
http1.1和http2.0的区别?
1. 新的传输格式
HTTP 1.1 :使用基于文本格式
HTTP 2.0 :使用二进制格式
HTTP1.x 的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
2. 多路复用
为什么会出现多路复用呢?那么多路复用到底又是什么呢?
为什么在2.0的时候会出现多路复用,那不用说,肯定1.1出问题了,HTTP 1.1 有什么问题呢?重点:效率。HTTP 1.1 虽然解决了多次连接的问题,但是它存在一个致命的缺陷,效率低下。
1)串行的文件传输。当请求 a 文件时,b 文件只能等待,等待 a 连接到服务器、服务器处理文件、服务器返回文件,这三个步骤。我们假设这三步用时都是1秒,那么 a 文件用时为3秒,b 文件传输完成用时为6秒,依此类推。(注:此项计算有一个前提条件,就是浏览器和服务器是单通道传输)
2)连接数过多。我们假设 Apache 设置了最大并发数为300,因为浏览器限制,浏览器发起的最大请求数为6,也就是服务器能承载的最高并发为50,当第51个人访问时,就需要等待前面某个请求处理完成。
就这两个问题,HTTP 1.1的效率强行的被拉下来了,这时候HTTP 2.0的多路复用就为解决这个问题而出现了。
说多路复用,不的不说一下HTTP 1.1的持久连接,而这个持久连接,就是我们接下来所说的 Keep-Alive 。
Keep-Alive 是使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
我们知道 HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答客户和服务器都要新建一个连接,完成 之后立即断开连接( HTTP 协议为无连接的协议);当使用 Keep-Alive 模式(又称持久连接)时,Keep-Alive 功能使客户端到服 务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。
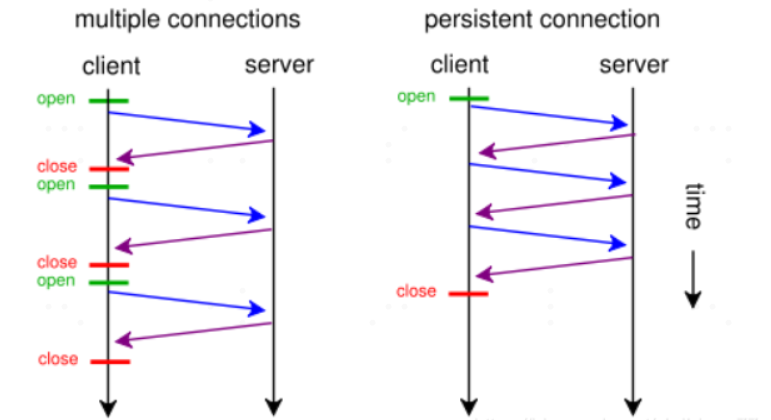
HTTP 1.0中默认是关闭的,需要在 HTTP 头加入" Connection: Keep-Alive",才能启用 Keep-Alive ;
