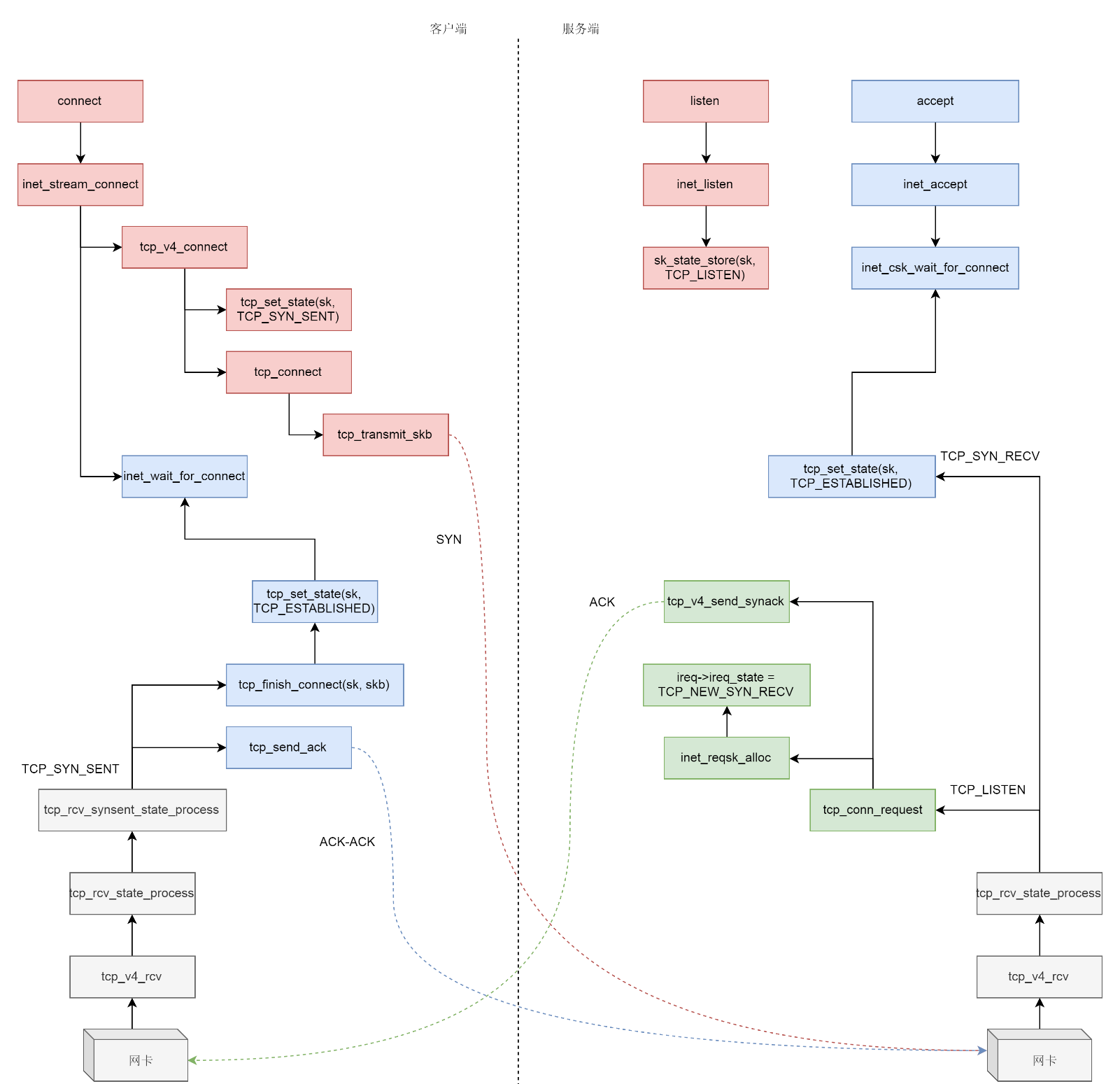
三次握手一般是由客户端调用connect发起,如下所示:
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, int, addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); err = move_addr_to_kernel(uservaddr, addrlen, &address); err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags); }
connect函数的实现还是通过sockfd_lookup_light根据fd文件描述符,找到struct socket结构。接着会调用struct socket结构里面ops的connect函数,根据前面创建socket时的设定,调用inet_stream_ops的connect函数,即调用inet_stream_connect,如下所示:
/* * Connect to a remote host. There is regrettably still a little * TCP 'magic' in here. */ int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags, int is_sendmsg) { struct sock *sk = sock->sk; int err; long timeo; switch (sock->state) { ...... case SS_UNCONNECTED: err = -EISCONN; if (sk->sk_state != TCP_CLOSE) goto out; err = sk->sk_prot->connect(sk, uaddr, addr_len); sock->state = SS_CONNECTING; break; } timeo = sock_sndtimeo(sk, flags & O_NONBLOCK); if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { ...... if (!timeo || !inet_wait_for_connect(sk, timeo, writebias)) goto out; err = sock_intr_errno(timeo); if (signal_pending(current)) goto out; } sock->state = SS_CONNECTED; }
在__inet_stream_connect里面,如果socket处于SS_UNCONNECTED状态,那就调用struct sock的sk->sk_prot->connect,即tcp_prot的connect函数——tcp_v4_connect函数进行连接,如下所示:
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; struct inet_sock *inet = inet_sk(sk); struct tcp_sock *tp = tcp_sk(sk); __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4; struct rtable *rt; ...... orig_sport = inet->inet_sport; orig_dport = usin->sin_port; rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); ...... tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(tcp_death_row, sk); sk_set_txhash(sk); rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); /* OK, now commit destination to socket. */ sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); if (likely(!tp->repair)) { if (!tp->write_seq) tp->write_seq = secure_tcp_seq(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port); tp->tsoffset = secure_tcp_ts_off(sock_net(sk), inet->inet_saddr, inet->inet_daddr); } rt = NULL; ...... err = tcp_connect(sk); ...... }
在tcp_v4_connect函数中,ip_route_connect其实是做一个路由的选择,因为三次握手马上就要发送一个SYN包了,这就要凑齐源地址、源端口、目标地址、目标端口。目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的IP地址。接下来在发送SYN之前,先将客户端socket的状态设置为TCP_SYN_SENT。然后初始化TCP的seq num即write_seq,然后调用tcp_connect进行发送,如下所示:
/* Build a SYN and send it off. */ int tcp_connect(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *buff; int err; ...... tcp_connect_init(sk); ...... buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true); ...... tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); tcp_mstamp_refresh(tp); tp->retrans_stamp = tcp_time_stamp(tp); tcp_connect_queue_skb(sk, buff); tcp_ecn_send_syn(sk, buff); /* Send off SYN; include data in Fast Open. */ err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); ...... tp->snd_nxt = tp->write_seq; tp->pushed_seq = tp->write_seq; buff = tcp_send_head(sk); if (unlikely(buff)) { tp->snd_nxt = TCP_SKB_CB(buff)->seq; tp->pushed_seq = TCP_SKB_CB(buff)->seq; } ...... /* Timer for repeating the SYN until an answer. */ inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX); return 0; }
在tcp_connect中有一个新的结构struct tcp_sock,如果打开它,会发现它是struct inet_connection_sock的一个扩展,struct inet_connection_sock在struct tcp_sock开头的位置,通过强制类型转换访问,扩展套嵌故伎重演。struct tcp_sock里面维护了更多的TCP的状态,后面遇到了再分析。接下来tcp_init_nondata_skb初始化一个SYN包,tcp_transmit_skb将SYN包发送出去,inet_csk_reset_xmit_timer设置了一个timer,如果SYN发送不成功则再次发送。发送网络包的过程放到后面再说。这里暂且认为SYN已经发送出去了。
回到__inet_stream_connect函数,在调用sk->sk_prot->connect之后,inet_wait_for_connect会一直等待客户端收到服务端的ACK。而服务端在accept之后也是在等待中。网络包是如何接收的呢?对于接收的详细过程后面会讲解,这里为了解析三次握手,先简单的看网络包接收到TCP层做的部分事情,如下所示:
static struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .early_demux_handler = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, .icmp_strict_tag_validation = 1, }
通过struct net_protocol结构中的handler进行接收,调用的函数是tcp_v4_rcv,接下来的调用链为tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process。tcp_rcv_state_process顾名思义是用来处理接收一个网络包后引起状态变化的,如下所示:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { ...... case TCP_LISTEN: ...... if (th->syn) { acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; if (!acceptable) return 1; consume_skb(skb); return 0; } ...... }
目前服务端是处于TCP_LISTEN状态的,而且发过来的包是SYN,因而就有了上面的代码,调用icsk->icsk_af_ops->conn_request函数。struct inet_connection_sock对应的操作是inet_connection_sock_af_ops,按照下面的定义其实调用的是tcp_v4_conn_request:
const struct inet_connection_sock_af_ops ipv4_specific = { .queue_xmit = ip_queue_xmit, .send_check = tcp_v4_send_check, .rebuild_header = inet_sk_rebuild_header, .sk_rx_dst_set = inet_sk_rx_dst_set, .conn_request = tcp_v4_conn_request, .syn_recv_sock = tcp_v4_syn_recv_sock, .net_header_len = sizeof(struct iphdr), .setsockopt = ip_setsockopt, .getsockopt = ip_getsockopt, .addr2sockaddr = inet_csk_addr2sockaddr, .sockaddr_len = sizeof(struct sockaddr_in), .mtu_reduced = tcp_v4_mtu_reduced, };
tcp_v4_conn_request会调用tcp_conn_request,这个函数也比较长里面调用了send_synack,但实际调用的是tcp_v4_send_synack。具体发送的过程不去管它,看注释能知道这是收到了SYN后回复一个SYN-ACK,回复完毕后服务端处于TCP_SYN_RECV,如下所示:
int tcp_conn_request(struct request_sock_ops *rsk_ops, const struct tcp_request_sock_ops *af_ops, struct sock *sk, struct sk_buff *skb) { ...... af_ops->send_synack(sk, dst, &fl, req, &foc, !want_cookie ? TCP_SYNACK_NORMAL : TCP_SYNACK_COOKIE); ...... } /* * Send a SYN-ACK after having received a SYN. */ static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst, struct flowi *fl, struct request_sock *req, struct tcp_fastopen_cookie *foc, enum tcp_synack_type synack_type) {......}
这个时候轮到客户端接收网络包了。都是TCP协议栈,所以过程和服务端没有太多区别,还是会走到tcp_rcv_state_process函数的,只不过由于客户端目前处于TCP_SYN_SENT状态,就进入了下面的代码分支:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { ...... case TCP_SYN_SENT: tp->rx_opt.saw_tstamp = 0; tcp_mstamp_refresh(tp); queued = tcp_rcv_synsent_state_process(sk, skb, th); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } ...... }
tcp_rcv_synsent_state_process会调用tcp_send_ack发送一个ACK-ACK,发送后客户端处于TCP_ESTABLISHED状态。又轮到服务端接收网络包了,还是归tcp_rcv_state_process函数处理。由于服务端目前处于状态TCP_SYN_RECV状态,因而又走了另外的分支。当收到这个网络包的时候,服务端也处于TCP_ESTABLISHED状态,三次握手结束,如下所示:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; ...... switch (sk->sk_state) { case TCP_SYN_RECV: if (req) { inet_csk(sk)->icsk_retransmits = 0; reqsk_fastopen_remove(sk, req, false); } else { /* Make sure socket is routed, for correct metrics. */ icsk->icsk_af_ops->rebuild_header(sk); tcp_call_bpf(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB); tcp_init_congestion_control(sk); tcp_mtup_init(sk); tp->copied_seq = tp->rcv_nxt; tcp_init_buffer_space(sk); } smp_mb(); tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); break; ...... }
4. send 过程
数据包发送过程如下:
4.1 VFS层
write系统调用找到struct file,根据里面file_operations的定义调用sock_write_iter函数,sock_write_iter 函数调用sock_sendmsg函数。
socket对于用户来讲是一个文件一样的存在,拥有一个文件描述符。因而对于网络包的发送,可以使用对于socket文件的写入系统调用,也就是write系统调用。write系统调用对于一个文件描述符的操作,大致过程都是类似的。对于每一个打开的文件都有一struct file 结构,write系统调用会最终调用stuct file结构指向的file_operations操作。对于socket来讲,它的file_operations定义如下:
static const struct file_operations socket_file_ops = { .owner = THIS_MODULE, .llseek = no_llseek, .read_iter = sock_read_iter, .write_iter = sock_write_iter, .poll = sock_poll, .unlocked_ioctl = sock_ioctl, .mmap = sock_mmap, .release = sock_close, .fasync = sock_fasync, .sendpage = sock_sendpage, .splice_write = generic_splice_sendpage, .splice_read = sock_splice_read, };
按照文件系统的写入流程,调用的是sock_write_iter,如下所示:
