
【kmeans聚类】如何选择最为合适的k值
下述提及方法均以k-means算法为基础, 不同聚类方法有不同的评价指标,这里说说k-means常用的两种方法
我们知道k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。 基于这个指标,我们可以重复训练多个k-means模型,选取不同的k值,来得到相对合适的聚类类别,
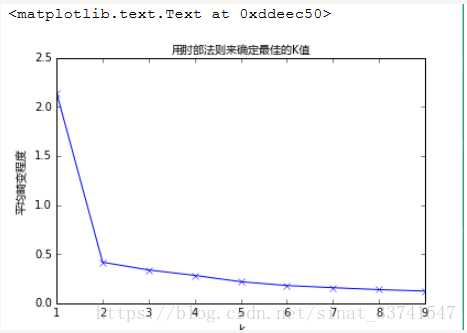
如上图所示,在k=2时,畸变程度得到大幅改善,可以考虑选取k=2作为聚类数量,附简单代码:
from sklearn.cluster import KMeansmodel = KMeans(n_clusters=k)model.fit(vector_points)md = model.inertia_ / vector_points.shape[0]
2、轮廓系数–Silhouette Coefficient
对于一个聚类任务,我们希望得到的簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下: s=b−amax(a,b)s=b−amax(a,b)其中a代表同簇样本到彼此间距离的均值,b代表样本到除自身所在簇外的最近簇的样本的均值,s取值在[-1, 1]之间。 如果s接近1,代表样本所在簇合理,若s接近-1代表s更应该分到其他簇中。 同样,利用上述指标,训练多个模型,对比选取合适的聚类类别:
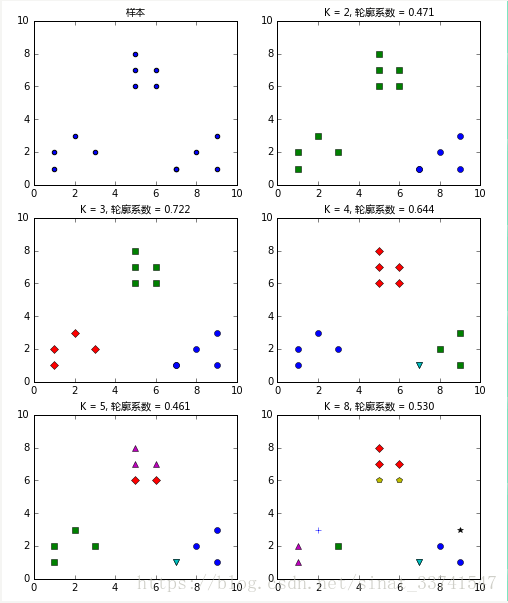
如上图, 当k=3时,轮廓系数最大,代表此时聚类的效果相对合理,简单代码如下:from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scoremodel = KMeans(n_clusters=k)model.fit(vector_points)
s = silhouette_score(vector_points, model.labels_)
当然还有其他的一些评判标准,后面会具体详细介绍一部分
主要参考可见:
https://www.cnblogs.com/niniya/p/8784947.html
https://blog.csdn.net/darkrabbit/article/details/80378597
https://www.jianshu.com/p/841ecdaab847?tdsourcetag=s_pctim_aiomsg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号