HTTP 1.1中默认启用 Keep-Alive ,如果加入"Connection: close ",才关闭。目前大部分浏览器都是用 HTTP 1.1协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
HTTP 1.1 和 HTTP 2.0 的区别来了,多路复用,什么是多路复用呢?
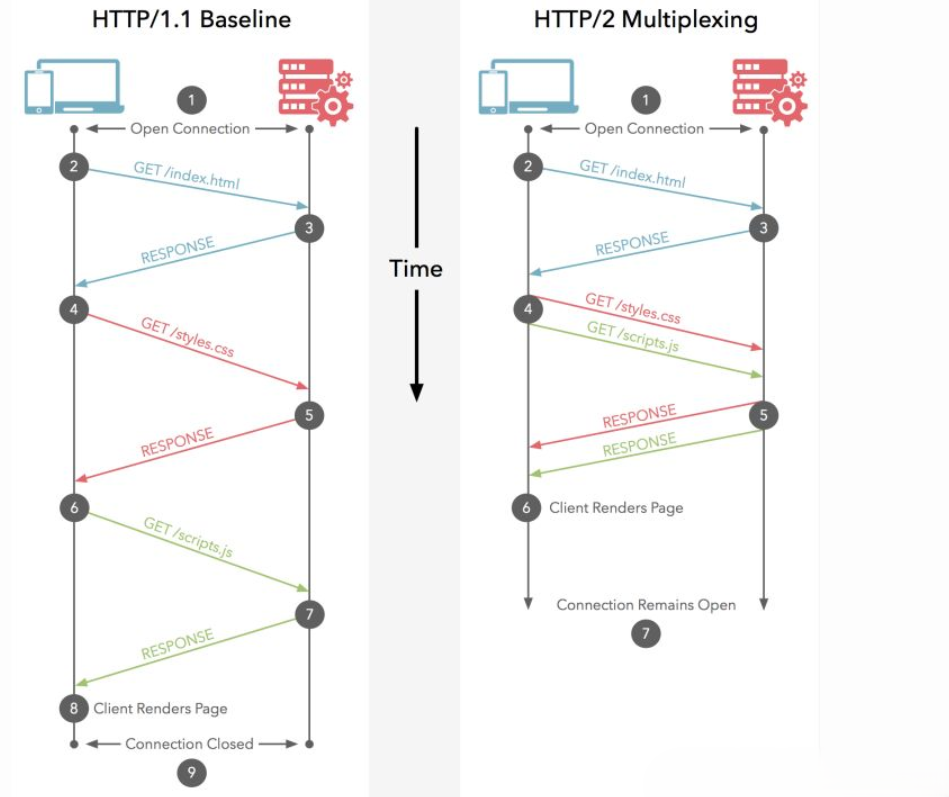
上图是 HTTP 2.0的复用连接,虽然依然遵循请求-响应模式,但客户端发送多个请求和服务端给出多个响应的顺序不受限制,这样既避免了"队头堵塞",又能更快获取响应。在复用同一个 TCP 连接时,服务器同时(或先后)收到了 A、B 两个请求,先回应A请求,但由于处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。HTTP 2.0长连接可以理解成全双工的协议。
因为HTTP 2.0引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,也就是说,我们传递一个字符串的时候,比如说,我要传递一个,“别说了,我爱你”,HTTP 1.1是按照一个顺序传输,那么 HTTP 2.0是怎么传输的,看图:
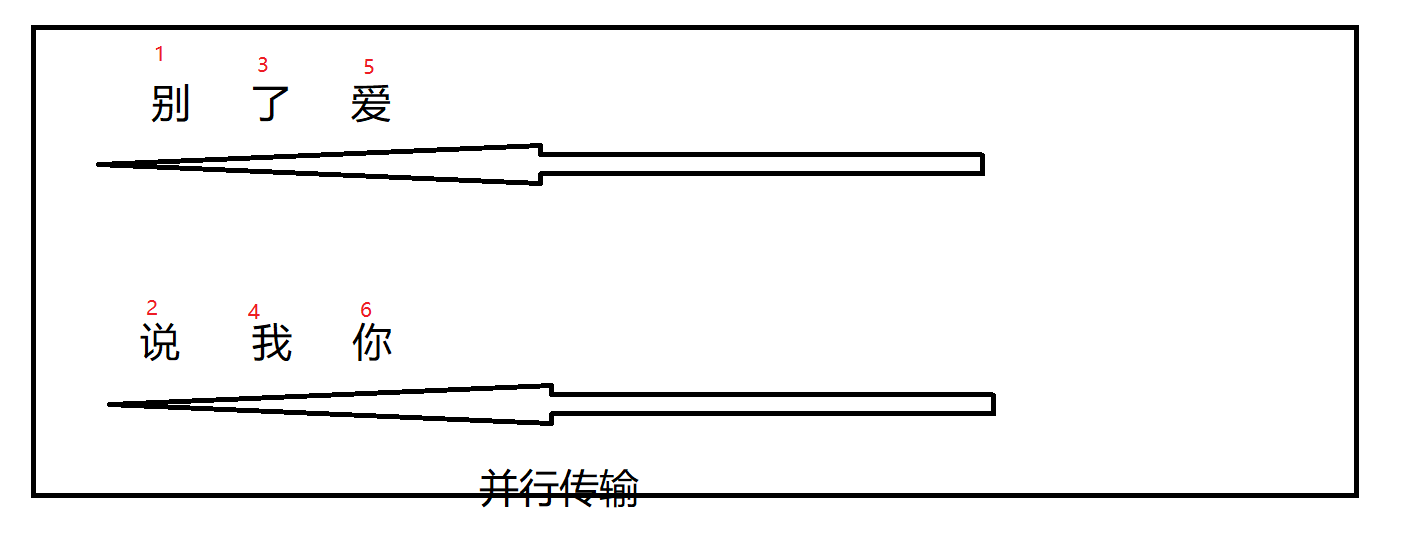
浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的传输数据,这就是流所做的事情。
这也就是解决了问题1,那么怎么解决问题2呢?HTTP 2.0 对同一域名下所有请求都是基于流,也就是说同一域名不管访问多少文件,也只建立一路连接。同样 Apache 的最大连接数为300,因为有了这个新特性,最大的并发就可以提升到300,比原来提升了6倍!
3. 头部header压缩
HTTP 1.x的 header 带有大量信息,而且每次都要重复发送,HTTP 2.0使用 encoder 来减少需要传输的 header 大小,通讯双方各自 cache 一份 header fields 表,既避免了重复 header 的传输,又减小了需要传输的大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号