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from) { struct file *file = iocb->ki_filp; struct socket *sock = file->private_data; struct msghdr msg = {.msg_iter = *from, .msg_iocb = iocb}; ssize_t res; ...... res = sock_sendmsg(sock, &msg); *from = msg.msg_iter; return res; }
在sock_write_iter中通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock_sendmsg,而sock_sendmsg会调用sock_sendmsg_nosec,如下所示:
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg) { int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg)); ...... }
4.2 Socket层
从struct file里面的private_data得到struct socket,根据里面ops的定义调用inet_sendmsg函数。
sock_sendmsg_nosec 调用了socket的ops的sendmsg,其实就是inet_stream_ops,根据它的定义这里调用的是inet_sendmsg,如下所示:
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size) { struct sock *sk = sock->sk; ...... return sk->sk_prot->sendmsg(sk, msg, size); }
4.3 Sock层
从struct socket里面的sk得到struct sock,根据里面sk_prot的定义调用tcp_sendmsg函数。
4.4 TCP层
tcp_sendmsg函数会调用tcp_write_xmit函数,tcp_write_xmit函数会调用tcp_transmit_skb,在这里实现了TCP层面向连接的逻辑。
tcp_sendmsg函数:
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; long timeo; ...... /* Ok commence sending. */ copied = 0; restart: mss_now = tcp_send_mss(sk, &size_goal, flags); while (msg_data_left(msg)) { int copy = 0; int max = size_goal; skb = tcp_write_queue_tail(sk); if (tcp_send_head(sk)) { if (skb->ip_summed == CHECKSUM_NONE) max = mss_now; copy = max - skb->len; } if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb; new_segment: /* Allocate new segment. If the interface is SG, * allocate skb fitting to single page. */ if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf; ...... first_skb = skb_queue_empty(&sk->sk_write_queue); skb = sk_stream_alloc_skb(sk, select_size(sk, sg, first_skb), sk->sk_allocation, first_skb); ...... skb_entail(sk, skb); copy = size_goal; max = size_goal; ...... } /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg); /* Where to copy to? */ if (skb_availroom(skb) > 0) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); ...... } else { bool merge = true; int i = skb_shinfo(skb)->nr_frags; struct page_frag *pfrag = sk_page_frag(sk); ...... copy = min_t(int, copy, pfrag->size - pfrag->offset); ...... err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, pfrag->page, pfrag->offset, copy); ...... pfrag->offset += copy; } ...... tp->write_seq += copy; TCP_SKB_CB(skb)->end_seq += copy; tcp_skb_pcount_set(skb, 0); copied += copy; if (!msg_data_left(msg)) { if (unlikely(flags & MSG_EOR)) TCP_SKB_CB(skb)->eor = 1; goto out; } if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair)) continue; if (forced_push(tp)) { tcp_mark_push(tp, skb); __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk)) tcp_push_one(sk, mss_now); continue; ...... } ...... }
tcp_sendmsg的实现还是很复杂的,这里面做了这样几件事情。msg是用户要写入的数据,这个数据要拷贝到内核协议栈里面去发送;在内核协议栈里面,网络包的数据都是由struct sk_buff维护的,因而第一件事情就是找到一个空闲的内存空间,将用户要写入的数据拷贝到struct sk_buff的管辖范围内。而第二件事情就是发送struct sk_buff。在tcp_sendmsg中首先通过强制类型转换,将sock结构转换为struct tcp_sock,这个是维护TCP连接状态的重要数据结构。
接下来是tcp_sendmsg的第一件事情,把数据拷贝到struct sk_buff。先声明一个变量copied初始化为0,这表示拷贝了多少数据,紧接着是一个循环,while (msg_data_left(msg))即如果用户的数据没有发送完毕,就一直循环。循环里声明了一个copy变量,表示这次拷贝的数值,在循环的最后有copied += copy,将每次拷贝的数量都加起来,这里只需要看一次循环做了哪些事情:
第一步,tcp_write_queue_tail从TCP写入队列sk_write_queue中拿出最后一个struct sk_buff,在这个写入队列中排满了要发送的 struct sk_buff,为什么要拿最后一个呢?这里面只有最后一个,可能会因为上次用户给的数据太少,而没有填满。
第二步,tcp_send_mss会计算MSS即Max Segment Size。这个意思是说,在网络上传输的网络包的大小是有限制的,而这个限制在最底层开始就有。MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义,以以太网为例MTU为1500个Byte,前面有6个Byte的目标MAC地址,6个Byt的源 MAC地址,2个Byte的类型,后面有4个Byte的CRC校验,共1518个Byte。在IP层,一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输。
在 TCP 层有个MSS,等于MTU 减去IP头,再减去TCP头,也就是在不分片的情况下,TCP里面放的最大内容。在这里max是struct sk_buff的最大数据长度,skb->len是当前已经占用的skb的数据长度,相减得到当前skb的剩余数据空间。
第三步,如果copy小于0,说明最后一个struct sk_buff已经没地方存放了,需要调用sk_stream_alloc_skb重新分配struct sk_buff,然后调用skb_entail,将新分配的sk_buf放到队列尾部。struct sk_buff 是存储网络包的重要数据结构,在应用层数据包叫data,在TCP层称为segment,在IP层叫packet,在数据链路层称为frame。在struct sk_buff,首先是一个链表将struct sk_buff结构串起来。
接下来从headers_start开始,到headers_end结束,里面都是各层次的头的位置。这里面有二层的mac_header、三层的network_header和四层的transport_header。sk_buff的实现如下所示:
struct sk_buff { union { struct { /* These two members must be first. */ struct sk_buff *next; struct sk_buff *prev; ...... }; struct rb_node rbnode; /* used in netem & tcp stack */ }; ...... /* private: */ __u32 headers_start[0]; /* public: */ ...... __u32 priority; int skb_iif; __u32 hash; __be16 vlan_proto; __u16 vlan_tci; ...... union { __u32 mark; __u32 reserved_tailroom; }; union { __be16 inner_protocol; __u8 inner_ipproto; }; __u16 inner_transport_header; __u16 inner_network_header; __u16 inner_mac_header; __be16 protocol; __u16 transport_header; __u16 network_header; __u16 mac_header; /* private: */ __u32 headers_end[0]; /* public: */ /* These elements must be at the end, see alloc_skb() for details. */ sk_buff_data_t tail; sk_buff_data_t end; unsigned char *head, *data; unsigned int truesize; refcount_t users; };
最后几项, head指向分配的内存块起始地址,data这个指针指向的位置是可变的,它有可能随着报文所处的层次而变动。当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加skb->data的值,来逐步剥离协议首部。而要发送报文时,各协议会创建sk_buff{},在经过各下层协议时,通过减少skb->data的值来增加协议首部。tail指向数据的结尾,end指向分配的内存块的结束地址。要分配这样一个结构,sk_stream_alloc_skb会最终调用到__alloc_skb,在这个函数里面除了分配一个sk_buff结构之外,还要分配sk_buff指向的数据区域,这段数据区域分为下面这几个部分:
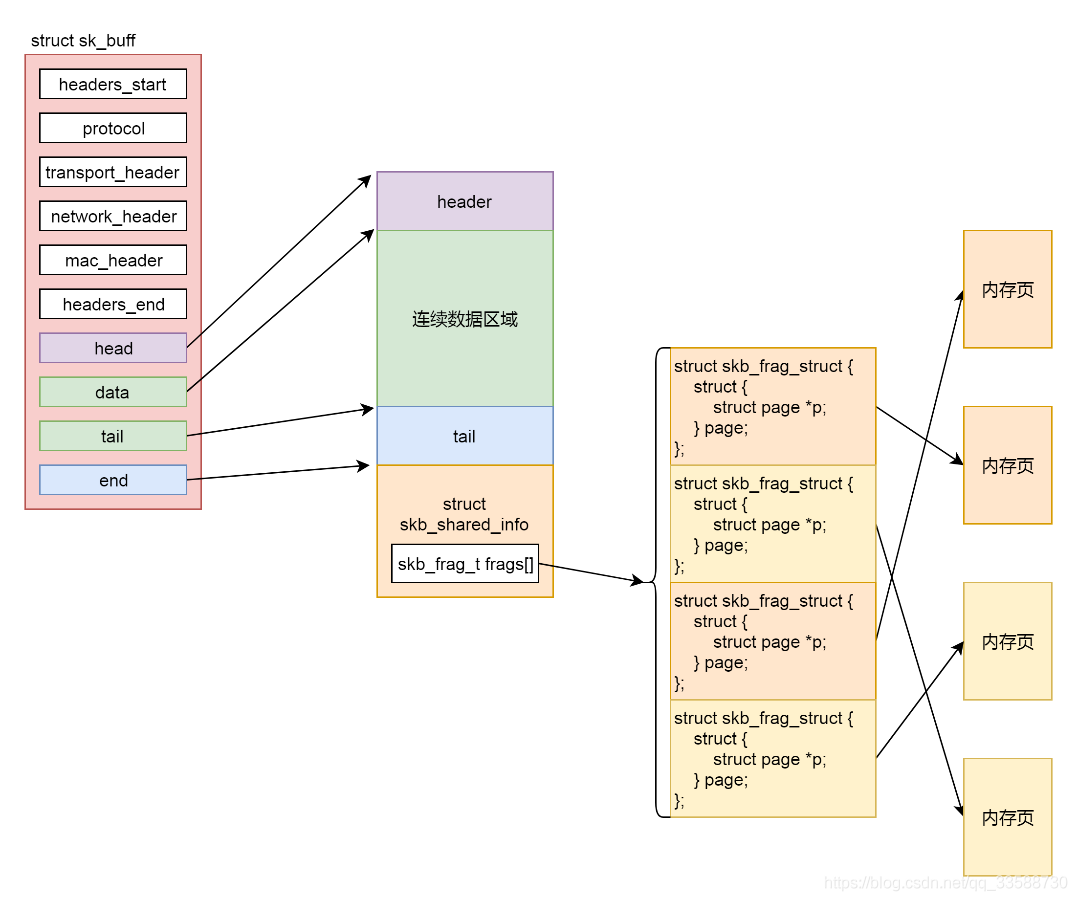
第一部分是连续的数据区域,紧接着是第二部分,即一个struct skb_shared_info结构,这个结构是对于网络包发送过程的一个优化,因为传输层之上就是应用层了。按照TCP的定义,应用层感受不到下面网络层的IP包是一个个独立包的存在的,反正就是一个流往里写就是了,可能一下子写多了超过了一个IP包的承载能力,就会出现上面MSS的定义,拆分成一个个的Segment放在一个个的IP包里面,也可能一次写一点,这样数据是分散的,在IP层还要通过内存拷贝合成一个IP包。
为了减少内存拷贝的代价,有的网络设备支持分散聚合(Scatter/Gather)I/O,顾名思义就是IP层没必要通过内存拷贝进行聚合,让散的数据零散的放在原处,在设备层进行聚合。如果使用这种模式,网络包的数据就不会放在连续的数据区域,而是放在struct skb_shared_info结构里面指向的离散数据,skb_shared_info的成员变量skb_frag_t frags[MAX_SKB_FRAGS]会指向一个数组的页面,就不能保证连续了。
于是就有了第四步。在注释 /* Where to copy to? */ 后面有个if-else分支,if分支就是skb_add_data_nocache将数据拷贝到连续的数据区域,else分支就是skb_copy_to_page_nocache将数据拷贝到struct skb_shared_info结构指向的不需要连续的页面区域。
第五步,就是要发送网络包了。第一种情况是积累的数据报数目太多了,因而需要通过调用__tcp_push_pending_frames发送网络包。第二种情况是这是第一个网络包,需要马上发送,调用tcp_push_one。无论__tcp_push_pending_frames还是tcp_push_one,都会调用tcp_write_xmit发送网络包。至此,tcp_sendmsg解析完了。
接下来看,tcp_write_xmit是如何发送网络包的,如下所示:
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; unsigned int tso_segs, sent_pkts; int cwnd_quota; ...... max_segs = tcp_tso_segs(sk, mss_now); while ((skb = tcp_send_head(sk))) { unsigned int limit; ...... tso_segs = tcp_init_tso_segs(skb, mss_now); ...... cwnd_quota = tcp_cwnd_test(tp, skb); ...... if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { is_rwnd_limited = true; break; } ...... limit = mss_now; if (tso_segs > 1 && !tcp_urg_mode(tp)) limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle); if (skb->len > limit && unlikely(tso_fragment(sk, skb, limit, mss_now, gfp))) break; ...... if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) break; repair: /* Advance the send_head. This one is sent out. * This call will increment packets_out. */ tcp_event_new_data_sent(sk, skb); tcp_minshall_update(tp, mss_now, skb); sent_pkts += tcp_skb_pcount(skb); if (push_one) break; } ...... }
这里面主要的逻辑是一个循环,用来处理发送队列,只要队列不空就会发送。在一个循环中,涉及TCP层的很多传输算法,来一一解析。第一个概念是TSO(TCP Segmentation Offload),如果发送的网络包非常大,就像上面说的一样要进行分段。分段这个事情可以由协议栈代码在内核做,但是缺点是比较费CPU,另一种方式是延迟到硬件网卡去做,需要网卡支持对大数据包进行自动分段,可以降低CPU负载。
在代码中,tcp_init_tso_segs会调用tcp_set_skb_tso_segs。这里面有这样的语句:DIV_ROUND_UP(skb->len, mss_now),也就是sk_buff的长度除以mss_now,应该分成几个段。如果算出来要分成多个段,接下来就是要看是在协议栈的代码里面分好,还是等待到了底层网卡再分,于是调用函数tcp_mss_split_point开始计算切分的limit,这里面会计算max_len = mss_now * max_segs,根据现在不切分来计算limit,所以下一步的判断中,大部分情况下tso_fragment不会被调用,等待到了底层网卡来切分。
