Elaticsearch REST API常用技巧
在Elasticsearch的REST API中,有很多使用技巧,这里针对官方文档给出的介绍,总结了几个常用的例子。
更多内容参考:Elastisearch文档总结
多索引
ES支持在一次请求中指定多个索引,可以使用通配符或者日期表达式的方式:
例如,foo*索引会匹配foo1,foo2,foo3等索引。_all则会匹配所有的索引。
同时也可以针对不可用的索引进行限制。
日期表达式支持如下的格式:
<static_name{date_math_expr{date_format|time_zone}}>
static_name是索引的静态部分
date_math_expr是日期表达式
后面跟着date_format是日期的格式;time_zone为时区
举个例子,如果想要查询logstash前两天的日期,可以写成:
curl -XGET 'localhost:9200/<logstash-{now/d-2d}>/_search' { "query" : { ... } }
再比如,当前的时间是2014年3月22日,那么:
<logstash-{now/d}> 会匹配 logstash-2024.03.22
<logstash-{now/M}> 会匹配 logstash-2024.03.01
<logstash-{now/M{YYYY.MM}}> 会匹配 logstash-2024.03
<logstash-{now/M-1M{YYYY.MM}}> 会匹配 logstash-2024.02
<logstash-{now/d{YYYY.MM.dd|+12:00}} 会匹配 logstash-2024.03.23
过去三天的索引可以表示为:
curl -XGET 'localhost:9200/<logstash-{now/d-2d}>,<logstash-{now/d-1d}>,<logstash-{now/d}>/_search' { "query" : { ... } }
过滤
所有的API都可以接受一个参数,filter_path,这个参数指定了过滤后的字段,返回的结果只会显示过滤指定的内容:
curl -XGET 'localhost:9200/_search?pretty&filter_path=took,hits.hits._id,hits.hits._score' { "took" : 3, "hits" : { "hits" : [ { "_id" : "3640", "_score" : 1.0 }, { "_id" : "3642", "_score" : 1.0 } ] } }
支持使用通配符,进行匹配
curl -XGET 'localhost:9200/_nodes/stats?filter_path=nodes.*.ho*' { "nodes" : { "lvJHed8uQQu4brS-SXKsNA" : { "host" : "portable" } } }
如果使用了两个**则会匹配所有的内容
curl 'localhost:9200/_segments?pretty&filter_path=indices.**.version' { "indices" : { "movies" : { "shards" : { "0" : [ { "segments" : { "_0" : { "version" : "5.2.0" } } } ], "2" : [ { "segments" : { "_0" : { "version" : "5.2.0" } } } ] } }, "books" : { "shards" : { "0" : [ { "segments" : { "_0" : { "version" : "5.2.0" } } } ] } } } }
如果要过滤_source,那么需要重新指定_source中的字段:
curl -XGET 'localhost:9200/_search?pretty&filter_path=hits.hits._source&_source=title' { "hits" : { "hits" : [ { "_source":{"title":"Book #2"} }, { "_source":{"title":"Book #1"} }, { "_source":{"title":"Book #3"} } ] } }
结果内容扁平化
使用flat_settings参数,它只会影响到返回的内容显示,例如设置为true后返回的内容是下面这种:
{ "persistent" : { }, "transient" : { "discovery.zen.minimum_master_nodes" : "1" } }
而设置为false,则为:
{ "persistent" : { }, "transient" : { "discovery" : { "zen" : { "minimum_master_nodes" : "1" } } } }
返回内容格式化
正常返回的数据,可能是混杂在一行的,人的肉眼很难分别其中的信息,这时,可以再请求的末尾添加?pretty=true,或者?format-yaml设置成可读的形式。
pretty是以JSON的形式返回结果。直接写?pretty与?pretty=true作用一样
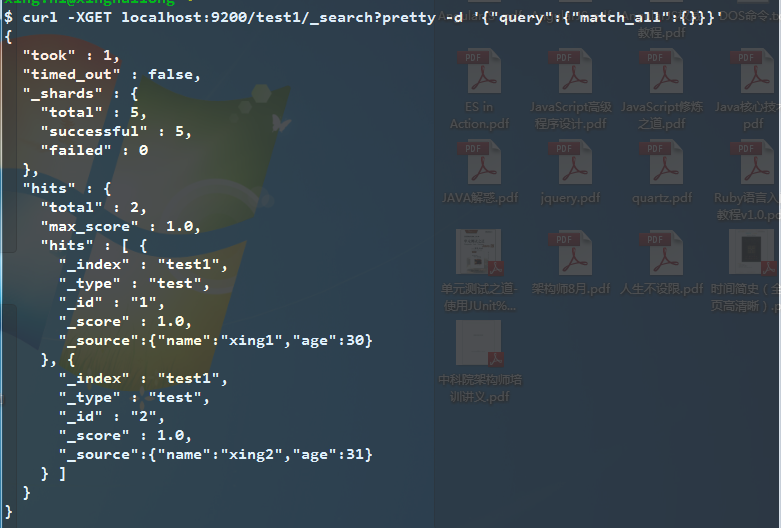
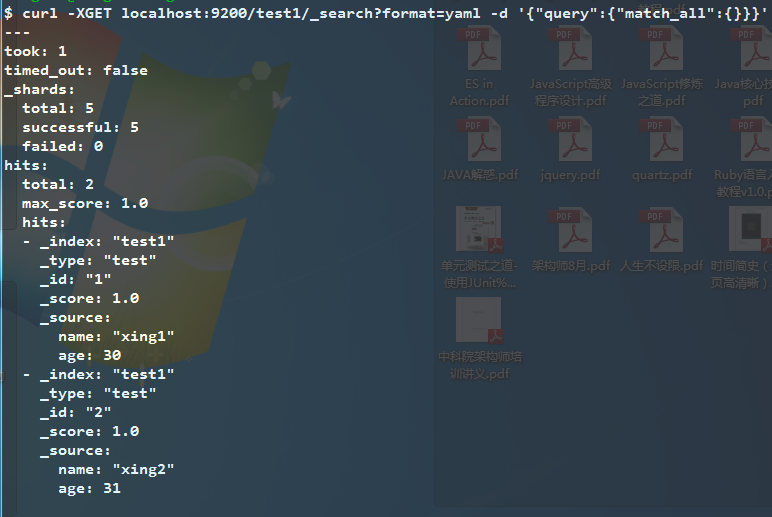
yaml则是使用横向缩进的方式展现结果。
返回结果可读
返回的结果设置为可读,对于我们肉眼去观察结果也很重要,比如:
"exists_time": "1h" "size": "1kb" 要比 "exists_time_in_millis": 3600000 "size_in_bytes": 1024 容易理解的多
参考
【1】YAML格式


 浙公网安备 33010602011771号
浙公网安备 33010602011771号