第二个概念是拥塞窗口(cwnd,congestion window),也就是说为了避免拼命发包把网络塞满了,定义一个窗口的概念,在这个窗口之内的才能发送,超过这个窗口的就不能发送,来控制发送的频率。那窗口大小是多少呢?就是遵循下面这个著名的拥塞窗口变化图:
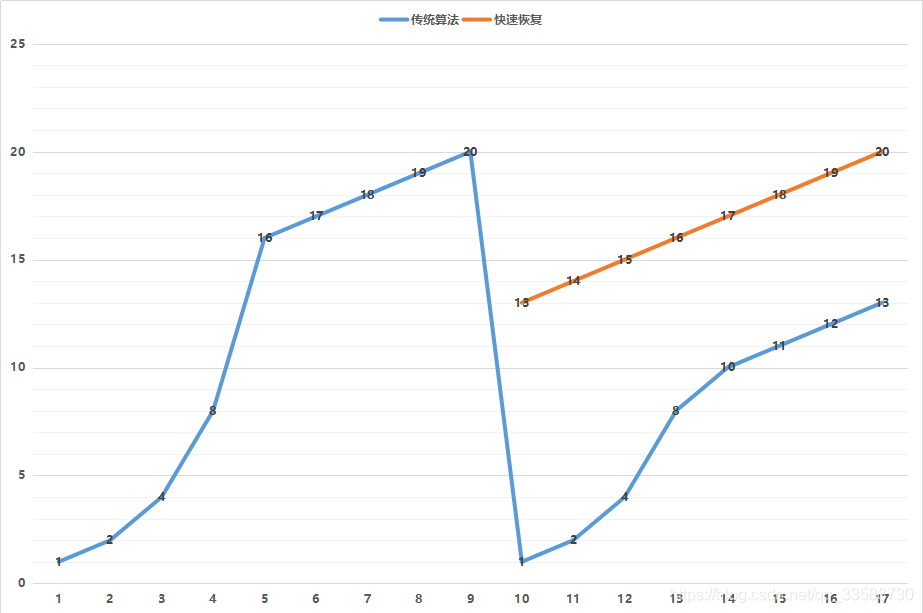
一开始的窗口只有一个mss大小叫作slow start(慢启动)。一开始的增长速度是很快的,翻倍增长。一旦到达一个临界值ssthresh,就变成线性增长,就称为拥塞避免。什么时候算真正拥塞呢?就是出现了丢包。一旦丢包,一种方法是马上降回到一个mss,然后重复先翻倍再线性对的过程。如果觉得太过激进也可以有第二种方法,就是降到当前cwnd的一半,然后进行线性增长。
在代码中,tcp_cwnd_test会将当前的snd_cwnd,减去已经在窗口里面尚未发送完毕的网络包,那就是剩下的窗口大小cwnd_quota,即就能发送这么多了。
第三个概念就是接收窗口rwnd的概念(receive window),也叫滑动窗口。如果说拥塞窗口是为了怕把网络塞满,在出现丢包的时候减少发送速度,那么滑动窗口就是为了怕把接收方塞满,而控制发送速度。滑动窗口,其实就是接收方主动告诉发送方自己的网络包的接收能力,超过这个能力就受不了了。因为滑动窗口的存在,将发送方的缓存分成了四个部分:
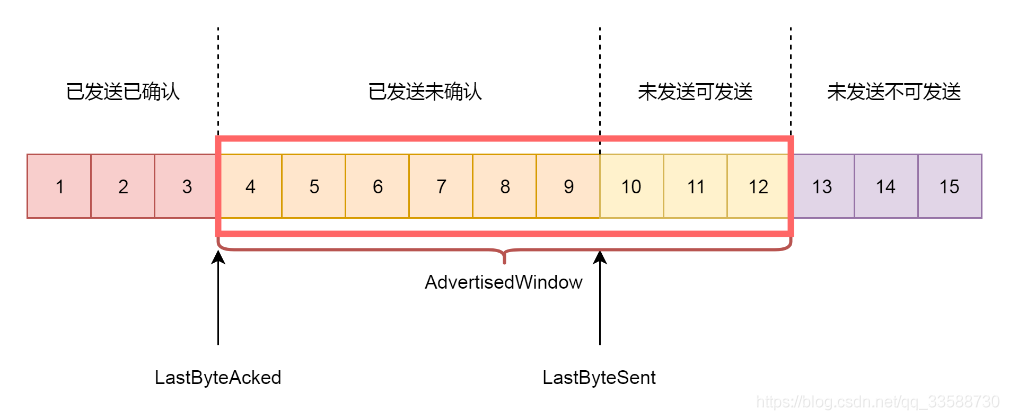
(1)发送了并且已经确认的。这部分是已经发送完毕的网络包,没有用了可以回收。
(2)发送了但尚未确认的。这部分发送方要等待,万一发送不成功,还要重新发送,所以不能删除。
(3)没有发送,但是已经等待发送的。这部分是接收方空闲的能力,可以马上发送,接收方受得了。
(4)没有发送,并且暂时还不会发送的。这部分已经超过了接收方的接收能力,再发送接收方就受不了了。
因为滑动窗口的存在,接收方的缓存也要分成了三个部分,如下图所示:
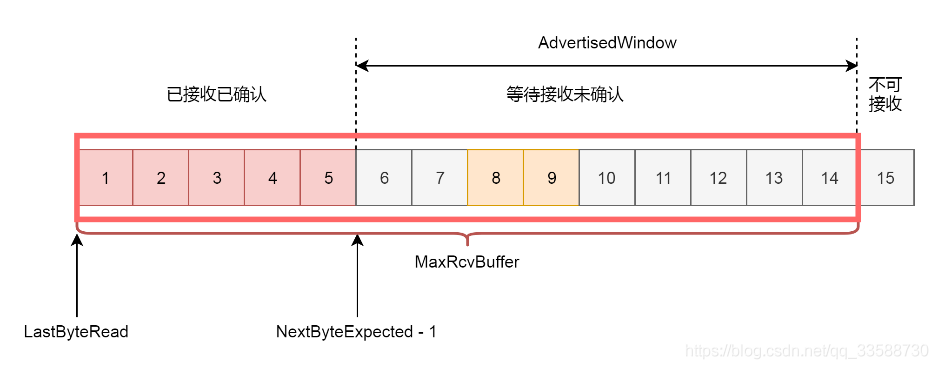
(1)接受并且确认过的任务。这部分完全接收成功了,可以交给应用层了。
(2)还没接收,但是马上就能接收的任务。这部分有的网络包到达了,但是还没确认,不算完全完毕,有的还没有到达,那就是接收方能够接受的最大的网络包数量。
(3)还没接收,也没法接收的任务。这部分已经超出接收方能力。
在网络包的交互过程中,接收方会将第二部分的大小,作为AdvertisedWindow发送给发送方,发送方就可以根据它来调整发送速度了。在tcp_snd_wnd_test函数中,会判断sk_buff中的end_seq和tcp_wnd_end(tp)之间的关系,即这个sk_buff是否在滑动窗口的允许范围之内,如果不在范围内说明发送要受限制了,就要把is_rwnd_limited设置为 true。接下来,tcp_mss_split_point函数要被调用了,如下所示:
static unsigned int tcp_mss_split_point(const struct sock *sk, const struct sk_buff *skb, unsigned int mss_now, unsigned int max_segs, int nonagle) { const struct tcp_sock *tp = tcp_sk(sk); u32 partial, needed, window, max_len; window = tcp_wnd_end(tp) - TCP_SKB_CB(skb)->seq; max_len = mss_now * max_segs; if (likely(max_len <= window && skb != tcp_write_queue_tail(sk))) return max_len; needed = min(skb->len, window); if (max_len <= needed) return max_len; ...... return needed; }
这里面除了会判断上面讲的是否会因为超出mss而分段,还会判断另一个条件,就是是否在滑动窗口的运行范围之内,如果小于窗口的大小也需要分段,即需要调用tso_fragment。在一个循环的最后是调用tcp_transmit_skb,真的去发送一个网络包,如下所示:
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask) { const struct inet_connection_sock *icsk = inet_csk(sk); struct inet_sock *inet; struct tcp_sock *tp; struct tcp_skb_cb *tcb; struct tcphdr *th; int err; tp = tcp_sk(sk); skb->skb_mstamp = tp->tcp_mstamp; inet = inet_sk(sk); tcb = TCP_SKB_CB(skb); memset(&opts, 0, sizeof(opts)); tcp_header_size = tcp_options_size + sizeof(struct tcphdr); skb_push(skb, tcp_header_size); /* Build TCP header and checksum it. */ th = (struct tcphdr *)skb->data; th->source = inet->inet_sport; th->dest = inet->inet_dport; th->seq = htonl(tcb->seq); th->ack_seq = htonl(tp->rcv_nxt); *(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) | tcb->tcp_flags); th->check = 0; th->urg_ptr = 0; ...... tcp_options_write((__be32 *)(th + 1), tp, &opts); th->window = htons(min(tp->rcv_wnd, 65535U)); ...... err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); ...... }
tcp_transmit_skb这个函数比较长,主要做了两件事情,第一件事情就是填充TCP头,如果对着TCP头的格式来看:
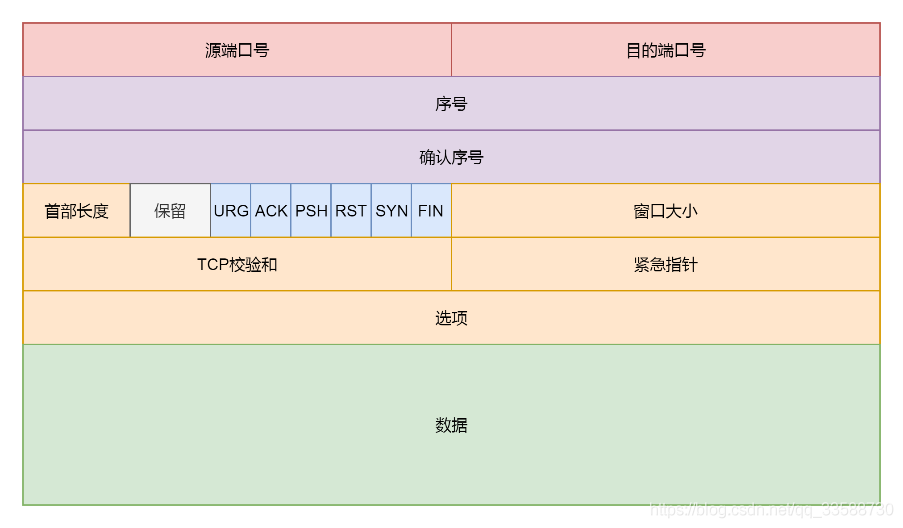
这里面有源端口设置为inet_sport,有目标端口设置为inet_dport;有序列号设置为tcb->seq;有确认序列号设置为tp->rcv_nxt。把所有的flags设置为tcb->tcp_flags,设置选项为opts,设置窗口大小为tp->rcv_wnd。全部设置完毕之后,就会调用icsk_af_ops的queue_xmit方法,icsk_af_ops指向ipv4_specific,即调用的是ip_queue_xmit函数,到了IP层,如下所示:
const struct inet_connection_sock_af_ops ipv4_specific = { .queue_xmit = ip_queue_xmit, .send_check = tcp_v4_send_check, .rebuild_header = inet_sk_rebuild_header, .sk_rx_dst_set = inet_sk_rx_dst_set, .conn_request = tcp_v4_conn_request, .syn_recv_sock = tcp_v4_syn_recv_sock, .net_header_len = sizeof(struct iphdr), .setsockopt = ip_setsockopt, .getsockopt = ip_getsockopt, .addr2sockaddr = inet_csk_addr2sockaddr, .sockaddr_len = sizeof(struct sockaddr_in), .mtu_reduced = tcp_v4_mtu_reduced, };
4.5 IP层
扩展struct sock得到struct inet_connection_sock,根据里面icsk_af_ops的定义调用ip_queue_xmit函数。然后ip_route_output_ports函数里面会调用fib_lookup查找FIB路由表。在IP层里要做的另外两个事情是填写IP层的头,和通过iptables规则。
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl) { struct inet_sock *inet = inet_sk(sk); struct net *net = sock_net(sk); struct ip_options_rcu *inet_opt; struct flowi4 *fl4; struct rtable *rt; struct iphdr *iph; int res; inet_opt = rcu_dereference(inet->inet_opt); fl4 = &fl->u.ip4; rt = skb_rtable(skb); /* Make sure we can route this packet. */ rt = (struct rtable *)__sk_dst_check(sk, 0); if (!rt) { __be32 daddr; /* Use correct destination address if we have options. */ daddr = inet->inet_daddr; ...... rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; sk_setup_caps(sk, &rt->dst); } skb_dst_set_noref(skb, &rt->dst); packet_routed: /* OK, we know where to send it, allocate and build IP header. */ skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0)); skb_reset_network_header(skb); iph = ip_hdr(skb); *((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff)); if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df) iph->frag_off = htons(IP_DF); else iph->frag_off = 0; iph->ttl = ip_select_ttl(inet, &rt->dst); iph->protocol = sk->sk_protocol; ip_copy_addrs(iph, fl4); /* Transport layer set skb->h.foo itself. */ if (inet_opt && inet_opt->opt.optlen) { iph->ihl += inet_opt->opt.optlen >> 2; ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0); } ip_select_ident_segs(net, skb, sk, skb_shinfo(skb)->gso_segs ?: 1); /* TODO : should we use skb->sk here instead of sk ? */ skb->priority = sk->sk_priority; skb->mark = sk->sk_mark; res = ip_local_out(net, sk, skb); ...... }
在 ip_queue_xmit 即 IP 层的发送函数里面,有三部分逻辑:
(1)第一部分,选取路由,即要发送这个包应该从哪个网卡出去。这件事情主要由ip_route_output_ports函数完成。接下来的调用链为:ip_route_output_ports->ip_route_output_flow->__ip_route_output_key->ip_route_output_key_hash->ip_route_output_key_hash_rcu,如下所示:
struct rtable *ip_route_output_key_hash_rcu(struct net *net, struct flowi4 *fl4, struct fib_result *res, const struct sk_buff *skb) { struct net_device *dev_out = NULL; int orig_oif = fl4->flowi4_oif; unsigned int flags = 0; struct rtable *rth; ...... err = fib_lookup(net, fl4, res, 0); ...... make_route: rth = __mkroute_output(res, fl4, orig_oif, dev_out, flags); ...... }
ip_route_output_key_hash_rcu先会调用fib_lookup,FIB(Forwarding Information Base,转发信息表)其实就是常说的路由表,如下所示:
static inline int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res, unsigned int flags) { struct fib_table *tb; ...... tb = fib_get_table(net, RT_TABLE_MAIN); if (tb) err = fib_table_lookup(tb, flp, res, flags | FIB_LOOKUP_NOREF); ...... }
路由表可以有多个,一般会有一个主表,RT_TABLE_MAIN,然后fib_table_lookup函数在这个表里面进行查找。路由就是在Linux服务器上的路由表里面配置的一条一条规则,这些规则大概是这样的:想访问某个网段,从某个网卡出去,下一跳是某个IP。之前讲过一个简单的拓扑图,里面三台Linux机器的路由表都可以通过ip route命令查看,如下所示:
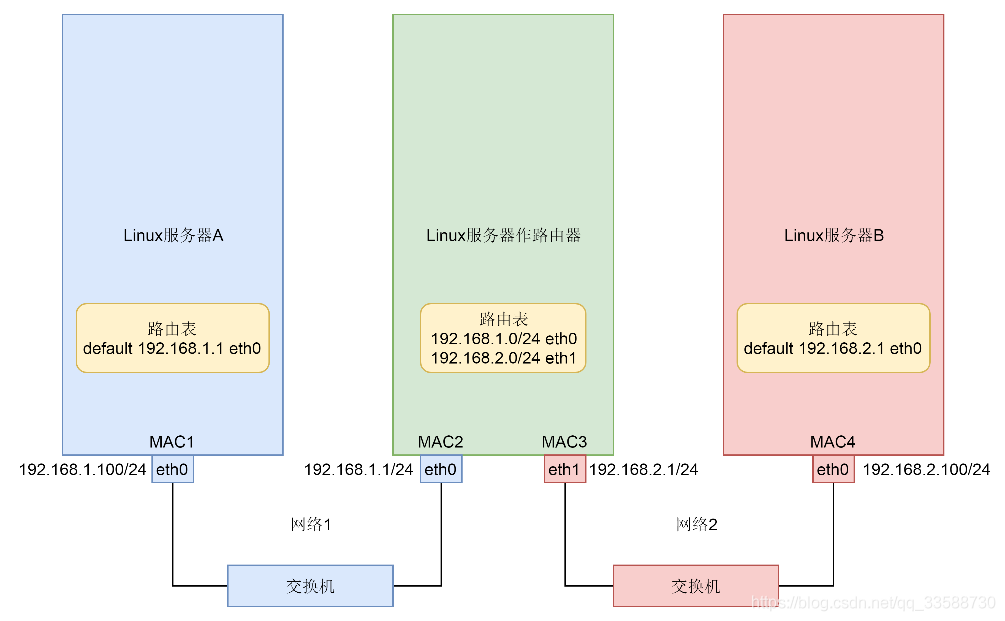
# Linux服务器A default via 192.168.1.1 dev eth0 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 100 # Linux服务器B default via 192.168.2.1 dev eth0 192.168.2.0/24 dev eth0 proto kernel scope link src 192.168.2.100 metric 100 # Linux服务器做路由器 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.1 192.168.2.0/24 dev eth1 proto kernel scope link src 192.168.2.1
可以看到对于两端的服务器来讲,没有太多路由可以选,但是对于中间Linux路由器来讲有两条路可以选,一个是往左面转发,一个是往右面转发,就需要路由表的查找。fib_table_lookup的代码逻辑比较复杂,好在注释比较清楚。因为路由表要按照前缀进行查询,希望找到最长匹配的那一个,例如192.168.2.0/24和192.168.0.0/16都能匹配192.168.2.100/24,但是应该使用192.168.2.0/24的这一条。为了更方面做这个事情,使用了Trie树这种结构(能比较好的查询最长前缀)。比如有一系列的字符串:{bcs#, badge#, baby#, back#, badger#, badness#},之所以每个字符串都加上#,是希望不要一个字符串成为另外一个字符串的前缀,然后把它们放在Trie树中。
对于将IP地址转成二进制放入trie树也是同样的道理,可以很快进行路由的查询。找到了路由,就知道了应该从哪个网卡发出去。然后ip_route_output_key_hash_rcu会调用__mkroute_output,创建一个struct rtable,表示找到的路由表项,这个结构是由rt_dst_alloc函数分配的,如下所示:
struct rtable *rt_dst_alloc(struct net_device *dev, unsigned int flags, u16 type, bool nopolicy, bool noxfrm, bool will_cache) { struct rtable *rt; rt = dst_alloc(&ipv4_dst_ops, dev, 1, DST_OBSOLETE_FORCE_CHK, (will_cache ? 0 : DST_HOST) | (nopolicy ? DST_NOPOLICY : 0) | (noxfrm ? DST_NOXFRM : 0)); if (rt) { rt->rt_genid = rt_genid_ipv4(dev_net(dev)); rt->rt_flags = flags; rt->rt_type = type; rt->rt_is_input = 0; rt->rt_iif = 0; rt->rt_pmtu = 0; rt->rt_gateway = 0; rt->rt_uses_gateway = 0; rt->rt_table_id = 0; INIT_LIST_HEAD(&rt->rt_uncached); rt->dst.output = ip_output; if (flags & RTCF_LOCAL) rt->dst.input = ip_local_deliver; } return rt; }
最终返回struct rtable实例,第一部分也就完成了,知道了怎么发。
(2)第二部分,就是准备IP层的头,往里面填充内容。这就要对着IP层的头的格式进行理解,如下图所示:

在这里面服务类型设置为tos,标识位里面设置是否允许分片frag_off,如果不允许而遇到MTU太小过不去的情况,就发送ICMP报错。TTL是这个包的存活时间,为了防止一个IP包迷路以后一直存活下去,每经过一个路由器TTL都减一,减为零则被丢弃。设置protocol指的是更上层的协议,这里是TCP。源地址和目标地址由ip_copy_addrs设置。最后设置options。
(3)第三部分,就是调用ip_local_out发送IP包,如下所示:
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) { int err; err = __ip_local_out(net, sk, skb); if (likely(err == 1)) err = dst_output(net, sk, skb); return err; } int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) { struct iphdr *iph = ip_hdr(skb); iph->tot_len = htons(skb->len); skb->protocol = htons(ETH_P_IP); return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, net, sk, skb, NULL, skb_dst(skb)->dev, dst_output); }
ip_local_out先是调用__ip_local_out,然后里面调用了nf_hook。这是什么呢?nf的意思是Netfilter,这是Linux内核的一个机制,用于在网络发送和转发的关键节点上加上hook函数,这些函数可以截获数据包,对数据包进行干预。一个著名的实现就是内核模块ip_tables,在用户态还有一个客户端程序iptables,用该命令行来干预内核的规则,如下图所示:
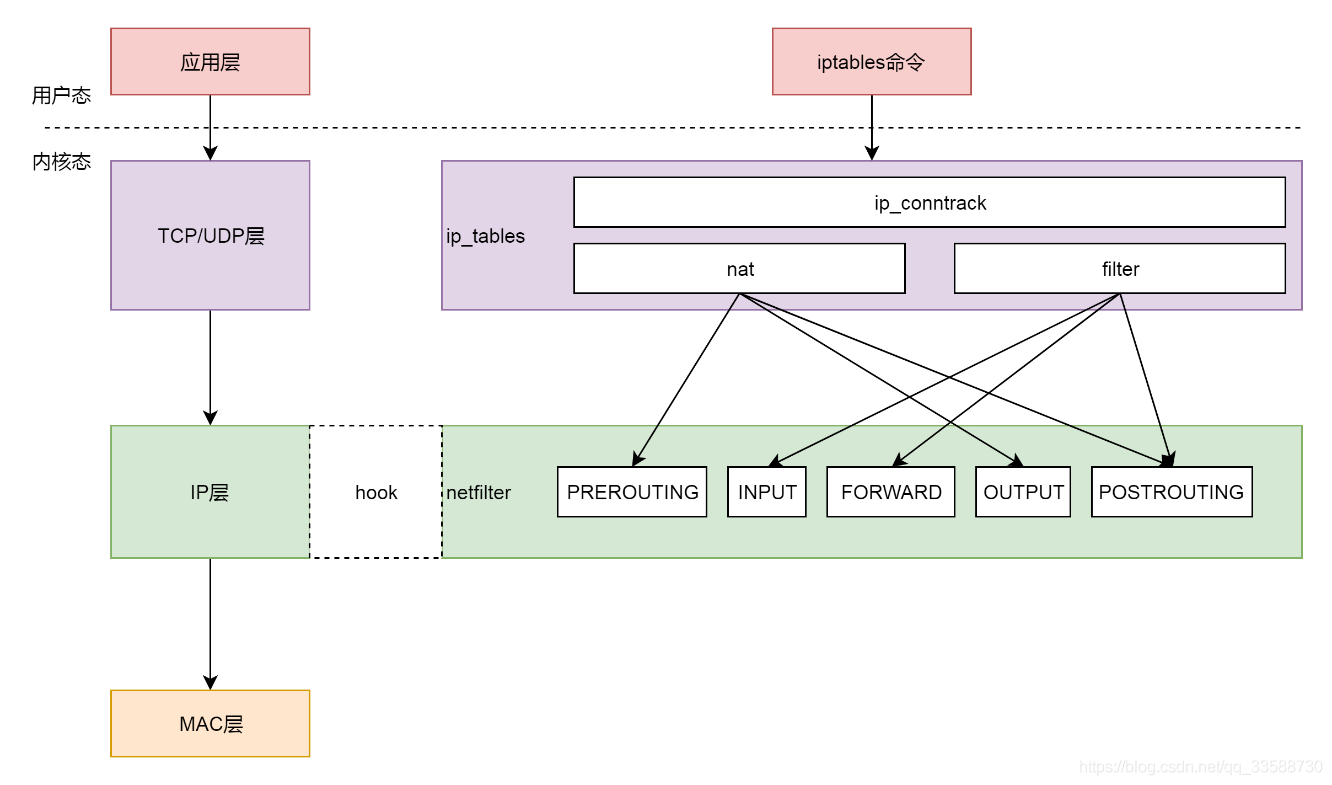
iptables有表和链的概念,最重要的是两个表:
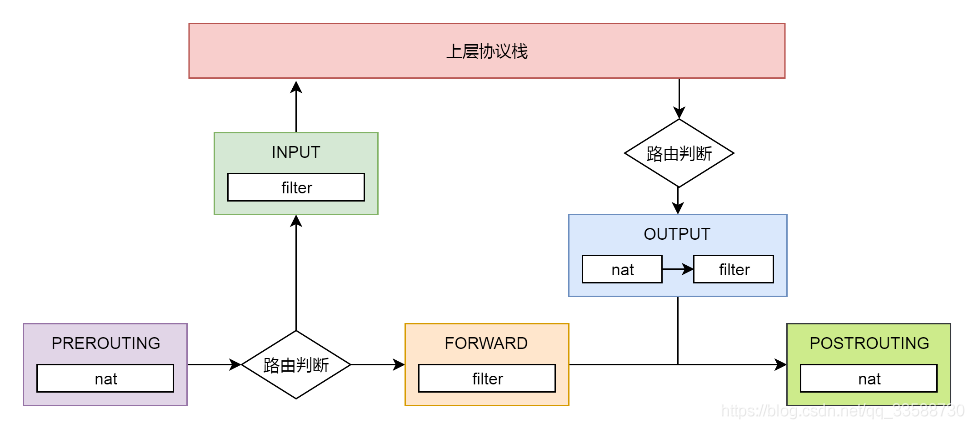
a. filter表处理过滤功能,主要包含以下三个链:INPUT链过滤所有目标地址是本机的数据包;FORWARD链过滤所有路过本机的数据包;OUTPUT链过滤所有由本机产生的数据包。
b. nat表主要处理网络地址转换,可以进行SNAT(改变源地址)、DNAT(改变目标地址),包含以下三个链:PREROUTING链可以在数据包到达时改变目标地址;OUTPUT 链可以改变本地产生的数据包的目标地址;POSTROUTING 链在数据包离开时改变数据包的源地址。改变的方式如下图所示:
在这里网络包马上就要发出去了,因而是NF_INET_LOCAL_OUT即ouput链,如果用户曾经在iptables里面写过某些规则,就会在nf_hook这个函数里面起作用。ip_local_out再调用dst_output,就是真正的发送数据,如下所示:
/* Output packet to network from transport. */ static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb) { return skb_dst(skb)->output(net, sk, skb); }
这里调用的就是struct rtable成员dst的ouput函数。在rt_dst_alloc中可以看到,output函数指向的是ip_output,如下所示:
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb) { struct net_device *dev = skb_dst(skb)->dev; skb->dev = dev; skb->protocol = htons(ETH_P_IP); return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, net, sk, skb, NULL, dev, ip_finish_output, !(IPCB(skb)->flags & IPSKB_REROUTED)); }
在ip_output里面又看到了熟悉的NF_HOOK,这一次是NF_INET_POST_ROUTING即POSTROUTING链,处理完之后调用ip_finish_output。
4.6 MAC层
IP层调用ip_finish_output进入MAC层。MAC层需要ARP获得MAC地址,因而要调用__neigh_lookup_noref查找属于同一个网段的邻居,它会调用neigh_probe发送 ARP。有了MAC地址,就可以调用dev_queue_xmit发送二层网络包了,它会调用__dev_xmit_skb会将请求放入队列。
从ip_finish_output函数开始,发送网络包的逻辑由第三层到达第二层。ip_finish_output最终调用ip_finish_output2,如下所示:
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb) { struct dst_entry *dst = skb_dst(skb); struct rtable *rt = (struct rtable *)dst; struct net_device *dev = dst->dev; unsigned int hh_len = LL_RESERVED_SPACE(dev); struct neighbour *neigh; u32 nexthop; ...... nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr); neigh = __ipv4_neigh_lookup_noref(dev, nexthop); if (unlikely(!neigh)) neigh = __neigh_create(&arp_tbl, &nexthop, dev, false); if (!IS_ERR(neigh)) { int res; sock_confirm_neigh(skb, neigh); res = neigh_output(neigh, skb); return res; } ...... }
在ip_finish_output2中,先找到struct rtable路由表里面的下一跳,下一跳一定和本机在同一个局域网中,可以通过二层进行通信,因而通过__ipv4_neigh_lookup_noref,查找如何通过二层访问下一跳:
static inline struct neighbour *__ipv4_neigh_lookup_noref(struct net_device *dev, u32 key) { return ___neigh_lookup_noref(&arp_tbl, neigh_key_eq32, arp_hashfn, &key, dev); } __ipv4_neigh_lookup_noref是从本地的ARP表中查找下一跳的MAC地址。ARP表的定义如下: struct neigh_table arp_tbl = { .family = AF_INET, .key_len = 4, .protocol = cpu_to_be16(ETH_P_IP), .hash = arp_hash, .key_eq = arp_key_eq, .constructor = arp_constructor, .proxy_redo = parp_redo, .id = "arp_cache", ...... .gc_interval = 30 * HZ, .gc_thresh1 = 128, .gc_thresh2 = 512, .gc_thresh3 = 1024, };
如果在ARP表中没有找到相应的项,则调用__neigh_create进行创建ARP项,如下所示:
struct neighbour *__neigh_create(struct neigh_table *tbl, const void *pkey, struct net_device *dev, bool want_ref) { u32 hash_val; int key_len = tbl->key_len; int error; struct neighbour *n1, *rc, *n = neigh_alloc(tbl, dev); struct neigh_hash_table *nht; memcpy(n->primary_key, pkey, key_len); n->dev = dev; dev_hold(dev); /* Protocol specific setup. */ if (tbl->constructor && (error = tbl->constructor(n)) < 0) { ...... } ...... if (atomic_read(&tbl->entries) > (1 << nht->hash_shift)) nht = neigh_hash_grow(tbl, nht->hash_shift + 1); hash_val = tbl->hash(pkey, dev, nht->hash_rnd) >> (32 - nht->hash_shift); for (n1 = rcu_dereference_protected(nht->hash_buckets[hash_val], lockdep_is_held(&tbl->lock)); n1 != NULL; n1 = rcu_dereference_protected(n1->next, lockdep_is_held(&tbl->lock))) { if (dev == n1->dev && !memcmp(n1->primary_key, pkey, key_len)) { if (want_ref) neigh_hold(n1); rc = n1; goto out_tbl_unlock; } } ...... rcu_assign_pointer(n->next, rcu_dereference_protected(nht->hash_buckets[hash_val], lockdep_is_held(&tbl->lock))); rcu_assign_pointer(nht->hash_buckets[hash_val], n); ...... }
__neigh_create先调用neigh_alloc创建一个struct neighbour结构,用于维护MAC地址和ARP相关的信息。大家都是在一个局域网里面,可以通过MAC地址访问到,当然是邻居了,如下所示:
static struct neighbour *neigh_alloc(struct neigh_table *tbl, struct net_device *dev) { struct neighbour *n = NULL; unsigned long now = jiffies; int entries; ...... n = kzalloc(tbl->entry_size + dev->neigh_priv_len, GFP_ATOMIC); if (!n) goto out_entries; __skb_queue_head_init(&n->arp_queue); rwlock_init(&n->lock); seqlock_init(&n->ha_lock); n->updated = n->used = now; n->nud_state = NUD_NONE; n->output = neigh_blackhole; seqlock_init(&n->hh.hh_lock); n->parms = neigh_parms_clone(&tbl->parms); setup_timer(&n->timer, neigh_timer_handler, (unsigned long)n); NEIGH_CACHE_STAT_INC(tbl, allocs); n->tbl = tbl; refcount_set(&n->refcnt, 1); n->dead = 1; ...... }
在neigh_alloc中,先分配一个struct neighbour结构并且初始化。这里面比较重要的有两个成员,一个是arp_queue,即上层想通过ARP获取MAC地址的任务,都放在这个队列里面。另一个是timer定时器,设置成过一段时间就调用neigh_timer_handler,来处理这些ARP任务。__neigh_create然后调用了arp_tbl的constructor函数,即调用了arp_constructor,在这里面定义了ARP的操作arp_hh_ops,如下所示:
static int arp_constructor(struct neighbour *neigh) { __be32 addr = *(__be32 *)neigh->primary_key; struct net_device *dev = neigh->dev; struct in_device *in_dev; struct neigh_parms *parms; ...... neigh->type = inet_addr_type_dev_table(dev_net(dev), dev, addr); parms = in_dev->arp_parms; __neigh_parms_put(neigh->parms); neigh->parms = neigh_parms_clone(parms); ...... neigh->ops = &arp_hh_ops; ...... neigh->output = neigh->ops->output; ...... } static const struct neigh_ops arp_hh_ops = { .family = AF_INET, .solicit = arp_solicit, .error_report = arp_error_report, .output = neigh_resolve_output, .connected_output = neigh_resolve_output, };
上面__neigh_create最后是将创建的struct neighbour结构放入一个哈希表,从前面的代码逻辑容易看出,这是一个数组加链表的链式哈希表,先计算出哈希值hash_val得到相应的链表,然后循环这个链表找到对应的项,如果找不到就在最后插入一项。回到ip_finish_output2,在__neigh_create之后,会调用neigh_output发送网络包,如下所示:
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb) { ...... return n->output(n, skb); }
按照上面对于struct neighbour的操作函数arp_hh_ops的定义,output调用的是neigh_resolve_output,如下所示:
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb) { if (!neigh_event_send(neigh, skb)) { ...... rc = dev_queue_xmit(skb); } ...... }
在neigh_resolve_output里面,首先neigh_event_send触发一个事件看能否激活ARP,如下所示:
int __neigh_event_send(struct neighbour *neigh, struct sk_buff *skb) { int rc; bool immediate_probe = false; if (!(neigh->nud_state & (NUD_STALE | NUD_INCOMPLETE))) { if (NEIGH_VAR(neigh->parms, MCAST_PROBES) + NEIGH_VAR(neigh->parms, APP_PROBES)) { unsigned long next, now = jiffies; atomic_set(&neigh->probes, NEIGH_VAR(neigh->parms, UCAST_PROBES)); neigh->nud_state = NUD_INCOMPLETE; neigh->updated = now; next = now + max(NEIGH_VAR(neigh->parms, RETRANS_TIME), HZ/2); neigh_add_timer(neigh, next); immediate_probe = true; } ...... } else if (neigh->nud_state & NUD_STALE) { neigh_dbg(2, "neigh %p is delayed\n", neigh); neigh->nud_state = NUD_DELAY; neigh->updated = jiffies; neigh_add_timer(neigh, jiffies + NEIGH_VAR(neigh->parms, DELAY_PROBE_TIME)); } if (neigh->nud_state == NUD_INCOMPLETE) { if (skb) { ....... __skb_queue_tail(&neigh->arp_queue, skb); neigh->arp_queue_len_Bytes += skb->truesize; } rc = 1; } out_unlock_bh: if (immediate_probe) neigh_probe(neigh); ....... }
在__neigh_event_send中,激活 ARP 分两种情况,第一种情况是马上激活即immediate_probe。另一种情况是延迟激活则仅仅设置一个timer,到时机了再激活。然后将ARP包放在arp_queue上,如果马上激活就直接调用neigh_probe;如果延迟激活,则定时器到了就会触发neigh_timer_handler,在这里面还是会调用neigh_probe。来看neigh_probe的实现,在这里面会从arp_queue中拿出ARP包来,然后调用struct neighbour的solicit操作,如下所示:
static void neigh_probe(struct neighbour *neigh) __releases(neigh->lock) { struct sk_buff *skb = skb_peek_tail(&neigh->arp_queue); ...... if (neigh->ops->solicit) neigh->ops->solicit(neigh, skb); ...... }
按照上面对于struct neighbour的操作函数arp_hh_ops的定义,solicit调用的是arp_solicit,在这里可以找到对于arp_send_dst的调用,创建并发送一个arp包,得到结果放在struct dst_entry里面,如下所示:
static void arp_send_dst(int type, int ptype, __be32 dest_ip, struct net_device *dev, __be32 src_ip, const unsigned char *dest_hw, const unsigned char *src_hw, const unsigned char *target_hw, struct dst_entry *dst) { struct sk_buff *skb; ...... skb = arp_create(type, ptype, dest_ip, dev, src_ip, dest_hw, src_hw, target_hw); ...... skb_dst_set(skb, dst_clone(dst)); arp_xmit(skb); }
再回到上面neigh_resolve_output中,当ARP发送完毕(知道MAC地址了),就可以调用dev_queue_xmit发送二层网络包了,如下所示:
/** * __dev_queue_xmit - transmit a buffer * @skb: buffer to transmit * @accel_priv: private data used for L2 forwarding offload * * Queue a buffer for transmission to a network device. */ static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv) { struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; ...... txq = netdev_pick_tx(dev, skb, accel_priv); q = rcu_dereference_bh(txq->qdisc); if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; } ...... }
就像硬盘块设备,每个块设备都有队列用于将内核的数据放到队列里面,然后设备驱动从队列里面取出后,将数据根据具体设备的特性发送给设备。网络设备也是类似的,对于发送来说有一个发送队列struct netdev_queue *txq,这里还有另一个变量叫做struct Qdisc,它的意思是如果在一台Linux机器上运行ip addr,能看到对于一个网卡都有下面的输出:
# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UP group default qlen 1000 link/ether fa:16:3e:75:99:08 brd ff:ff:ff:ff:ff:ff inet 10.173.32.47/21 brd 10.173.39.255 scope global noprefixroute dynamic eth0 valid_lft 67104sec preferred_lft 67104sec inet6 fe80::f816:3eff:fe75:9908/64 scope link valid_lft forever preferred_lft forever
这里面有个关键字qdisc pfifo_fast是什么意思呢?qdisc全称是queueing discipline叫排队规则,内核如果需要通过某个网络接口发送数据包,都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。最简单的qdisc是pfifo,它不对进入的数据包做任何处理,数据包采用先入先出的方式通过队列。pfifo_fast稍复杂一些,它的队列包括三个波段(band),在每个波段里面使用先进先出规则。
三个波段的优先级也不相同。band 0的优先级最高,band 2的最低。如果band 0里面有数据包,系统就不会处理band 1里面的数据包,band 1和band 2之间也是一样。数据包是按照服务类型(Type of Service,TOS)被分配到三个波段里面的。TOS是IP头里面的一个字段,代表了当前的包是高优先级的还是低优先级的。pfifo_fast分为三个先入先出的队列,称为三个Band。根据网络包里面的TOS,看这个包到底应该进入哪个队列。TOS总共四位,每一位表示的意思不同,总共十六种类型,如下图所示:
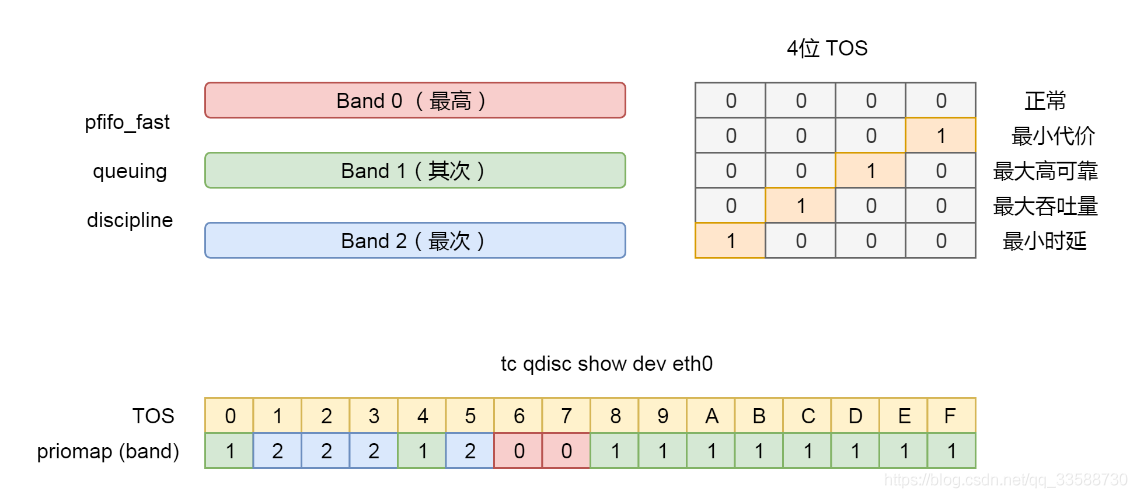
通过命令行tc qdisc show dev eth0可以输出结果priomap,也是十六个数字,在0到2之间,和TOS的十六种类型对应起来。不同的TOS对应不同的队列。其中Band 0优先级最高,发送完毕后才轮到Band 1发送,最后才是Band 2,如下所示:
# tc qdisc show dev eth0 qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
接下来,__dev_xmit_skb开始进行网络包发送,如下所示:
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq) { ...... rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK; if (qdisc_run_begin(q)) { ...... __qdisc_run(q); } ...... } void __qdisc_run(struct Qdisc *q) { int quota = dev_tx_weight; int packets; while (qdisc_restart(q, &packets)) { /* * Ordered by possible occurrence: Postpone processing if * 1. we've exceeded packet quota * 2. another process needs the CPU; */ quota -= packets; if (quota <= 0 || need_resched()) { __netif_schedule(q); break; } } qdisc_run_end(q); }
__dev_xmit_skb会将请求放入队列,然后调用__qdisc_run处理队列中的数据。qdisc_restart用于数据的发送,这段注释很重要,qdisc的另一个功能是用于控制网络包的发送速度,因而如果超过速度就需要重新调度,则会调用__netif_schedule,__netif_schedule又会调用__netif_reschedule,如下所示:
static void __netif_reschedule(struct Qdisc *q) { struct softnet_data *sd; unsigned long flags; local_irq_save(flags); sd = this_cpu_ptr(&softnet_data); q->next_sched = NULL; *sd->output_queue_tailp = q; sd->output_queue_tailp = &q->next_sched; raise_softirq_irqoff(NET_TX_SOFTIRQ); local_irq_restore(flags); }
4.7 设备层
网络包的发送会触发一个软中断NET_TX_SOFTIRQ来处理队列中的数据,这个软中断的处理函数是net_tx_action。在软中断处理函数中会将网络包从队列上拿下来,调用网络设备的传输函数ixgb_xmit_frame,将网络包发到设备的队列上去。
发起一个软中断NET_TX_SOFTIRQ。之前提到设备驱动程序时说过,设备驱动程序处理中断分两个过程,一个是屏蔽中断的关键处理逻辑,一个是延迟处理逻辑,工作队列是延迟处理逻辑的处理方案,软中断也是一种方案。在系统初始化时,会定义软中断的处理函数,例如NET_TX_SOFTIRQ的处理函数是net_tx_action,用于发送网络包。还有一个NET_RX_SOFTIRQ的处理函数是net_rx_action,用于接收网络包,如下所示:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
这里来解析一下net_tx_action,如下所示:
static __latent_entropy void net_tx_action(struct softirq_action *h) { struct softnet_data *sd = this_cpu_ptr(&softnet_data); ...... if (sd->output_queue) { struct Qdisc *head; local_irq_disable(); head = sd->output_queue; sd->output_queue = NULL; sd->output_queue_tailp = &sd->output_queue; local_irq_enable(); while (head) { struct Qdisc *q = head; spinlock_t *root_lock; head = head->next_sched; ...... qdisc_run(q); } } }
会发现net_tx_action还是调用了qdisc_run,然后会调用__qdisc_run,再调用qdisc_restart发送网络包。来看一下qdisc_restart的实现,如下所示:
static inline int qdisc_restart(struct Qdisc *q, int *packets) { struct netdev_queue *txq; struct net_device *dev; spinlock_t *root_lock; struct sk_buff *skb; bool validate; /* Dequeue packet */ skb = dequeue_skb(q, &validate, packets); if (unlikely(!skb)) return 0; root_lock = qdisc_lock(q); dev = qdisc_dev(q); txq = skb_get_tx_queue(dev, skb); return sch_direct_xmit(skb, q, dev, txq, root_lock, validate); }
qdisc_restart将网络包从Qdisc的队列中拿下来,然后调用sch_direct_xmit进行发送,如下所示:
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, spinlock_t *root_lock, bool validate) { int ret = NETDEV_TX_BUSY; if (likely(skb)) { if (!netif_xmit_frozen_or_stopped(txq)) skb = dev_hard_start_xmit(skb, dev, txq, &ret); } ...... if (dev_xmit_complete(ret)) { /* Driver sent out skb successfully or skb was consumed */ ret = qdisc_qlen(q); } else { /* Driver returned NETDEV_TX_BUSY - requeue skb */ ret = dev_requeue_skb(skb, q); } ...... }
在sch_direct_xmit中,调用dev_hard_start_xmit进行发送,如果发送不成功会返回NETDEV_TX_BUSY,这说明网卡很忙,于是就调用dev_requeue_skb重新放入队列。dev_hard_start_xmit的实现如下所示:
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev, struct netdev_queue *txq, int *ret) { struct sk_buff *skb = first; int rc = NETDEV_TX_OK; while (skb) { struct sk_buff *next = skb->next; rc = xmit_one(skb, dev, txq, next != NULL); skb = next; if (netif_xmit_stopped(txq) && skb) { rc = NETDEV_TX_BUSY; break; } } ...... }
在dev_hard_start_xmit中是一个 while 循环,每次在队列中取出一个sk_buff,调用xmit_one发送。接下来的调用链为:xmit_one->netdev_start_xmit->__netdev_start_xmit,如下所示:
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops, struct sk_buff *skb, struct net_device *dev, bool more) { skb->xmit_more = more ? 1 : 0; return ops->ndo_start_xmit(skb, dev); }
这个时候已经到了设备驱动层了,能看到drivers/net/ethernet/intel/ixgb/ixgb_main.c里面有对于这个网卡的操作定义,如下所示:
static const struct net_device_ops ixgb_netdev_ops = { .ndo_open = ixgb_open, .ndo_stop = ixgb_close, .ndo_start_xmit = ixgb_xmit_frame, .ndo_set_rx_mode = ixgb_set_multi, .ndo_validate_addr = eth_validate_addr, .ndo_set_mac_address = ixgb_set_mac, .ndo_change_mtu = ixgb_change_mtu, .ndo_tx_timeout = ixgb_tx_timeout, .ndo_vlan_rx_add_vid = ixgb_vlan_rx_add_vid, .ndo_vlan_rx_kill_vid = ixgb_vlan_rx_kill_vid, .ndo_fix_features = ixgb_fix_features, .ndo_set_features = ixgb_set_features, };
在这里面可以找到对于ndo_start_xmit的定义,即调用ixgb_xmit_frame,如下所示:
static netdev_tx_t ixgb_xmit_frame(struct sk_buff *skb, struct net_device *netdev) { struct ixgb_adapter *adapter = netdev_priv(netdev); ...... if (count) { ixgb_tx_queue(adapter, count, vlan_id, tx_flags); /* Make sure there is space in the ring for the next send. */ ixgb_maybe_stop_tx(netdev, &adapter->tx_ring, DESC_NEEDED); } ...... return NETDEV_TX_OK; }
在ixgb_xmit_frame中会得到这个网卡对应的适配器(adapter),然后将包放入硬件网卡的队列中。至此整个发送才算结束。
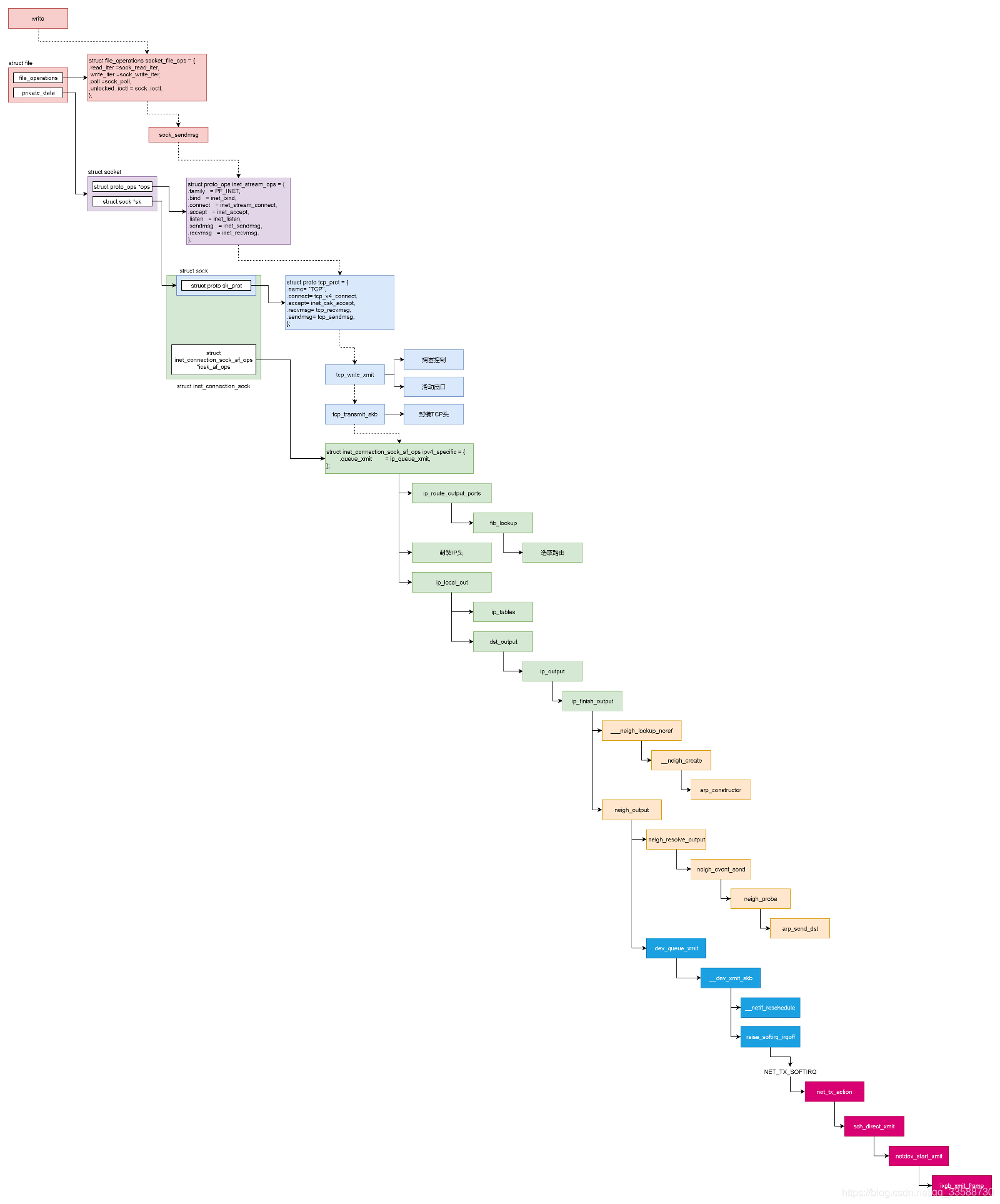
4.8 发送过程总结
整个发送过程总结如下:
5. recv 过程
数据包接收过程如下:
5.1内核接收网络包
5.1.1 设备层
网卡作为一个硬件接收到网络包,应该怎么通知操作系统这个网络包到达了呢?虽然可以触发一个中断。但是这里有个问题,就是网络包的到来往往是很难预期的。网络吞吐量比较大的时候,网络包的到达会十分频繁。这个时候如果非常频繁地去触发中断,会导致这样的后果:比如CPU正在做某个事情,一些网络包来了触发了中断,CPU停下手里的事情去处理这些网络包,处理完毕按照中断处理的逻辑,应该回去继续处理其他事情;这个时候另一些网络包又来了又触发了中断,CPU手里的事情还没捂热,又要停下来去处理网络包。
因此必须另想办法,可以有一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,可以先进入主动轮询poll网卡的方式,主动去接收到来的网络包。如果一直有就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断再轮询poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式称为NAPI。
为了了解设备驱动层的工作机制,还是以上面发送网络包时的网卡的drivers/net/ethernet/intel/ixgb/ixgb_main.c为例子进行解析:
static struct pci_driver ixgb_driver = { .name = ixgb_driver_name, .id_table = ixgb_pci_tbl, .probe = ixgb_probe, .remove = ixgb_remove, .err_handler = &ixgb_err_handler }; MODULE_AUTHOR("Intel Corporation, <linux.nics@intel.com>"); MODULE_DESCRIPTION("Intel(R) PRO/10GbE Network Driver"); MODULE_LICENSE("GPL"); MODULE_VERSION(DRV_VERSION); /** * ixgb_init_module - Driver Registration Routine * * ixgb_init_module is the first routine called when the driver is * loaded. All it does is register with the PCI subsystem. **/ static int __init ixgb_init_module(void) { pr_info("%s - version %s\n", ixgb_driver_string, ixgb_driver_version); pr_info("%s\n", ixgb_copyright); return pci_register_driver(&ixgb_driver); } module_init(ixgb_init_module);
在网卡驱动程序初始化的时候会调用ixgb_init_module,注册一个驱动ixgb_driver,并且调用它的probe函数ixgb_probe,如下所示:
static int ixgb_probe(struct pci_dev *pdev, const struct pci_device_id *ent) { struct net_device *netdev = NULL; struct ixgb_adapter *adapter; ...... netdev = alloc_etherdev(sizeof(struct ixgb_adapter)); SET_NETDEV_DEV(netdev, &pdev->dev); pci_set_drvdata(pdev, netdev); adapter = netdev_priv(netdev); adapter->netdev = netdev; adapter->pdev = pdev; adapter->hw.back = adapter; adapter->msg_enable = netif_msg_init(debug, DEFAULT_MSG_ENABLE); adapter->hw.hw_addr = pci_ioremap_bar(pdev, BAR_0); ...... netdev->netdev_ops = &ixgb_netdev_ops; ixgb_set_ethtool_ops(netdev); netdev->watchdog_timeo = 5 * HZ; netif_napi_add(netdev, &adapter->napi, ixgb_clean, 64); strncpy(netdev->name, pci_name(pdev), sizeof(netdev->name) - 1); adapter->bd_number = cards_found; adapter->link_speed = 0; adapter->link_duplex = 0; ...... }
在ixgb_probe中会创建一个struct net_device表示这个网络设备,并且netif_napi_add函数为这个网络设备注册一个轮询poll函数ixgb_clean,将来一旦出现网络包的时候就是要通过它来轮询了。当一个网卡被激活的时候,会调用函数ixgb_open->ixgb_up,在这里面注册一个硬件的中断处理函数,如下所示:
int ixgb_up(struct ixgb_adapter *adapter) { struct net_device *netdev = adapter->netdev; ...... err = request_irq(adapter->pdev->irq, ixgb_intr, irq_flags, netdev->name, netdev); ...... } /** * ixgb_intr - Interrupt Handler * @irq: interrupt number * @data: pointer to a network interface device structure **/ static irqreturn_t ixgb_intr(int irq, void *data) { struct net_device *netdev = data; struct ixgb_adapter *adapter = netdev_priv(netdev); struct ixgb_hw *hw = &adapter->hw; ...... if (napi_schedule_prep(&adapter->napi)) { IXGB_WRITE_REG(&adapter->hw, IMC, ~0); __napi_schedule(&adapter->napi); } return IRQ_HANDLED; }
如果一个网络包到来触发了硬件中断,就会调用ixgb_intr,这里面会调用__napi_schedule,如下所示:
/** * __napi_schedule - schedule for receive * @n: entry to schedule * * The entry's receive function will be scheduled to run. * Consider using __napi_schedule_irqoff() if hard irqs are masked. */ void __napi_schedule(struct napi_struct *n) { unsigned long flags; local_irq_save(flags); ____napi_schedule(this_cpu_ptr(&softnet_data), n); local_irq_restore(flags); } static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); }
__napi_schedule是处于中断处理的关键部分,在它被调用的时候中断是暂时关闭的,但是处理网络包是个复杂的过程,需要到延迟处理部分,所以____napi_schedule将当前设备放到struct softnet_data结构的poll_list里面,说明在延迟处理部分可以接着处理这个poll_list里面的网络设备。然后____napi_schedule触发一个软中断NET_RX_SOFTIRQ,通过软中断触发中断处理的延迟处理部分,也是常用的手段。
软中断NET_RX_SOFTIRQ对应的中断处理函数是net_rx_action,如下所示:
static __latent_entropy void net_rx_action(struct softirq_action *h) { struct softnet_data *sd = this_cpu_ptr(&softnet_data); LIST_HEAD(list); list_splice_init(&sd->poll_list, &list); ...... for (;;) { struct napi_struct *n; ...... n = list_first_entry(&list, struct napi_struct, poll_list); budget -= napi_poll(n, &repoll); } ...... }
在net_rx_action中会得到struct softnet_data结构,这个结构在发送的时候也遇到过,当时它的output_queue用于网络包的发送,这里的poll_list用于网络包的接收。softnet_data结构如下所示:
struct softnet_data { struct list_head poll_list; ...... struct Qdisc *output_queue; struct Qdisc **output_queue_tailp; ...... }
在net_rx_action中接下来是一个循环,在poll_list里面取出网络包到达的设备,然后调用napi_poll来轮询这些设备,napi_poll会调用最初设备初始化时注册的poll函数,对于ixgb_driver对应的函数是ixgb_clean,ixgb_clean会调用ixgb_clean_rx_irq,如下所示:
static bool ixgb_clean_rx_irq(struct ixgb_adapter *adapter, int *work_done, int work_to_do) { struct ixgb_desc_ring *rx_ring = &adapter->rx_ring; struct net_device *netdev = adapter->netdev; struct pci_dev *pdev = adapter->pdev; struct ixgb_rx_desc *rx_desc, *next_rxd; struct ixgb_buffer *buffer_info, *next_buffer, *next2_buffer; u32 length; unsigned int i, j; int cleaned_count = 0; bool cleaned = false; i = rx_ring->next_to_clean; rx_desc = IXGB_RX_DESC(*rx_ring, i); buffer_info = &rx_ring->buffer_info[i]; while (rx_desc->status & IXGB_RX_DESC_STATUS_DD) { struct sk_buff *skb; u8 status; status = rx_desc->status; skb = buffer_info->skb; buffer_info->skb = NULL; prefetch(skb->data - NET_IP_ALIGN); if (++i == rx_ring->count) i = 0; next_rxd = IXGB_RX_DESC(*rx_ring, i); prefetch(next_rxd); j = i + 1; if (j == rx_ring->count) j = 0; next2_buffer = &rx_ring->buffer_info[j]; prefetch(next2_buffer); next_buffer = &rx_ring->buffer_info[i]; ...... length = le16_to_cpu(rx_desc->length); rx_desc->length = 0; ...... ixgb_check_copybreak(&adapter->napi, buffer_info, length, &skb); /* Good Receive */ skb_put(skb, length); /* Receive Checksum Offload */ ixgb_rx_checksum(adapter, rx_desc, skb); skb->protocol = eth_type_trans(skb, netdev); netif_receive_skb(skb); ...... /* use prefetched values */ rx_desc = next_rxd; buffer_info = next_buffer; } rx_ring->next_to_clean = i; ...... }
在网络设备的驱动层有一个用于接收网络包的rx_ring,它是一个环,从网卡硬件接收的包会放在这个环里面。这个环里面的buffer_info[]是一个数组,存放的是网络包的内容,i和j是这个数组的下标,在ixgb_clean_rx_irq里面的while循环中,依次处理环里面的数据,在这里面看到了i和j加一之后,如果超过了数组的大小就跳回下标0,就说明这是一个环。ixgb_check_copybreak函数将buffer_info里面的内容拷贝到struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用netif_receive_skb。
5.1.2 MAC层
从netif_receive_skb函数开始,就进入了内核的网络协议栈。接下来的调用链为:netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb->__netif_receive_skb_core。在__netif_receive_skb_core中先是处理了二层的一些逻辑,例如对于VLAN的处理,接下来要想办法交给第三层,如下所示:
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) { struct packet_type *ptype, *pt_prev; ...... type = skb->protocol; ...... deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &orig_dev->ptype_specific); if (pt_prev) { ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); } ...... } static inline void deliver_ptype_list_skb(struct sk_buff *skb, struct packet_type **pt, struct net_device *orig_dev, __be16 type, struct list_head *ptype_list) { struct packet_type *ptype, *pt_prev = *pt; list_for_each_entry_rcu(ptype, ptype_list, list) { if (ptype->type != type) continue; if (pt_prev) deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } *pt = pt_prev; }
在网络包struct sk_buff里面,二层的头里面有一个protocol表示里面一层,即三层是什么协议。deliver_ptype_list_skb在一个协议列表中逐个匹配,如果能够匹配到就返回。这些协议的注册在网络协议栈初始化的时候, inet_init函数调用dev_add_pack(&ip_packet_type)添加IP协议,协议被放在一个链表里面,如下所示:
void dev_add_pack(struct packet_type *pt) { struct list_head *head = ptype_head(pt); list_add_rcu(&pt->list, head); } static inline struct list_head *ptype_head(const struct packet_type *pt) { if (pt->type == htons(ETH_P_ALL)) return pt->dev ? &pt->dev->ptype_all : &ptype_all; else return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK]; }
假设这个时候的网络包是一个IP包,则在这个链表里面一定能够找到ip_packet_type,在__netif_receive_skb_core中会调用ip_packet_type的func函数,如下所示:
static struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, };
5.1.3 IP层
从ip_rcv函数开始,处理逻辑就从二层到了三层即IP层,如下所示:
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { const struct iphdr *iph; struct net *net; u32 len; ...... net = dev_net(dev); ...... iph = ip_hdr(skb); len = ntohs(iph->tot_len); skb->transport_header = skb->network_header + iph->ihl*4; ...... return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL, skb, dev, NULL, ip_rcv_finish); ...... }
在ip_rcv中得到IP头,然后又遇到了见过多次的NF_HOOK,这次因为是接收网络包,第一个hook点是NF_INET_PRE_ROUTING,也就是iptables的PREROUTING链。如果里面有规则则执行规则,然后调用ip_rcv_finish,如下所示:
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) { const struct iphdr *iph = ip_hdr(skb); struct net_device *dev = skb->dev; struct rtable *rt; int err; ...... rt = skb_rtable(skb); ..... return dst_input(skb); } static inline int dst_input(struct sk_buff *skb) { return skb_dst(skb)->input(skb);
ip_rcv_finish得到网络包对应的路由表然后调用dst_input,在dst_input中调用的是struct rtable成员的dst的input函数。在rt_dst_alloc中可以看到,input函数指向的是ip_local_deliver,如下所示:
int ip_local_deliver(struct sk_buff *skb) { /* * Reassemble IP fragments. */ struct net *net = dev_net(skb->dev); if (ip_is_fragment(ip_hdr(skb))) { if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER)) return 0; } return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL, skb, skb->dev, NULL, ip_local_deliver_finish); }
在ip_local_deliver函数中,如果IP层进行了分段则进行重新的组合。接下来就是熟悉的NF_HOOK,hook点在NF_INET_LOCAL_IN,对应iptables里面的INPUT链,在经过iptables规则处理完毕后调用ip_local_deliver_finish,如下所示:
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb) { __skb_pull(skb, skb_network_header_len(skb)); int protocol = ip_hdr(skb)->protocol; const struct net_protocol *ipprot; ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot) { int ret; ret = ipprot->handler(skb); ...... } ...... }
在IP头中有一个字段protocol,用于指定里面一层的协议,在这里应该是TCP协议。于是从inet_protos数组中,找出TCP协议对应的处理函数,这个数组的定义如下,里面的内容是struct net_protocol:
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly; int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol) { ...... return !cmpxchg((const struct net_protocol **)&inet_protos[protocol], NULL, prot) ? 0 : -1; } static int __init inet_init(void) { ...... if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol\n", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol\n", __func__); ...... } static struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .early_demux_handler = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, .icmp_strict_tag_validation = 1, }; static struct net_protocol udp_protocol = { .early_demux = udp_v4_early_demux, .early_demux_handler = udp_v4_early_demux, .handler = udp_rcv, .err_handler = udp_err, .no_policy = 1, .netns_ok = 1, };
在系统初始化的时候,网络协议栈的初始化调用的是inet_init,它会调用inet_add_protocol,将TCP协议对应的处理函数tcp_protocol、UDP协议对应的处理函数udp_protocol,放到inet_protos数组中。在上面的网络包的接收过程中,会取出TCP协议对应的处理函数tcp_protocol,然后调用handler函数即tcp_v4_rcv函数。这里IP层就结束了,后面就到传输层了。
5.1.4 TCP层
从tcp_v4_rcv函数开始,处理逻辑就从IP层到了TCP层,如下所示:
int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; ...... th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); ...... TCP_SKB_CB(skb)->seq = ntohl(th->seq); TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4); TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq); TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th); TCP_SKB_CB(skb)->tcp_tw_isn = 0; TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph); TCP_SKB_CB(skb)->sacked = 0; lookup: sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted); process: if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; if (sk->sk_state == TCP_NEW_SYN_RECV) { ...... } ...... th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); skb->dev = NULL; if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } ...... if (!sock_owned_by_user(sk)) { if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb); } else if (tcp_add_backlog(sk, skb)) { goto discard_and_relse; } ...... }
在tcp_v4_rcv中得到TCP的头之后,就可以开始处理TCP层的事情。因为TCP层是分状态的,状态被维护在数据结构struct sock里面,因而要根据IP地址以及TCP头里面的内容,在tcp_hashinfo中找到这个包对应的struct sock,从而得到这个包对应连接的状态,接下来就根据不同的状态做不同的处理。例如上面代码中的TCP_LISTEN、TCP_NEW_SYN_RECV状态属于连接建立过程中,再比如TCP_TIME_WAIT状态是连接结束时的状态,这个暂时可以不用看。
接下来分析最主流的网络包接收过程,这里面涉及三个队列:backlog队、prequeue队列和sk_receive_queue队列。同样一个网络包要在三个主体之间交接:
(1)第一个主体是软中断的处理过程。在执行tcp_v4_rcv函数的时候依然处于软中断的处理逻辑里,所以必然会占用这个软中断。
(2)第二个主体就是用户态进程。如果用户态触发系统调用read读取网络包,也要从队列里面找。
(3)第三个主体就是内核协议栈。哪怕用户进程没有调用read读取网络包,当网络包来的时候也得有一个地方接收。
这时候就能够了解上面代码中sock_owned_by_user的意思了,其实就是说当前这个sock是否正有一个用户态进程等着读数据,如果没有则内核协议栈也调用tcp_add_backlog暂存在backlog队列中,并且抓紧离开软中断的处理过程。
如果有一个用户态进程等待读取数据,就会先调用tcp_prequeue即赶紧放入prequeue队列,并且离开软中断的处理过程。在这个函数里面,会看到对于sysctl_tcp_low_latency的判断,即是否要低时延地处理网络包,如果把sysctl_tcp_low_latency设置为 0,那就要放在prequeue队列中暂存,这样不用等待网络包处理完毕就可以离开软中断的处理过程,但是会造成比较长的时延。如果把sysctl_tcp_low_latency设置为1就会是低时延,还是会调用tcp_v4_do_rcv,如下所示:
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) { struct sock *rsk; if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */ struct dst_entry *dst = sk->sk_rx_dst; ...... tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len); return 0; } ...... if (tcp_rcv_state_process(sk, skb)) { ...... } return 0; ...... }
在tcp_v4_do_rcv中分两种情况,一种情况是连接已经建立处于TCP_ESTABLISHED状态,调用tcp_rcv_established。另一种情况就是其他的状态,调用tcp_rcv_state_process,如下所示:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { case TCP_CLOSE: ...... case TCP_LISTEN: ...... case TCP_SYN_SENT: ...... } ...... switch (sk->sk_state) { case TCP_SYN_RECV: ...... case TCP_FIN_WAIT1: ...... case TCP_CLOSING: ...... case TCP_LAST_ACK: ...... } /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: ...... case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: ...... case TCP_ESTABLISHED: ...... } }
在tcp_rcv_state_process中,如果对着TCP的状态图进行比对,能看到对于TCP所有状态的处理,其中和连接建立相关的状态前面已经分析过,释放连接相关的状态暂不分析,这里重点关注连接状态下的工作模式,在连接状态下会调用tcp_rcv_established。在这个函数里面会调用tcp_data_queue,将其放入sk_receive_queue队列进行处理,如下所示:
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); bool fragstolen = false; ...... if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) { if (tcp_receive_window(tp) == 0) goto out_of_window; /* Ok. In sequence. In window. */ if (tp->ucopy.task == current && tp->copied_seq == tp->rcv_nxt && tp->ucopy.len && sock_owned_by_user(sk) && !tp->urg_data) { int chunk = min_t(unsigned int, skb->len, tp->ucopy.len); __set_current_state(TASK_RUNNING); if (!skb_copy_datagram_msg(skb, 0, tp->ucopy.msg, chunk)) { tp->ucopy.len -= chunk; tp->copied_seq += chunk; eaten = (chunk == skb->len); tcp_rcv_space_adjust(sk); } } if (eaten <= 0) { queue_and_out: ...... eaten = tcp_queue_rcv(sk, skb, 0, &fragstolen); } tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq); ...... if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) { tcp_ofo_queue(sk); ...... } ...... return; } if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) { /* A retransmit, 2nd most common case. Force an immediate ack. */ tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq); out_of_window: tcp_enter_quickack_mode(sk); inet_csk_schedule_ack(sk); drop: tcp_drop(sk, skb); return; } /* Out of window. F.e. zero window probe. */ if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp))) goto out_of_window; tcp_enter_quickack_mode(sk); if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) { /* Partial packet, seq < rcv_next < end_seq */ tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt); /* If window is closed, drop tail of packet. But after * remembering D-SACK for its head made in previous line. */ if (!tcp_receive_window(tp)) goto out_of_window; goto queue_and_out; } tcp_data_queue_ofo(sk, skb); }
在tcp_data_queue中,对于收到的网络包要分情况进行处理。第一种情况是seq == tp->rcv_nxt,说明来的网络包正是服务端期望的下一个网络包,这个时候判断sock_owned_by_user,即用户进程也是正在等待读取,这种情况下就直接skb_copy_datagram_msg,将网络包拷贝给用户进程就可以了。如果用户进程没有正在等待读取,或者因为内存原因没有能够拷贝成功,tcp_queue_rcv里面还是将网络包放入sk_receive_queue队列。
接下来,tcp_rcv_nxt_update将tp->rcv_nxt设置为end_seq,即当前的网络包接收成功后,更新下一个期待的网络包。这个时候,还会判断一下另一个队列out_of_order_queue,也看看乱序队列的情况,看看乱序队列里面的包,会不会因为这个新的网络包的到来,也能放入到sk_receive_queue队列中。
例如,客户端发送的网络包序号为5、6、7、8、9。在5还没有到达的时候,服务端的rcv_nxt应该是 5,即期望下一个网络包是5。但是由于中间网络通路的问题,5、6还没到达服务端,7、8已经到达了服务端了,这就出现了乱序。乱序的包不能进入sk_receive_queue队列,因为一旦进入到这个队列意味着可以发送给用户进程。然而按照TCP的定义,用户进程应该是按顺序收到包的,没有排好序就不能给用户进程。
所以,7、8不能进入sk_receive_queue队列,只能暂时放在out_of_order_queue乱序队列中。当5、6到达的时候,5、6先进入sk_receive_queue队列,这个时候再来看out_of_order_queue乱序队列中的7、8,发现能够接上,于是7、8也能进入sk_receive_queue队列了,上面tcp_ofo_queue函数就是做这个事情的。至此第一种情况处理完毕。
第二种情况,end_seq不大于rcv_nxt,即服务端期望网络包5,但是来了一个网络包3,怎样才会出现这种情况呢?肯定是服务端早就收到了网络包3,但是ACK没有到达客户端中途丢了,那客户端就认为网络包3没有发送成功,于是又发送了一遍,这种情况下要赶紧给客户端再发送一次ACK,表示早就收到了。
第三种情况,seq不小于rcv_nxt + tcp_receive_window,这说明客户端发送得太猛了。本来seq肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。这种情况下,服务端不能再接收数据包了,只能发送ACK了,在ACK中会将接收窗口为0的情况告知客户端,客户端就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在ACK里面再次告诉客户端,又有窗口了又能发送数据包了。
第四种情况,seq小于rcv_nxt但是end_seq大于rcv_nxt,这说明从seq到rcv_nxt这部分网络包原来的ACK客户端没有收到,所以重新发送了一次,从rcv_nxt到end_seq时新发送的,可以放入sk_receive_queue队列。
当前四种情况都排除掉了,说明网络包一定是一个乱序包了。这里有点难理解,还是用上面那个乱序的例子仔细分析一下rcv_nxt=5,假设tcp_receive_window也是5,即超过10服务端就接收不了了。当前来的这个网络包既不在rcv_nxt之前(不是3这种),也不在rcv_nxt + tcp_receive_window之后(不是11这种),说明这正在期望的接收窗口里面,但是又不是rcv_nxt(不是马上期望的网络包 5),这正是上面例子中网络包7、8的情况。
对于网络包7、8,只好调用tcp_data_queue_ofo进入out_of_order_queue乱序队列,但是没有关系,当网络包5、6到来的时候,会走上面第一种情况,把7、8拿出来放到sk_receive_queue队列中。至此,网络协议栈的处理过程就结束了。
5.2 用户态读取网络包
5.2.1 VFS层
read系统调用找到struct file,根据里面file_operations的定义调用sock_read_iter函数。sock_read_iter 函数调用 sock_recvmsg 函数。
当接收的网络包进入各种队列之后,接下来就要等待用户进程去读取它们了。读取一个socket就像读取一个文件一样,读取socket的文件描述符,通过read系统调用,它对于一个文件描述符的操作大致过程都是类似的,最终它会调用到用来表示一个打开文件的结构stuct file所指向的file_operations操作。对socket来讲,它的file_operations定义如下:
static const struct file_operations socket_file_ops = { .owner = THIS_MODULE, .llseek = no_llseek, .read_iter = sock_read_iter, .write_iter = sock_write_iter, .poll = sock_poll, .unlocked_ioctl = sock_ioctl, .mmap = sock_mmap, .release = sock_close, .fasync = sock_fasync, .sendpage = sock_sendpage, .splice_write = generic_splice_sendpage, .splice_read = sock_splice_read, };
按照文件系统的读取流程,调用的是sock_read_iter,如下所示:
static ssize_t sock_read_iter(struct kiocb *iocb, struct iov_iter *to) { struct file *file = iocb->ki_filp; struct socket *sock = file->private_data; struct msghdr msg = {.msg_iter = *to, .msg_iocb = iocb}; ssize_t res; if (file->f_flags & O_NONBLOCK) msg.msg_flags = MSG_DONTWAIT; ...... res = sock_recvmsg(sock, &msg, msg.msg_flags); *to = msg.msg_iter; return res; }
5.2.2 Socket层
在sock_read_iter中,通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock_recvmsg,sock_recvmsg会调用sock_recvmsg_nosec,如下所示:
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, int flags) { return sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags); }
这里调用了socket的ops的recvmsg。根据inet_stream_ops的定义,这里调用的是inet_recvmsg,如下所示:
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size, int flags) { struct sock *sk = sock->sk; int addr_len = 0; int err; ...... err = sk->sk_prot->recvmsg(sk, msg, size, flags & MSG_DONTWAIT, flags & ~MSG_DONTWAIT, &addr_len); ...... }
5.2.3 Sock层
从socket结构,可以得到更底层的sock结构,然后调用sk_prot的recvmsg方法。根据tcp_prot的定义调用的是tcp_recvmsg
5.2.4 TCP层
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock, int flags, int *addr_len) { struct tcp_sock *tp = tcp_sk(sk); int copied = 0; u32 peek_seq; u32 *seq; unsigned long used; int err; int target; /* Read at least this many bytes */ long timeo; struct task_struct *user_recv = NULL; struct sk_buff *skb, *last; ..... do { u32 offset; ...... /* Next get a buffer. */ last = skb_peek_tail(&sk->sk_receive_queue); skb_queue_walk(&sk->sk_receive_queue, skb) { last = skb; offset = *seq - TCP_SKB_CB(skb)->seq; if (offset < skb->len) goto found_ok_skb; ...... } ...... if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) { /* Install new reader */ if (!user_recv && !(flags & (MSG_TRUNC | MSG_PEEK))) { user_recv = current; tp->ucopy.task = user_recv; tp->ucopy.msg = msg; } tp->ucopy.len = len; /* Look: we have the following (pseudo)queues: * * 1. packets in flight * 2. backlog * 3. prequeue * 4. receive_queue * * Each queue can be processed only if the next ones * are empty. */ if (!skb_queue_empty(&tp->ucopy.prequeue)) goto do_prequeue; } if (copied >= target) { /* Do not sleep, just process backlog. */ release_sock(sk); lock_sock(sk); } else { sk_wait_data(sk, &timeo, last); } if (user_recv) { int chunk; chunk = len - tp->ucopy.len; if (chunk != 0) { len -= chunk; copied += chunk; } if (tp->rcv_nxt == tp->copied_seq && !skb_queue_empty(&tp->ucopy.prequeue)) { do_prequeue: tcp_prequeue_process(sk); chunk = len - tp->ucopy.len; if (chunk != 0) { len -= chunk; copied += chunk; } } } continue; found_ok_skb: /* Ok so how much can we use? */ used = skb->len - offset; if (len < used) used = len; if (!(flags & MSG_TRUNC)) { err = skb_copy_datagram_msg(skb, offset, msg, used); ...... } *seq += used; copied += used; len -= used; tcp_rcv_space_adjust(sk); ...... } while (len > 0); ...... }
tcp_recvmsg这个函数比较长,里面逻辑也很复杂,好在里面有一段注释概括了这里面的逻辑。注释里面提到了三个队列,即receive_queue队列、prequeue队列和backlog队列。这里面需要把前一个队列处理完毕,才处理后一个队列。tcp_recvmsg的整个逻辑也是这样执行的:这里面有一个while循环,不断地读取网络包,这里会先处理sk_receive_queue队列,如果找到了网络包,就跳到found_ok_skb这里,这里会调用skb_copy_datagram_msg,将网络包拷贝到用户进程中,然后直接进入下一层循环。
循环直到sk_receive_queue队列处理完毕,才到了sysctl_tcp_low_latency判断。如果不需要低时延,则会有prequeue队列,于是能就跳到do_prequeue这里,调用tcp_prequeue_process进行处理。如果sysctl_tcp_low_latency设置为1,即没有prequeue队列,或者prequeue队列为空,则需要处理backlog队列,在release_sock函数中处理。release_sock会调用__release_sock,这里面会依次处理队列中的网络包,如下所示:
void release_sock(struct sock *sk) { ...... if (sk->sk_backlog.tail) __release_sock(sk); ...... } static void __release_sock(struct sock *sk) __releases(&sk->sk_lock.slock) __acquires(&sk->sk_lock.slock) { struct sk_buff *skb, *next; while ((skb = sk->sk_backlog.head) != NULL) { sk->sk_backlog.head = sk->sk_backlog.tail = NULL; do { next = skb->next; prefetch(next); skb->next = NULL; sk_backlog_rcv(sk, skb); cond_resched(); skb = next; } while (skb != NULL); } ...... }
5.3 接收过程总结
整个网络包的接收过程总结如下:
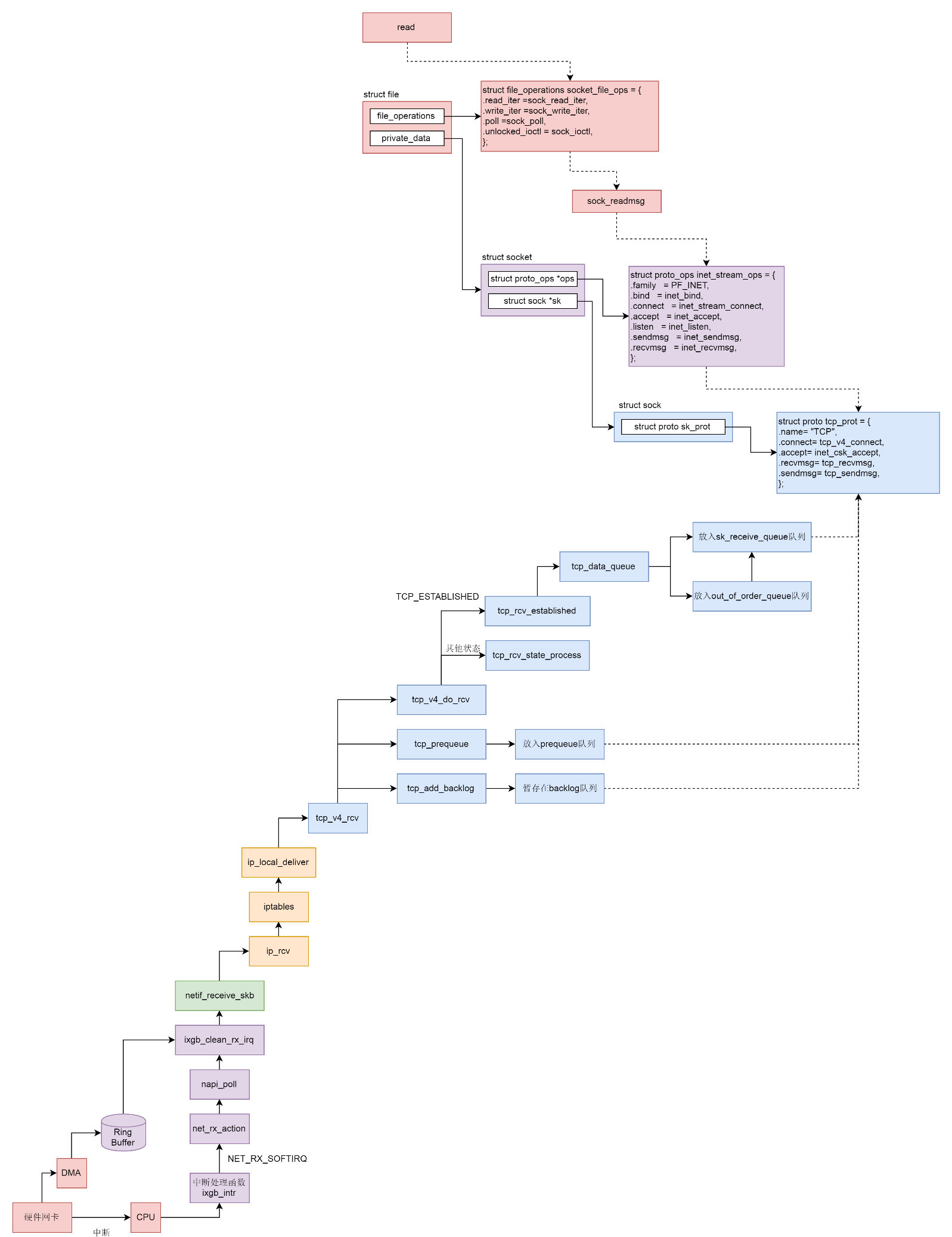
6. 参考
[1] https://blog.csdn.net/qq_33588730/article/details/105177754
[2] https://blog.csdn.net/lidandan999/article/details/91129124
[3] 《linux内核协议栈源码解析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号